Mechanical Enforcement for LLM Governance:Evidence of Governance-Task Decoupling in Financial Decision Systems
Pith reviewed 2026-06-30 21:01 UTC · model grok-4.3
The pith
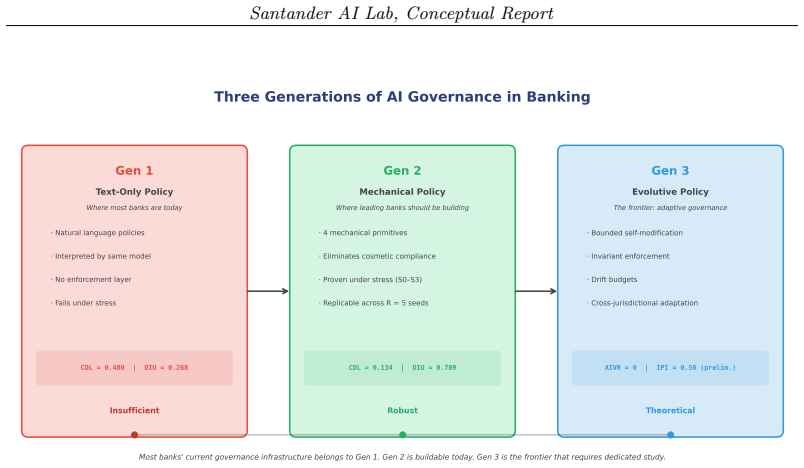
Mechanical enforcement preserves governance quality in LLM financial decisions even as task performance drops, unlike text-only policies which degrade on both.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
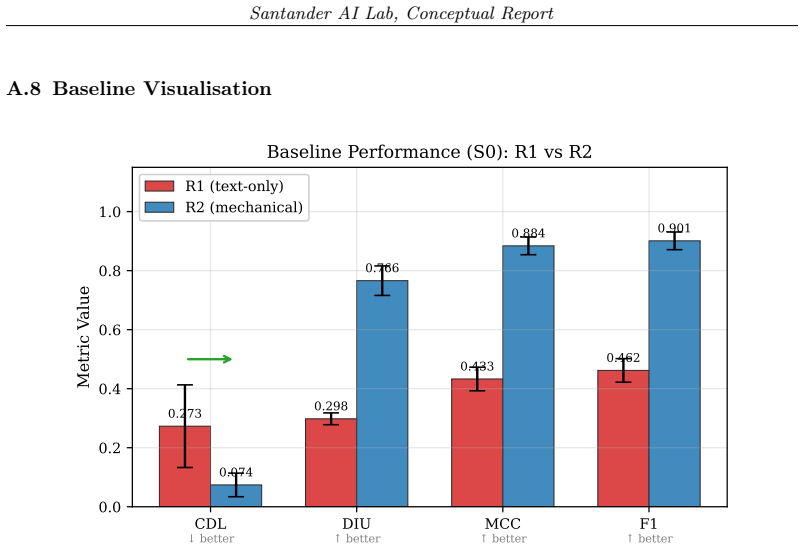
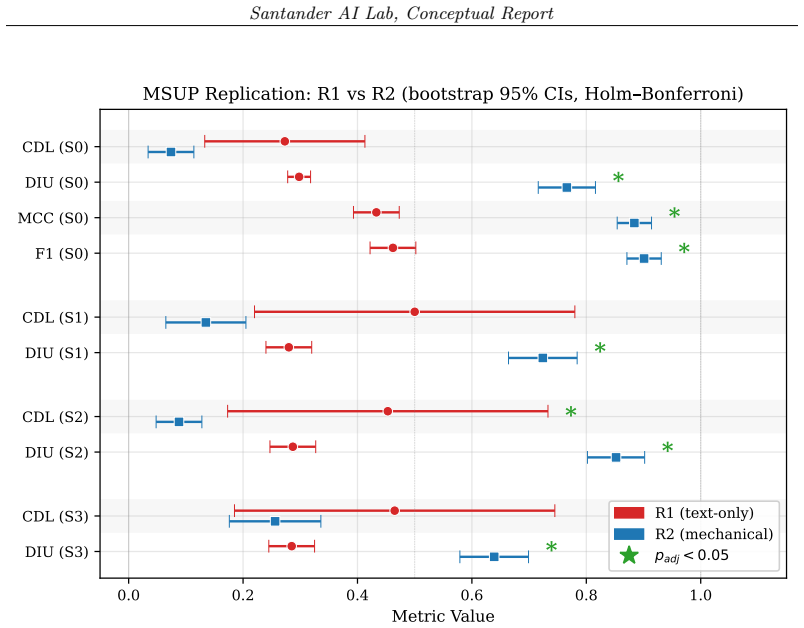
In the synthetic banking domain, text-only governance yields 27 percent of deferrals with no decision-relevant information; mechanical enforcement lowers this rate by 73 percent, more than doubles deferral information content, and lifts task accuracy from MCC 0.43 to 0.88. LLM-generated rationales show comparable CDL under both regimes, so the improvement arises from architectural separation that removes clear-cut decisions from the model's control. A causal ablation establishes that each of the four primitives is individually necessary. The central result is a governance-task decoupling: text-only governance degrades on both axes under structural stress, whereas mechanical enforcement maint
What carries the argument
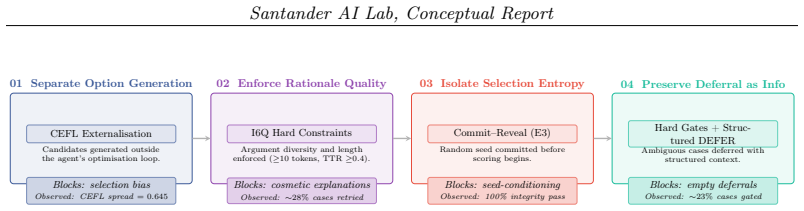
Four mechanical-enforcement primitives operating outside the model's interpretive loop, which enforce governance by removing clear-cut decisions from LLM control.
If this is right
- Governance quality and task accuracy must be evaluated on separate axes in regulated LLM systems.
- Accuracy alone is not a sufficient proxy for policy compliance at the rationale level.
- Each of the four primitives contributes independently to the observed decoupling effect.
- Removing clear-cut decisions from model control improves deferral informativeness without changing rationale quality.
Where Pith is reading between the lines
- The same separation principle could be tested in other regulated domains such as medical diagnosis or legal advice.
- Built-in mechanical checks might reduce reliance on post-generation audits if scaled to production systems.
- Design choices that deliberately create governance-task decoupling may outperform attempts to jointly optimize both in one model.
- Real-world validation would require replacing the synthetic domain with live policy logs while keeping the five metrics fixed.
Load-bearing premise
The synthetic banking domain and the five governance metrics accurately reflect real-world policy compliance in regulated financial workflows.
What would settle it
Apply the same four primitives to actual transaction logs and decision rationales from a regulated bank under documented policy stress and measure whether governance metrics remain stable while task accuracy falls.
