UMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
Pith reviewed 2026-06-30 19:37 UTC · model grok-4.3
The pith
UMo unifies text, audio and motion tokens with sparse experts to generate real-time co-speech avatar animations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
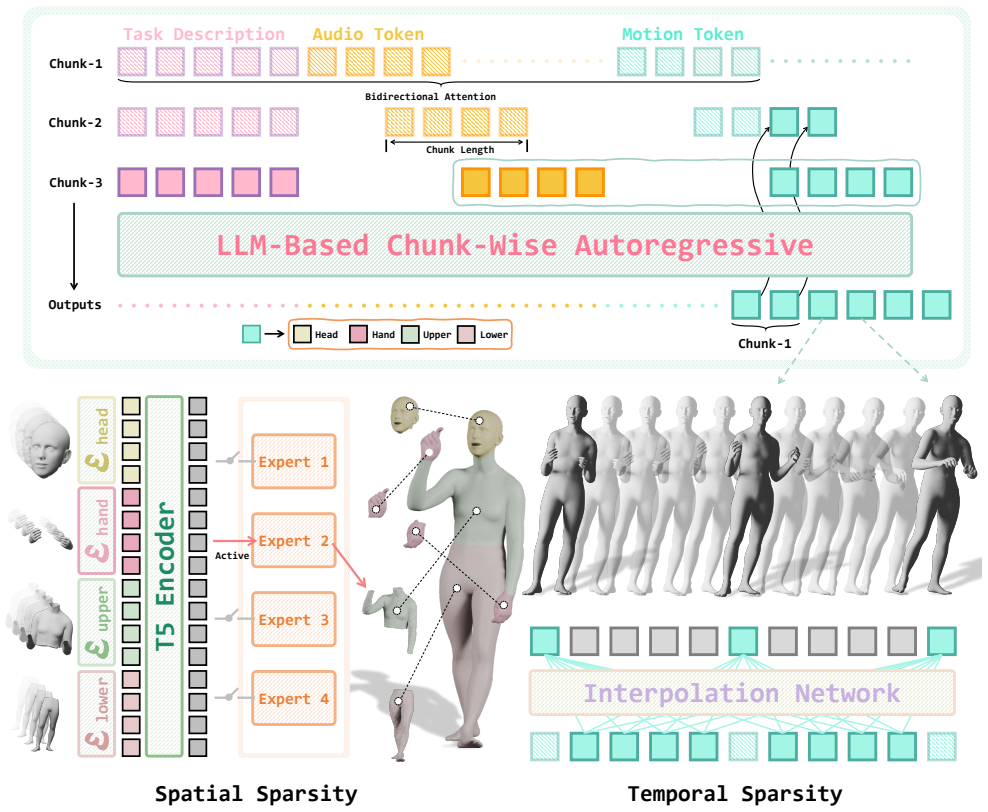
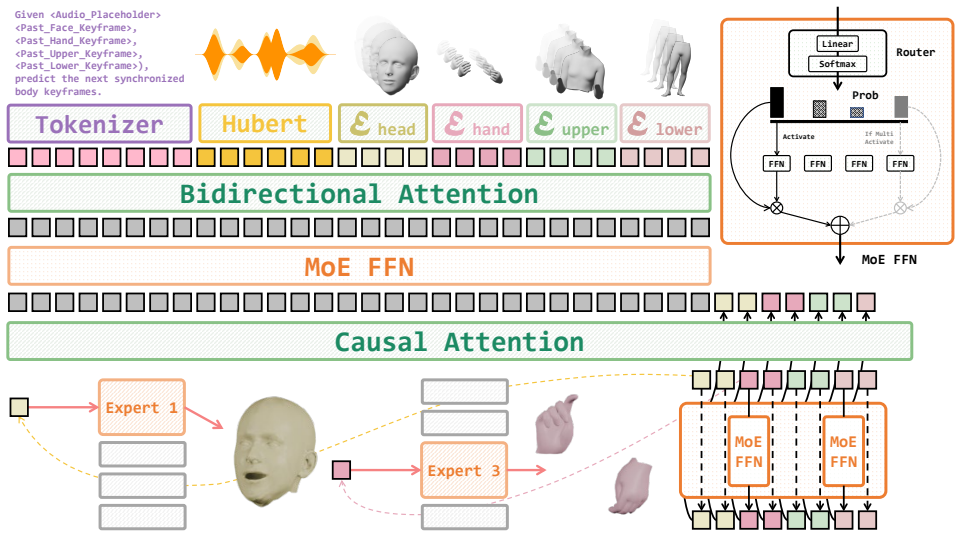
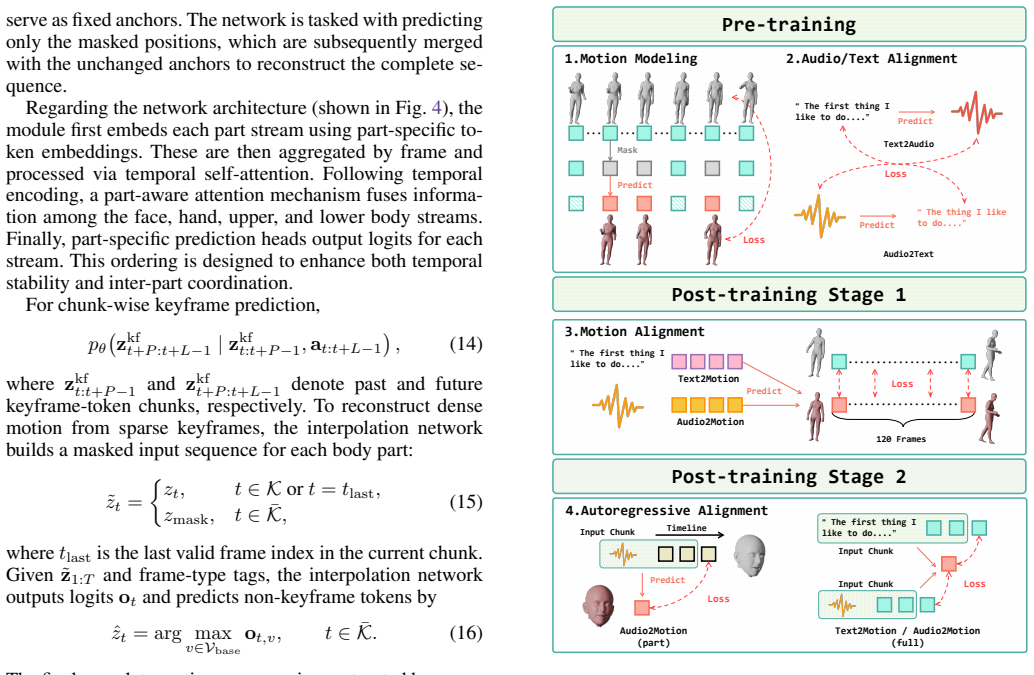
UMo processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. A multi-stage training strategy with targeted audio augmentation enhances acoustic diversity and semantic consistency, preserving fine-grained speech-motion alignment even under strict latency constraints.
What carries the argument
Unified sparse motion modeling architecture that combines a spatially sparse Mixture-of-Experts framework with a temporally sparse keyframe-centric design for processing text, audio and motion tokens.
If this is right
- Real-time dense reconstruction of facial and gesture motion becomes feasible from multimodal inputs.
- Multi-stage training with audio augmentation improves semantic consistency between speech and generated motion.
- Spatially and temporally sparse components together reduce computational load while maintaining coherence.
- The same architecture supports both facial expressions and full-body gestures without separate pipelines.
Where Pith is reading between the lines
- The approach may allow single-model deployment across different avatar platforms that vary in frame rate or compute budget.
