VGGT-Ω
Pith reviewed 2026-06-30 20:29 UTC · model grok-4.3
The pith
The quality of feed-forward reconstruction models scales predictably with model and data size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VGGT-Ω, obtained by replacing VGGT's multi-head design with a single dense prediction head under multi-task supervision, removing high-resolution convolutional layers, and introducing register attention that funnels inter-frame exchange through compact scene registers, can be trained on 15 times more data including dynamic scenes thanks to a new high-quality annotation pipeline and self-supervised protocol; the resulting model delivers higher reconstruction accuracy and efficiency on both static and dynamic scenes.
What carries the argument
Register attention, which aggregates scene information into a small set of registers and restricts inter-frame information exchange to those registers rather than full global attention.
If this is right
- Reconstruction accuracy on standard benchmarks rises as model size and data volume grow.
- Dynamic-scene reconstruction becomes feasible at the same quality level as static-scene work.
- Features from the trained registers improve downstream vision-language-action models and language alignment.
- Self-supervised training on large unlabeled video collections becomes practical for reconstruction tasks.
Where Pith is reading between the lines
- Continued scaling could make feed-forward reconstruction competitive with or superior to optimization-based pipelines in many practical settings.
- Treating reconstruction as a scalable proxy task suggests geometric supervision can serve as a foundation for broader spatial reasoning in multimodal systems.
- The memory-saving register design may transfer to other dense-prediction vision models that currently face similar data-scale bottlenecks.
Load-bearing premise
The architectural simplifications and new dynamic-scene annotation pipeline preserve geometric accuracy while allowing the 15-fold increase in training data.
What would settle it
A direct comparison that trains the original VGGT architecture on the same expanded dataset without register attention or the single-head change and measures whether camera-estimation error on Sintel fails to drop by a comparable amount.
Figures









read the original abstract
Recent feed-forward reconstruction models, such as VGGT, have proven competitive with traditional optimization-based reconstructors while also providing geometry-aware features useful for other tasks. Here, we show that the quality of these models scales predictably with model and data size. We do so by introducing VGGT-$\Omega$, which substantially improves reconstruction accuracy, efficiency, and capabilities for both static and dynamic scenes. To enable training this model at an unprecedented scale, we introduce architectural changes that improve training efficiency, a high-quality data annotation pipeline that supports dynamic scenes, and a self-supervised learning protocol. We simplify VGGT's architecture by using a single dense prediction head with multi-task supervision and removing the expensive high-resolution convolutional layers. We also use registers to aggregate scene information into a compact representation and introduce register attention, which restricts inter-frame information exchange to these registers, in part replacing global attention. In this way, during training, VGGT-$\Omega$ uses only about 30% of the GPU memory of its predecessor, allowing us to train with 15x more supervised data than prior work and to leverage vast amounts of unlabeled video data. VGGT-$\Omega$ achieves strong results for reconstruction of static and dynamic scenes across multiple benchmarks, for example, improving over the previous best camera estimation accuracy on Sintel by 77%. We also show that the learned registers can improve vision-language-action models and support alignment with language, suggesting that reconstruction can be a powerful and scalable proxy task for spatial understanding. Project Page: http://vggt-omega.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VGGT-Ω, a scaled feed-forward 3D reconstruction model extending VGGT. It claims that reconstruction quality scales predictably with model and data size, enabled by architectural simplifications (single dense prediction head with multi-task supervision, removal of high-resolution convolutional layers, register attention that restricts inter-frame exchange to compact registers) plus a new high-quality annotation pipeline for dynamic scenes and self-supervised protocol. These changes reduce GPU memory to ~30% of the predecessor, permitting 15× more supervised data and use of unlabeled video; the model reports strong gains on static/dynamic benchmarks (e.g., 77% improvement in camera estimation accuracy on Sintel) and shows that learned registers aid vision-language-action models.