Figures
read the original abstract
Large language models in regulated financial workflows are governed by natural-language policies that the same model interprets, creating a principal--agent failure: outputs can appear compliant without being compliant. Existing evaluation measures task accuracy but not whether governance constrains behaviour at the decision rationale level -- where regulated decisions must be auditable. We introduce five governance metrics that quantify policy compliance at the rationale level and apply them in a synthetic banking domain to compare text-only governance against mechanical enforcement: four primitives operating outside the model's interpretive loop. Under text-only governance, 27% of deferrals carry no decision-relevant information. Mechanical enforcement reduces this rate by 73%, more than doubles deferral information content, and raises task accuracy from MCC~$0.43$ to $0.88$. The improvement is driven by architectural separation: LLM-generated rationales under mechanical enforcement show comparable CDL to text-only governance -- the gain comes from removing clear-cut decisions from the model's control. A causal ablation confirms that each primitive is individually necessary. Our central finding is a governance-task decoupling: under structural stress, text-only governance degrades on both dimensions simultaneously, whereas mechanical enforcement preserves governance quality even as task performance drops. This implies that governance and task evaluation are distinct axes: accuracy is not a sufficient proxy for governance in regulated AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to demonstrate governance-task decoupling in LLM-based financial decision systems via a synthetic banking domain. Text-only governance degrades on both governance quality and task performance under structural stress, while mechanical enforcement (four primitives outside the model's interpretive loop) preserves governance metrics at the rationale level (73% reduction in empty deferrals, more than doubled deferral information content) even as task performance varies, raising MCC from 0.43 to 0.88. Five new governance metrics quantify policy compliance; a causal ablation shows each primitive is individually necessary. The central implication is that governance and task evaluation are distinct axes, so accuracy is not a sufficient proxy for compliance in regulated AI.
Significance. If the five governance metrics are shown to validly capture real policy compliance rather than artifacts of the setup, the work supplies concrete empirical evidence that architectural separation can enforce auditable behavior independently of task accuracy. The causal ablation and quantitative metrics (empty deferral rate, information content, MCC) provide a reproducible template for testing governance primitives in high-stakes domains.
major comments (3)
- [Abstract] Abstract: The five governance metrics are introduced and used to support the decoupling claim, yet no derivation from actual regulatory standards, inter-annotator agreement with compliance experts, or mapping to real audit criteria is provided. This is load-bearing because the observed separation between governance quality and task performance could be an artifact of metric construction tuned to the mechanical primitives under test.
- [Abstract] Abstract / Methods: The synthetic banking domain is the sole testbed for the decoupling result, but the manuscript supplies no external validation against real-world regulated financial workflows or audit criteria. The central claim that mechanical enforcement preserves governance quality therefore rests on an untested assumption that the domain accurately reflects policy compliance.
- [Results] Results (ablation and metrics): The abstract reports specific quantitative gains (MCC 0.43→0.88, 73% reduction in empty deferrals) and an ablation, but without visible full methods, dataset details, error bars, or statistical validation of the five metrics, the strength of the causal claim cannot be assessed.
minor comments (2)
- [Abstract] Abstract: The notation "MCC~$0.43$" should be expanded on first use (Matthews correlation coefficient) and the five metrics should be named explicitly rather than referred to generically.
- [Abstract] Abstract: The phrase "comparable CDL" is undefined in the provided text; clarify the acronym and its relation to the governance metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate where revisions will strengthen the manuscript. The core finding of governance-task decoupling via mechanical enforcement is supported by the controlled experiments and ablation, but we agree that additional justification and transparency are warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: The five governance metrics are introduced and used to support the decoupling claim, yet no derivation from actual regulatory standards, inter-annotator agreement with compliance experts, or mapping to real audit criteria is provided. This is load-bearing because the observed separation between governance quality and task performance could be an artifact of metric construction tuned to the mechanical primitives under test.
Authors: The five metrics operationalize observable properties of rationales required for auditability (e.g., presence of decision-relevant information in deferrals, policy consistency at the rationale level). Each is defined with explicit, reproducible criteria in the Methods. While the study does not include inter-annotator agreement with external compliance experts, the metrics align with standard regulatory expectations for documented decision rationales in financial services. We will revise to add an explicit subsection mapping each metric to principles drawn from common financial regulations (e.g., requirements for complete deferral documentation). This grounds the metrics independently of the primitives and reduces the risk of artifact concerns. revision: partial
-
Referee: [Abstract] Abstract / Methods: The synthetic banking domain is the sole testbed for the decoupling result, but the manuscript supplies no external validation against real-world regulated financial workflows or audit criteria. The central claim that mechanical enforcement preserves governance quality therefore rests on an untested assumption that the domain accurately reflects policy compliance.
