VG²GT: Voxel-Gaussian Splatting Visual Geometry Grounded Transformer
Pith reviewed 2026-06-28 15:40 UTC · model grok-4.3
The pith
VG²GT regresses Gaussian primitive parameters directly from multi-scale voxel features of a frozen visual foundation model, supervised by stochastic solid volume rendering of depth maps.
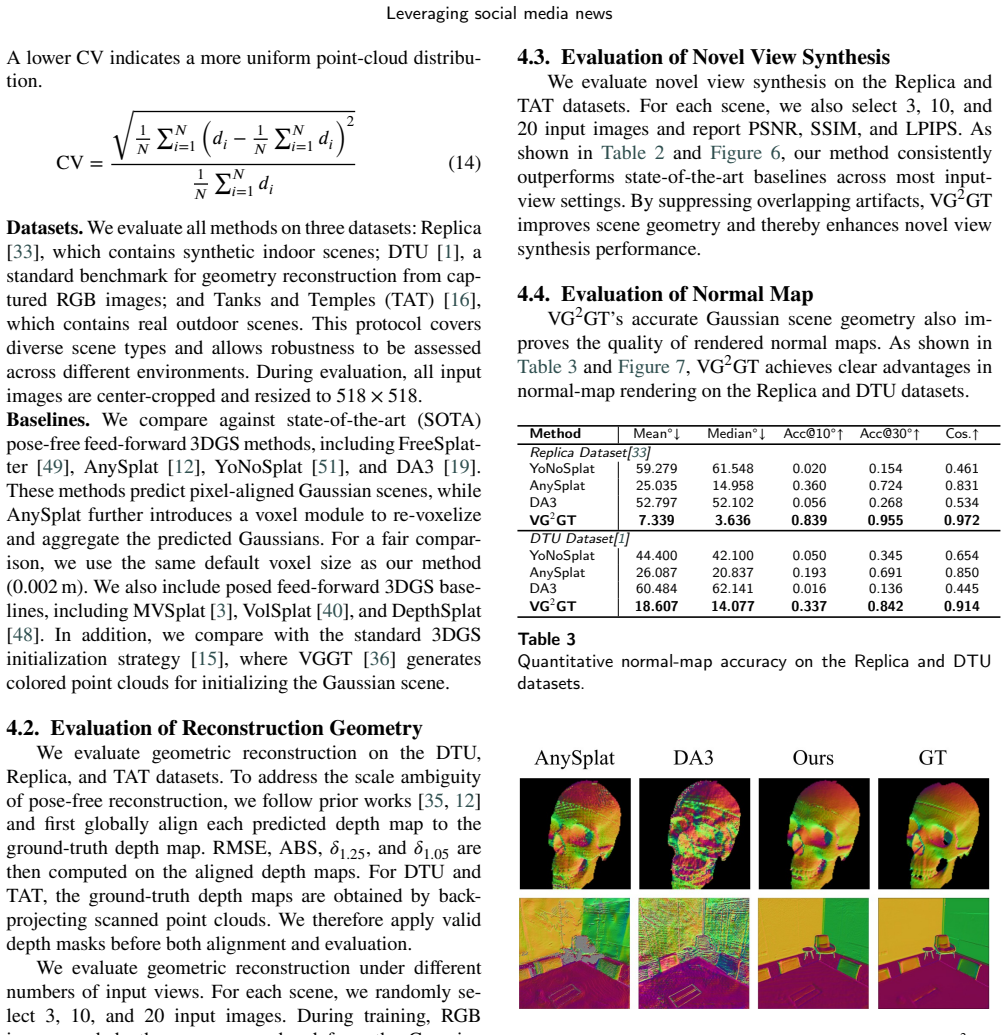
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
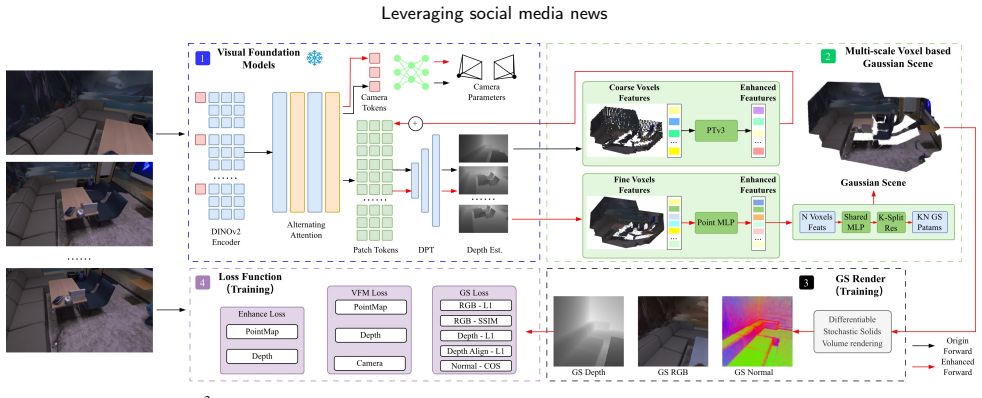
VG²GT is a Voxel-Gaussian Splatting Visual Geometry-Grounded Transformer that leverages a frozen pretrained visual foundation model, incorporates a multi-scale differentiable voxel module to enhance geometric understanding, and directly splits and regresses Gaussian primitive parameters from voxel features, with depth maps supervised through stochastic solid volume rendering to enable geometrically accurate Gaussian scene reconstruction.
