GRLO: Towards Generalizable Reinforcement Learning in Open-Ended Environments from Zero
Pith reviewed 2026-05-19 15:09 UTC · model grok-4.3
The pith
Reinforcement learning from open-ended conversations transfers to improve math and code performance without domain-specific training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRLO shows that reinforcement learning from a small set of interactions in open-ended environments produces models whose acquired conversational abilities transfer to downstream domains, delivering average performance gains from 24.1 to 63.1 on a Qwen3-4B-Base backbone with 5K prompts and 22.7 GPU hours, which is about 46 times less data and 68 times less compute than in-domain RLVR while matching heavily trained released models; a later in-domain RLVR stage adds only selective gains mainly on harder competition-math benchmarks.
What carries the argument
GRLO, the reinforcement learning process in open-ended environments from scratch that builds conversational abilities intended to transfer implicitly to reasoning and coding tasks.
If this is right
- The resulting model reaches performance levels competitive with Qwen's released post-trained models despite using much lower training cost.
- A follow-up in-domain RLVR stage after GRLO produces only selective additional gains, concentrated on harder competition-math benchmarks.
- Post-training can achieve strong cross-domain results with about 46 times less data and 68 times less compute than standard in-domain RLVR.
- Broadly capable models become feasible with far smaller interaction sets when training begins in open-ended rather than domain-specific environments.
Where Pith is reading between the lines
- This pattern suggests that collecting diverse conversational data may prove more efficient for general capabilities than curating separate datasets for each reasoning domain.
- One could test extensions by applying the same open-ended RL stage to other base models or measuring transfer to additional areas such as scientific problem solving.
- The selective benefit of later in-domain stages implies that open-ended training may already cover many easier reasoning cases, leaving only the hardest instances for targeted follow-up.
Load-bearing premise
Conversational abilities gained explicitly from RL in open-ended environments will transfer implicitly to raise performance on mathematical reasoning and code generation without any direct training on those domains.
What would settle it
An ablation that applies the same compute budget but skips the open-ended RL stage entirely and then measures whether average performance across math and code benchmarks remains near 24.1 instead of rising to 63.1 would directly test the transfer claim.
Figures
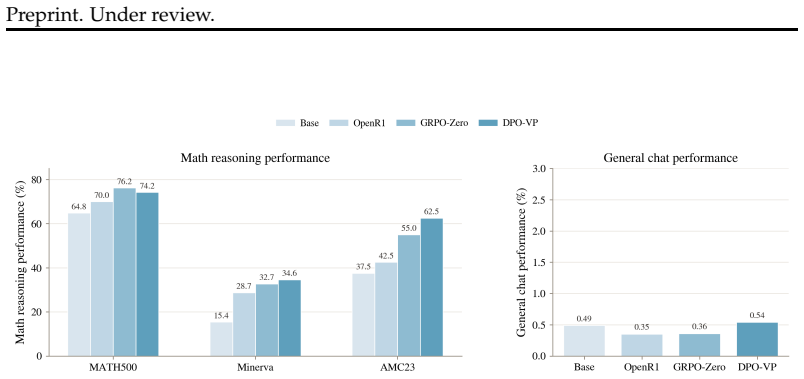
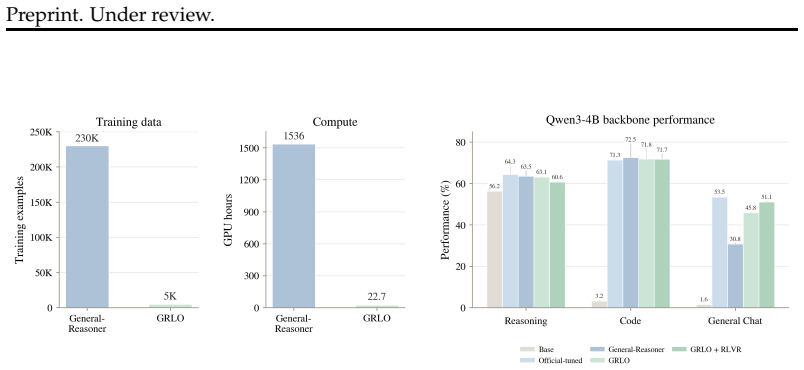





read the original abstract
Post-training has become a crucial step for unlocking the capabilities of large language models, with reinforcement learning (RL) emerging as a critical paradigm. Recent RL-based post-training has increasingly split into two paradigms: reinforcement learning from human feedback (RLHF), which optimizes models using human preference signals in target domains, and reinforcement learning from verifiable rewards (RLVR), which operates in verifier-backed environments. The latter has dominated recent reasoning-oriented post-training because it delivers stronger gains and higher efficiency on domain-specific tasks (e.g., reasoning). However, although in-domain RL training achieves promising performance, it still requires a substantial amount of GPU compute, which remains a major barrier to broad adoption. In this work, we study the generalization ability of RLHF learned from scratch from a small set of interactions in open-ended environments, and investigate whether the conversational abilities it explicitly acquires can implicitly transfer to downstream tasks such as mathematical reasoning and code generation, namely GRLO. Specifically, on Qwen3-4B-Base backbone, GRLO improves the average performance across all domains from 24.1 to 63.1 with only 5K prompts and 22.7 GPU hours, requiring about $46\times$ less data and $68\times$ less compute than a strong in-domain RLVR baseline. The resulting model is even competitive with Qwen's released post-trained models which required a much larger training cost. Notably, a subsequent in-domain RLVR stage brings only selective gains, mainly on harder competition-math benchmarks. We hope GRLO offers a simple and efficient recipe for building broadly capable post-trained models. Our code and data will be available at: \href{https://github.com/SJY8460/GRLO}{https://github.com/SJY8460/GRLO}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRLO, which applies RLHF from scratch in open-ended environments using only 5K prompts on the Qwen3-4B-Base model. It reports that this raises average performance across domains (including math and code) from 24.1 to 63.1, requires 46× less data and 68× less compute than a strong in-domain RLVR baseline, and yields a model competitive with Qwen's released post-trained models. A follow-up in-domain RLVR stage adds only selective gains on harder benchmarks. Code and data are promised to be released.