Authors: The synthetic domain was selected to enable precise control over policy stress and to support the causal ablation demonstrating necessity of each primitive—conditions difficult to achieve with real transaction data due to privacy constraints. The domain incorporates standard banking policy elements (loan approval thresholds, deferral triggers for missing information). We will expand the Methods to detail the domain construction process and add a dedicated limitations paragraph on generalizability, while preserving the controlled demonstration of the decoupling principle. revision: partial
-
Referee: [Results] Results (ablation and metrics): The abstract reports specific quantitative gains (MCC 0.43→0.88, 73% reduction in empty deferrals) and an ablation, but without visible full methods, dataset details, error bars, or statistical validation of the five metrics, the strength of the causal claim cannot be assessed.
Authors: The full manuscript contains a Methods section with dataset generation procedures, metric definitions and formulas, experimental protocol, and ablation design. We will revise to prominently include error bars, bootstrap confidence intervals or paired statistical tests for the reported MCC and deferral reductions, and ensure all dataset and metric computation details are explicit and reproducible. These additions will allow direct assessment of the quantitative and causal claims. revision: yes
Circularity Check
No significant circularity; empirical measurements on introduced metrics
full rationale
The paper introduces five governance metrics, applies them to a synthetic banking domain, and reports measured outcomes (e.g., deferral rates, MCC scores) under text-only vs. mechanical conditions, plus a causal ablation. No equations, fitted parameters renamed as predictions, or self-definitional reductions appear. The decoupling claim rests on observed differences between experimental arms rather than quantities defined in terms of the results themselves. No self-citation chains or ansatzes are invoked as load-bearing. This is a standard empirical comparison whose validity concerns (metric grounding) fall outside circularity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The synthetic banking domain sufficiently models regulated financial decision making for the purpose of testing governance metrics.
Reference graph
Works this paper leans on
-
[1]
Problems of Monetary Management: The UK Experience
C. A. E. Goodhart. “Problems of Monetary Management: The UK Experience”. In: Macmillan Education UK, 1984, pp. 91–121.doi:10.1007/978-1-349-17295-5_4
-
[2]
Goodhart’s Law in Reinforcement Learning
Jacek Karwowski et al. “Goodhart’s Law in Reinforcement Learning”. In:Proceedings of the Twelfth International Conference on Learning Representations (ICLR). 2024
2024
-
[3]
Regulation (EU) 2024/1689 lay- ing down harmonised rules on artificial intelligence (Artificial Intelligence Act)
European Parliament and Council of the European Union. “Regulation (EU) 2024/1689 lay- ing down harmonised rules on artificial intelligence (Artificial Intelligence Act)”. In:Official Journal of the European UnionL (2024). OJ L, 2024/1689, 12.7.2024
2024
-
[4]
Board of Governors of the Federal Reserve System and Office of the Comptroller of the Currency.Supervisory Guidance on Model Risk Management. Tech. rep. SR 11-7 / OCC 2011-
2011
-
[5]
Federal Reserve / OCC, 2011.url:https://www.federalreserve.gov/supervisionreg/ srletters/sr1107.htm
2011
-
[6]
Model Risk Management for Generative AI In Financial Institutions
Anwesha Bhattacharyya et al. “Model Risk Management for Generative AI In Financial Institutions”. In:arXiv preprint arXiv:2503.15668(2025).url:https://arxiv.org/abs/ 2503.15668
-
[7]
Realistic Synthetic Financial Transactions for Anti-Money Laundering Models
