Recognition: no theorem link
SWE-Chain: Benchmarking Coding Agents on Chained Release-Level Package Upgrades
Pith reviewed 2026-05-15 02:24 UTC · model grok-4.3
The pith
Coding agents resolve an average of 44.8 percent of chained release-level package upgrades while preserving prior functionality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
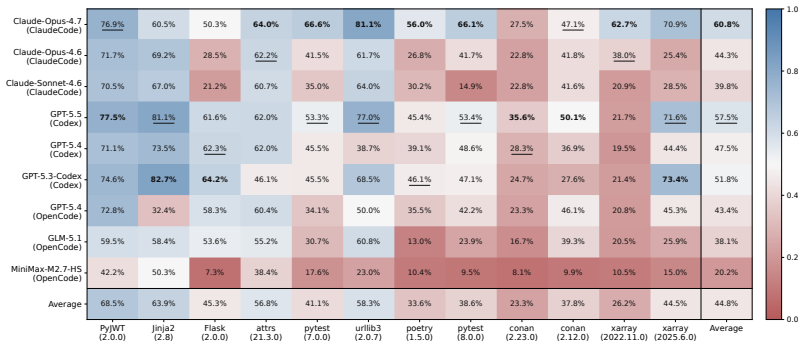
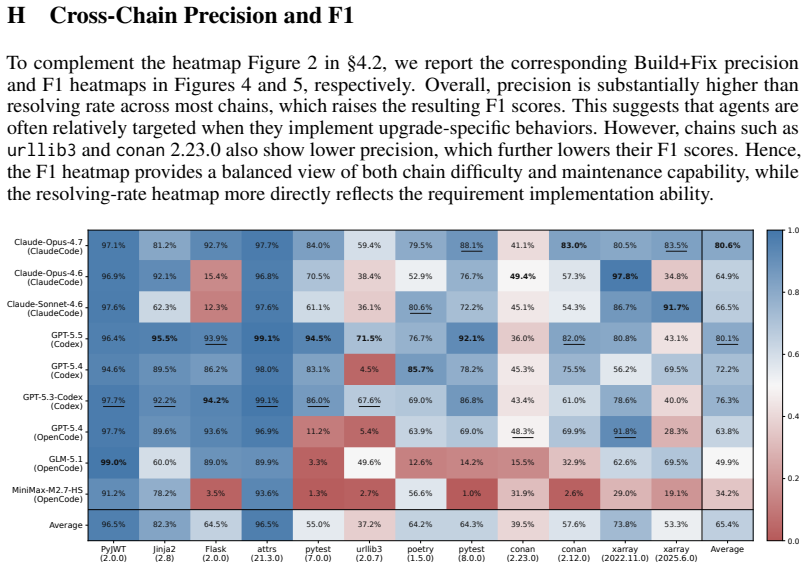
SWE-Chain contains 12 upgrade chains drawn from 9 real Python packages, covering 155 version transitions and 1,660 grounded requirements. In the Build+Fix regime agents reach an average resolving rate of 44.8 percent, precision of 65.4 percent, and F1 of 50.2 percent; Claude-Opus-4.7 leads with 60.8 percent resolving, 80.6 percent precision, and 68.5 percent F1. The benchmark is shown to be both feasible for agents to attempt and capable of distinguishing performance across configurations, while highlighting persistent struggles in executing correct upgrades across chained releases without breaking existing functionality.
What carries the argument
The divide-and-conquer synthesis pipeline that aligns release notes with code diffs to produce grounded upgrade specifications for each version transition.
Load-bearing premise
The synthesis pipeline creates upgrade specifications that reflect actual code changes and remain feasible for agents to implement without artificial simplifications.
What would settle it
Measuring whether the same nine agent configurations maintain resolving rates near 45 percent on a fresh collection of chained upgrades drawn from packages outside the original 12 chains.