Significance. If the central empirical claims hold, the work would indicate that conversational abilities acquired via RLHF in open-ended settings can implicitly transfer to downstream reasoning and code tasks without direct domain-specific data, offering a lower-cost route to broadly capable post-trained models. The promised release of code and data strengthens reproducibility and allows independent verification of the efficiency claims.
major comments (2)
- [Abstract and §4] Abstract and §4: The efficiency ratios (46× less data, 68× less compute) and the 24.1-to-63.1 average-performance lift are presented as direct comparisons to an in-domain RLVR baseline, yet the manuscript provides no explicit description of the baseline's prompt count, implementation details, or exact evaluation protocol (including whether the same 5K-prompt regime or a larger set was used). This information is load-bearing for the central efficiency and generalization claims.
- [§3 and §4.1] §3 and §4.1: The open-ended prompt set is described only at a high level; there is no breakdown of prompt composition, presence of multi-step reasoning signals, or explicit checks for surface-pattern overlap with the math and code evaluation benchmarks. Without these details the implicit-transfer interpretation cannot be isolated from possible distributional leakage.
minor comments (2)
- [§2] §2: The notation for environment dynamics and reward formulation could be made more explicit to aid readers unfamiliar with the open-ended RLHF setup.
- [Figure 2 and Table 1] Figure 2 and Table 1: Axis labels and caption text are occasionally terse; expanding them would improve readability of the cross-domain results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to improve clarity on the baseline and prompt details, which we agree are important for supporting the central claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: The efficiency ratios (46× less data, 68× less compute) and the 24.1-to-63.1 average-performance lift are presented as direct comparisons to an in-domain RLVR baseline, yet the manuscript provides no explicit description of the baseline's prompt count, implementation details, or exact evaluation protocol (including whether the same 5K-prompt regime or a larger set was used). This information is load-bearing for the central efficiency and generalization claims.
Authors: We agree that a more explicit description of the in-domain RLVR baseline is needed to make the efficiency claims fully verifiable. In the revised manuscript we will expand the relevant section (currently §4) with a self-contained paragraph and table that specifies: the baseline used ~230K domain-specific prompts (far larger than the 5K open-ended set), the exact verifier and reward setup, training hyperparameters, and confirmation that evaluation uses the identical benchmark suite and protocol for all methods. This will directly substantiate the reported 46× data and 68× compute reductions without altering any numbers or conclusions. revision: yes
-
Referee: [§3 and §4.1] §3 and §4.1: The open-ended prompt set is described only at a high level; there is no breakdown of prompt composition, presence of multi-step reasoning signals, or explicit checks for surface-pattern overlap with the math and code evaluation benchmarks. Without these details the implicit-transfer interpretation cannot be isolated from possible distributional leakage.