Erik Altman et al. “Realistic Synthetic Financial Transactions for Anti-Money Laundering Models”. In:Advances in Neural Information Processing Systems 36. Neural Information Pro- cessing Systems Foundation, Inc. (NeurIPS), 2023, pp. 29851–29874.doi:10.52202/075280- 1300
-
[8]
UK Financial Conduct Authority (FCA).Generating and Using Synthetic Data for Models in Financial Services: Governance Considerations. Tech. rep. FCA Synthetic Data Expert Group, 2024
2024
-
[9]
Risks from Learned Optimization in Advanced Machine Learning Systems
Evan Hubinger et al. “Risks from Learned Optimization in Advanced Machine Learning Sys- tems”. In:arXiv preprint arXiv:1906.01820(2019).url:https://arxiv.org/abs/1906. 01820
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[10]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Evan Hubinger et al. “Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training”. In:arXiv preprint arXiv:2401.05566(2024).url:https://arxiv.org/abs/2401. 05566
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Concrete Problems in AI Safety
Dario Amodei et al. “Concrete Problems in AI Safety”. In:arXiv preprint arXiv:1606.06565 (2016).url:https://arxiv.org/abs/1606.06565
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark
Alexander Pan et al. “Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark”. In:Proceedings of the 40th International Conference on Machine Learning (ICML). PMLR, 2023
2023
-
[13]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai et al. “Constitutional AI: Harmlessness from AI Feedback”. In:arXiv preprint arXiv:2212.08073(2022).url:https://arxiv.org/abs/2212.08073. 9 Santander AI Lab, Conceptual Report
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan et al. “Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conver- sations”. In:arXiv preprint arXiv:2312.06674(2023).url:https://arxiv.org/abs/2312. 06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Robust Prompt Optimization for Defending Language ModelsAgainstJailbreakingAttacks
Bo Li, Haohan Wang, and Andy Zhou. “Robust Prompt Optimization for Defending Language ModelsAgainstJailbreakingAttacks”.In:Advances in Neural Information Processing Systems
-
[16]
Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024, pp. 40184– 40211.doi:10.52202/079017-1270
-
[17]
Red Teaming Language Models with Language Models
Ethan Perez et al. “Red Teaming Language Models with Language Models”. In:Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022, pp. 3419–3448.doi:10.18653/v1/2022.emnlp-main.225
-
[18]
Who Should Predict? Exact Algorithms For Learning to Defer to Humans
Hussein Mozannar et al. “Who Should Predict? Exact Algorithms For Learning to Defer to Humans”. In:Proceedings of the 26th International Conference on Artificial Intelligence and Statistics (AISTATS). PMLR, 2023
2023
-
[19]
Machinelearningwitharejectoption:asurvey
KilianHendrickxetal.“Machinelearningwitharejectoption:asurvey”.In:Machine Learning 113.5 (2024), pp. 3073–3110.doi:10.1007/s10994-024-06534-x
-
[20]
Know Your Limits: A Survey of Abstention in Large Language Models
Bingbing Wen et al. “Know Your Limits: A Survey of Abstention in Large Language Models”. In:arXiv preprint arXiv:2407.18418(2024).url:https://arxiv.org/abs/2407.18418
-
[21]
Harms from Increasingly Agentic Algorithmic Systems
Alan Chan et al. “Harms from Increasingly Agentic Algorithmic Systems”. In:2023 ACM Conference on Fairness Accountability and Transparency. ACM, 2023, pp. 651–666.doi:10. 1145/3593013.3594033
-
[22]
Managing extreme AI risks amid rapid progress
Yoshua Bengio et al. “Managing extreme AI risks amid rapid progress”. In:Science384.6698 (2024), pp. 842–845.doi:10.1126/science.adn0117
-
[23]
FinBen: A Holistic Financial Benchmark for Large Language Mod- els