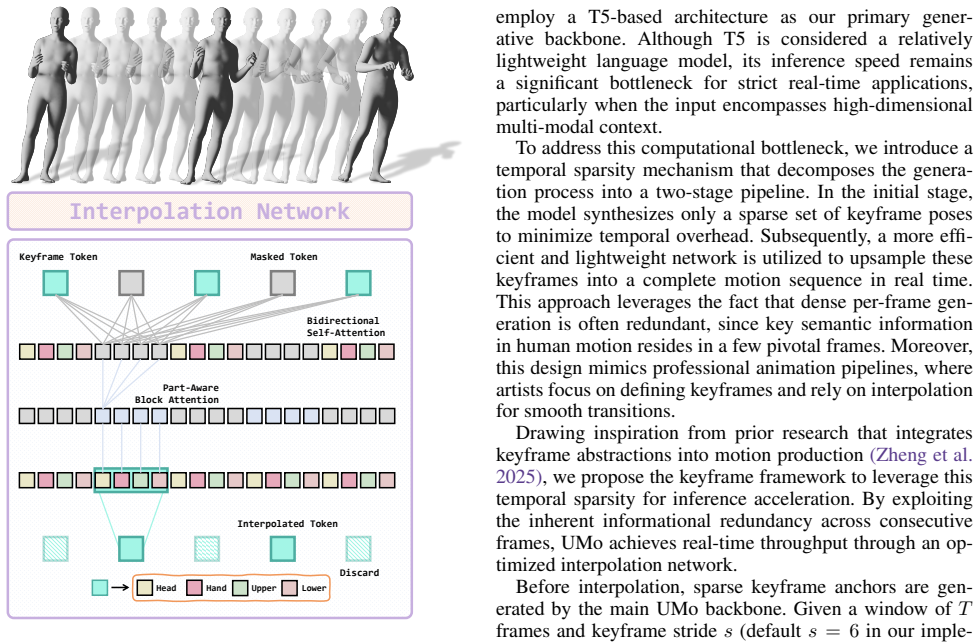
- Keyframe sparsity could be adjusted at inference time to trade quality for even lower latency in specific applications.
- Because the model ingests text alongside audio, it may support scripted or edited speech tracks without retraining.
- The sparse design might reduce memory footprint enough to run on edge devices for mobile or AR use cases.
Load-bearing premise
A spatially sparse Mixture-of-Experts combined with a temporally sparse keyframe-centric design can preserve fine-grained speech-motion alignment and temporal coherence without full dense per-frame modeling or extra post-processing.
What would settle it
Side-by-side comparison at fixed low latency showing that UMo outputs lose measurable alignment with audio or temporal smoothness compared with a dense baseline model on the same test sequences.
Figures



read the original abstract
Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents UMo, a unified sparse motion modeling architecture for real-time co-speech avatars. It processes text, audio, and motion tokens within a single formulation, employing a spatially sparse Mixture-of-Experts framework together with a temporally sparse keyframe-centric design to perform real-time dense reconstruction of facial expressions and gestures. A multi-stage training strategy incorporating targeted audio augmentation is used to improve acoustic diversity and semantic consistency. The central claim is that this approach preserves fine-grained speech-motion alignment under strict latency constraints and delivers superior output quality relative to prior methods while satisfying real-time performance requirements, as supported by extensive quantitative and qualitative evaluations.
Significance. If the empirical claims are substantiated by the reported evaluations, the work would offer a practical advance for high-fidelity real-time co-speech avatars in games, virtual production, and interactive media. The combination of spatial and temporal sparsity to achieve dense, coherent animation without full per-frame modeling or post-processing addresses a key efficiency-quality trade-off in multimodal motion generation.
minor comments (2)
- [Abstract] Abstract: the claim of 'better output quality under low latency and real-time performance constraints' is stated without any numerical results, baselines, or protocol details; including at least the primary quantitative metrics (e.g., FID, beat alignment error, latency in ms) would strengthen immediate readability.