Authors: We acknowledge that greater transparency on prompt composition would help readers assess the implicit-transfer interpretation. In the revision we will add to §3 (and a new Appendix C) a breakdown of the 5K-prompt distribution (approximately 45% general multi-turn dialogue, 25% creative/problem-solving, 20% instruction following, 10% other), representative examples, and the results of our post-hoc overlap analysis (n-gram and embedding-based) showing negligible surface or semantic overlap with the math and code evaluation sets. The prompts were intentionally generated to remain open-ended and domain-agnostic; these additions will make that design choice explicit without changing the experimental outcomes. revision: yes
Circularity Check
Empirical RL training results contain no derivational chain
full rationale
The paper reports direct experimental outcomes from running RLHF on 5K open-ended prompts using a Qwen3-4B-Base backbone, followed by benchmark evaluations on math, code, and other domains. No equations, uniqueness theorems, ansatzes, or first-principles derivations are presented that could reduce to fitted parameters, self-citations, or renamed inputs by construction. All performance numbers (e.g., 24.1 to 63.1 average) are measured post-training results rather than predictions derived from the training procedure itself, so the work is self-contained against external benchmarks with no circular structure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human preference signals collected in open-ended conversational interactions provide a training signal that generalizes to verifiable downstream tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRLO applies RLHF-style optimization on an open-ended, largely non-verifiable prompt distribution Dopen
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
max θ Ex∼Dopen,y∼πθ(·|x)[rϕ(x,y)] − β KL(πθ(·|x)∥πref(·|x))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
work page 2024
- [3]
-
[4]
Long-Short Chain-of-Thought Mixture Supervised Fine-Tuning Eliciting Efficient Reasoning in Large Language Models , author=. 2025 , eprint=
work page 2025
-
[5]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author=. 2025 , eprint=
work page 2025
- [6]
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[8]
Open R1: A fully open reproduction of DeepSeek-R1 , url =
-
[9]
UltraFeedback: Boosting Language Models with Scaled AI Feedback , author=. 2024 , eprint=
work page 2024
- [10]
-
[11]
Enhancing LLM Reasoning with Iterative DPO: A Comprehensive Empirical Investigation , author=. 2025 , eprint=
work page 2025
-
[12]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
work page 2021
-
[13]
Solving Quantitative Reasoning Problems with Language Models , author=. 2022 , eprint=
work page 2022
-
[14]
American Invitational Mathematics Examination (AIME) 2024 , author=
work page 2024
-
[15]
American Invitational Mathematics Examination (AIME) 2025 , author=
work page 2025
-
[16]
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy , author =. arXiv preprint arXiv:2507.01352 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
RewardBench: Evaluating Reward Models for Language Modeling , author=. 2024 , eprint=
work page 2024
-
[18]
Pass@K Policy Optimization: Solving Harder Reinforcement Learning Problems , author=. 2025 , eprint=
work page 2025
-
[19]
Adaptive Guidance Accelerates Reinforcement Learning of Reasoning Models , author=. 2025 , eprint=
work page 2025
- [20]
-
[21]
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning , author=. 2025 , eprint=
work page 2025
-
[22]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
- [23]
- [24]
-
[25]
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong. O lympiad B ench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. Proceedings of the ...
-
[26]
Generative Verifiers: Reward Modeling as Next-Token Prediction , author=. 2025 , eprint=
work page 2025
-
[27]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning , author=. 2025 , eprint=
work page 2025
- [28]
-
[29]
KTO: Model Alignment as Prospect Theoretic Optimization , author=. 2024 , eprint=
work page 2024
-
[30]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
A General Theoretical Paradigm to Understand Learning from Human Preferences , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , editor =
work page 2024
-
[31]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
-
[32]
Better Process Supervision with Bi-directional Rewarding Signals
Chen, Wenxiang and He, Wei and Xi, Zhiheng and Guo, Honglin and Hong, Boyang and Zhang, Jiazheng and Li, Nijun and Gui, Tao and Li, Yun and Zhang, Qi and Huang, Xuanjing. Better Process Supervision with Bi-directional Rewarding Signals. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.747
-
[33]
Demystifying Long Chain-of-Thought Reasoning in LLMs , author=. 2025 , eprint=
work page 2025
-
[34]
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for
Wei Xiong and Hanze Dong and Chenlu Ye and Ziqi Wang and Han Zhong and Heng Ji and Nan Jiang and Tong Zhang , booktitle=. Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for. 2024 , url=
work page 2024
-
[35]
The Thirteenth International Conference on Learning Representations , year=
Building Math Agents with Multi-Turn Iterative Preference Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[36]
Flow-DPO: Improving LLM Mathematical Reasoning through Online Multi-Agent Learning , author=. 2024 , eprint=
work page 2024
-
[37]
Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level , author=. 2024 , eprint=
work page 2024
-
[38]
Transactions on Machine Learning Research , issn=
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
work page 2024
-
[39]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models , author=. 2024 , eprint=
work page 2024
-
[40]
Bootstrapping Language Models with
Changyu Chen and Zichen Liu and Chao Du and Tianyu Pang and Qian Liu and Arunesh Sinha and Pradeep Varakantham and Min Lin , booktitle=. Bootstrapping Language Models with. 2025 , url=
work page 2025
-
[41]
Training Language Models to Follow Instructions with Human Feedback , author =. 2022 , eprint =
work page 2022
-
[42]
Xueguang Ma and Qian Liu and Dongfu Jiang and Ge Zhang and Zejun Ma and Wenhu Chen , booktitle =. General-Reasoner: Advancing. 2025 , url =
work page 2025
-
[43]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein and Bethel Chen and Oshin Agarwal and John Miller and Sidharth Dhand and Benjamin Schreiber and Max Tegmark , year =. 2311.12022 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Evaluating Large Language Models Trained on Code , author =. 2021 , eprint =
work page 2021
-
[45]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.