What carries the argument
The multi-scale differentiable voxel module that extracts features from a frozen VFM and supplies them for direct regression of Gaussian primitive parameters.
If this is right
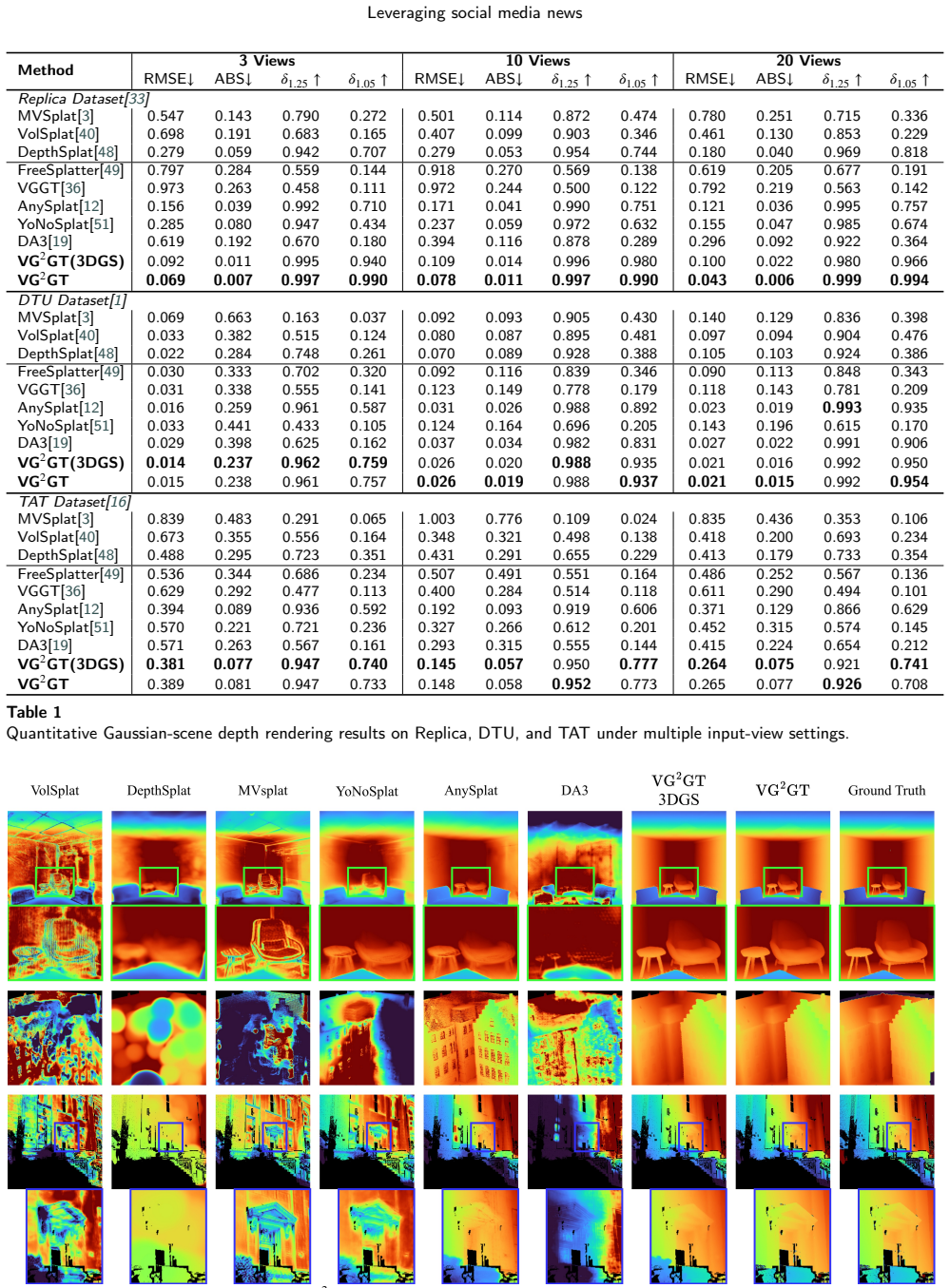
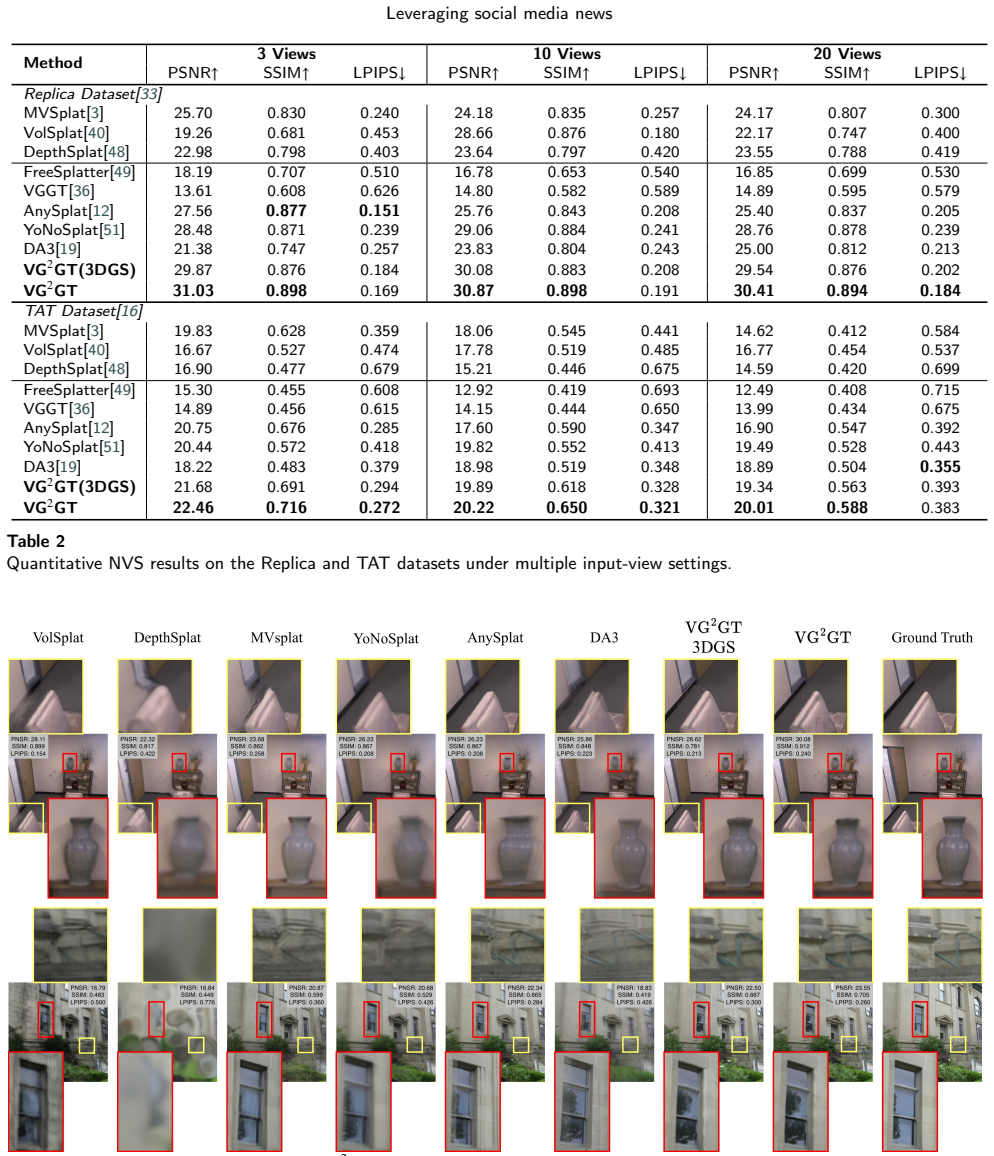
- VG²GT outperforms current state-of-the-art methods on the DTU, Replica, TAT, and ScanNet datasets.
- The method requires no per-scene optimization or camera parameter refinement at inference time.
- VG²GT can be plugged into any patch-feature-based visual foundation model.
- Training cost is substantially reduced compared to methods that optimize per scene.
Where Pith is reading between the lines
- The feed-forward design could support reconstruction pipelines that process video streams in real time without repeated optimization steps.
- Replacing the depth-only supervision with additional signals such as surface normals might reduce remaining inconsistencies in complex indoor scenes.
- Because the voxel module operates on frozen features, the same architecture could be tested on tasks like semantic 3D labeling with minimal added heads.