- The multi-stage training procedure and audio-augmentation strategy are described at a high level; a concise diagram or pseudocode listing the stages and loss terms would clarify how semantic consistency is enforced.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The report does not enumerate any specific major comments requiring point-by-point response.
Circularity Check
No significant circularity; empirical architecture with no derivation chain
full rationale
The paper describes a neural architecture (spatially sparse MoE + temporally sparse keyframes), multi-stage training, and empirical evaluations. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text. The central claims rest on quantitative/qualitative results rather than any step that reduces to its own inputs by construction. This is the expected outcome for an applied ML systems paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MoGeFlow: Flowing Through Motion Codebook Geometry for Text-to-Motion Generation
MoGeFlow learns text-conditioned flows over PartVQ group-specific code embeddings to generate motions, achieving SOTA R-Precision on HumanML3D and KIT-ML while preserving discrete token validity.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Alexanderson, S.; Nagy, R.; Beskow, J.; and Henter, G. E. 2023. Listen, denoise, action! audio-driven motion synthesis with diffusion models. ACM Transactions on Graphics (TOG), 42(4): 1--20
2023
-
[4]
Ao, T.; Gao, Q.; Lou, Y.; Chen, B.; and Liu, L. 2022. Rhythmic gesticulator: Rhythm-aware co-speech gesture synthesis with hierarchical neural embeddings. ACM Transactions on Graphics (TOG), 41(6): 1--19
2022
-
[5]
Ao, T.; Zhang, Z.; and Liu, L. 2023. Gesturediffuclip: Gesture diffusion model with clip latents. ACM Transactions on Graphics (TOG), 42(4): 1--18
2023
-
[6]
Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [7]
-
[8]
Chen, B.; Li, Y.; Ding, Y.-X.; Shao, T.; and Zhou, K. 2024 a . Enabling synergistic full-body control in prompt-based co-speech motion generation. In Proceedings of the 32nd ACM International Conference on Multimedia, 6774--6783
2024
-
[9]
K.; Fang, Y.; Shao, R.; Wetzstein, G.; Li, F.-F.; and Adeli, E
Chen, C.; Zhang, J.; Lakshmikanth, S. K.; Fang, Y.; Shao, R.; Wetzstein, G.; Li, F.-F.; and Adeli, E. 2025. The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR )
2025
-
[10]
Chen, J.; Liu, Y.; Wang, J.; Zeng, A.; Li, Y.; and Chen, Q. 2024 b . Diffsheg: A diffusion-based approach for real-time speech-driven holistic 3d expression and gesture generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 7352--7361
2024
-
[11]
Chen, R.; Shi, M.; Huang, S.; Tan, P.; Komura, T.; and Chen, X. 2024 c . Taming diffusion probabilistic models for character control. In ACM SIGGRAPH 2024 Conference Papers, 1--10
2024
-
[12]
Chen, X.; Jiang, B.; Liu, W.; Huang, Z.; Fu, B.; Chen, T.; and Yu, G. 2023. Executing your commands via motion diffusion in latent space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 18000--18010
2023
- [13]
-
[14]
Chi, S.; Chi, H.-g.; Ma, H.; Agarwal, N.; Siddiqui, F.; Ramani, K.; and Lee, K. 2024. M2d2m: Multi-motion generation from text with discrete diffusion models. In Proceedings of the European Conference on Computer Vision ( ECCV ) , 18--36
2024
-
[15]
