Recognition: no theorem link
Accelerating State-Vector Quantum Simulation on Integrated GPUs via Cache Locality Optimization: A Cross-Architecture Evaluation
Pith reviewed 2026-05-15 03:07 UTC · model grok-4.3
The pith
Reorganizing the quantum state vector for last-level cache locality reverses GPU performance degradation on integrated hardware as qubit count grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
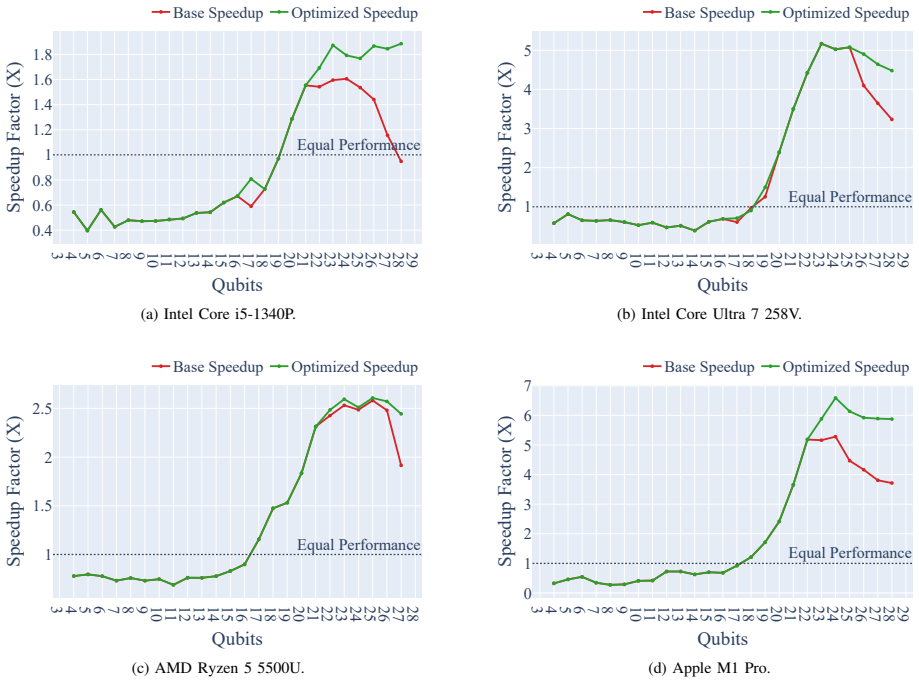
The central claim is that a state partitioning optimization reorganizes the quantum state vector to maximize last-level cache locality and minimize costly main-memory fetches. When applied to state-vector simulation of a Quantum Phase Estimation algorithm, this change mitigates the performance degradation that baseline GPU implementations suffer at larger qubit scales. Concrete measurements show the optimization reverses an Intel Core i5 deficit from 0.95x to 1.89x GPU-over-CPU speedup and raises the Apple M1 Pro speedup from 3.71x to 5.88x at 28 qubits, while delivering consistent execution-time gains across the tested integrated-GPU architectures.
What carries the argument
State partitioning optimization that reorganizes the quantum state vector to maximize last-level cache locality and minimize main-memory fetches.
If this is right
- Baseline implementations suffer severe relative GPU speedup loss with rising qubit count because of poor spatial locality in the state vector.
- The partitioning strategy restores GPU advantage on Intel integrated graphics from 0.95x to 1.89x at 28 qubits.
- The same change lifts Apple M1 Pro speedup from 3.71x to 5.88x at the same scale.
- Execution-time improvements appear consistently across Intel, AMD, and Apple integrated GPUs without vendor-specific code.
- Integrated GPUs become viable for practical quantum circuit simulation on consumer laptops.
Where Pith is reading between the lines
- The same locality reorganization could be applied to other memory-bandwidth-bound quantum algorithms such as variational quantum eigensolvers or quantum approximate optimization.
- If the overhead remains low, the technique may extend naturally to larger qubit counts beyond 28 on future integrated GPUs with bigger caches.
- Consumer-laptop quantum simulation workloads could shift from cloud GPU clusters to local hardware once the optimization is integrated into open simulators.
Load-bearing premise
The reorganization of the state vector can be performed with negligible overhead and produces consistent cache behavior across different integrated GPU architectures without architecture-specific tuning.
What would settle it
Run the same 28-qubit Quantum Phase Estimation circuit after partitioning and observe no measurable rise in last-level cache hit rate or no reversal of the baseline GPU-to-CPU speedup deficit on at least two of the three tested platforms.
