Recognition: 2 theorem links
· Lean TheoremRemember Your Trace: Memory-Guided Long-Horizon Agentic Framework for Consistent and Hierarchical Repository-Level Code Documentation
Pith reviewed 2026-05-15 01:34 UTC · model grok-4.3
The pith
MemDocAgent generates consistent hierarchical documentation for entire repositories by planning dependency order and consulting a shared memory of prior work traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
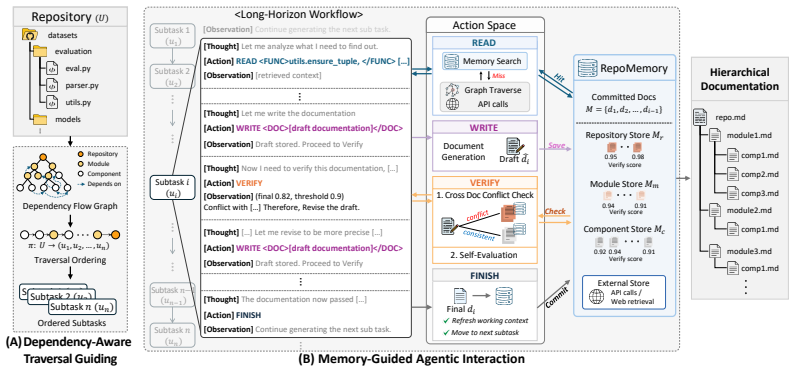
MemDocAgent produces consistent and hierarchical repository-level code documentation by combining Dependency-Aware Traversal Guiding, which fixes a processing sequence according to dependency and granularity relations, with Memory-Guided Agentic Interaction, in which the agent continually updates and consults RepoMemory, a shared store of prior documentation traces accessed through read, write, and verify operations.
What carries the argument
RepoMemory, the shared memory that accumulates documentation traces through read, write, and verify operations, together with the predetermined Dependency-Aware Traversal Guiding that orders processing by code dependencies and granularity.
If this is right
- Each new document references the accumulated traces, eliminating redundant retrieval of the same code elements.
- The fixed traversal order imposes a natural hierarchy that reflects the repository's dependency structure.
- Conflicts between documents are reduced because the agent verifies against prior traces before writing.
- The single integrated context allows the framework to scale to large repositories while maintaining coherence across files.
Where Pith is reading between the lines
- The same memory mechanism could support other long-horizon repository tasks such as incremental refactoring or test generation by reusing traces across sessions.
- Repositories with cyclic dependencies or unclear module boundaries may still require human review to resolve ordering choices the traversal cannot decide automatically.
- Embedding the agent inside an IDE would let documentation update automatically when code changes, turning the memory store into a living project log.
Load-bearing premise
That the dependency-guided traversal and repeated interactions with the shared memory will keep new documents free of conflicts and will produce a natural hierarchy without extensive manual repair.
What would settle it
Apply MemDocAgent and an independent baseline to the same repositories and measure whether the memory-guided outputs contain more conflicting statements or less hierarchical structure than the baseline outputs.
Figures






read the original abstract
Automated code documentation is essential for modern software development, providing the contextual grounding that both human developers and coding agents rely on to navigate large codebases. Existing repository-level approaches process components independently, causing redundant retrieval and conflicting descriptions across documents while producing outputs that lack hierarchical structure. Therefore, we propose MemDocAgent, a long-horizon agentic framework that generates documentation within a single, integrated context spanning the entire repository. It combines two components: (i) Dependency-Aware Traversal Guiding that predetermines a traversal order respecting dependency and granularity hierarchies; (ii) Memory-Guided Agentic Interaction, in which the agent interacts with RepoMemory, a shared memory accumulating prior work traces through read, write, and verify operations. Through an in-depth multi-criteria evaluation, MemDocAgent achieves the best performance over both open and closed-source baselines and demonstrates practical applicability in real software development workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MemDocAgent, a long-horizon agentic framework for repository-level code documentation. It addresses limitations of independent component processing by combining (i) Dependency-Aware Traversal Guiding to predetermine a traversal order that respects dependency and granularity hierarchies and (ii) Memory-Guided Agentic Interaction in which an agent performs read, write, and verify operations on a shared RepoMemory that accumulates prior documentation traces. An in-depth multi-criteria evaluation is presented claiming that MemDocAgent outperforms both open-source and closed-source baselines while showing practical applicability in real software development workflows.
