Recognition: 2 theorem links
· Lean TheoremSystematic Discovery of Semantic Attacks in Online Map Construction through Conditional Diffusion
Pith reviewed 2026-05-15 01:36 UTC · model grok-4.3
The pith
Conditional diffusion models enable discovery of semantic attacks that degrade online HD map construction while appearing as natural variations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
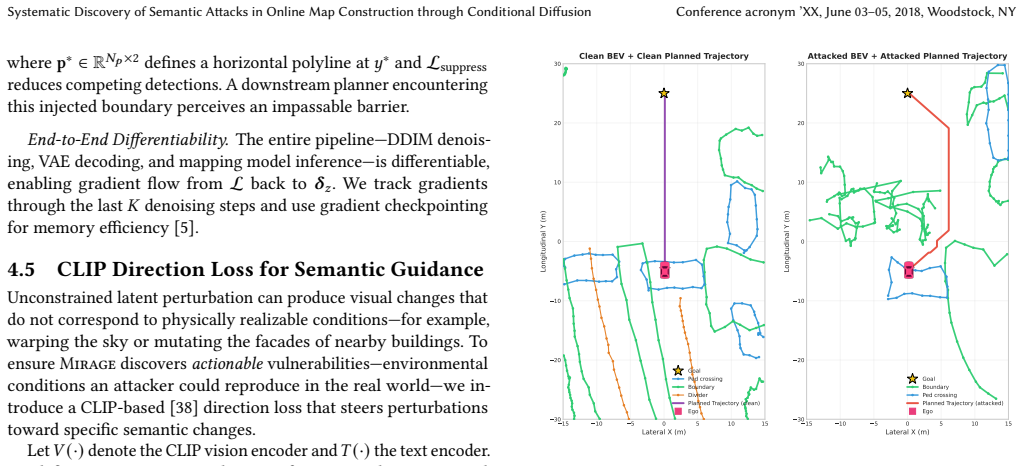
MIRAGE exploits the latent manifold of real-world data learned by conditional diffusion models to search for semantically mutated scenes neighboring the ground truth with the same road topology yet mislead the mapping predictions. On nuScenes it produces boundary removal that suppresses 57.7% of detections and corrupts 96% of planned trajectories, plus boundary injection that adds fictitious boundaries where pixel PGD and AdvPatch fail entirely. Both attacks remain potent under various adversarial defenses and pass as realistic 80-84% of the time to two independent VLM judges versus 97-99% for clean nuScenes.
What carries the argument
MIRAGE framework that uses conditional diffusion to generate and search semantically plausible environmental variations neighboring ground truth scenes while preserving exact road topology.
If this is right
- Boundary removal suppresses 57.7% of lane detections and corrupts 96% of planned trajectories.
- Boundary injection adds fictitious boundaries, succeeding where pixel-based PGD and AdvPatch fail entirely.
- Both semantic attacks remain effective against standard adversarial defenses that neutralize pixel perturbations.
- Generated scenes are rated realistic by VLMs 80-84% of the time compared with 97-99% for clean data.
Where Pith is reading between the lines
- Future AV mapping systems may require semantic consistency checks that go beyond pixel statistics or local anomaly detection.
- Real-world environmental factors could be adversarially exploited if they match the generated variations closely enough.
- Applying the same diffusion search approach to other perception modules such as object detection could reveal comparable semantic vulnerabilities.
Load-bearing premise
The conditional diffusion model accurately captures the latent manifold of real-world road scenes, generating variations that maintain exact road topology while altering semantics enough to mislead the target mapper.
What would settle it
A defense trained specifically on MIRAGE-generated semantic examples that eliminates the attacks while preserving accuracy on clean nuScenes scenes would show the perturbations are not substantially harder to mitigate than pixel-level ones.