D \'e fossez, A.; Mazar \'e , L.; Orsini, M.; Royer, A.; P \'e rez, P.; J \'e gou, H.; Grave, E.; and Zeghidour, N. 2024. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Fu, D.; Sun, T.; Fang, P.; Cai, X.; and Kim, H. 2026. MOGO: Residual Quantized Hierarchical Causal Transformer for Real-Time and Infinite-Length 3D Human Motion Generation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 5, 3994--4002
2026
-
[17]
Ginosar, S.; Bar, A.; Kohavi, G.; Chan, C.; Owens, A.; and Malik, J. 2019. Learning individual styles of conversational gesture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 3497--3506
2019
- [18]
-
[19]
G.; Wang, S.; and Cheng, L
Guo, C.; Mu, Y.; Javed, M. G.; Wang, S.; and Cheng, L. 2024. Momask: Generative masked modeling of 3d human motions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 1900--1910
2024
-
[20]
Guo, C.; Zou, S.; Zuo, X.; Wang, S.; Ji, W.; Li, X.; and Cheng, L. 2022 a . Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 5152--5161
2022
-
[21]
Guo, C.; Zuo, X.; Wang, S.; and Cheng, L. 2022 b . Tm2t: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts. In Proceedings of the European Conference on Computer Vision ( ECCV ) , 580--597
2022
-
[22]
Habibie, I.; Xu, W.; Mehta, D.; Liu, L.; Seidel, H.-P.; Pons-Moll, G.; Elgharib, M.; and Theobalt, C. 2021. Learning speech-driven 3d conversational gestures from video. In Proceedings of the 21st ACM international conference on intelligent virtual agents, 101--108
2021
-
[23]
Han, Z.; Teye, M.; Yadgaroff, D.; and B \"u tepage, J. 2025. Tiny is not small enough: High quality, low-resource facial animation models through hybrid knowledge distillation. ACM Transactions on Graphics (TOG), 44(4): 1--18
2025
- [24]
-
[25]
H.; Lakhotia, K.; Salakhutdinov, R.; and Mohamed, A
Hsu, W.-N.; Bolte, B.; Tsai, Y.-H. H.; Lakhotia, K.; Salakhutdinov, R.; and Mohamed, A. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29: 3451--3460
2021
-
[26]
Jiang, B.; Chen, X.; Liu, W.; Yu, J.; Yu, G.; and Chen, T. 2023. Motiongpt: Human motion as a foreign language. In Advances in Neural Information Processing Systems ( NeurIPS ) , volume 36, 20067--20079
2023
-
[27]
Karunratanakul, K.; Preechakul, K.; Suwajanakorn, S.; and Tang, S. 2023. Guided motion diffusion for controllable human motion synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision ( ICCV ) , 2151--2162
2023
-
[28]
A.; and Kanazawa, A
Li, R.; Yang, S.; Ross, D. A.; and Kanazawa, A. 2021. Ai choreographer: Music conditioned 3d dance generation with aist++. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 13401--13412
2021
-
[29]
Li, Z.; An, S.; Tang, C.; Guo, C.; Shugurov, I.; Zhang, L.; Zhao, A.; Sridhar, S.; Tao, L.; and Mittal, A. 2026. LLaMo: Scaling Pretrained Language Models for Unified Motion Understanding and Generation with Continuous Autoregressive Tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR )
2026
-
[30]
Lin, J.; Zeng, A.; Lu, S.; Cai, Y.; Zhang, R.; Wang, H.; and Zhang, L. 2023. Motion-x: A large-scale 3d expressive whole-body human motion dataset. Advances in Neural Information Processing Systems, 36: 25268--25280
2023
- [31]
-
[32]
Liu, H.; Iwamoto, N.; Zhu, Z.; Li, Z.; Zhou, Y.; Bozkurt, E.; and Zheng, B. 2022 a . Disco: Disentangled implicit content and rhythm learning for diverse co-speech gestures synthesis. In Proceedings of the 30th ACM international conference on multimedia, 3764--3773
2022
-
[33]