Significance. If the empirical scaling results and ablations hold, the work supplies concrete evidence that reconstruction can serve as a scalable proxy task for spatial understanding, analogous to scaling laws observed elsewhere in machine learning. The memory-efficient register mechanism, dynamic-scene data pipeline, and cross-task transfer to VLA models are substantive contributions that could shift practice toward larger data-driven reconstructors.
minor comments (3)
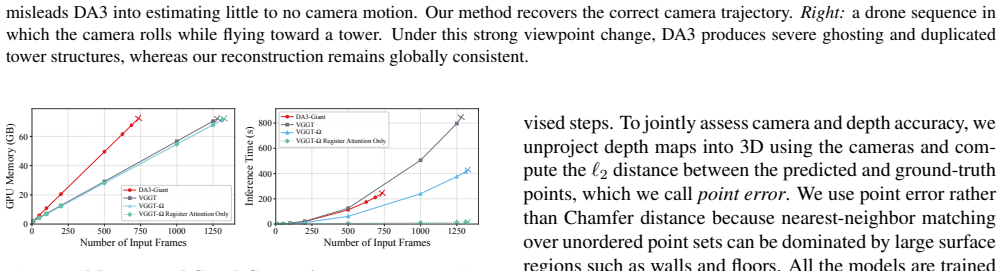
- [§4.1] §4.1: The ablation table on register attention reports memory savings but does not list the exact sequence lengths or batch sizes used for the 30% figure; adding these values would make the efficiency claim directly reproducible.
- [Figure 4] Figure 4: The dynamic-scene qualitative results would benefit from side-by-side comparison with the prior VGGT baseline on the same frames to illustrate the claimed accuracy gains.
- [§3.3] The self-supervised protocol is mentioned in the abstract and §3.3 but the precise loss weighting between supervised and self-supervised terms is not tabulated; a short equation or hyper-parameter table would clarify training.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of VGGT-Ω, accurate summary of the architectural changes, data scaling, and empirical results, and for recommending minor revision. The report correctly identifies the memory-efficient register mechanism, dynamic-scene annotation pipeline, and cross-task transfer as substantive contributions. No major comments were raised in the report.
Circularity Check
No significant circularity; empirical scaling results only
full rationale
The manuscript reports empirical scaling of reconstruction quality with model and data size via architectural simplifications (single dense head, register attention), a new annotation pipeline, and 15x larger training data. No equations, derivations, or first-principles claims appear; all results are direct benchmark comparisons and ablations. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations are present. The central claims rest on external benchmarks (Sintel, etc.) rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 7 Pith papers
-
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
SpatialBench evaluates 41 spatial foundation models across 6 paradigms and 5 task suites, finds they are not all-round players, and introduces the DA-Next-5M dataset plus DA-Next baseline model.
-
Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes
Argus is a feed-forward network for metric panoramic 3D reconstruction, trained on the new Realsee3D dataset of 10K indoor scenes and using a learned covisibility module plus decomposed mapping supervision to achieve ...
-
Current World Models Lack a Persistent State Core
Current world models fail to evolve internal state when unobserved and instead resume scenes at the last observed state, as diagnosed by the new WRBench benchmark across 23 models and 9600 videos.
-
Geometric Action Model for Robot Policy Learning
GAM splits a geometric foundation model to enable language-conditioned future geometry prediction and action decoding for robot policies, claiming superior performance on manipulation benchmarks.
-
Modality Forcing for Scalable Spatial Generation
Modality Forcing lets a single DiT produce image and depth outputs in any order after training on sparse real-world depth, with larger image-pretrained models yielding better depth accuracy and a 57% AbsRel reduction ...
-
Dexterity-BEV: Aligning 3D World and Actions for Generalizable Robot Policies Learning
Dexterity-BEV creates 3D vertex-based inputs and BEV-aligned outputs to reduce spatial-temporal misalignments in end-to-end robot policies trained on diverse datasets and embodiments.
-
$\text{VG}^2$GT: Voxel-Gaussian Splatting Visual Geometry Grounded Transformer
VG²GT regresses Gaussian primitive parameters from multi-scale voxel features of a frozen VFM and uses stochastic solid volume rendering for depth supervision to produce geometrically accurate reconstructions that out...