Sophia Ananiadou et al. “FinBen: A Holistic Financial Benchmark for Large Language Mod- els”. In:Advances in Neural Information Processing Systems 37. Neural Information Process- ing Systems Foundation, Inc. (NeurIPS), 2024, pp. 95716–95743.doi:10 . 52202 / 079017 - 3033
2024
-
[24]
Marcantonio Bracale Syrnikov et al. “Institutional AI: Governing LLM Collusion in Multi- Agent Cournot Markets via Public Governance Graphs”. In:arXiv preprint arXiv:2601.11369 (2026).url:https://arxiv.org/abs/2601.11369
-
[25]
The Agentic Regulator: Risks for AI in Fi- nanceandaProposedAgent-basedFrameworkforGovernance
Eren Kurshan, Tucker Balch, and David Byrd. “The Agentic Regulator: Risks for AI in Fi- nanceandaProposedAgent-basedFrameworkforGovernance”.In:arXiv preprint arXiv:2512.11933 (2025).url:https://arxiv.org/abs/2512.11933
-
[26]
Paris: OECD Publishing, 2008.doi:10.1787/ 9789264043466-en
OECD and European Commission Joint Research Centre.Handbook on Constructing Com- posite Indicators: Methodology and User Guide. Paris: OECD Publishing, 2008.doi:10.1787/ 9789264043466-en
2008
-
[27]
Towards Selection as Power: Bounding Decision Authority in Autonomous Agents
Jose Manuel de la Chica Rodriguez and Juan Manuel Vera Díaz. “Towards Selection as Power: Bounding Decision Authority in Autonomous Agents”. In:arXiv preprint arXiv:2602.14606 (2026).url:https://arxiv.org/abs/2602.14606
-
[28]
Coin flipping by telephone a protocol for solving impossible problems
Manuel Blum. “Coin flipping by telephone a protocol for solving impossible problems”. In: ACM SIGACT News15.1 (1983), pp. 23–27.doi:10.1145/1008908.1008911
-
[29]
Basel Committee on Banking Supervision.Corporate Governance Principles for Banks. Tech. rep. BCBS 328. Bank for International Settlements, 2015.url:https://www.bis.org/bcbs/ publ/d328.htm
2015
-
[30]
EuropeanBankingAuthority.Guidelines on Internal Governance under Directive 2013/36/EU. Tech. rep. EBA/GL/2021/05. EBA, 2021.url:https://www.eba.europa.eu/activities/ single-rulebook/regulatory-activities/internal-governance/guidelines-internal- governance-under-crd
2013
-
[31]
Basel Committee on Banking Supervision.Principles for Effective Risk Data Aggregation and Risk Reporting. Tech. rep. 239. Bank for International Settlements, 2013.url:https: //www.bis.org/publ/bcbs239.htm
2013
-
[32]
Stephen E Toulmin.The Uses of Argument. Updated. Cambridge University Press, 2003. 10 Santander AI Lab, Conceptual Report
2003
-
[33]
Philip M. McCarthy and Scott Jarvis. “MTLD, vocd-D, and HD-D: A validation study of sophisticated approaches to lexical diversity assessment”. In:Behavior Research Methods42.2 (2010), pp. 381–392.doi:10.3758/brm.42.2.381
-
[34]
Davide Chicco and Giuseppe Jurman. “The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation”. In:BMC Genomics 21.1 (2020).doi:10.1186/s12864-019-6413-7
-
[35]
Tibshirani.An Introduction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. New York: Chap- man & Hall/CRC, 1993.isbn: 978-0-412-04231-7
1993
-
[36]
A simple sequentially rejective multiple test procedure
Sture Holm. “A simple sequentially rejective multiple test procedure”. In:Scandinavian Jour- nal of Statistics6.2 (1979), pp. 65–70
1979
-
[37]
National Institute of Standards and Technology.AI Risk Management Framework (AI RMF 1.0). Tech. rep. NIST AI 100-1. NIST, 2023
2023
-
[38]
Practical and Provably-Secure Commitment Schemes from Collision-Free Hashing
Shai Halevi and Silvio Micali. “Practical and Provably-Secure Commitment Schemes from Collision-Free Hashing”. In: Springer Berlin Heidelberg, 1996, pp. 201–215.doi:10.1007/3- 540-68697-5_16. A Supplementary Material A.1 Dataset Characteristics Stress conditions are specified in Table 2 (Section 3.1). Table 7: Dataset characteristics under baseline condit...
work page doi:10.1007/3- 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.