Recognition: 2 theorem links
· Lean TheoremEntityBench: Towards Entity-Consistent Long-Range Multi-Shot Video Generation
Pith reviewed 2026-05-15 03:10 UTC · model grok-4.3
The pith
Explicit per-entity memory maintains character consistency across long gaps in multi-shot video generation where existing methods fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
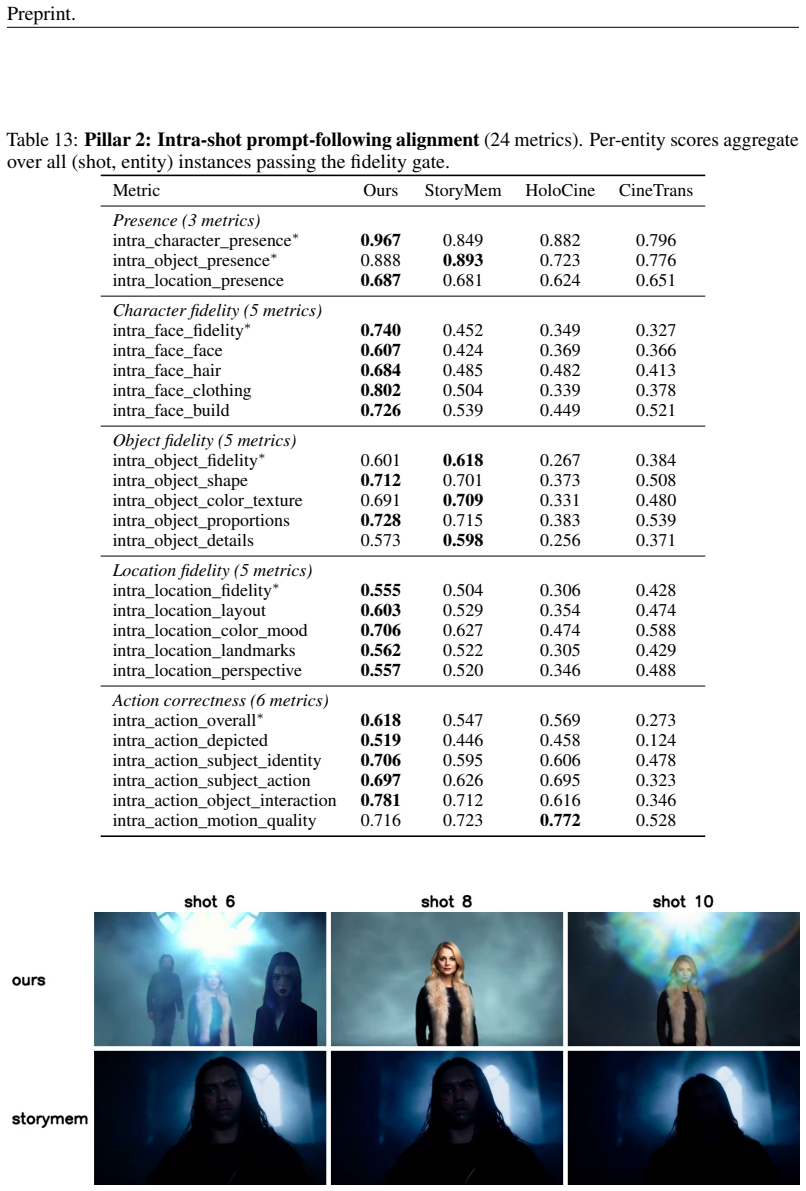
EntityBench supplies explicit entity schedules across 140 episodes with up to 13 recurring characters, 8 locations, and 22 objects per episode, while EntityMem stores verified per-entity visual references in a memory bank and produces the highest cross-shot character fidelity (Cohen's d = +2.33) and presence among evaluated systems; existing methods show sharp degradation in consistency as recurrence distance grows.
What carries the argument
Persistent per-entity memory bank that stores verified visual references before generation begins and retrieves them for each subsequent shot.
If this is right
- Cross-shot entity consistency in existing video models falls sharply as the number of shots between appearances increases.
- Storing verified per-entity references in a memory bank produces the largest measured gains in character fidelity and presence.
- The three-pillar evaluation separates intra-shot quality, prompt following, and cross-shot consistency so each can be measured independently.
- Benchmarks that track multiple entity types simultaneously across up to 50 shots expose failure modes missed by simpler prompt sets.