Reference graph
Works this paper leans on
-
[1]
Geoaware-VLA: Implicit geometry aware vision-language-action model.arXiv, 2025
Ali Abouzeid, Malak Mansour, Qinbo Sun, Zezhou Sun, and Dezhen Song. Geoaware-VLA: Implicit geometry aware vision-language-action model.arXiv, 2025. 1, 3, 11
2025
-
[2]
Building rome in a day.Communications of the ACM, 54(10), 2011
Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day.Communications of the ACM, 54(10), 2011. 3
2011
-
[3]
Mapillary planet-scale depth dataset
Manuel L ´opez Antequera, Pau Gargallo, Markus Hofinger, Samuel Rota Bul `o, Yubin Kuang, and Peter Kontschieder. Mapillary planet-scale depth dataset. InProc. ECCV, 2020. 7
2020
-
[4]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Daniyar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. InProc. ECCV, 2022. 7
2022
-
[5]
Neural RGB-D surface reconstruction
Dejan Azinovi ´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural RGB-D surface reconstruction. InProc. CVPR, 2022. 8
2022
-
[6]
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Fan Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, Jakob Julian Engel, and Tomas Hodan. Introducing HOT3D: an egocentric dataset for 3D hand and object tracking.arXiv, 2406.09598, 2024. 7
-
[7]
Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. 15 Mip-nerf: A multiscale representation for anti-aliasing neu- ral radiance fields. InProc. ICCV, 2021. 13, 14
2021
-
[8]
Black, Priyanka Patel, Joachim Tesch, and Jin- long Yang
Michael J. Black, Priyanka Patel, Joachim Tesch, and Jin- long Yang. BEDLAM: a synthetic dataset of bodies ex- hibiting detailed lifelike animated motion. InProc. CVPR,
-
[9]
Human-level 3D shape perception emerges from multi- view learning.arXiv, 2026
Tyler Bonnen, Jitendra Malik, and Angjoo Kanazawa. Human-level 3D shape perception emerges from multi- view learning.arXiv, 2026. 1, 3
2026
-
[10]
Scene coordinate reconstruction: Posing of image collections via incremental learning of a relocalizer
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cav- allari, ´Aron Monszpart, Daniyar Turmukhambetov, and Victor Adrian Prisacariu. Scene coordinate reconstruction: Posing of image collections via incremental learning of a relocalizer. InProc. ECCV, 2024. 3
2024
-
[11]
On geometric understanding and learned data priors in VGGT.arXiv, 2025
Jelena Bratuli ´c, Sudhanshu Mittal, Thomas Brox, and Christian Rupprecht. On geometric understanding and learned data priors in VGGT.arXiv, 2025. 3
2025
-
[12]
Recovering non-rigid 3D shape from image streams
Christoph Bregler, Aaron Hertzmann, and Henning Bier- mann. Recovering non-rigid 3D shape from image streams. InProc. CVPR, 2000. 4, 6
2000
-
[13]
Random forests.Machine learning, 45(1),
Leo Breiman. Random forests.Machine learning, 45(1),
-
[14]
Butler, Jonas Wulff, Garrett B
Daniel J. Butler, Jonas Wulff, Garrett B. Stanley, and Michael J. Black. A naturalistic open source movie for op- tical flow evaluation. InProc. ECCV, 2012. 8
2012
-
[15]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual KITTI 2.arXiv, 2001.10773, 2020. 7
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[16]
MUSt3R: Multi-view network for stereo 3D recon- struction
Yohann Cabon, Lucas Stoffl, Leonid Antsfeld, Gabriela Csurka, Boris Chidlovskii, Jerome Revaud, and Vincent Leroy. MUSt3R: Multi-view network for stereo 3D recon- struction. InProc. CVPR, 2025. 3
2025
-
[17]
DepthLM: Metric depth from vision language models
Zhipeng Cai, Ching-Feng Yeh, Hu Xu, Zhuang Liu, Gre- gory Meyer, Xinjie Lei, Changsheng Zhao, Shang-Wen Li, Vikas Chandra, and Yangyang Shi. DepthLM: Metric depth from vision language models. InProc. ICLR, 2026. 15