Figures



read the original abstract
Coding agents powered by large language models are increasingly expected to perform realistic software maintenance tasks beyond isolated issue resolution. Existing benchmarks have shifted toward realistic software evolution, but they rarely capture continuous maintenance at the granularity of package releases, where changes are bundled, shipped, and inherited by subsequent versions. We present SWE-Chain, a benchmark for evaluating agents on chained release-level package upgrades, where each transition builds on the agent's prior codebase. To produce upgrade specifications, we design a divide-and-conquer synthesis pipeline that aligns release notes with code diffs for each version transition, ensuring the requirements are grounded in actual code changes, informative to agents, and feasible to implement. SWE-Chain contains 12 upgrade chains across 9 real Python packages, with 155 version transitions and 1,660 grounded upgrade requirements. Across nine frontier agent-model configurations, agents achieve an average of 44.8% resolving, 65.4% precision, and 50.2% F1 under the Build+Fix regime, with Claude-Opus-4.7 (Claude Code) leading at 60.8% resolving, 80.6% precision, and 68.5% F1. These results show that SWE-Chain is both feasible and discriminative, and reveal that current agents still struggle to make correct upgrades across chained package releases without breaking existing functionality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-Chain, a benchmark consisting of 12 upgrade chains across 9 real Python packages (155 version transitions, 1,660 grounded requirements) for evaluating LLM coding agents on chained release-level package upgrades. Upgrade specifications are produced via a divide-and-conquer synthesis pipeline that aligns release notes with code diffs. Across nine frontier agent-model configurations, the work reports average performance of 44.8% resolving rate, 65.4% precision, and 50.2% F1 under the Build+Fix regime, with Claude-Opus-4.7 leading at 60.8% resolving; the results are presented as evidence that current agents struggle with maintaining functionality across chained package releases.
Significance. If the synthesis pipeline and evaluation protocol are shown to be robust to cumulative state changes, the benchmark would provide a valuable, realistic testbed for continuous maintenance tasks that existing issue-resolution benchmarks do not capture. The concrete numbers across multiple agent configurations and the explicit chaining design are strengths that could help discriminate agent capabilities in realistic evolution scenarios.
major comments (3)
- [§3.2] §3.2 (Synthesis Pipeline): The divide-and-conquer alignment of release notes to diffs is performed independently per transition; the manuscript does not describe re-deriving or re-validating specifications against the agent-modified codebase after each step. This leaves open whether cumulative effects (renamed symbols, altered test expectations, import changes) are reflected in later specs, directly affecting the validity of the reported 44.8% resolving rate for chained tasks.
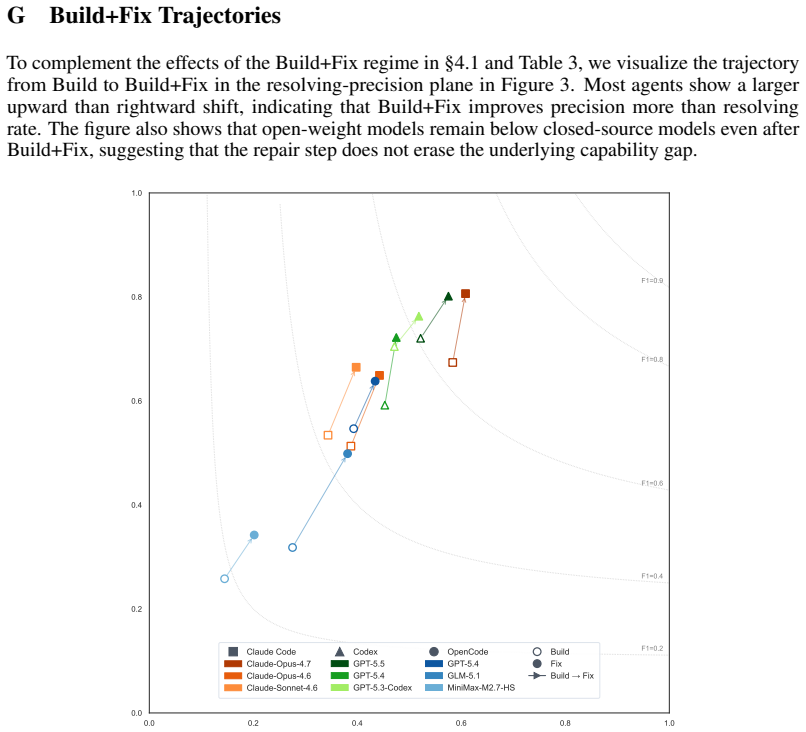
- [§4.3] §4.3 (Evaluation Protocol): The Build+Fix regime results treat each of the 155 transitions as an isolated task whose success is measured against the original release sequence. Without an ablation that replays the full chain from the agent's prior output and re-synthesizes requirements on the modified tree, it is unclear whether the 50.2% F1 understates or overstates real difficulty due to compounding errors.
- [Table 2] Table 2 / §5.1: The per-package breakdown shows substantial variance (e.g., some chains near 0% resolving). The manuscript does not report whether the synthesis pipeline's feasibility filter was applied uniformly or whether certain packages required manual post-processing that could affect cross-package claims.
minor comments (3)
- [§1] The abstract and §1 use 'grounded upgrade requirements' without a precise definition or example of how 'grounded' is operationalized beyond alignment; a short illustrative example in §3 would improve clarity.