Significance. If the reported performance gains and consistency improvements hold under scrutiny, the work could meaningfully advance automated documentation for large codebases by reducing redundant retrieval, conflicting descriptions, and lack of hierarchy. The memory-guided agentic approach for long-horizon tasks offers a reusable pattern that may influence future systems for repository-scale software engineering tasks involving both human developers and coding agents.
major comments (2)
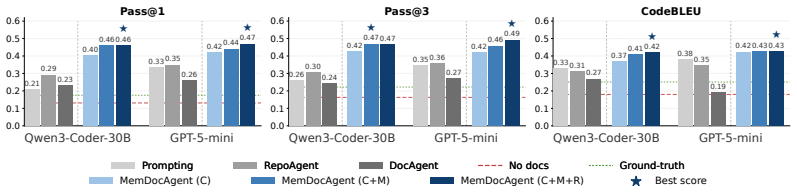
- [§4] §4 (Evaluation): The central claim of best performance over baselines rests on a multi-criteria evaluation, yet the section supplies no concrete numerical metrics, baseline configurations, dataset statistics (repository sizes, languages, number of files), or statistical significance tests. Without these, the outperformance assertion cannot be independently verified and remains load-bearing for the paper's contribution.
- [§3.2] §3.2 (Memory-Guided Agentic Interaction): The description of RepoMemory read/write/verify operations does not specify how conflicts are detected or resolved when new traces are written, nor how the verify step enforces hierarchical consistency across the full repository traversal. This leaves the weakest assumption—that the mechanism reliably produces conflict-free hierarchical output—unaddressed in the core technical contribution.
minor comments (2)
- [Abstract] Abstract: The performance claims would be more persuasive if at least one key quantitative result (e.g., a specific metric improvement) were included to ground the superiority statement.
- [Figures/Tables] Figure captions and tables: Ensure all figures and tables are self-contained with explicit axis labels, legend definitions, and units so that the multi-criteria results can be interpreted without reference to the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to incorporate additional details and clarifications as requested.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The central claim of best performance over baselines rests on a multi-criteria evaluation, yet the section supplies no concrete numerical metrics, baseline configurations, dataset statistics (repository sizes, languages, number of files), or statistical significance tests. Without these, the outperformance assertion cannot be independently verified and remains load-bearing for the paper's contribution.
Authors: We agree that the original §4 lacked the quantitative details needed for independent verification. In the revised manuscript we have expanded the evaluation section with concrete tables reporting all multi-criteria metrics (consistency, coverage, accuracy, and human preference scores), explicit baseline configurations (model versions, temperature, retrieval settings), dataset statistics (10 repositories, 50–500 files each, Python and Java), and statistical significance results (Wilcoxon signed-rank tests, p < 0.01). These additions directly support the performance claims. revision: yes
-
Referee: [§3.2] §3.2 (Memory-Guided Agentic Interaction): The description of RepoMemory read/write/verify operations does not specify how conflicts are detected or resolved when new traces are written, nor how the verify step enforces hierarchical consistency across the full repository traversal. This leaves the weakest assumption—that the mechanism reliably produces conflict-free hierarchical output—unaddressed in the core technical contribution.
Authors: We thank the referee for highlighting this gap. The revised §3.2 now specifies that conflicts are detected via semantic similarity thresholds on hierarchical paths during write operations; resolution merges descriptions by prioritizing higher-granularity or more recent traces and records the merge in the trace log. The verify step enforces consistency by traversing the full dependency graph after each write and re-generating any child document whose summary diverges from its parent or siblings. These mechanisms are now explicitly described. revision: yes
Circularity Check
No significant circularity in framework proposal or empirical evaluation
full rationale
The paper presents MemDocAgent as an agentic framework with two explicitly described components (Dependency-Aware Traversal Guiding and Memory-Guided interaction with RepoMemory) whose claimed benefits are supported by a multi-criteria empirical comparison against open- and closed-source baselines. No equations, fitted parameters, or first-principles derivations appear; the traversal order and memory read/write/verify operations are defined directly by the framework design rather than being derived from or reduced to any self-referential quantities. No self-citations are used to justify uniqueness theorems or ansatzes, and the evaluation is externally falsifiable via the reported metrics on repository-level documentation tasks. The work is therefore self-contained against external benchmarks with no load-bearing steps that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An agent interacting via read, write, and verify operations on shared memory will produce consistent documentation across repository components.