2026
-
[18]
VGGT-Det: Mining VGGT internal priors for sensor-geometry-free multi-view indoor 3D object detection.arXiv, 2026
Yang Cao, Feize Wu, Dave Zhenyu Chen, Yingji Zhong, Lanqing Hong, and Dan Xu. VGGT-Det: Mining VGGT internal priors for sensor-geometry-free multi-view indoor 3D object detection.arXiv, 2026. 1, 3
2026
-
[19]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProc. ICCV, 2021. 2, 6
2021
-
[20]
SpatialVLM: En- dowing vision-language models with spatial reasoning ca- pabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. SpatialVLM: En- dowing vision-language models with spatial reasoning ca- pabilities. InProc. CVPR, 2024. 15
2024
-
[21]
Learning to match features with seeded graph matching network
Hongkai Chen, Zixin Luo, Jiahui Zhang, Lei Zhou, Xuyang Bai, Zeyu Hu, Chiew-Lan Tai, and Long Quan. Learning to match features with seeded graph matching network. In Proc. CVPR, 2021. 3
2021
-
[22]
Geometric context transformer for streaming 3D reconstruction.arXiv, 2026
Lin-Zhuo Chen, Jian Gao, Yihang Chen, Ka Leong Cheng, Yipengjing Sun, Liangxiao Hu, Nan Xue, Xing Zhu, Yu- jun Shen, Yao Yao, and Yinghao Xu. Geometric context transformer for streaming 3D reconstruction.arXiv, 2026. 3
2026
-
[23]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProc. Knowledge Discovery and Data Mining, 2016. 7
2016
-
[24]
HD-VGGT: High- resolution visual geometry transformer.arXiv, 2026
Tianrun Chen, Yuanqi Hu, Yidong Han, Hanjie Xu, Deyi Ji, Qi Zhu, Chunan Yu, Xin Zhang, Cheng Chen, Chao- tao Ding, Ying Zang, Xuanfu Li, et al. HD-VGGT: High- resolution visual geometry transformer.arXiv, 2026. 3
2026
-
[25]
TTT3R: 3D reconstruction as test-time train- ing.arXiv, 2025
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. TTT3R: 3D reconstruction as test-time train- ing.arXiv, 2025. 3
2025
-
[26]
TTT3R: 3D reconstruction as test-time train- ing
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. TTT3R: 3D reconstruction as test-time train- ing. InProc. ICLR, 2026. 3
2026
-
[27]
Human3R: Everyone ev- erywhere all at once.arXiv, 2025
Yue Chen, Xingyu Chen, Yuxuan Xue, Anpei Chen, Yu- liang Xiu, and Gerard Pons-Moll. Human3R: Everyone ev- erywhere all at once.arXiv, 2025. 4
2025
-
[28]
SpatialRGPT: Grounded spatial reasoning in vision- language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. SpatialRGPT: Grounded spatial reasoning in vision- language models. InProc. NeurIPS, 2024. 15
2024
-
[29]
ScanNet: Richly-annotated 3D reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. In Proc. CVPR, 2017. 7
2017
-
[30]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. InProc. ACL, 2022. 12
2022
-
[31]
A simple prior- free method for non-rigid structure-from-motion factoriza- tion.IJCV, 107, 2014
Yuchao Dai, Hongdong Li, and Mingyi He. A simple prior- free method for non-rigid structure-from-motion factoriza- tion.IJCV, 107, 2014. 6
2014
-
[32]
Vision transformers need registers.Proc
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Pi- otr Bojanowski. Vision transformers need registers.Proc. ICLR, 2024. 2, 4
2024
-
[33]
Factor graphs and GTSAM: A hands-on introduction, 2012
Frank Dellaert. Factor graphs and GTSAM: A hands-on introduction, 2012. 3
2012
-
[34]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging proper- ties in unified multimodal pretraining.arXiv, 2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
SAIL-Recon: Large SfM by augmenting scene regression with localization
Junyuan Deng, Heng Li, Tao Xie, Weiqiang Ren, Qian Zhang, Ping Tan, and Xiaoyang Guo. SAIL-Recon: Large SfM by augmenting scene regression with localization. In Proc. 3DV, 2026. 3
2026
-
[36]