Figures












read the original abstract
Autonomous vehicles depend on online HD map construction to perceive lane boundaries, dividers, and pedestrian crossings -- safety-critical road elements that directly govern motion planning. While existing pixel perturbation attacks can disrupt the mapping, they can be neutralized by standard adversarial defenses. We present MIRAGE, a framework for systematic discovery of semantic attacks that bypass adversarial defenses and degrade mapping predictions by finding plausible environmental variation (e.g. shadows, wet roads). MIRAGE exploits the latent manifold of real-world data learned by diffusion models, and searches for semantically mutated scenes neighboring the ground truth with the same road topology yet mislead the mapping predictions. We evaluate MIRAGE on nuScenes and demonstrate two attacks: (1) boundary removal, suppressing 57.7% of detections and corrupting 96% of planned trajectories; and (2) boundary injection, the only method that successfully injects fictitious boundaries, while pixel PGD and AdvPatch fail entirely. Both attacks remain potent under various adversarial defenses. We use two independent VLM judges to quantify realism, where MIRAGE passes as realistic 80--84% of the time (vs. 97--99% for clean nuScenes), while AdvPatch only 0--9%. Our findings expose a categorical gap in current adversarial defenses: semantic-level perturbations that manifest as legitimate environmental variation are substantially harder to mitigate than pixel-level perturbations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MIRAGE, a framework that leverages conditional diffusion models to discover semantic attacks on online HD map construction for autonomous vehicles. It searches the latent manifold of real-world scenes (e.g., nuScenes) for plausible environmental variations such as altered lighting or surface conditions that preserve road topology while misleading mapping predictions, achieving 57.7% boundary detection suppression, 96% trajectory corruption, and successful fictitious boundary injection where pixel PGD and AdvPatch fail. Realism is assessed via two independent VLM judges (80-84% pass rate vs. 97-99% for clean data), and attacks remain effective under standard defenses.
Significance. If the topology-preservation assumption holds, the work identifies a meaningful gap between pixel-level and semantic-level attacks on safety-critical AV mapping, with the empirical evaluation on a public dataset and use of independent VLM judges providing a reproducible basis for the claim that semantic perturbations manifesting as legitimate variation are harder to mitigate.
major comments (2)
- [Method and Experimental Evaluation] The central claim that MIRAGE produces scenes with identical road topology (same lane boundaries, dividers, crossings) while only altering semantics rests on the conditional diffusion operating on the latent manifold, yet no independent quantitative verification is provided (e.g., polyline Hausdorff distance, lane-graph edit distance, or pixel-wise boundary IoU between original and generated annotations).
- [Results] Reported performance figures (57.7% suppression, 96% trajectory corruption, 80-84% realism) are given without error bars, scene-wise variance, or full protocol details on how many scenes were tested and how baselines were matched, weakening assessment of whether the gap versus pixel attacks is robust.
minor comments (1)
- [Abstract] The abstract states specific percentages without cross-references to the tables or sections containing the complete experimental setup and statistical details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions that will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method and Experimental Evaluation] The central claim that MIRAGE produces scenes with identical road topology (same lane boundaries, dividers, crossings) while only altering semantics rests on the conditional diffusion operating on the latent manifold, yet no independent quantitative verification is provided (e.g., polyline Hausdorff distance, lane-graph edit distance, or pixel-wise boundary IoU between original and generated annotations).
Authors: We agree that explicit quantitative verification of topology preservation would strengthen the central claim. In the revised manuscript we will report polyline Hausdorff distances and pixel-wise boundary IoU between original and generated annotations across the evaluated scenes. These metrics will be computed directly from the nuScenes annotations and the generated outputs to confirm that lane boundaries, dividers, and crossings remain unchanged while semantic elements vary. revision: yes
-
Referee: [Results] Reported performance figures (57.7% suppression, 96% trajectory corruption, 80-84% realism) are given without error bars, scene-wise variance, or full protocol details on how many scenes were tested and how baselines were matched, weakening assessment of whether the gap versus pixel attacks is robust.
Authors: We acknowledge that additional statistical detail is needed. The revised results section will include error bars (standard deviation across scenes), scene-wise variance analysis, the exact number of scenes drawn from the nuScenes validation set, and a complete protocol describing how perturbation budgets and evaluation settings were matched for PGD and AdvPatch baselines. These additions will allow readers to assess the robustness of the performance gaps more rigorously. revision: yes
Circularity Check
No circularity: derivation relies on external diffusion properties and empirical validation
full rationale
The paper's central method (MIRAGE) uses conditional diffusion models to search the latent manifold for semantic variations that preserve road topology while misleading mappers. This is presented as an exploitation of learned data manifolds rather than a self-referential definition or fitted parameter renamed as a prediction. No equations reduce attack success or topology preservation to inputs by construction; claims are supported by evaluations on the independent nuScenes dataset and VLM realism judges. Self-citations, if present, are not load-bearing for the uniqueness or correctness of the topology-preserving search. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditional diffusion models trained on driving data learn a latent manifold that permits generation of plausible environmental variations while preserving road topology.