Liu, H.; Zhu, Z.; Becherini, G.; Peng, Y.; Su, M.; Zhou, Y.; Zhe, X.; Iwamoto, N.; Zheng, B.; and Black, M. J. 2024. EMAGE : Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 1144--1154
2024
-
[34]
Liu, H.; Zhu, Z.; Iwamoto, N.; Peng, Y.; Li, Z.; Zhou, Y.; Bozkurt, E.; and Zheng, B. 2022 b . Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis. In Proceedings of the European Conference on Computer Vision ( ECCV ) , 612--630
2022
-
[35]
Liu, P.; Song, L.; Huang, J.; and Xu, C. 2025. GestureLSM : Latent Shortcut based Co-Speech Gesture Generation with Spatial-Temporal Modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision ( ICCV )
2025
-
[36]
Liu, X.; Wu, Q.; Zhou, H.; Du, Y.; Wu, W.; Lin, D.; and Liu, Z. 2022 c . Audio-driven co-speech gesture video generation. In Advances in Neural Information Processing Systems ( NeurIPS ) , volume 35, 21386--21399
2022
-
[37]
Liu, X.; Wu, Q.; Zhou, H.; Xu, Y.; Qian, R.; Lin, X.; Zhou, X.; Wu, W.; Dai, B.; and Zhou, B. 2022 d . Learning hierarchical cross-modal association for co-speech gesture generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 10462--10472
2022
-
[38]
Lu, S.; Wang, J.; Lu, Z.; Chen, L.-H.; Dai, W.; Dong, J.; Dou, Z.; Dai, B.; and Zhang, R. 2025. Scamo: Exploring the scaling law in autoregressive motion generation model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 27872--27882
2025
-
[39]
F.; Pons-Moll, G.; and Black, M
Mahmood, N.; Ghorbani, N.; Troje, N. F.; Pons-Moll, G.; and Black, M. J. 2019. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 5442--5451
2019
-
[40]
MiniMax . 2025. MiniMax Speech 2.6
2025
-
[41]
H.; Dabral, R.; Demberg, V.; and Theobalt, C
Mughal, M. H.; Dabral, R.; Demberg, V.; and Theobalt, C. 2026. MIBURI : Towards Expressive Interactive Gesture Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR )
2026
-
[42]
H.; Dabral, R.; Scholman, M
Mughal, M. H.; Dabral, R.; Scholman, M. C.; Demberg, V.; and Theobalt, C. 2025. Retrieving semantics from the deep: an rag solution for gesture synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 16578--16588
2025
-
[43]
Nazarenus, E.; Li, C.; He, Y.; Xie, X.; Lenssen, J. E.; and Pons-Moll, G. 2026. ActionPlan: Future-Aware Streaming Motion Synthesis via Frame-Level Action Planning. arXiv preprint arXiv:2603.13500
-
[44]
Pan, Y.; Singh, K.; and Hafemann, L. G. 2025. Model See Model Do: Speech-Driven Facial Animation with Style Control. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, 1--10
2025
-
[45]
J.; and Varol, G
Petrovich, M.; Black, M. J.; and Varol, G. 2022. Temos: Generating diverse human motions from textual descriptions. In Proceedings of the European Conference on Computer Vision ( ECCV ) , 480--497
2022
-
[46]
Pinyoanuntapong, E.; Wang, P.; Lee, M.; and Chen, C. 2024. Mmm: Generative masked motion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 1546--1555
2024
-
[47]
R.; Chandrasekaran, A.; Athanasiou, N.; Quiros-Ramirez, A.; and Black, M
Punnakkal, A. R.; Chandrasekaran, A.; Athanasiou, N.; Quiros-Ramirez, A.; and Black, M. J. 2021. BABEL: Bodies, action and behavior with english labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 722--731
2021
-
[48]
Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; and Liu, P. J. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140): 1--67
2020
-
[49]
B.; Jiang, Y.; Wang, T.; Iqbal, U.; Minor, D.; de Ruyter, M.; et al