- [Figure 3] Figure 3 (agent performance radar) lacks error bars or per-chain variance; adding these would help readers assess stability of the 60.8% Claude-Opus lead.
- [§2] The manuscript cites prior SWE-bench work but does not quantify how the 1,660 requirements differ in granularity or dependency structure from existing single-issue benchmarks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications on our design choices and commit to revisions that strengthen the manuscript's transparency regarding the synthesis pipeline, evaluation protocol, and per-package details.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Synthesis Pipeline): The divide-and-conquer alignment of release notes to diffs is performed independently per transition; the manuscript does not describe re-deriving or re-validating specifications against the agent-modified codebase after each step. This leaves open whether cumulative effects (renamed symbols, altered test expectations, import changes) are reflected in later specs, directly affecting the validity of the reported 44.8% resolving rate for chained tasks.
Authors: The specifications are synthesized once from the original release sequence to provide a fixed, reproducible ground truth grounded in actual code diffs and release notes. This design ensures consistency across all agent evaluations and avoids introducing agent-dependent variability into the requirements themselves. We acknowledge that this fixed approach does not automatically capture all cumulative effects from imperfect agent outputs. We will revise §3.2 to explicitly describe this choice, add a discussion of its implications for chained tasks, and note it as a limitation with suggestions for dynamic re-validation in future extensions. revision: yes
-
Referee: [§4.3] §4.3 (Evaluation Protocol): The Build+Fix regime results treat each of the 155 transitions as an isolated task whose success is measured against the original release sequence. Without an ablation that replays the full chain from the agent's prior output and re-synthesizes requirements on the modified tree, it is unclear whether the 50.2% F1 understates or overstates real difficulty due to compounding errors.
Authors: The primary results isolate each transition to measure the inherent difficulty of applying a specific upgrade while preserving functionality, with the chained aspect reflected in the benchmark's sequential structure. The Build+Fix regime already incorporates iterative correction based on build feedback. We agree that a full-chain replay ablation would better quantify compounding effects. We will add this ablation to the revised manuscript, replaying successful agent outputs through subsequent transitions and reporting the resulting performance delta. revision: yes
-
Referee: [Table 2] Table 2 / §5.1: The per-package breakdown shows substantial variance (e.g., some chains near 0% resolving). The manuscript does not report whether the synthesis pipeline's feasibility filter was applied uniformly or whether certain packages required manual post-processing that could affect cross-package claims.
Authors: The feasibility filter was applied uniformly across all 12 chains using the automated criteria in §3.2, with no manual post-processing or selective inclusion. All reported packages satisfied the filter without exception. We will revise §5.1 and the Table 2 caption to explicitly state the uniform application of the filter and confirm the absence of manual intervention. revision: yes
Circularity Check
No circularity: empirical benchmark grounded in external package histories
full rationale
The paper constructs SWE-Chain as an empirical benchmark using real release histories from 9 Python packages (155 transitions, 1660 requirements). Upgrade specifications are synthesized via a divide-and-conquer pipeline that aligns external release notes with actual code diffs; agent performance (44.8% resolving, 50.2% F1) is measured against those same external histories under Build+Fix. No derivations, fitted parameters, self-definitional equations, or load-bearing self-citations reduce any result to the paper's own inputs by construction. The evaluation remains falsifiable against independent package evolution data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude Code overview , author=
- [2]
- [3]
-
[4]
Xingyao Wang and Boxuan Li and Yufan Song and Frank F. Xu and Xiangru Tang and Mingchen Zhuge and Jiayi Pan and Yueqi Song and Bowen Li and Jaskirat Singh and Hoang H. Tran and Fuqiang Li and Ren Ma and Mingzhang Zheng and Bill Qian and Yanjun Shao and Niklas Muennighoff and Yizhe Zhang and Binyuan Hui and Junyang Lin and Robert Brennan and Hao Peng and H...