invented entities (1)
-
MIRAGE attack discovery framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mirage exploits the latent manifold of real-world data learned by diffusion models, and searches for semantically mutated scenes neighboring the ground truth with the same road topology yet mislead the mapping predictions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Leverage ControlNet to constraint the generation to be conditioned on the ground truth mapping results, ensuring the actual road topology remains consistent
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. 2020. nuScenes: A Multimodal Dataset for Autonomous Driving. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
work page 2020
-
[2]
Yulong Cao, Chaowei Xiao, Benjamin Cyr, Yimeng Zhou, Won Park, Sara Ram- pazzi, Qi Alfred Chen, Kevin Fu, and Z. Morley Mao. 2019. Adversarial Sensor Attack on LiDAR-based Perception in Autonomous Driving. InACM Conference on Computer and Communications Security (CCS)
work page 2019
-
[3]
Nicholas Carlini and David Wagner. 2017. Towards Evaluating the Robustness of Neural Networks. InIEEE Symposium on Security and Privacy (SP)
work page 2017
-
[4]
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. 2024. End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Machine Intelligence46, 12 (2024), 10164–10183
work page 2024
-
[5]
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training deep nets with sublinear memory cost.arXiv preprint arXiv:1604.06174(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Jeremy M. Cohen, Elan Rosenfeld, and J. Zico Kolter. 2019. Certified Adversarial Robustness via Randomized Smoothing. InInternational Conference on Machine Learning (ICML)
work page 2019
-
[7]
Xuelong Dai, Kaisheng Liang, and Bin Xiao. 2024. Advdiff: Generating unre- stricted adversarial examples using diffusion models. InEuropean Conference on Computer Vision. Springer, 93–109
work page 2024
-
[8]
Yinpeng Dong, Qi-An Fu, Xiao Yang, Tianyu Pang, Hang Su, Zihao Xiao, and Jun Zhu. 2020. Benchmarking adversarial robustness on image classification. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 321–331
work page 2020
-
[9]
Gintare Karolina Dziugaite, Zoubin Ghahramani, and Daniel M Roy. 2016. A study of the effect of jpg compression on adversarial images.arXiv preprint arXiv:1608.00853(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[10]
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. 2018. Robust Physical- World Attacks on Deep Learning Visual Classification. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2018
-
[11]
Alvan R Feinstein and Domenic V Cicchetti. 1990. High agreement but low kappa: I. The problems of two paradoxes.Journal of clinical epidemiology43, 6 (1990), 543–549
work page 1990
-
[12]
Bermano, Gal Chechik, and Daniel Cohen-Or
Rinon Gal, Or Patashnik, Haggai Maron, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. 2022. StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators. InACM SIGGRAPH
work page 2022
-
[13]
Hao Gao, Shaoyu Chen, Bo Jiang, Bencheng Liao, Yiang Shi, Xiaoyang Guo, Yuechuan Pu, haoran yin, Xiangyu Li, xinbang zhang, ying zhang, Wenyu Liu, Qian Zhang, and Xinggang Wang. 2025. RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS)
work page 2025
-
[14]
Jiyang Gao, Chen Sun, Hang Zhao, Yi Shen, Dragomir Anguelov, Congcong Li, and Cordelia Schmid. 2020. Vectornet: Encoding hd maps and agent dynamics from vectorized representation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11525–11533
work page 2020
-
[15]
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. 2024. MagicDrive: Street View Generation with Diverse 3D Geometry Control. InInternational Conference on Learning Representations (ICLR)
work page 2024
-
[16]
Gemma Team. 2026. Gemma 4: Byte for byte, the most capable open mod- els. https://blog.google/innovation-and-ai/technology/developers-tools/gemma- 4/. (2026)
work page 2026
-
[17]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. InInternational Conference on Learning Representations (ICLR)
work page 2015
-
[18]
Chuan Guo, Mayank Rana, Moustapha Cisse, and Laurens Van Der Maaten
-
[19]
Countering adversarial images using input transformations.arXiv preprint arXiv:1711.00117(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
work page 2016
-
[21]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems (NeurIPS)
work page 2020
-
[22]
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al . 2023. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 17853–17862