Rempe, D.; Petrovich, M.; Yuan, Y.; Zhang, H.; Peng, X. B.; Jiang, Y.; Wang, T.; Iqbal, U.; Minor, D.; de Ruyter, M.; et al. 2026. Kimodo: Scaling Controllable Human Motion Generation. arXiv preprint arXiv:2603.15546
-
[50]
Sun, Z.; Lv, T.; Ye, S.; Lin, M.; Sheng, J.; Wen, Y.-H.; Yu, M.; and Liu, Y.-j. 2024. Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models. ACM Transactions on Graphics (ToG), 43(4): 1--9
2024
-
[51]
H.; and Cohen-Or, D
Tevet, G.; Gordon, B.; Hertz, A.; Bermano, A. H.; and Cohen-Or, D. 2022. Motionclip: Exposing human motion generation to clip space. In Proceedings of the European Conference on Computer Vision ( ECCV ) , 358--374
2022
-
[52]
Tevet, G.; Raab, S.; Cohan, S.; Reda, D.; Luo, Z.; Peng, X. B.; Bermano, A. H.; and van de Panne, M. 2024. Closd: Closing the loop between simulation and diffusion for multi-task character control. arXiv preprint arXiv:2410.03441
-
[53]
Tevet, G.; Raab, S.; Gordon, B.; Shafir, Y.; Cohen-Or, D.; and Bermano, A. H. 2023. Human Motion Diffusion Model. In International Conference on Learning Representations ( ICLR )
2023
-
[54]
Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozi \`e re, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Wu, Q.; Zhao, Y.; Wang, Y.; Liu, X.; Tai, Y.-W.; and Tang, C.-K. 2025. Motion-Agent : A Conversational Framework for Human Motion Generation with LLM s. In International Conference on Learning Representations ( ICLR )
2025
-
[56]
Xiao, L.; Lu, S.; Pi, H.; Fan, K.; Pan, L.; Zhou, Y.; Feng, Z.; Zhou, X.; Peng, S.; and Wang, J. 2025. Motionstreamer: Streaming motion generation via diffusion-based autoregressive model in causal latent space. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 10086--10096
2025
-
[57]
Xie, Y.; Jampani, V.; Zhong, L.; Sun, D.; and Jiang, H. 2024. Omnicontrol: Control any joint at any time for human motion generation. In International Conference on Learning Representations ( ICLR )
2024
-
[58]
Xing, J.; Xia, M.; Zhang, Y.; Cun, X.; Wang, J.; and Wong, T.-T. 2023. Codetalker: Speech-driven 3d facial animation with discrete motion prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 12780--12790
2023
-
[59]
Xu, Z.; Lin, Y.; Han, H.; Yang, S.; Li, R.; Zhang, Y.; and Li, X. 2024. Mambatalk: Efficient holistic gesture synthesis with selective state space models. In Advances in Neural Information Processing Systems ( NeurIPS ) , volume 37, 20055--20080
2024
-
[60]
Yi, H.; Liang, H.; Liu, Y.; Cao, Q.; Wen, Y.; Bolkart, T.; Tao, D.; and Black, M. J. 2023. Generating holistic 3d human motion from speech. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 469--480
2023
-
[61]
Yu, H.; Zhang, J.; Chen, C.; Xiang, T.; Fang, Y.; Niebles, J. C.; and Adeli, E. 2025. Socialgen: Modeling multi-human social interaction with language models. arXiv preprint arXiv:2503.22906
-
[62]
Yuan, Y.; Song, J.; Iqbal, U.; Vahdat, A.; and Kautz, J. 2023. Physdiff: Physics-guided human motion diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision ( ICCV ) , 16010--16021
2023
-
[63]
Zeng, L.-A.; Huang, G.; Wu, G.; and Zheng, W.-S. 2025. Light-t2m: A lightweight and fast model for text-to-motion generation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 9, 9797--9805
2025
-
[64]
Zhang, J.; Fan, H.; and Yang, Y. 2025. Energymogen: Compositional human motion generation with energy-based diffusion model in latent space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 17592--17602