invented entities (2)
-
RepoMemory
no independent evidence
-
Dependency-Aware Traversal Guiding
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dependency-Aware Traversal Guiding that predetermines a traversal order respecting dependency and granularity hierarchies
-
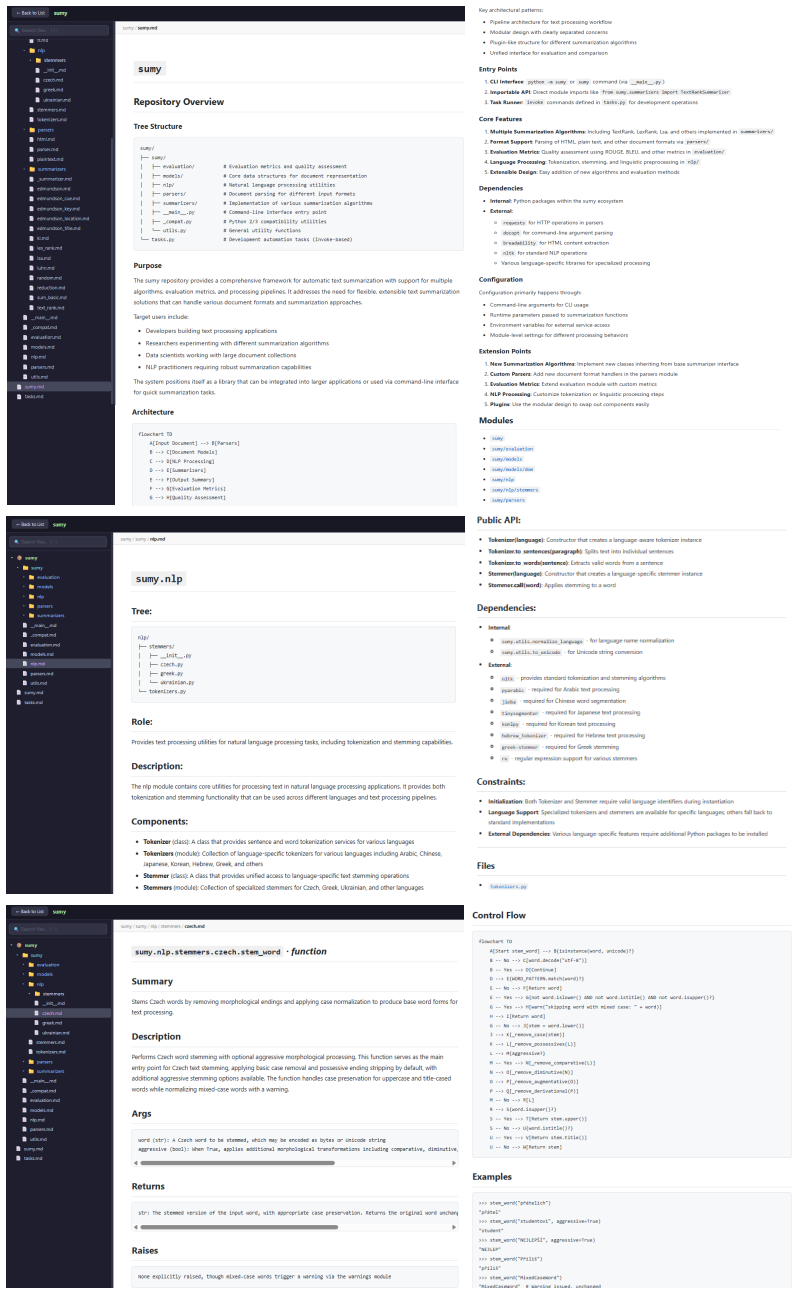
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Memory-Guided Agentic Interaction... RepoMemory... read, write, and verify operations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DocAgent: A multi-agent system for automated code documentation generation
Dayu Yang, Antoine Simoulin, Xin Qian, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, and Grey Yang. DocAgent: A multi-agent system for automated code documentation generation. In Pushkar Mishra, Smaranda Muresan, and Tao Yu, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) (Volume 3: System Demonstrations), pages...