work page 2023
-
[23]
Yunhan Jia, Yantao Lu, Junjie Shen, Qi Alfred Chen, Hao Chan, Zhenyu Zhong, and Tao Wei. 2020. Fooling Detection Alone is Not Enough: Adversarial Attack against Multiple Object Tracking. InICLR
work page 2020
-
[24]
Yunhan Jia, Yantao Lu, Junjie Shen, Qi Alfred Chen, Zhenyu Zhong, and Tao Wei. 2019. Fooling detection alone is not enough: First adversarial attack against multiple object tracking.arXiv preprint arXiv:1905.11026(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. 2023. VAD: Vec- torized Scene Representation for Efficient Autonomous Driving. InIEEE/CVF International Conference on Computer Vision (ICCV)
work page 2023
-
[26]
Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye. 2022. DiffusionCLIP: Text- Guided Diffusion Models for Robust Image Manipulation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2022
-
[27]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Tencent Keen Security Lab. 2019. Experimental security research of Tesla autopi- lot.Tencent Keen Security Lab(2019)
work page 2019
-
[29]
Chumeng Liang, Xiaoyu Wu, Yang Hua, Jiaru Zhang, Yiming Xue, Tao Song, Zhengui Xue, Ruhui Ma, and Haibing Guan. 2023. Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples. InInternational Conference on Machine Learning (ICML)
work page 2023
-
[30]
Bencheng Liao, Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Chang Huang. 2023. MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction. InInternational Conference on Learning Representations (ICLR)
work page 2023
-
[31]
Bencheng Liao, Shaoyu Chen, Yunchi Zhang, Bo Jiang, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. 2024. MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction.International Journal of Computer Vision (IJCV)(2024), 1–23
work page 2024
-
[32]
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. 2023. Vectormapnet: End-to-end vectorized hd map learning. InInternational conference on machine learning. PMLR, 22352–22369
work page 2023
-
[33]
Yang Lou, Haibo Hu, Qun Song, Qian Xu, Yi Zhu, Rui Tan, Wei-Bin Lee, and Jianping Wang. 2025. Asymmetry Vulnerability and Physical Attacks on Online Map Construction for Autonomous Driving. InACM Conference on Computer and Communications Security (CCS)
work page 2025
-
[34]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Conference acronym ’XX, June 03–05, 2018, Woodstock, NY C. Wang, R. Song, R. Muller, J.P. Monteuuis, J. Petit, Z.B. Celik, R. Gerdes, M.F. Li Attacks. InInternational Conference on Learning Representations (ICLR)
work page 2018
-
[35]
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2023. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6038–6047
work page 2023
-
[36]
Raymond Muller, Yanmao Man, Z Berkay Celik, Ming Li, and Ryan Gerdes. 2022. Physical hijacking attacks against object trackers. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security. 2309–2322
work page 2022
-
[37]
Raymond Muller, Ruoyu Song, Chenyi Wang, Yuxia Zhan, Jean-Phillipe Mon- teuuis, Yanmao Man, Ming Li, Ryan Gerdes, Jonathan Petit, and Z Berkay Celik
-
[38]
In 2025 IEEE Symposium on Security and Privacy (SP)
Investigating physical latency attacks against camera-based perception. In 2025 IEEE Symposium on Security and Privacy (SP). IEEE, 4588–4605
work page 2025
-
[39]
Weili Nie, Brandon Guo, Yujia Huang, Chaowei Xiao, Arash Vahdat, and Anima Anandkumar. 2022. Diffusion Models for Adversarial Purification. InInternational Conference on Machine Learning (ICML)
work page 2022
-
[40]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning (ICML)
work page 2021
-
[41]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). 10684–10695
work page 2022
-
[42]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention. Springer, 234–241
work page 2015
-
[43]
Miyu Sato, Ryunosuke Kobayashi, Kazuki Nomoto, Yuna Tanaka, Go Tsuruoka, and Tatsuya Mori. 2025. {WIP}: Evaluation of Threats and Impacts of {HD} Map Tampering Attacks in Autonomous Driving. In3rd USENIX Symposium on Vehicle Security and Privacy (VehicleSec 25). 307–314
work page 2025
-
[44]
Takami Sato, Junjie Shen, Ningfei Wang, Yunhan Jia, Xue Lin, and Qi Alfred Chen
-
[45]
In30th USENIX security symposium (USENIX Security 21)
Dirty road can attack: Security of deep learning based automated lane centering under {Physical-World} attack. In30th USENIX security symposium (USENIX Security 21). 3309–3326
-
[46]