Where Pith is reading between the lines
- Video generation pipelines could adopt similar memory banks as a default module to support longer coherent stories.
- The same entity-schedule format could be reused to test consistency in image-to-video or text-to-3D pipelines.
- Recurrence-distance curves may become a standard diagnostic plot for any multi-shot generation system.
- If the fidelity gate proves robust, it could be applied to filter training data for future models.
Load-bearing premise
Entity schedules extracted from real narrative media together with the fidelity gate used for scoring accurately capture the consistency problems that current video models actually face.
What would settle it
A new generation method that achieves equal or higher character fidelity and presence scores on the 140 EntityBench episodes without any per-entity memory bank would refute the claim that explicit memory is required.
Figures























read the original abstract
Multi-shot video generation extends single-shot generation to coherent visual narratives, yet maintaining consistent characters, objects, and locations across shots remains a challenge over long sequences. Existing evaluations typically use independently generated prompt sets with limited entity coverage and simple consistency metrics, making standardized comparison difficult. We introduce EntityBench, a benchmark of 140 episodes (2,491 shots) derived from real narrative media, with explicit per-shot entity schedules tracking characters, objects, and locations simultaneously across easy / medium / hard tiers of up to 50 shots, 13 cross-shot characters, 8 cross-shot locations, 22 cross-shot objects, and recurrence gaps spanning up to 48 shots. It is paired with a three-pillar evaluation suite that disentangles intra-shot quality, prompt-following alignment, and cross-shot consistency, with a fidelity gate that admits only accurate entity appearances into cross-shot scoring. As a baseline, we propose EntityMem, a memory-augmented generation system that stores verified per-entity visual references in a persistent memory bank before generation begins. Experiments show that cross-shot entity consistency degrades sharply with recurrence distance in existing methods, and that explicit per-entity memory yields the highest character fidelity (Cohen's d = +2.33) and presence among methods evaluated. Code and data are available at https://github.com/Catherine-R-He/EntityBench/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EntityBench, a benchmark of 140 episodes (2,491 shots) derived from real narrative media, featuring explicit per-shot entity schedules for characters, objects, and locations across easy/medium/hard tiers with recurrence gaps up to 48 shots. It defines a three-pillar evaluation (intra-shot quality, prompt alignment, cross-shot consistency) that incorporates a fidelity gate to filter entity appearances before scoring consistency. As a baseline, the authors propose EntityMem, which maintains a persistent memory bank of verified per-entity visual references, and report that existing methods show sharp consistency degradation with recurrence distance while EntityMem achieves the highest character fidelity (Cohen's d = +2.33) and presence.
Significance. If the benchmark construction and fidelity gate are shown to be robust, the work would supply a standardized, entity-rich evaluation resource for long-range multi-shot video generation that improves on prior prompt-only or short-sequence tests. The empirical demonstration that explicit per-entity memory outperforms recurrence-based methods on character fidelity would provide a concrete engineering direction for narrative video systems, with the released code and data increasing its immediate utility.
major comments (3)
- [§3.2] §3.2 (fidelity gate): The gate is described as admitting only accurate entity appearances into cross-shot scoring, yet no implementation details (embedding threshold, reference selection, or human judgment protocol), sensitivity analysis on the threshold, or inter-annotator agreement are reported. Because the degradation curves and Cohen's d = +2.33 result are computed exclusively on gate-passing entities, this omission directly undermines the central empirical claims.
- [§3.1] §3.1 (entity schedule extraction): The process of deriving per-shot schedules and assigning easy/medium/hard tiers from real narrative media is outlined but lacks validation metrics such as inter-annotator agreement or agreement with model failure modes. The recurrence-distance degradation result and tier-wise comparisons rest on these schedules accurately reflecting the consistency problem; without such checks the benchmark's external validity is unclear.
- [Experiments / Table 3] Experiments section / Table 3: Baseline comparisons do not report model sizes, training data volumes, or hyperparameter controls for the evaluated generators. Without these controls it is impossible to isolate whether the reported +2.33 Cohen's d advantage is attributable to the EntityMem memory bank or to differences in underlying model capacity.
minor comments (3)
- [Figure 2] Figure 2: The memory-bank diagram would be clearer with an explicit arrow or caption indicating the verification step before storage.