Load-bearing premise
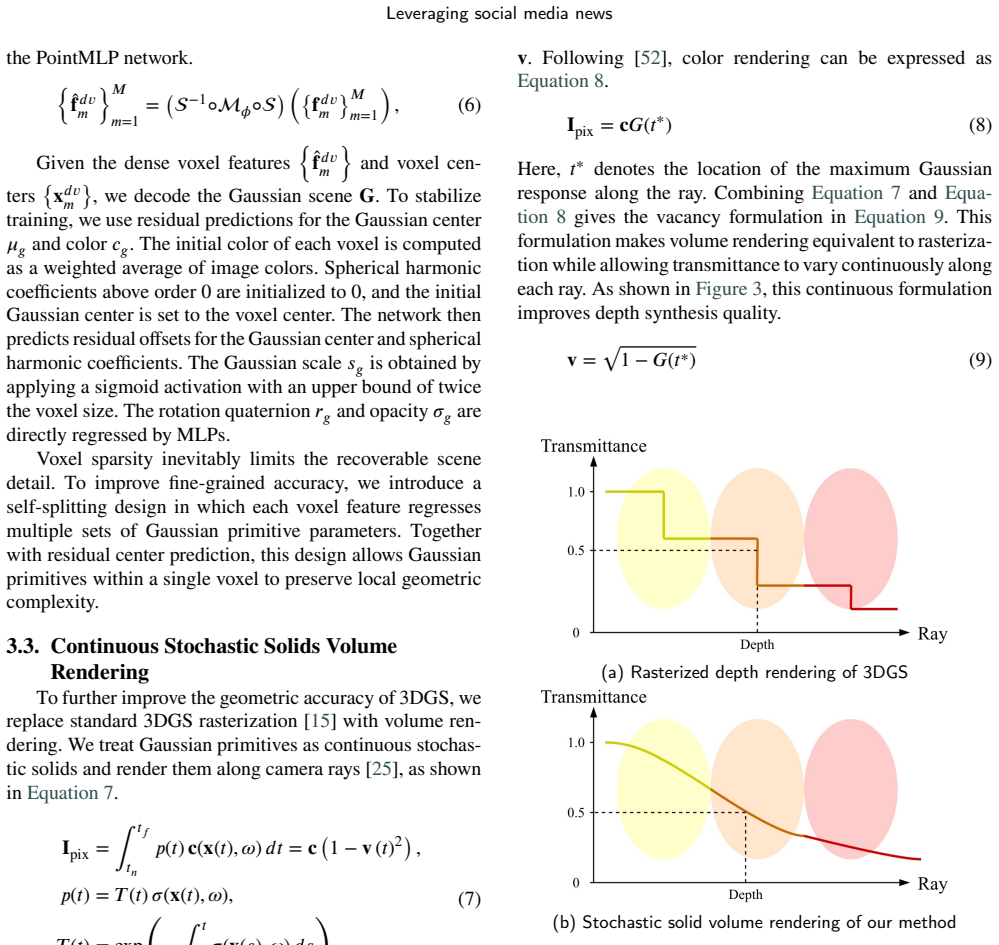
Directly regressing Gaussian parameters from multi-scale voxel features of a frozen VFM, supervised only by stochastic solid volume rendering of depth maps, produces artifact-free and geometrically accurate scene reconstructions without per-scene optimization or camera parameter refinement.
What would settle it
Significant geometric inaccuracies or visible artifacts appearing in reconstructions on the ScanNet dataset when tested without any per-scene adjustment would indicate the claim does not hold.
Figures



read the original abstract
Gaussian splatting has shown strong potential for 3D reconstruction and novel view synthesis. However, most existing methods require accurate camera parameters and per-scene optimization, while feed-forward methods with pixel-aligned Gaussian primitives often suffer from artifacts and non-uniform primitives. In this paper, we propose $\text{VG}^2$GT, a Voxel-Gaussian Splatting Visual Geometry-Grounded Transformer. $\text{VG}^2$GT leverages a frozen pretrained visual foundation model (VFM), incorporates a multi-scale differentiable voxel module to enhance geometric understanding, and directly splits and regresses Gaussian primitive parameters from voxel features. During training, depth maps are supervised through stochastic solid volume rendering, enabling geometrically accurate Gaussian scene reconstruction while keeping the visual foundation model fully frozen. This design enables $\text{VG}^2$GT to be seamlessly plugged into any patch-feature-based VFM, while substantially reducing the required training cost. $\text{VG}^2$GT outperforms current state-of-the-art methods on widely used DTU, Replica, TAT, and ScanNet datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VG²GT, a feed-forward architecture for 3D scene reconstruction that combines Gaussian splatting with a visual geometry-grounded transformer. It extracts multi-scale features from a frozen pretrained visual foundation model (VFM), processes them via a differentiable voxel module, and directly regresses all Gaussian primitive parameters (means, covariances, opacities, SH coefficients). Depth supervision is applied through stochastic solid volume rendering; the design avoids per-scene optimization and camera refinement while claiming to be pluggable into existing patch-feature VFMs and to outperform prior methods on DTU, Replica, TAT, and ScanNet.