-
[5]
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=
-
[6]
arXiv preprint arXiv:2212.09420 , year=
Large Language Models Meet NL2Code: A Survey , author=. arXiv preprint arXiv:2212.09420 , year=
-
[7]
2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=
Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping , author=. 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=. 2025 , organization=
work page 2025
-
[8]
arXiv preprint arXiv:2412.15310 , year=
Mrweb: An exploration of generating multi-page resource-aware web code from ui designs , author=. arXiv preprint arXiv:2412.15310 , year=
-
[9]
arXiv preprint arXiv:2509.25297 , year=
Automatically Generating Web Applications from Requirements Via Multi-Agent Test-Driven Development , author=. arXiv preprint arXiv:2509.25297 , year=
-
[10]
arXiv preprint arXiv:2602.19276 , year=
ComUICoder: Component-based Reusable UI Code Generation for Complex Websites via Semantic Segmentation and Element-wise Feedback , author=. arXiv preprint arXiv:2602.19276 , year=
-
[11]
arXiv preprint arXiv:2506.06251 , year=
Designbench: A comprehensive benchmark for mllm-based front-end code generation , author=. arXiv preprint arXiv:2506.06251 , year=
-
[12]
arXiv preprint arXiv:2509.12159 , year=
Efficientuicoder: Efficient mllm-based ui code generation via input and output token compression , author=. arXiv preprint arXiv:2509.12159 , year=
-
[13]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Automated repair of programs from large language models , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
work page 2023
-
[14]
arXiv preprint arXiv:2411.02310 , year=
MdEval: Massively Multilingual Code Debugging , author=. arXiv preprint arXiv:2411.02310 , year=
-
[15]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Large language models are few-shot testers: Exploring llm-based general bug reproduction , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
work page 2023
-
[16]
Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models , author=. Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis , pages=
-
[17]
arXiv preprint arXiv:2310.02368 , year=
Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation , author=. arXiv preprint arXiv:2310.02368 , year=
-
[18]
Journal of Systems and Software , volume=
Pytester: Deep reinforcement learning for text-to-testcase generation , author=. Journal of Systems and Software , volume=
-
[19]
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
- [20]
- [21]
-
[22]
Practices and Challenges of Using GitHub Copilot: An Empirical Study , author=. 2023 , month=Apr, booktitle=
work page 2023
-
[23]
Transforming Software Development: Evaluating the Efficiency and Challenges of GitHub Copilot in Real-World Projects , author=. 2024 , journal=
work page 2024
-
[24]
Large Language Model-Based Agents for Software Engineering: A Survey , author=. 2024 , journal=
work page 2024
-
[25]
Codev-Bench: How Do LLMs Understand Developer-Centric Code Completion? , author=. 2024 , journal=
work page 2024
-
[26]
Chengxing Xie and Bowen Li and Chang Gao and He Du and Wai Lam and Difan Zou and Kai Chen , booktitle=. 2025 , pages=
work page 2025
-
[27]
Xia, Chunqiu Steven and Deng, Yinlin and Dunn, Soren and Zhang, Lingming , journal=. Demystifying. 2025 , doi=
work page 2025
-
[28]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Show Your Work: Scratchpads for Intermediate Computation with Language Models , author=. arXiv preprint arXiv:2112.00114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2305.05383 , year=
Code Execution with Pre-trained Language Models , author=. arXiv preprint arXiv:2305.05383 , year=
-
[30]
NExT: Teaching Large Language Models to Reason about Code Execution , author=. 2024 , journal=
work page 2024
-
[31]
Large Language Models as Code Executors: An Exploratory Study , author=. 2024 , journal=
work page 2024
-
[32]
Proceedings of the 40th International Conference on Machine Learning , pages=
LEVER: Learning to Verify Language-to-Code Generation with Execution , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , volume=
work page 2023
-
[33]
CodeScore: Evaluating Code Generation by Learning Code Execution , author=. 2024 , journal=
work page 2024
-
[34]
Khan, Mohammad Abdullah Matin and Bari, M Saiful and Do, Xuan Long and Wang, Weishi and Parvez, Md Rizwan and Joty, Shafiq. XC ode E val: An Execution-based Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol...