- [§4] §4: The recurrence-distance metric is used throughout but never given an explicit equation; adding one would remove ambiguity when comparing to prior work.
- [References] References: Several recent multi-shot video papers on identity preservation are absent; adding them would strengthen the related-work positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. Where the manuscript requires additional details or analysis, we will revise accordingly to strengthen the presentation of EntityBench and EntityMem.
read point-by-point responses
-
Referee: [§3.2] §3.2 (fidelity gate): The gate is described as admitting only accurate entity appearances into cross-shot scoring, yet no implementation details (embedding threshold, reference selection, or human judgment protocol), sensitivity analysis on the threshold, or inter-annotator agreement are reported. Because the degradation curves and Cohen's d = +2.33 result are computed exclusively on gate-passing entities, this omission directly undermines the central empirical claims.
Authors: We agree that the current description of the fidelity gate lacks sufficient implementation details. In the revised manuscript we will expand §3.2 to specify the embedding model and exact threshold used for verification, the protocol for selecting reference images from the memory bank, and the human judgment protocol. We will also report inter-annotator agreement for the verification step and include a sensitivity analysis showing how Cohen's d and degradation curves vary with threshold choice. These additions will directly support the robustness of the reported results. revision: yes
-
Referee: [§3.1] §3.1 (entity schedule extraction): The process of deriving per-shot schedules and assigning easy/medium/hard tiers from real narrative media is outlined but lacks validation metrics such as inter-annotator agreement or agreement with model failure modes. The recurrence-distance degradation result and tier-wise comparisons rest on these schedules accurately reflecting the consistency problem; without such checks the benchmark's external validity is unclear.
Authors: We acknowledge the value of explicit validation metrics. In the revision we will add inter-annotator agreement statistics for both the per-shot entity schedule derivation and the easy/medium/hard tier assignment. We will further include a short analysis comparing the defined tiers against observed failure modes of the evaluated models. These metrics will help confirm that the schedules accurately capture the long-range consistency challenge and thereby support the recurrence-distance and tier-wise findings. revision: yes
-
Referee: Experiments section / Table 3: Baseline comparisons do not report model sizes, training data volumes, or hyperparameter controls for the evaluated generators. Without these controls it is impossible to isolate whether the reported +2.33 Cohen's d advantage is attributable to the EntityMem memory bank or to differences in underlying model capacity.
Authors: The generators evaluated are off-the-shelf models from prior publications; we used their publicly released implementations without retraining. In the revised Experiments section we will add a table listing parameter counts, training-data descriptions, and the hyperparameter settings employed during our runs. Because EntityMem is applied as a plug-in memory augmentation on top of each base generator, our primary comparisons hold the underlying model fixed and vary only the presence of the memory bank. While exhaustive capacity-matched retraining is outside the scope of this benchmark paper, the added details will allow readers to assess potential capacity confounds. revision: partial
Circularity Check
No circularity: empirical benchmark with external data and explicit engineering choices
full rationale
The paper constructs EntityBench from real narrative media with per-shot entity schedules and introduces a fidelity gate as part of its three-pillar evaluation. It then evaluates an explicit baseline (EntityMem) against other methods on this benchmark. No equations, derivations, or predictions are present that reduce by construction to fitted inputs, self-citations, or ansatzes. The central results are comparative empirical measurements on held-out data, with no load-bearing step that renames or re-derives its own inputs. This is a standard benchmark paper whose claims rest on the external validity of the media-derived schedules rather than internal self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entity schedules derived from real narrative media capture representative consistency challenges for multi-shot video generation
invented entities (1)
-
EntityMem persistent memory bank
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
explicit per-shot entity schedules tracking characters, objects, and locations simultaneously across easy / medium / hard tiers of up to 50 shots, 13 cross-shot characters, 8 cross-shot locations, 22 cross-shot objects, and recurrence gaps spanning up to 48 shots
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel and Jcost_pos_of_ne_one unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fidelity gate that admits only accurate entity appearances into cross-shot scoring
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mixture of contexts for long video generation
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Junfei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, et al. Mixture of contexts for long video generation. arXiv preprint arXiv:2508.21058,
-
[2]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Xiaokun Feng, Haiming Yu, Meiqi Wu, Shiyu Hu, Jintao Chen, Chen Zhu, Jiahong Wu, Xiangxiang Chu, and Kaiqi Huang. Narrlv: Towards a comprehensive narrative-centric evaluation for long video generation.arXiv preprint arXiv:2507.11245,
-
[5]
Longvie: Multimodal-guided controllable ultra-long video generation
Jianxiong Gao, Zhaoxi Chen, Xian Liu, Jianfeng Feng, Chenyang Si, Yanwei Fu, Yu Qiao, and Ziwei Liu. Longvie: Multimodal-guided controllable ultra-long video generation.arXiv preprint arXiv:2508.03694,
-
[6]
Id- animator: Zero-shot identity-preserving human video generation.arXiv preprint arXiv:2404.15275,
Xuanhua He, Quande Liu, Shengju Qian, Xin Wang, Tao Hu, Ke Cao, Keyu Yan, and Jie Zhang. Id- animator: Zero-shot identity-preserving human video generation.arXiv preprint arXiv:2404.15275,
-
[7]
Kaiyi Huang, Yukun Huang, Xintao Wang, Zinan Lin, Xuefei Ning, Pengfei Wan, Di Zhang, Yu Wang, and Xihui Liu. Filmaster: Bridging cinematic principles and generative ai for automated film generation.arXiv preprint arXiv:2506.18899, 2025a. Lianghua Huang, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Huanzhang Dou, Chen Liang, Yutong Feng, Yu Liu, and Jingren Zhou. In...