Figures





read the original abstract
The classical simulation of quantum algorithms is a crucial tool for circuit development, testing, and validation. Although acceleration using GPUs significantly reduces simulation time, most high-performance simulators rely on vendor-specific frameworks that target data-center hardware. To broaden access to quantum simulation, this work proposes a vendor-agnostic approach targeting the integrated GPUs commonly found in consumer-grade laptops. A primary challenge in state-vector simulation is its inherently poor spatial locality, which creates a memory bandwidth bottleneck. Consequently, baseline implementations experience a severe degradation in relative GPU speedup as the number of simulated qubits increases. To address this limitation, we introduce a state partitioning optimization that reorganizes the quantum state vector to maximize the last-level cache locality and minimize costly main memory fetches. We evaluate this strategy using a Quantum Phase Estimation algorithm across diverse architectures from Intel, AMD, and Apple. The experimental results demonstrate that the proposed optimization successfully mitigates performance degradation at larger qubit scales. In particular, for a 28-qubit simulation, the optimization reversed a performance deficit on an Intel Core i5, improving the GPU speedup over the CPU from 0.95x to 1.89x, and increased the Apple M1 Pro speedup from 3.71x to 5.88x. Overall, this approach yields consistent execution time improvements, demonstrating the viability of integrated GPUs for efficient quantum circuit simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a vendor-agnostic state partitioning optimization to reorganize the quantum state vector for improved last-level cache locality in state-vector simulations on integrated GPUs. It evaluates the approach using Quantum Phase Estimation circuits on Intel, AMD, and Apple hardware, claiming that the optimization mitigates GPU speedup degradation at scale; specifically, for 28 qubits it reverses a 0.95x GPU/CPU deficit to 1.89x on an Intel Core i5 and raises Apple M1 Pro speedup from 3.71x to 5.88x.
Significance. If the net speedups are shown to arise from cache improvements rather than unaccounted reorganization costs, the work would usefully expand accessible quantum simulation to consumer laptops. The cross-architecture empirical evaluation on real integrated GPUs is a positive contribution, though the absence of overhead isolation and ablations leaves the central performance attribution only partially supported.
major comments (1)
- [Experimental Results] Experimental Results section: the reported 28-qubit speedups (0.95x to 1.89x on Intel i5; 3.71x to 5.88x on M1 Pro) provide no breakdown isolating the wall-clock cost of the state-vector partitioning/reorganization pass from the subsequent gate kernels. For a 2^28 complex-double vector (~4 GB), any full-array permutation or blocking step incurs substantial memory traffic; without separate timing or an ablation that disables the reorganization while keeping all other factors fixed, it is impossible to confirm that the quoted net improvements are attributable to reduced LLC misses rather than amortization artifacts or exclusion of the reorganization cost.
minor comments (2)
- [Abstract] Abstract and §4: no error bars, standard deviations, or number of repetitions are reported for the timing measurements, weakening confidence in the precise speedup ratios.
- [Evaluation] No ablation study is presented that quantifies the incremental benefit of the partitioning step alone versus baseline GPU kernels on the same hardware.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address the concern about isolating the reorganization overhead below and will revise the paper to provide the requested ablation.
read point-by-point responses
-
Referee: Experimental Results section: the reported 28-qubit speedups (0.95x to 1.89x on Intel i5; 3.71x to 5.88x on M1 Pro) provide no breakdown isolating the wall-clock cost of the state-vector partitioning/reorganization pass from the subsequent gate kernels. For a 2^28 complex-double vector (~4 GB), any full-array permutation or blocking step incurs substantial memory traffic; without separate timing or an ablation that disables the reorganization while keeping all other factors fixed, it is impossible to confirm that the quoted net improvements are attributable to reduced LLC misses rather than amortization artifacts or exclusion of the reorganization cost.
Authors: We agree that the current manuscript lacks an explicit isolation of the one-time state partitioning overhead from the gate kernels, which limits the strength of the cache-locality attribution. The reorganization is performed once prior to simulation and its cost is amortized across the many gates in the QPE circuit, but we acknowledge this does not substitute for a direct measurement. In the revised version we will add an ablation that reports wall-clock times for (i) the partitioning pass alone, (ii) the full optimized run, and (iii) the baseline run without partitioning. This will allow readers to verify that the reported net speedups (0.95x→1.89x on Intel i5; 3.71x→5.88x on M1 Pro) arise from reduced LLC misses during kernel execution rather than from omitting reorganization cost. revision: yes