work page 2025
-
[2]
CodeWiki: Evaluating AI's Ability to Generate Holistic Documentation for Large-Scale Codebases
Anh Nguyen Hoang, Minh Le-Anh, Bach Le, and Nghi DQ Bui. Codewiki: Evaluating ai’s ability to generate holistic documentation for large-scale codebases.arXiv preprint arXiv:2510.24428, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
RepoAgent: An LLM-powered open-source framework for repository-level code documentation generation
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, Xiaoyin Che, Zhiyuan Liu, and Maosong Sun. RepoAgent: An LLM-powered open-source framework for repository-level code documentation generation. In Delia Irazu Hernandez Farias, Tom Hope, and Manling Li, editors,Proceedings of the 2024 Conferen...
work page 2024
-
[4]
Precise documentation: The key to better software
David Lorge Parnas. Precise documentation: The key to better software. InThe Future of Soft- ware Engineering, 2010. URLhttps://api.semanticscholar.org/CorpusID:38934599
work page 2010
-
[5]
Golara Garousi, Vahid Garousi-Yusifo˘glu, Guenther Ruhe, Junji Zhi, Mahmoud Moussavi, and Brian Smith. Usage and usefulness of technical software documentation: An industrial case study.Information and Software Technology, 57:664–682, 2015. ISSN 0950-5849. doi: https://doi.org/10.1016/j.infsof.2014.08.003. URL https://www.sciencedirect.com/ science/articl...
-
[6]
Ai-driven chatbot as a support tool for developers during the onboarding process
Lea Katalina Kivinen. Ai-driven chatbot as a support tool for developers during the onboarding process. 2023
work page 2023
-
[7]
Software engineering (extended abstract) an unconsummated marriage
David Lorge Parnas. Software engineering (extended abstract) an unconsummated marriage. ACM SIGSOFT Software Engineering Notes, 22(6):1–3, 1997
work page 1997
-
[8]
The relevance of software documentation, tools and technologies: a survey
Andrew Forward and Timothy C Lethbridge. The relevance of software documentation, tools and technologies: a survey. InProceedings of the 2002 ACM symposium on Document engineering, pages 26–33, 2002
work page 2002
-
[9]
A study of the docu- mentation essential to software maintenance
Sergio Cozzetti B De Souza, Nicolas Anquetil, and Káthia M De Oliveira. A study of the docu- mentation essential to software maintenance. InProceedings of the 23rd annual international conference on Design of communication: documenting & designing for pervasive information, pages 68–75, 2005
work page 2005
-
[10]
Emad Aghajani, Csaba Nagy, Olga Lucero Vega-Márquez, Mario Linares-Vásquez, Laura Moreno, Gabriele Bavota, and Michele Lanza. Software documentation issues unveiled.2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pages 1199–1210,
work page 2019
-
[11]
URLhttps://api.semanticscholar.org/CorpusID:174800564
-
[12]
Cost, benefits and quality of software development documentation: A systematic mapping
Junji Zhi, Vahid Garousi-Yusifo˘glu, Bo Sun, Golara Garousi, Shawn Shahnewaz, and Guenther Ruhe. Cost, benefits and quality of software development documentation: A systematic mapping. Journal of Systems and Software, 99:175–198, 2015
work page 2015
-
[13]
Xin Xia, Lingfeng Bao, David Lo, Zhenchang Xing, Ahmed E Hassan, and Shanping Li. Mea- suring program comprehension: A large-scale field study with professionals.IEEE Transactions on Software Engineering, 44(10):951–976, 2017
work page 2017
-
[14]
DeepWiki.https://deepwiki.com/, 2025
Cognition AI. DeepWiki.https://deepwiki.com/, 2025
work page 2025
-
[15]
Claude Code.https://www.anthropic.com/claude-code, 2025
Anthropic. Claude Code.https://www.anthropic.com/claude-code, 2025
work page 2025
-
[16]
Evalu- ating usage and quality of technical software documentation: an empirical study
Golara Garousi, Vahid Garousi, Mahmoud Moussavi, Guenther Ruhe, and Brian Smith. Evalu- ating usage and quality of technical software documentation: an empirical study. InProceedings of the 17th international conference on evaluation and assessment in software engineering, pages 24–35, 2013. 10
work page 2013
-
[17]
arXiv preprint arXiv:2503.09572 , year =
Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anu- manchipalli, Kurt Keutzer, and Amir Gholami. Plan-and-act: Improving planning of agents for long-horizon tasks.arXiv preprint arXiv:2503.09572, 2025
-
[18]
Swe-agent: Agent-computer interfaces enable automated software engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[19]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13643–13658, 2024