VGGT-Long: chunk it, loop it, align it—pushing vggt’s limits on kilometer-scale long RGB sequences.arXiv,
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. VGGT-Long: chunk it, loop it, align it—pushing vggt’s limits on kilometer-scale long RGB sequences.arXiv,
-
[37]
Unipr- 3d: Towards universal visual place recognition with visual geometry grounded transformer.arXiv, 2025
Tianchen Deng, Xun Chen, Ziming Li, Hongming Shen, Danwei Wang, Javier Civera, and Hesheng Wang. Unipr- 3d: Towards universal visual place recognition with visual geometry grounded transformer.arXiv, 2025. 3
2025
-
[38]
SuperPoint: self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. SuperPoint: self-supervised interest point detection and description. InProc. CVPR Workshop, 2018. 3, 7
2018
-
[39]
16 MASt3R-SfM: a fully-integrated solution for unconstrained structure-from-motion
Bardienus Duisterhof, Lojze Zust, Philippe Weinzaepfel, Vincent Leroy, Yohann Cabon, and Jerome Revaud. 16 MASt3R-SfM: a fully-integrated solution for unconstrained structure-from-motion. InProc. 3DV, 2025. 3
2025
-
[40]
D2- Net: A trainable CNN for joint description and detection of local features
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2- Net: A trainable CNN for joint description and detection of local features. InProc. CVPR, 2019. 3
2019
-
[41]
Light3R- SfM: towards feed-forward structure-from-motion
Sven Elflein, Qunjie Zhou, and Laura Leal-Taix´e. Light3R- SfM: towards feed-forward structure-from-motion. InProc. CVPR, 2025. 3
2025
-
[42]
Dens3R: A founda- tion model for 3D geometry prediction.Proc
Xianze Fang, Jingnan Gao, Zhe Wang, Zhuo Chen, Xingyu Ren, Jiangjing Lyu, Qiaomu Ren, Zhonglei Yang, Xiaokang Yang, Yichao Yan, and Chengfei Lyu. Dens3R: A founda- tion model for 3D geometry prediction.Proc. ICLR, 2026. 3
2026
-
[43]
Faugeras and Stephen J
Olivier D. Faugeras and Stephen J. Maybank. Motion from point matches: Multiplicity of solutions.IJCV, 4(3), 1990. 2
1990
-
[44]
Black, Trevor Darrell, and Angjoo Kanazawa
Haiwen Feng, Junyi Zhang, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J. Black, Trevor Darrell, and Angjoo Kanazawa. St4RTrack: simultaneous 4D recon- struction and tracking in the world. InProc. ICCV, 2025. 4
2025
-
[45]
Mid-Air: A multi-modal dataset for extremely low altitude drone flights
Michael Fonder and Marc Van Droogenbroeck. Mid-Air: A multi-modal dataset for extremely low altitude drone flights. InProc. CVPR Workshop, 2019. 7
2019
-
[46]
Building Rome on a cloudless day
Jan-Michael Frahm, Pierre Fite-Georgel, David Gallup, Tim Johnson, Rahul Raguram, Changchang Wu, Yi-Hung Jen, Enrique Dunn, Brian Clipp, Svetlana Lazebnik, et al. Building Rome on a cloudless day. InProc. ECCV, 2010. 3
2010
-
[47]
Geo-Neus: Geometry-consistent neural implicit surfaces learning for multi-view reconstruction
Qiancheng Fu, Qingshan Xu, Yew Soon Ong, and Wen- bing Tao. Geo-Neus: Geometry-consistent neural implicit surfaces learning for multi-view reconstruction. InProc. NeurIPS, 2022. 3
2022
-
[48]
Barron, Kyle Genova, Nithish Kannen, et al
Valentin Gabeur, Shangbang Long, Songyou Peng, Paul V oigtlaender, Shuyang Sun, Yanan Bao, Karen Truong, Zhicheng Wang, Wenlei Zhou, Jonathan T. Barron, Kyle Genova, Nithish Kannen, et al. Image generators are gen- eralist vision learners.arXiv, 2026. 15
2026
-
[49]
Monocular dynamic view synthe- sis: A reality check
Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa. Monocular dynamic view synthe- sis: A reality check. InProc. NeurIPS, 2022. 8
2022
-
[50]
MoRE: 3D visual geometry recon- struction meets mixture-of-experts.arXiv, 2025