2025
-
[65]
Zhang, J.; Zhang, Y.; Cun, X.; Zhang, Y.; Zhao, H.; Lu, H.; Shen, X.; and Shan, Y. 2023 a . Generating human motion from textual descriptions with discrete representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) , 14730--14740
2023
-
[66]
Zhang, M.; Cai, Z.; Pan, L.; Hong, F.; Guo, X.; Yang, L.; and Liu, Z. 2024 a . Motiondiffuse: Text-driven human motion generation with diffusion model. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6): 4115--4128
2024
-
[67]
Zhang, M.; Guo, X.; Pan, L.; Cai, Z.; Hong, F.; Li, H.; Yang, L.; and Liu, Z. 2023 b . Remodiffuse: Retrieval-augmented motion diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision ( ICCV ) , 364--373
2023
-
[68]
Zhang, M.; Li, H.; Cai, Z.; Ren, J.; Yang, L.; and Liu, Z. 2023 c . Finemogen: Fine-grained spatio-temporal motion generation and editing. In Advances in Neural Information Processing Systems ( NeurIPS ) , volume 36, 13981--13992
2023
-
[69]
W.; Xu, M.; Wang, Q.; Wen, Z.; He, X.; Zhao, W.; Gong, K.; and Zhang, M
Zhang, N.; Li, Z.; Loh, K. W.; Xu, M.; Wang, Q.; Wen, Z.; He, X.; Zhao, W.; Gong, K.; and Zhang, M. 2026. DiMo: Discrete Diffusion Modeling for Motion Generation and Understanding. arXiv preprint arXiv:2602.04188
-
[70]
Zhang, Y.; Feng, Y.; Cseke, A.; Saini, N.; Bajandas, N.; Heron, N.; and Black, M. J. 2025 a . PRIMAL : Physically Reactive and Interactive Motor Model for Avatar Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision ( ICCV ) , 12725--12736
2025
-
[71]
Zhang, Y.; Huang, D.; Liu, B.; Tang, S.; Lu, Y.; Chen, L.; Bai, L.; Chu, Q.; Yu, N.; and Ouyang, W. 2024 b . MotionGPT : Finetuned LLM s Are General-Purpose Motion Generators. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , 7, 7368--7376
2024
-
[72]
Zhang, Y.-Y.; Sun, T.; Fang, P.; Wang, D.-B.; Cai, X.; Zhang, M.-L.; and Kim, H. 2025 b . MotionDuet: Dual-Conditioned 3D Human Motion Generation with Video-Regularized Text Learning. arXiv preprint arXiv:2511.18209
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Zhang, Z.; Ao, T.; Zhang, Y.; Gao, Q.; Lin, C.; Chen, B.; and Liu, L. 2024 c . Semantic gesticulator: Semantics-aware co-speech gesture synthesis. ACM Transactions on Graphics (TOG), 43(4): 1--17
2024
-
[74]
Zhao, K.; Li, G.; and Tang, S. 2025. DartControl: A Diffusion-Based Autoregressive Motion Model for Real-Time Text-Driven Motion Control. In International Conference on Learning Representations ( ICLR )
2025
-
[75]
Zhao, Q.; Long, P.; Zhang, Q.; Qin, D.; Liang, H.; Zhang, L.; Zhang, Y.; Yu, J.; and Xu, L. 2024. Media2face: Co-speech facial animation generation with multi-modality guidance. In ACM SIGGRAPH 2024 conference papers, 1--13
2024
-
[76]
Zheng, B.; Chen, K.; Yao, Y.; Zeng, Z.; Jiang, X.; Wang, H.; Lasenby, J.; and Jin, X. 2025. Autokeyframe: Autoregressive keyframe generation for human motion synthesis and editing. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, 1--12
2025
-
[77]
Zhou, W.; Dou, Z.; Cao, Z.; Liao, Z.; Wang, J.; Wang, W.; Liu, Y.; Komura, T.; Wang, W.; and Liu, L. 2024. Emdm: Efficient motion diffusion model for fast and high-quality motion generation. In Proceedings of the European Conference on Computer Vision ( ECCV ) , 18--38
2024
- [78]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.