work page 2024
-
[21]
Huy Nhat Phan, Tien N Nguyen, Phong X Nguyen, and Nghi DQ Bui. Hyperagent: Generalist software engineering agents to solve coding tasks at scale.arXiv preprint arXiv:2409.16299, 2024
-
[22]
Repairagent: An autonomous, llm-based agent for program repair
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. Repairagent: An autonomous, llm-based agent for program repair. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 2188–2200. IEEE, 2025
work page 2025
-
[23]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Haotian Luo, Huaisong Zhang, Xuelin Zhang, Haoyu Wang, Zeyu Qin, Wenjie Lu, Guozheng Ma, Haiying He, Yingsha Xie, Qiyang Zhou, et al. Ultrahorizon: Benchmarking agent capabili- ties in ultra long-horizon scenarios.arXiv preprint arXiv:2509.21766, 2025
-
[25]
Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, et al. Agentfold: Long-horizon web agents with proactive context management.arXiv preprint arXiv:2510.24699, 2025
-
[26]
Shukai Liu, Jian Yang, Bo Jiang, Yizhi Li, Jinyang Guo, Xianglong Liu, and Bryan Dai. Context as a tool: Context management for long-horizon swe-agents.arXiv preprint arXiv:2512.22087, 2025
-
[27]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[28]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[29]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[30]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
work page 2024
-
[31]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024. 11
work page 2024
-
[32]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. doi: 10.1162/tacl_a_00638. URLhttps://aclanthology.org/2024.tacl-1.9/
-
[33]
The illusion of diminishing returns: Measuring long horizon execution in LLMs
Akshit Sinha, Arvindh Arun, Shashwat Goel, Steffen Staab, and Jonas Geiping. The illusion of diminishing returns: Measuring long horizon execution in LLMs. InThe Fourteenth Inter- national Conference on Learning Representations, 2026. URL https://openreview.net/ forum?id=3lm8lWYxiq
work page 2026
-
[34]
Guangya Wan, Mingyang Ling, Xiaoqi Ren, Rujun Han, Sheng Li, and Zizhao Zhang. Compass: Enhancing agent long-horizon reasoning with evolving context.arXiv preprint arXiv:2510.08790, 2025
-
[35]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[36]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gon- zalez. Memgpt: Towards llms as operating systems.CoRR, abs/2310.08560, 2023. URL https://doi.org/10.48550/arXiv.2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[37]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024
work page 2024
-
[39]
Bernal J Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobio- logically inspired long-term memory for large language models.Advances in neural information processing systems, 37:59532–59569, 2024
work page 2024
-
[40]
A-mem: Agentic memory for llm agents.Advances in Neural Information Processing Systems, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.Advances in Neural Information Processing Systems, 2025
work page 2025
-
[41]
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large lan- guage model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32779–32798, 2025
work page 2025
-
[42]
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Xinmiao Yu, Dingchu Zhang, Yong Jiang, et al. Resum: Unlocking long-horizon search intelligence via context summarization.arXiv preprint arXiv:2509.13313, 2025
-
[43]
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon llm agents.arXiv preprint arXiv:2510.00615, 2025
-
[44]
Mo Li, LH Xu, Qitai Tan, Long Ma, Ting Cao, and Yunxin Liu. Sculptor: Empowering llms with cognitive agency via active context management.arXiv preprint arXiv:2508.04664, 2025
-
[45]
Automatic generation of natural language summaries for java classes
Laura Moreno, Jairo Aponte, Giriprasad Sridhara, Andrian Marcus, Lori Pollock, and K Vijay- Shanker. Automatic generation of natural language summaries for java classes. In2013 21st International conference on program comprehension (ICPC), pages 23–32. IEEE, 2013
work page 2013
-
[46]
Summarizing source code using a neural attention model
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. Summarizing source code using a neural attention model. In Katrin Erk and Noah A. Smith, editors,Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2073–2083, Berlin, Germany, August 2016. Association for Computational ...