Jingnan Gao, Zhe Wang, Xianze Fang, Xingyu Ren, Zhuo Chen, Shengqi Liu, Yuhao Cheng, Jiangjing Lyu, Xiaokang Yang, and Yichao Yan. MoRE: 3D visual geometry recon- struction meets mixture-of-experts.arXiv, 2025. 3
2025
-
[51]
VGGT-Segmentor: Geometry- enhanced cross-view segmentation.arXiv, 2026
Yulu Gao, Bohao Zhang, Zongheng Tang, Jitong Liao, Wenjun Wu, and Si Liu. VGGT-Segmentor: Geometry- enhanced cross-view segmentation.arXiv, 2026. 1, 3
2026
-
[52]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProc. Empirical Methods in Natural Language Process- ing, 2021. 12
2021
-
[53]
Kubric: a scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapra- gasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, et al. Kubric: a scalable dataset generator. InProc. CVPR, 2022. 7
2022
-
[54]
Cascade cost volume for high- resolution multi-view stereo and stereo matching
Xiaodong Gu, Zhiwen Fan, Siyu Zhu, Zuozhuo Dai, Feitong Tan, and Ping Tan. Cascade cost volume for high- resolution multi-view stereo and stereo matching. InProc. CVPR, 2020. 3
2020
-
[55]
D 2USt3R: Enhancing 3D reconstruction with 4d pointmaps for dy- namic scenes.arXiv, 2504.06264, 2025
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chaehyun Kim, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. D 2USt3R: Enhancing 3D reconstruction with 4d pointmaps for dy- namic scenes.arXiv, 2504.06264, 2025. 4
-
[56]
Learning to see before seeing: Demystifying llm visual priors from lan- guage pre-training
Junlin Han, Shengbang Tong, David Fan, Yufan Ren, Kous- tuv Sinha, Philip Torr, and Filippos Kokkinos. Learning to see before seeing: Demystifying llm visual priors from lan- guage pre-training. InProc. NeurIPS Workshop, 2025. 12
2025
-
[57]
Cambridge University Press,
Richard Hartley and Andrew Zisserman.Multiple View Ge- ometry in Computer Vision. Cambridge University Press,
-
[58]
Cambridge University Press, ISBN: 0521540518, 2004
Richard Hartley and Andrew Zisserman.Multiple View Ge- ometry in Computer Vision. Cambridge University Press, ISBN: 0521540518, 2004. 2
2004
-
[59]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProc. CVPR, 2016. 14
2016
-
[60]
Girshick
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. Momentum contrast for unsupervised visual representation learning. InProc. CVPR, 2020. 2, 6
2020
-
[61]
Generative camera dolly: Ex- treme monocular dynamic novel view synthesis.arXiv, 2405.14868, 2024
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sar- gent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Ex- treme monocular dynamic novel view synthesis.arXiv, 2405.14868, 2024. 7
-
[62]
GAIA-1: A generative world model for autonomous driving.arXiv, 2023
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gi- anluca Corrado. GAIA-1: A generative world model for autonomous driving.arXiv, 2023. 15
2023
-
[63]
SAIL-VOS 3D: A synthetic dataset and baselines for object detection and 3d mesh reconstruc- tion from video data
Yuan-Ting Hu, Jiahong Wang, Raymond A Yeh, and Alexander G Schwing. SAIL-VOS 3D: A synthetic dataset and baselines for object detection and 3d mesh reconstruc- tion from video data. InProc. CVPR, 2021. 7
2021
-
[64]
LongSplat: Online generalizable 3D Gaussian splatting from long se- quence images
Guichen Huang, Ruoyu Wang, Xiangjun Gao, Che Sun, Yuwei Wu, Shenghua Gao, and Yunde Jia. LongSplat: Online generalizable 3D Gaussian splatting from long se- quence images. InProc. ICCV, 2025. 3
2025
-
[65]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Ko- rovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, Jiawei Ren, Kevin Xie, et al. ViPE: video pose engine for 3D geometric perception. arXiv, 2508.10934, 2025. 4, 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Gen3R: 3D scene generation meets feed-forward reconstruction