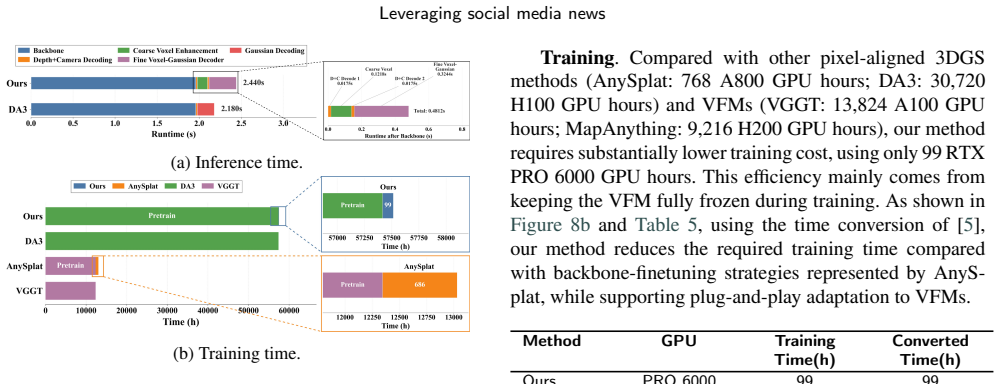
Significance. If the empirical claims are substantiated, the work would be significant for demonstrating that frozen VFMs plus a lightweight voxel module can supply sufficient metric geometry for high-quality, artifact-free Gaussian reconstruction in a single forward pass, thereby removing the dominant computational cost of per-scene optimization in current pipelines.
major comments (2)
- [Abstract] Abstract: the central claim that VG²GT 'outperforms current state-of-the-art methods' on DTU, Replica, TAT, and ScanNet is presented without any quantitative numbers, tables, error bars, or ablation statistics, rendering the soundness of the outperformance assertion impossible to evaluate from the given material.
- [Method overview] Core regression step (described in the abstract and method overview): the load-bearing assumption that multi-scale voxel features extracted from a frozen VFM contain adequate metric geometric signal to regress accurate Gaussian means, covariances, opacities, and SH coefficients—supervised solely by stochastic solid volume rendering of depth maps—remains untested by the provided text. The skeptic concern that VFMs are optimized for 2D semantics rather than precise 3D geometry is therefore not yet addressed by concrete evidence such as failure-case analysis or controlled ablations that isolate the voxel module.
minor comments (1)
- [Abstract] Abstract: the phrasing 'substantially reducing the required training cost' is asserted without any reported training-time or memory figures relative to baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that VG²GT 'outperforms current state-of-the-art methods' on DTU, Replica, TAT, and ScanNet is presented without any quantitative numbers, tables, error bars, or ablation statistics, rendering the soundness of the outperformance assertion impossible to evaluate from the given material.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised version we will insert the primary metrics (e.g., mean PSNR/SSIM on DTU and Replica) directly into the abstract while retaining the high-level claim. revision: yes
-
Referee: [Method overview] Core regression step (described in the abstract and method overview): the load-bearing assumption that multi-scale voxel features extracted from a frozen VFM contain adequate metric geometric signal to regress accurate Gaussian means, covariances, opacities, and SH coefficients—supervised solely by stochastic solid volume rendering of depth maps—remains untested by the provided text. The skeptic concern that VFMs are optimized for 2D semantics rather than precise 3D geometry is therefore not yet addressed by concrete evidence such as failure-case analysis or controlled ablations that isolate the voxel module.
Authors: The current manuscript already contains ablation studies (Section 4.3) that remove the voxel module and report corresponding drops in depth and reconstruction accuracy, together with failure-case visualizations in the supplement. To make the geometric-signal argument more explicit, we will add a short dedicated paragraph in Section 3.2 and expand the ablation table with an additional row that isolates the voxel module while keeping the frozen VFM fixed. revision: partial
Circularity Check
No derivation chain or equations present; architectural proposal with empirical claims only.
full rationale
The provided abstract and description contain no equations, no claimed first-principles derivations, no fitted parameters presented as predictions, and no self-citations invoked as load-bearing uniqueness theorems. The method is described as an architectural design (frozen VFM + voxel module + regression + volume rendering supervision) whose performance is asserted via dataset benchmarks rather than any mathematical reduction to inputs. Without any load-bearing steps that reduce by construction, the circularity score is 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Features from a frozen pretrained visual foundation model remain useful for geometric understanding when combined with a differentiable voxel module.