-
[35]
arXiv preprint arXiv:2111.02840 , year=
Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models , author=. arXiv preprint arXiv:2111.02840 , year=
-
[36]
arXiv preprint arXiv:2406.19783 , year=
NLPerturbator: Studying the Robustness of Code LLMs to Natural Language Variations , author=. arXiv preprint arXiv:2406.19783 , year=
-
[37]
arXiv preprint arXiv:2212.10264 , year=
ReCode: Robustness Evaluation of Code Generation Models , author=. arXiv preprint arXiv:2212.10264 , year=
-
[38]
arXiv preprint arXiv:2302.00438 , year=
On the Robustness of Code Generation Techniques: An Empirical Study on GitHub Copilot , author=. arXiv preprint arXiv:2302.00438 , year=
-
[39]
arXiv preprint arXiv:2302.12095 , year=
On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective , author=. arXiv preprint arXiv:2302.12095 , year=
-
[40]
Proceedings of the 45th International Conference on Software Engineering , pages=
CCTest: Testing and Repairing Code Completion Systems , author=. Proceedings of the 45th International Conference on Software Engineering , pages=. 2023 , isbn=
work page 2023
-
[41]
Reasoning Runtime Behavior of a Program with LLM: How Far Are We? , author=. 2024 , journal=
work page 2024
-
[42]
Forty-first International Conference on Machine Learning , year=
Do Large Code Models Understand Programming Concepts? Counterfactual Analysis for Code Predicates , author=. Forty-first International Conference on Machine Learning , year=
-
[43]
On Robustness of Prompt-based Semantic Parsing with Large Pre-trained Language Model: An Empirical Study on Codex , author=. arXiv preprint arXiv:2301.12868 , year=
-
[44]
Robustness, Security, Privacy, Explainability, Efficiency, and Usability of Large Language Models for Code , author=. 2024 , journal=
work page 2024
-
[45]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Two sides of the same coin: Exploiting the impact of identifiers in neural code comprehension , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
work page 2023
-
[46]
Code Comment Inconsistency Detection and Rectification Using a Large Language Model , author=. 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE) , year=. doi:10.1109/ICSE55347.2025.00035 , publisher=
-
[47]
arXiv preprint arXiv:2503.20197 , year=
Enhancing the Robustness of LLM-Generated Code: Empirical Study and Framework , author=. arXiv preprint arXiv:2503.20197 , year=
-
[48]
Backdooring Neural Code Search , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month=Jul, year=. doi:10.18653/v1/2023.acl-long.540 , pages=
-
[49]
You see what I want you to see: poisoning vulnerabilities in neural code search , author=. 2022 , isbn=. doi:10.1145/3540250.3549153 , booktitle=
-
[50]
Man Ho Lam and Chaozheng Wang and Jen-tse Huang and Michael Lyu , booktitle=. CodeCrash: Exposing
-
[51]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Is Your Code Generated by Chat
Jiawei Liu and Chunqiu Steven Xia and Yuyao Wang and Lingming Zhang , booktitle=. Is Your Code Generated by Chat
-
[54]
Measuring Coding Challenge Competence With APPS , author=. 2021 , journal=
work page 2021
-
[55]
CRUXEval: a benchmark for code reasoning, understanding and execution , year=
Gu, Alex and Rozi\`. CRUXEval: a benchmark for code reasoning, understanding and execution , year=. Proceedings of the 41st International Conference on Machine Learning , articleno=
-
[56]
The Thirteenth International Conference on Learning Representations , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. The Thirteenth International Conference on Learning Representations , year=
-
[57]
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=
-
[58]
arXiv preprint arXiv:2410.03859 , year=
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains? , author=. arXiv preprint arXiv:2410.03859 , year=
-
[59]
InfiBench: Evaluating the Question-Answering Capabilities of Code Large Language Models , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[60]
The Thirteenth International Conference on Learning Representations , year=
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[61]
International Conference on Learning Representations (ICLR) , year=
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems , author=. International Conference on Learning Representations (ICLR) , year=
-
[62]
EvoCodeBench: An Evolving Code Generation Benchmark with Domain-Specific Evaluations , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[63]
Shunyu Yao and Noah Shinn and Pedram Razavi and Karthik R Narasimhan , booktitle=. \ \
-
[64]
The Fourteenth International Conference on Learning Representations , year=
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces , author=. The Fourteenth International Conference on Learning Representations , year=
-
[65]
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts , author=. arXiv preprint arXiv:2601.11044 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
arXiv preprint arXiv:2512.12730 , year=
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents , author=. arXiv preprint arXiv:2512.12730 , year=
-
[67]
Vibe Code Bench: Evaluating AI Models on End-to-End Web Application Development , author=. 2026 , journal=
work page 2026
-
[68]
Introducing Claude Opus 4.6 , author=
-
[69]
Introducing Claude Sonnet 4.6 , author=
-
[70]
Introducing Claude Opus 4.7 , author=
- [71]
- [72]
- [73]
- [74]
-
[75]
MiniMax M2.7: Early Echoes of Self-Evolution , author=
-
[76]
Aider's polyglot benchmark , author=
-
[77]
Advances in Neural Information Processing Systems , volume=
Large language models are zero-shot reasoners , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
OverThink: Slowdown Attacks on Reasoning LLMs , author=. 2025 , journal=
work page 2025
-
[79]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs , author=. 2025 , journal=
work page 2025
-
[80]
Proceedings of the 27th International Conference on Computational Linguistics , year=
Stress Test Evaluation for Natural Language Inference , author=. Proceedings of the 27th International Conference on Computational Linguistics , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.