-
[8]
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning.arXiv preprint arXiv:2309.15091,
-
[9]
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025a. Lijie Liu, Tianxiang Ma, Bingchuan Li, Zhuowei Chen, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, and Xinglong Wu. Phantom: Subject-consistent video generation via cross-modal alignment. In Proceed...
-
[10]
Yawen Luo, Xiaoyu Shi, Junhao Zhuang, Yutian Chen, Quande Liu, Xintao Wang, Pengfei Wan, and Tianfan Xue. Shotstream: Streaming multi-shot video generation for interactive storytelling.arXiv preprint arXiv:2603.25746,
-
[11]
Xiangyu Meng, Zixian Zhang, Zhenghao Zhang, Junchao Liao, Long Qin, and Weizhi Wang. Identity- grpo: Optimizing multi-human identity-preserving video generation via reinforcement learning. arXiv preprint arXiv:2510.14256, 2025a. Yihao Meng, Hao Ouyang, Yue Yu, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Hanlin Wang, Yixuan Li, Cheng Chen, Yanhong Zeng, et al. H...
-
[12]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Haoyuan Shi, Yunxin Li, Nanhao Deng, Zhenran Xu, Xinyu Chen, Longyue Wang, Baotian Hu, and Min Zhang. Msvbench: Towards human-level evaluation of multi-shot video generation.arXiv preprint arXiv:2602.23969,
-
[14]
Jaskirat Singh, Junshen Kevin Chen, Jonas Kohler, and Michael Cohen. Storybooth: Training-free multi-subject consistency for improved visual storytelling.arXiv preprint arXiv:2504.05800,
-
[15]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Echoshot: Multi-shot portrait video generation
Jiahao Wang, Hualian Sheng, Sijia Cai, Weizhan Zhang, Caixia Yan, Yachuang Feng, Bing Deng, and Jieping Ye. Echoshot: Multi-shot portrait video generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Qinghe Wang, Xiaoyu Shi, Baolu Li, Weikang Bian, Quande Liu, Huchuan Lu, Xintao Wang, Pengfei Wan, Kun Gai, and Xu ...
-
[17]
Moviebench: A hierarchical movie level dataset for long video generation
Weijia Wu, Mingyu Liu, Zeyu Zhu, Xi Xia, Haoen Feng, Wen Wang, Kevin Qinghong Lin, Chunhua Shen, and Mike Zheng Shou. Moviebench: A hierarchical movie level dataset for long video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 28984–28994, 2025a. Xiaoxue Wu, Bingjie Gao, Yu Qiao, Yaohui Wang, and Xinyuan Chen. Cin...