Reference graph
Works this paper leans on
-
[1]
Large-scale data for multiple-view stere- opsis
Aanaes, HenrikJensen, RamsbolVogiatzis, R., GeorgeTola, Engin- Dahl, Bjorholm, A., 2016. Large-scale data for multiple-view stere- opsis. International Journal of Computer Vision 120
2016
-
[2]
Barron,J.T.,Mildenhall,B.,Verbin,D.,Srinivasan,P.P.,Hedman,P.,
-
[3]
5470–5479
Mip-nerf 360: Unbounded anti-aliased neural radiance fields, in:ProceedingsoftheIEEE/CVFconferenceoncomputervisionand pattern recognition, pp. 5470–5479
-
[4]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J., 2024. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. arXiv preprint arXiv:2403.14627
-
[5]
Scannet: Richly-annotated 3d reconstructions of indoor scenes, in: Proc
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner, M., 2017. Scannet: Richly-annotated 3d reconstructions of indoor scenes, in: Proc. Computer Vision and Pattern Recognition (CVPR), IEEE
2017
-
[6]
FlashAttention-2: Faster attention with better paral- lelism and work partitioning, in: International Conference on Learn- ing Representations (ICLR)
Dao, T., 2024. FlashAttention-2: Faster attention with better paral- lelism and work partitioning, in: International Conference on Learn- ing Representations (ICLR)
2024
-
[7]
Superpoint:Self- supervised interest point detection and description, in: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp
DeTone,D.,Malisiewicz,T.,Rabinovich,A.,2018. Superpoint:Self- supervised interest point detection and description, in: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 224–236
2018
-
[8]
Real-time plane-sweeping stereo with multiple sweeping directions, J.K
Gallup,D.,Frahm,J.M.,Mordohai,P.,Yang,Q.,Pollefeys,M.,2007. Real-time plane-sweeping stereo with multiple sweeping directions, J.K. Krishnan et al.:Preprint submitted to ElsevierPage 12 of 15 Leveraging social media news Method 3 Views 10 Views 20 Views RMSE↓ABS↓𝛿 1.25 ↑𝛿 1.05 ↑ RMSE↓ABS↓𝛿 1.25 ↑𝛿 1.05 ↑ RMSE↓ABS↓𝛿 1.25 ↑𝛿 1.05 ↑ Replica Dataset[33] MVSpl...
2007
-
[9]
Vision meets robotics:Thekittidataset
Geiger, A., Lenz, P., Stiller, C., Urtasun, R., 2013. Vision meets robotics:Thekittidataset. InternationalJournalofRoboticsResearch (IJRR)
2013
-
[10]
Rgbd gs-icp slam, in: European conference on computer vision, Springer
Ha, S., Yeon, J., Yu, H., 2024. Rgbd gs-icp slam, in: European conference on computer vision, Springer. pp. 180–197
2024
-
[11]
In: ACM SIGGRAPH 2024 Conference Pa- pers
Huang, B., Yu, Z., Chen, A., Geiger, A., Gao, S., 2024. 2d gaussian splatting for geometrically accurate radiance fields, in: SIGGRAPH 2024 Conference Papers, Association for Computing Machinery. doi:10.1145/3641519.3657428
-
[12]
Huang, H., Wu, Y., Deng, C., Gao, G., Gu, M., Liu, Y.S., 2025. Fatesgs: Fast and accurate sparse-view surface reconstruction using gaussian splatting with depth-feature consistency, in: Proceedings of the AAAI Conference on Artificial Intelligence
2025
-
[13]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al., 2025. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics (TOG) 44, 1–16
2025
-
[14]
Splatam: Splat track & map 3d gaussians for dense rgb-d slam, in: Proceedings of the IEEE/CVF J.K
Keetha, N., Karhade, J., Jatavallabhula, K.M., Yang, G., Scherer, S., Ramanan, D., Luiten, J., 2024. Splatam: Splat track & map 3d gaussians for dense rgb-d slam, in: Proceedings of the IEEE/CVF J.K. Krishnan et al.:Preprint submitted to ElsevierPage 13 of 15 Leveraging social media news conference on computer vision and pattern recognition, pp. 21357– 21366
2024
-
[15]
MapAnything: Universal feed-forward metric 3D reconstruction, in: International Conference on 3D Vision (3DV), IEEE
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera,M.,Bulò,S.R.,Richardt,C.,Ramanan,D.,Scherer, S., Kontschieder, P., 2026. MapAnything: Universal feed-forward metric 3D reconstruction, in: International Conference on 3D Vision (3DV), IEEE
2026
-
[16]
3d gaussiansplattingforreal-timeradiancefieldrendering
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., 2023. 3d gaussiansplattingforreal-timeradiancefieldrendering. ACMTrans- actions on Graphics 42. URL:https://repo-sam.inria.fr/fungraph/ 3d-gaussian-splatting/
2023
-
[17]
Tanks and temples: Benchmarking large-scale scene reconstruction
Knapitsch, A., Park, J., Zhou, Q.Y., Koltun, V., 2017. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics 36
2017
-
[18]
Iggt: Instance-grounded geometry transformer for semantic 3d reconstruction
Li, H., Zou, Z., Liu, F., Zhang, X., Hong, F., Cao, Y., Lan, Y., Zhang, M., Yu, G., Zhang, D., et al., 2025. Iggt: Instance-grounded geometry transformer for semantic 3d reconstruction. arXiv preprint arXiv:2510.22706
-
[19]
Tokensplat: Token-aligned3dgaussiansplattingforfeed-forwardpose-freerecon- struction
Li, Y., Lv, C., Tang, Z., Yang, H., Huang, D., 2026. Tokensplat: Token-aligned3dgaussiansplattingforfeed-forwardpose-freerecon- struction. arXiv preprint arXiv:2603.00697
-
[20]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B., 2025. Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Scale invariant feature transform
Lindeberg, T., 2012. Scale invariant feature transform
2012
-
[22]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Lu, T., Yu, M., Xu, L., Xiangli, Y., Wang, L., Lin, D., Dai, B., 2024. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20654–20664
2024
-
[23]
Rethinking network design and local geometry in point cloud: A simple residual mlp framework
Ma, X., Qin, C., You, H., Ran, H., Fu, Y., 2022. Rethinking network design and local geometry in point cloud: A simple residual mlp framework. arXiv preprint arXiv:2202.07123
-
[24]
Gnerf: Gan-based neural radiance field without posed camera, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Meng, Q., Chen, A., Luo, H., Wu, M., Su, H., Xu, L., He, X., Yu, J., 2021. Gnerf: Gan-based neural radiance field without posed camera, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6351–6361
2021
-
[25]
Nerf: Representing scenes as neural radiance fields for view synthesis, in: ECCV
Mildenhall,B.,Srinivasan,P.P.,Tancik,M.,Barron,J.T.,Ramamoor- thi, R., Ng, R., 2020. Nerf: Representing scenes as neural radiance fields for view synthesis, in: ECCV
2020
-
[26]
Objects as volumes: A stochastic geometry view of opaque solids
Miller, B., Chen, H., Lai, A., Gkioulekas, I., 2023. Objects as volumes: A stochastic geometry view of opaque solids. IEEE
2023
-
[27]
Dinov2: Learning robust visual features without supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Howes, R., Huang, P.Y., Xu, H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P., 2023. Dinov2: Learning robust visua...