Jiaxin Huang, Yuanbo Yang, Bangbang Yang, Lin Ma, Yuewen Ma, and Yiyi Liao. Gen3R: 3D scene generation meets feed-forward reconstruction. InProc. CVPR, 2026. 1, 3
2026
-
[67]
Self-Improving 4D Perception via Self-Distillation
Nan Huang, Pengcheng Yu, Weijia Zeng, James M Rehg, Angjoo Kanazawa, Haiwen Feng, and Qianqian Wang. Self-improving 4d perception via self-distillation.arXiv preprint arXiv:2604.08532, 2026. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
17 Self-improving 4D perception via self-distillation.arXiv,
Nan Huang, Pengcheng Yu, Weijia Zeng, James M Rehg, Angjoo Kanazawa, Haiwen Feng, and Qianqian Wang. 17 Self-improving 4D perception via self-distillation.arXiv,
-
[69]
DeepMVS: Learning multi- view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. DeepMVS: Learning multi- view stereopsis. InProc. CVPR, 2018. 7
2018
-
[70]
Point- World: Scaling 3D world models for in-the-wild robotic manipulation.arXiv, 2026
Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming- Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei-Fei. Point- World: Scaling 3D world models for in-the-wild robotic manipulation.arXiv, 2026. 28
2026
-
[71]
Position: The platonic representation hypoth- esis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypoth- esis. InProc. ICML, 2024. 12
2024
-
[72]
Repurposing geometric foundation models for multi-view diffusion.arXiv, 2026
Wooseok Jang, Seonghu Jeon, Jisang Han, Jinhyeok Choi, Minkyung Kwon, Seungryong Kim, Saining Xie, and Sainan Liu. Repurposing geometric foundation models for multi-view diffusion.arXiv, 2026. 1, 3
2026
-
[73]
RayZer: a self-supervised large view synthesis model
Hanwen Jiang, Hao Tan, Peng Wang, Haian Jin, Yue Zhao, Sai Bi, Kai Zhang, Fujun Luan, Kalyan Sunkavalli, Qixing Huang, and Georgios Pavlakos. RayZer: a self-supervised large view synthesis model. InProc. ICCV, 2025. 13
2025
-
[74]
MegaSynth: Scaling up 3d scene reconstruction with synthesized data
Hanwen Jiang, Zexiang Xu, Desai Xie, Ziwen Chen, Haian Jin, Fujun Luan, Zhixin Shu, Kai Zhang, Sai Bi, Xin Sun, Jiuxiang Gu, Qixing Huang, et al. MegaSynth: Scaling up 3d scene reconstruction with synthesized data. InProc. CVPR, 2025. 7
2025
-
[75]
arXiv preprint arXiv:2505.23716 (2025)
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, Dahua Lin, and Bo Dai. AnySplat: feed-forward 3D Gaussian Splatting from unconstrained views.arXiv, 2505.23716, 2025. 3
-
[76]
Vision transformers don’t need trained registers
Nick Jiang, Amil Dravid, Alexei Efros, and Yossi Gan- delsman. Vision transformers don’t need trained registers. arXiv, 2025. 2, 4
2025
-
[77]
Geo4D: Leveraging video generators for geometric 4D scene reconstruction
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Geo4D: Leveraging video generators for geometric 4D scene reconstruction. InProceedings of the International Conference on Computer Vision (ICCV),
-
[78]
Barron, Noah Snavely, and Aleksander Holyn- ski
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T. Barron, Noah Snavely, and Aleksander Holyn- ski. ZipMap: linear-time stateful 3D reconstruction via test- time training. InProc. CVPR, 2026. 3
2026
-
[79]
MoRe: Monocular geometry refinement via graph optimization for cross-view consistency
Dongki Jung, Jaehoon Choi, Yonghan Lee, Sungmin Eum, Heesung Kwon, and Dinesh Manocha. MoRe: Monocular geometry refinement via graph optimization for cross-view consistency. InProc. WACV, 2026. 3
2026
-
[80]
Scaling laws for neural language models.arXiv, 2020
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv, 2020. 1
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.