Takami Sato, Justin Yue, Nanze Chen, Ningfei Wang, and Qi Alfred Chen. 2024. Intriguing properties of diffusion models: An empirical study of the natural attack capability in text-to-image generative models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). 24635–24644
work page 2024
-
[47]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2021. Denoising Diffusion Implicit Models. InInternational Conference on Learning Representations (ICLR)
work page 2021
-
[48]
Ruoyu Song, Muslum Ozgur Ozmen, Hyungsub Kim, Raymond Muller, Z Berkay Celik, and Antonio Bianchi. 2023. Discovering adversarial driving maneuvers against autonomous vehicles. In32nd USENIX Security Symposium (USENIX Security 23). 2957–2974
work page 2023
-
[49]
Jiachen Sun, Yulong Cao, Qi Alfred Chen, and Z. Morley Mao. 2020. Towards Robust LiDAR-based Perception in Autonomous Driving: General Black-box Adversarial Sensor Attack and Countermeasures. InUSENIX Security Symposium
work page 2020
-
[50]
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. 2025. Sparsedrive: End-to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 8795–8801
work page 2025
-
[51]
James Tu, Mengye Ren, Sivabalan Manivasagam, Ming Liang, Bin Yang, Richard Du, Frank Cheng, and Raquel Urtasun. 2020. Physically Realizable Adversarial Examples for LiDAR Object Detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2020
-
[52]
Chenyi Wang, Yanmao Man, Raymond Muller, Ming Li, Z Berkay Celik, Ryan Gerdes, and Jonathan Petit. 2024. Physical ID-Transfer Attacks against Multi- Object Tracking via Adversarial Trajectory. In2024 Annual Computer Security Applications Conference (ACSAC). IEEE, 957–973
work page 2024
-
[53]
Ningfei Wang, Yunpeng Luo, Takami Sato, Kaidi Xu, and Qi Alfred Chen. 2023. Does physical adversarial example really matter to autonomous driving? towards system-level effect of adversarial object evasion attack. InProceedings of the IEEE/CVF international conference on computer vision. 4412–4423
work page 2023
-
[54]
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. 2024. Drivedreamer: Towards real-world-drive world models for autonomous driving. InEuropean conference on computer vision (ECCV). Springer, 55–72
work page 2024
-
[55]
Hui Wei, Hao Tang, Xuemei Jia, Zhixiang Wang, Hanxun Yu, Zhubo Li, Shin’ichi Satoh, Luc Van Gool, and Zheng Wang. 2024. Physical adversarial attack meets computer vision: A decade survey.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 12 (2024), 9797–9817
work page 2024
-
[56]
Yuting Xie, Xianda Guo, Cong Wang, Kunhua Liu, and Long Chen. 2024. Advdif- fuser: Generating adversarial safety-critical driving scenarios via guided diffusion. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 9983–9989
work page 2024
-
[57]
Chejian Xu, Aleksandr Petiushko, Ding Zhao, and Bo Li. 2025. Diffscene: Diffusion-based safety-critical scenario generation for autonomous vehicles. In Proceedings of the AAAI conference on artificial intelligence, Vol. 39. 8797–8805
work page 2025
-
[58]
Haotian Xue, Alexandre Araujo, Bin Hu, and Yongxin Chen. 2023. Diffusion- based adversarial sample generation for improved stealthiness and controllability. Advances in Neural Information Processing Systems36 (2023), 2894–2921
work page 2023
-
[59]
Koichiro Yamanaka, Ryutaroh Matsumoto, Keita Takahashi, and Toshiaki Fujii
-
[60]
Adversarial patch attacks on monocular depth estimation networks.IEEE Access8 (2020), 179094–179104
work page 2020
-
[61]
Yuanyuan Yuan, Shuai Wang, and Zhendong Su. 2023. Precise and generalized robustness certification for neural networks. In32nd USENIX Security Symposium (USENIX Security 23). 4769–4786
work page 2023
-
[62]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding Conditional Control to Text-to-Image Diffusion Models. InIEEE/CVF International Conference on Computer Vision (ICCV)
work page 2023
- [63]
-
[64]
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen
-
[65]
InEuropean Conference on Computer Vision
Genad: Generative end-to-end autonomous driving. InEuropean Conference on Computer Vision. Springer, 87–104
-
[66]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. 2025. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Haomin Zhuang, Yihua Zhang, and Sijia Liu. 2023. A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 2385–2392. A Generative AI Usage During the preparation of this paper, the authors used Google Gem- ini and Anthropic Claude for language refineme...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.