2023
-
[28]
Global structure-from-motion revisited, in: European Conference on Com- puter Vision, Springer
Pan, L., Baráth, D., Pollefeys, M., Schönberger, J.L., 2024. Global structure-from-motion revisited, in: European Conference on Com- puter Vision, Springer. pp. 58–77
2024
-
[29]
Vision transformers for dense prediction
Ranftl, R., Bochkovskiy, A., Koltun, V., 2021. Vision transformers for dense prediction. ArXiv preprint
2021
-
[30]
Fastgs:Training3dgaussian splatting in 100 seconds
Ren,S.,Wen,T.,Fang,Y.,Lu,B.,2025. Fastgs:Training3dgaussian splatting in 100 seconds. arXiv preprint arXiv:2511.04283
-
[31]
Superglue: Learning feature matching with graph neural networks, in:ProceedingsoftheIEEE/CVFconferenceoncomputervisionand pattern recognition, pp
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A., 2020. Superglue: Learning feature matching with graph neural networks, in:ProceedingsoftheIEEE/CVFconferenceoncomputervisionand pattern recognition, pp. 4938–4947
2020
-
[32]
Structure-from-motion revis- ited, in: Conference on Computer Vision and Pattern Recognition (CVPR)
Schönberger, J.L., Frahm, J.M., 2016. Structure-from-motion revis- ited, in: Conference on Computer Vision and Pattern Recognition (CVPR)
2016
-
[33]
Pixel- wise view selection for unstructured multi-view stereo, in: European Conference on Computer Vision (ECCV)
Schönberger,J.L.,Zheng,E.,Pollefeys,M.,Frahm,J.M.,2016. Pixel- wise view selection for unstructured multi-view stereo, in: European Conference on Computer Vision (ECCV)
2016
-
[34]
The Replica Dataset: A Digital Replica of Indoor Spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., Clarkson, A., Yan, M., Budge, B., Yan, Y., Pan, X., Yon, J., Zou, Y., Leon, K., Carter, N., Briales, J., Gillingham, T., Mueggler, E., Pesqueira, L., Savva, M., Batra, D., Strasdat, H.M., Nardi, R.D., Goesele, M., Lovegrove, S., Newcombe,R.,20...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Sparsityinvariantcnns,in:InternationalConferenceon3D Vision (3DV)
Uhrig, J., Schneider, N., Schneider, L., Franke, U., Brox, T., Geiger, A.,2017. Sparsityinvariantcnns,in:InternationalConferenceon3D Vision (3DV)
2017
-
[36]
Amb3r: Accurate feed-forward metric-scale 3d reconstruction with backend
Wang, H., Agapito, L., 2025. Amb3r: Accurate feed-forward metric-scale 3d reconstruction with backend. arXiv preprint arXiv:2511.20343
-
[37]
Vggt:Visualgeometrygroundedtransformer,in:Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang,J.,Chen,M.,Karaev,N.,Vedaldi,A.,Rupprecht,C.,Novotny, D.,2025a. Vggt:Visualgeometrygroundedtransformer,in:Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
-
[38]
Wang, J., Chen, M., Zhang, S., Karaev, N., Schönberger, J., Labatut, P., Bojanowski, P., Novotny, D., Vedaldi, A., Rupprecht, C., 2026. Vggt-𝜔. URL:https://arxiv.org/abs/2605.15195,arXiv:2605.15195
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Vggsfm: Visual geometry grounded deep structure from motion, in: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Wang, J., Karaev, N., Rupprecht, C., Novotny, D., 2024a. Vggsfm: Visual geometry grounded deep structure from motion, in: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 21686–21697
-
[40]
Dust3r: Geometric 3d vision made easy, in: CVPR
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J., 2024b. Dust3r: Geometric 3d vision made easy, in: CVPR
-
[41]
VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
Wang, W., Chen, Y., Zhang, Z., Liu, H., Wang, H., Feng, Z., Qin, W., Chen, F., Zhu, Z., Chen, D.Y., Zhuang, B., 2025b. Volsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction. arXiv preprint arXiv:2509.19297
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang,J.,Shen,C.,He,T.,2025c.𝜋 3:Permutation-EquivariantVisual Geometry Learning. arXiv preprint arXiv:2507.13347