-
[47]
Recommendations for datasets for source code summarization
Alexander LeClair and Collin McMillan. Recommendations for datasets for source code summarization. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3931–3937, 2019
work page 2019
-
[48]
Yunseok Choi, Cheolwon Na, Hyojun Kim, and Jee-Hyong Lee. Readsum: retrieval-augmented adaptive transformer for source code summarization.IEEE Access, 11:51155–51165, 2023
work page 2023
-
[49]
Bibek Poudel, Adam Cook, Sekou Traore, and Shelah Ameli. Documint: Docstring generation for python using small language models.arXiv preprint arXiv:2405.10243, 2024
-
[50]
Automatic code documentation generation using gpt-
Junaed Younus Khan and Gias Uddin. Automatic code documentation generation using gpt-
-
[51]
InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, pages 1–6, 2022
work page 2022
-
[52]
ProConSuL: Project context for code summarization with LLMs
Vadim Lomshakov, Andrey Podivilov, Sergey Savin, Oleg Baryshnikov, Alena Lisevych, and Sergey Nikolenko. ProConSuL: Project context for code summarization with LLMs. In Franck Dernoncourt, Daniel Preo¸ tiuc-Pietro, and Anastasia Shimorina, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages...
-
[53]
Code summarization beyond function level
Vladimir Makharev and Vladimir Ivanov. Code summarization beyond function level. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code), pages 153–160. IEEE, 2025
work page 2025
-
[54]
Mingyang Geng, Shangwen Wang, Dezun Dong, Haotian Wang, Ge Li, Zhi Jin, Xiaoguang Mao, and Xiangke Liao. Large language models are few-shot summarizers: Multi-intent comment generation via in-context learning. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, pages 1–13, 2024
work page 2024
-
[55]
Automatic semantic augmentation of language model prompts (for code summarization)
Toufique Ahmed, Kunal Suresh Pai, Premkumar Devanbu, and Earl Barr. Automatic semantic augmentation of language model prompts (for code summarization). InProceedings of the IEEE/ACM 46th international conference on software engineering, pages 1–13, 2024
work page 2024
-
[56]
Code needs comments: Enhancing code llms with comment augmentation
Demin Song, Honglin Guo, Yunhua Zhou, Shuhao Xing, Yudong Wang, Zifan Song, Wenwei Zhang, Qipeng Guo, Hang Yan, Xipeng Qiu, et al. Code needs comments: Enhancing code llms with comment augmentation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13640–13656, 2024
work page 2024
-
[57]
Rethinking-based code summarization with chain of comments
Liuwen Cao, Hongkui He, Hailin Huang, Jiexin Wang, and Yi Cai. Rethinking-based code summarization with chain of comments. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages 3043–3056, Abu Dhabi, UAE, Janua...
work page 2025
-
[58]
Philippe Laban, Tobias Schnabel, Paul N Bennett, and Marti A Hearst. Summac: Re-visiting nli-based models for inconsistency detection in summarization.Transactions of the Association for Computational Linguistics, 10:163–177, 2022
work page 2022
-
[59]
Alessandro Scirè, Karim Ghonim, and Roberto Navigli. Fenice: Factuality evaluation of summarization based on natural language inference and claim extraction. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14148–14161, 2024
work page 2024
-
[60]
FIZZ: Factual in- consistency detection by zoom-in summary and zoom-out document
Joonho Yang, Seunghyun Yoon, ByeongJeong Kim, and Hwanhee Lee. FIZZ: Factual in- consistency detection by zoom-in summary and zoom-out document. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 30–45, Miami, Florida, USA, November
work page 2024
-
[61]
doi: 10.18653/v1/2024.emnlp-main.3
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.3. URL https://aclanthology.org/2024.emnlp-main.3/. 13
-
[62]
Suyoung Bae, CheolWon Na, Jaehoon Lee, Yumin Lee, YunSeok Choi, and Jee-Hyong Lee. Referee: Reference-free and fine-grained method for evaluating factual consistency in real-world code summarization.arXiv preprint arXiv:2604.10520, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Proc...