Circularity Check
No circularity: purely empirical timing measurements with no derivations or self-referential reductions
full rationale
The manuscript reports wall-clock timings for a state-vector simulator before and after a cache-locality reorganization pass on real integrated-GPU hardware (Intel, AMD, Apple) running a fixed Quantum Phase Estimation circuit. No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the provided text; the central claim is simply that measured speedups improve at 28 qubits once the reorganization is applied. Because the work contains no derivation chain that could reduce to its own inputs, no self-citation load-bearing steps, and no renaming of known results, the circularity score is zero. The skeptic concern about unmeasured reorganization overhead is a question of experimental completeness, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quantum Software Engineering: Roadmap and Chal- lenges Ahead,
J. M. Murillo, J. Garcia-Alonso, E. Moguel, J. Barzen, F. Leymann, S. Ali, T. Yue, P. Arcaini, R. P ´erez-Castillo, I. Garc ´ıa-Rodr´ıguez De Guzm´an, M. Piattini, A. Ruiz-Cort ´es, A. Brogi, J. Zhao, A. Miranskyy, and M. Wimmer, “Quantum Software Engineering: Roadmap and Chal- lenges Ahead,”ACM Trans. Softw. Eng. Methodol., vol. 34, no. 5, pp. 1–48, Jun. 2025
work page 2025
-
[2]
Quantum Computing in the NISQ era and beyond,
J. Preskill, “Quantum Computing in the NISQ era and beyond,”Quan- tum, vol. 2, p. 79, Aug. 2018
work page 2018
-
[3]
Simulation of Quantum Computers: Review and Acceleration Oppor- tunities,
A. Cicero, M. A. Maleki, M. W. Azhar, A. F. Kockum, and P. Trancoso, “Simulation of Quantum Computers: Review and Acceleration Oppor- tunities,”ACM Trans. Quantum Comput., vol. 7, no. 1, pp. 1–35, Mar. 2026
work page 2026
-
[4]
Stabilizer Codes and Quantum Error Correction,
D. Gottesman, “Stabilizer Codes and Quantum Error Correction,” May 1997
work page 1997
-
[5]
qHiPSTER: The Quantum High Performance Software Testing Environment,
M. Smelyanskiy, N. P. D. Sawaya, and A. Aspuru-Guzik, “qHiPSTER: The Quantum High Performance Software Testing Environment,” May 2016
work page 2016
-
[6]
cuQuantum SDK: A High-Performance Library for Accelerating Quantum Science,
H. Bayraktar, A. Charara, D. Clark, S. Cohen, T. Costa, Y .-L. L. Fang, Y . Gao, J. Guan, J. Gunnels, A. Haidar, A. Hehn, M. Hohnerbach, M. Jones, T. Lubowe, D. Lyakh, S. Morino, P. Springer, S. Stanwyck, I. Terentyev, S. Varadhan, J. Wong, and T. Yamaguchi, “cuQuantum SDK: A High-Performance Library for Accelerating Quantum Science,” in2023 IEEE Internat...
work page 2023
-
[7]
Intel Quantum Simulator: A cloud-ready high-performance simulator of quantum circuits,
G. G. Guerreschi, J. Hogaboam, F. Baruffa, and N. P. D. Sawaya, “Intel Quantum Simulator: A cloud-ready high-performance simulator of quantum circuits,”Quantum Sci. Technol., vol. 5, no. 3, p. 034007, Jul. 2020
work page 2020
-
[8]
HyQuas: Hy- brid partitioner based quantum circuit simulation system on GPU,
C. Zhang, Z. Song, H. Wang, K. Rong, and J. Zhai, “HyQuas: Hy- brid partitioner based quantum circuit simulation system on GPU,” in Proceedings of the ACM International Conference on Supercomputing. Virtual Event USA: ACM, Jun. 2021, pp. 443–454
work page 2021
-
[9]
QuEST and High Performance Simulation of Quantum Computers,
T. Jones, A. Brown, I. Bush, and S. C. Benjamin, “QuEST and High Performance Simulation of Quantum Computers,”Sci Rep, vol. 9, no. 1, p. 10736, Jul. 2019
work page 2019
-
[10]
SV-sim: Scalable PGAS-based state vector simulation of quantum circuits,
A. Li, B. Fang, C. Granade, G. Prawiroatmodjo, B. Heim, M. Roetteler, and S. Krishnamoorthy, “SV-sim: Scalable PGAS-based state vector simulation of quantum circuits,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. St. Louis Missouri: ACM, Nov. 2021, pp. 1–14
work page 2021
-
[11]
Cache Blocking Technique to Large Scale Quantum Computing Simulation on Supercomputers,
J. Doi and H. Horii, “Cache Blocking Technique to Large Scale Quantum Computing Simulation on Supercomputers,” in2020 IEEE International Conference on Quantum Computing and Engineering (QCE). Denver, CO, USA: IEEE, Oct. 2020, pp. 212–222
work page 2020
-
[12]
Efficient Hierarchical State Vector Simulation of Quantum Circuits via Acyclic Graph Partitioning,
B. Fang, M. Y . Ozkaya, A. Li, U. V . Catalyurek, and S. Krishnamoorthy, “Efficient Hierarchical State Vector Simulation of Quantum Circuits via Acyclic Graph Partitioning,” in2022 IEEE International Conference on Cluster Computing (CLUSTER). Heidelberg, Germany: IEEE, Sep. 2022, pp. 289–300
work page 2022
-
[13]
Full Quantum Stack: Ket Platform,
E. Rosa, E. Lussi, J. Marchi, R. De Santiago, and E. Duzzioni, “Full Quantum Stack: Ket Platform,”Braz J Phys, vol. 56, no. 1, p. 45, Feb. 2026
work page 2026
-
[14]
M. A. Nielsen and I. L. Chuang,Quantum Computation and Quantum Information, 10th ed. Cambridge: Cambridge university press, 2010
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.