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Image qualityassessment:fromerrorvisibilitytostructuralsimilarity
Wang,Z.,Bovik,A.C.,Sheikh,H.R.,Simoncelli,E.P.,2004a. Image qualityassessment:fromerrorvisibilitytostructuralsimilarity. IEEE transactions on image processing 13, 600–612
-
[44]
Image qualityassessment:fromerrorvisibilitytostructuralsimilarity
Wang,Z.,Bovik,A.C.,Sheikh,H.R.,Simoncelli,E.P.,2004b. Image qualityassessment:fromerrorvisibilitytostructuralsimilarity. IEEE Trans Image Process 13
-
[45]
Nerf–: Neural radiance fields without known camera parameters
Wang, Z., Wu, S., Xie, W., Chen, M., Prisacariu, V.A., 2021. Nerf–: Neural radiance fields without known camera parameters
2021
-
[46]
4d gaussian splatting for real-time dynamic scene rendering,in:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR), pp
Wu,G.,Yi,T.,Fang,J.,Xie,L.,Zhang,X.,Wei,W.,Liu,W.,Tian,Q., Wang, X., 2024a. 4d gaussian splatting for real-time dynamic scene rendering,in:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR), pp. 20310–20320
-
[47]
Sparse2dgs: Geometry-prioritized gaussian splatting for surface reconstruction from sparse views
Wu,J.,Li,R.,Zhu,Y.,Guo,R.,Sun,J.,Zhang,Y.,2025. Sparse2dgs: Geometry-prioritized gaussian splatting for surface reconstruction from sparse views. arXiv preprint arXiv:2504.20378
-
[48]
Point transformer v3: Simpler, faster, stronger, in: CVPR
Wu, X., Jiang, L., Wang, P.S., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., Zhao, H., 2024b. Point transformer v3: Simpler, faster, stronger, in: CVPR
-
[49]
Depthsplat: Connecting gaussian splatting and depth, in: CVPR
Xu,H.,Peng,S.,Wang,F.,Blum,H.,Barath,D.,Geiger,A.,Pollefeys, M., 2025. Depthsplat: Connecting gaussian splatting and depth, in: CVPR
2025
-
[50]
Freesplatter: Pose-free gaus- sian splatting for sparse-view 3d reconstruction
Xu, J., Gao, S., Shan, Y., 2024. Freesplatter: Pose-free gaus- sian splatting for sparse-view 3d reconstruction. arXiv preprint arXiv:2412.09573
-
[51]
Mvsnet: Depth inference for unstructured multi-view stereo
Yao, Y., Luo, Z., Li, S., Fang, T., Quan, L., 2018. Mvsnet: Depth inference for unstructured multi-view stereo. European Conference on Computer Vision (ECCV)
2018
-
[52]
Yonosplat: You only need one model for feedforward 3d gaussian splatting
Ye, B., Chen, B., Xu, H., Barath, D., Pollefeys, M., 2025. Yonosplat: You only need one model for feedforward 3d gaussian splatting. arXiv:2511.07321
-
[53]
Geometry- grounded gaussian splatting
Zhang, B., Jiang, C., Li, H., Shen, S., Tan, P., 2026. Geometry- grounded gaussian splatting. arXiv preprint arXiv:2601.17835
-
[54]
The unreasonable effectiveness of deep features as a perceptual metric
Zhang,R.,Isola,P.,Efros,A.A.,Shechtman,E.,Wang,O.,2018. The unreasonable effectiveness of deep features as a perceptual metric. IEEE
2018
-
[55]
Applied Intelligence 55, 1118
Zhao,Y.,Yi,J.,Pan,Y.,Chen,L.,2025.Robustgeometricreconstruc- tion of rgb-d data based on gaussian splatting. Applied Intelligence 55, 1118. J.K. Krishnan et al.:Preprint submitted to ElsevierPage 14 of 15 Leveraging social media news
2025
-
[56]
Voxel- splat: Dynamic gaussian splatting as an effective loss for occupancy and flow prediction, in: Proceedings of the Computer Vision and Pattern Recognition Conference, pp
Zhu, Z., Wang, S., Xie, J., Liu, J.j., Wang, J., Yang, J., 2025. Voxel- splat: Dynamic gaussian splatting as an effective loss for occupancy and flow prediction, in: Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 6761–6771. Yibin Zhaois currently a Ph.D. student at East China University of Science and Technology at Shanghai. He...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.