-
[64]
DevEval: A manually-annotated code generation benchmark aligned with real-world code repositories
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, Jiazheng Ding, Xuanming Zhang, Yuqi Zhu, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, Yongbin Li, Bin Gu, and Mengfei Yang. DevEval: A manually-annotated code generation benchmark aligned with real-world code repositories. In Lun-Wei Ku, Andre Ma...
-
[65]
Robert Tarjan. Depth-first search and linear graph algorithms.SIAM journal on computing, 1 (2):146–160, 1972. 14 A Additional details about MemDocAgent A.1 Algorithms of dependency-aware traversal guiding Algorithm 1 describes dependency graph construction, and Algorithm 2 presents the topological traversal used for hierarchical generation. Algorithm 1Bui...
work page 1972
-
[66]
Focus on the big picture, not implementation details
REPO : Repository-level Documentation: - Brief introduction and purpose of the overall system - Architecture overview with diagrams - High-level functionality of each sub-module including references to its documentation file - Link to other module documentation instead of duplicating information - Do not duplicate content covered in MODULE or COMPONENT do...
-
[67]
MODULE: Module-level Documentation: - Explanation of the module’s role within the system and its internal design, so a developer can understand *how* its components fit together before reading individual component details - Responsibility and boundaries of the module - List of core components with a one-line description each - Component interaction diagra...
-
[68]
COMPONENT: Component-level Documentation: - Providing enough detail to *reimplement* the function, method, or class correctly — covering inputs, outputs, behavior, edge cases, and constraints - Summary of what the component does and why it exists (not how it works) </DOCUMENTATION_STRUCTURE> <WORKFLOW>
-
[69]
You will first receive a sub-task, which includes the type of task (COMPONENT, MODULE, or REPO), the target component/module/repo to document, and other relevant information
-
[70]
Analyze the provided code components or module structure, explore the not given dependencies between the components if needed
-
[71]
For COMPONENT tasks, generate the documentation for the specific component, and save the documentation in memory with the name of ‘component_id’
-
[72]
For MODULE tasks, synthesize the documentations of sub-components and generate the module-level documentation, and save the documentation in memory with the name of ‘module_id’
-
[73]
For REPO tasks, synthesize the documentations of all modules and generate the repository-level documentation, and save the documentation in memory with the name of ‘repo_id’
-
[74]
For each task, you perform thought-action-observation loops to iteratively improve the documentation until it passes verification, then save the final documentation to memory and return. - At every turn, you MUST follow this structure: Thought:〈your reasoning about what to do next, what information you need〉 Action: Choose exactly one action from the list...
-
[75]
READ:If you think more information is needed to generate high-quality documentation of the target component, use this action to request relevant information. - During think step, you should analyze the current code and context, and explain what additional information might be needed (if any) - You have access to three types of information sources:
-
[76]
Sub-components or sub-modules (from memory): - If the target is a MODULE or REPO, you can request the documentation of its sub-components or sub-modules that have already been documented from memory. - This is the primary source of information for MODULE and REPO tasks, since the module/repo-level documentation should be synthesized based on the already g...
-
[77]
Internal Codebase Information (from local code repository): For Functions: - Code components called within the function body - Places where this function is called For Methods: - Code components called within the method body - Places where this method is called - The class this method belongs to For Classes: - Code components called in the __init__ method...
-
[78]
External Open Internet retrieval Information: - External Retrieval is extremely expensive. Only request it when understanding an external third-party API or library is essential for accurate documentation, and that information cannot be found within the target codebase. - Use the import statements in <IMPORT_INFORMATION_IN_THE_FILE> to identify candidates...
-
[79]
""Reads a file and returns its content as a list of lines
WRITE:If you think you have collected sufficient context, use this action and generate the documentation for the target task type. - General guidelines for high-quality documentation: - Make documentations actionable and specific: Focus on practical usage. - Use clear, concise language: Avoid jargon unless necessary, use active voice, and be direct and sp...
-
[80]
VERIFY:After generating a documentation, use this action to self-evaluate the documentation quality along three criteria, each scored from 0.00 to 1.00 (two decimal places). - Verification Process: - First read the target task information (source code and related information) as if you’re seeing it for the first time. - Read the generated documentation an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.