-
[18]
Zhifei Xie, Daniel Tang, Dingwei Tan, Jacques Klein, Tegawend F Bissyand, and Saad Ezzini. Dreamfactory: Pioneering multi-scene long video generation with a multi-agent framework.arXiv preprint arXiv:2408.11788,
-
[19]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622,
work page internal anchor Pith review arXiv
-
[20]
Songlin Yang, Zhe Wang, Xuyi Yang, Songchun Zhang, Xianghao Kong, Taiyi Wu, Xiaotong Zhao, Ran Zhang, Alan Zhao, and Anyi Rao. Shotverse: Advancing cinematic camera control for text-driven multi-shot video creation.arXiv preprint arXiv:2603.11421,
-
[21]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity- rope: Action-controllable infinite video generation emerges from autoregressive self-rollout.arXiv preprint arXiv:2511.20649,
-
[23]
Opens2v-nexus: A detailed benchmark and million-scale dataset for subject-to-video generation
Shenghai Yuan, Xianyi He, Yufan Deng, Yang Ye, Jinfa Huang, Bin Lin, Jiebo Luo, and Li Yuan. Opens2v-nexus: A detailed benchmark and million-scale dataset for subject-to-video generation. arXiv preprint arXiv:2505.20292, 2025a. Shenghai Yuan, Jinfa Huang, Xianyi He, Yunyang Ge, Yujun Shi, Liuhan Chen, Jiebo Luo, and Li Yuan. Identity-preserving text-to-vi...
-
[24]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Concat-id: Towards universal identity-preserving video synthesis
Yong Zhong, Zhuoyi Yang, Jiayan Teng, Xiaotao Gu, and Chongxuan Li. Concat-id: Towards universal identity-preserving video synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1906–1915,
work page 1906
-
[27]
Jinsong Zhou, Yihua Du, Xinli Xu, Luozhou Wang, Zijie Zhuang, Yehang Zhang, Shuaibo Li, Xiaojun Hu, Bolan Su, and Ying-cong Chen. Videomemory: Toward consistent video generation via memory integration.arXiv preprint arXiv:2601.03655,
-
[28]
2c+1o” denotes “≥2 characters and ≥1 object,
plus a fixed-length stress test, measuring both typical-case behavior (easy/medium) and worst-case scaling (hard) within a tractable compute budget. 14 Preprint. 2 4 6 8 10 12 Characters / episode 0 5 10 15 20 25 30# episodes median=7.0 10 20 30 40 50 Objects / episode 0 5 10 15 20 25 30# episodes median=13.0 2 4 6 8 10 12 14 Locations / episode 0 10 20 3...
work page 2000
-
[29]
image and text embeddings respec- tively (jointly trained, 512-dim, unit-normalized). For an image x and text t, the CLIP text-image similarity is CLIPsim(x, t) =ϕ img CLIP(x)⊤ϕtxt CLIP(t)∈[−1,1].(1) Grounding.Let G denote the GroundingDINO(Liu et al., 2024a) detector with text encoder bert-base-uncased. For frame f and query q, G(f, q) returns a (possibl...
work page 2025
-
[30]
did the action use the object correctly
optical flow is used to interpolate intermediate frames; MS(Sk) is the mean reconstruction quality of the interpolation, with higher values indicating smoother apparent motion. Implementation follows Huang et al. (2024b). 21 Preprint. Dynamic degree(range [0,1] ): the fraction of inter-frame pairs whose RAFT optical flow magni- tude exceeds a threshold; p...
work page 2021
-
[31]
This appendix decomposes the corrected means into their two components for transparency
and Appendix F.1 aggregate asm= rawmean(m)×coverage(m) , where coverage is the fraction of eligible (shot, entity) instances that pass the fidelity gate (Equation 22). This appendix decomposes the corrected means into their two components for transparency. What coverage measures.For each per-entity metric, coverage answers a different question: For Pillar...
-
[32]
Place new characters on the side the camera panned toward Example: Previous shot had CharA at "right" with camera_angle="front". New shot introduces CharB and CharC. The camera should pan right to make room → camera_angle="right". CharA moves to "left" or "center-left". CharB and CharC enter at "center-right" and "right". If the retained character was at ...
-
[33]
shows little gap effect for any method, as DINOv2 cosine similarity reflects identity differently, discussed in Appendix F.4. 47 Preprint. Table 20:DINOv2 face similarity by gap distance.DINOv2 cosine similarity (mean of adjacent- pair sims to centroid) shows little gap effect across methods, consistent with embedding-similarity rewarding visual self-simi...
-
[34]
and universal identity-preserving synthesis (Zhong et al., 2025). However, these methods focus primarily on human facial identity for one or two subjects, leaving broader entity types, such as objects, locations, and character ensembles, largely unaddressed. LLM-Directed Video Generation.LLMs have been used as video planners to produce scene descriptions ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.