Process Rewards with Learned Reliability
Pith reviewed 2026-05-19 14:44 UTC · model grok-4.3
pith:VTEXE334 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{VTEXE334}
Prints a linked pith:VTEXE334 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A process reward model learns both step success probability and the reliability of that probability to guide more efficient reasoning search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
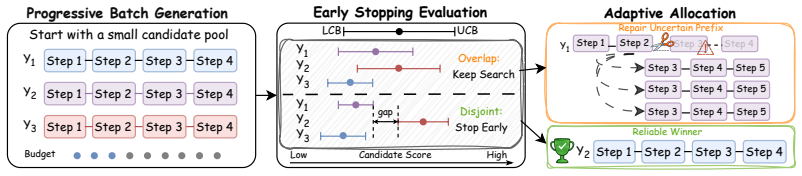
BetaPRM is a distributional process reward model that learns a Beta belief over each step's success probability by maximizing the Beta-Binomial likelihood of observed successful Monte Carlo continuations, rather than regressing to the sample success ratio. This yields an explicit reliability signal that downstream methods can use to decide when to trust a reward score. The signal supports improved Best-of-N selection and enables Adaptive Computation Allocation that spends extra tokens on uncertain candidate prefixes while stopping early on reliable high-reward paths.
What carries the argument
The Beta distribution over step success probability, fitted via Beta-Binomial likelihood to Monte Carlo continuation counts, which separates expected success rate from uncertainty around it.
If this is right
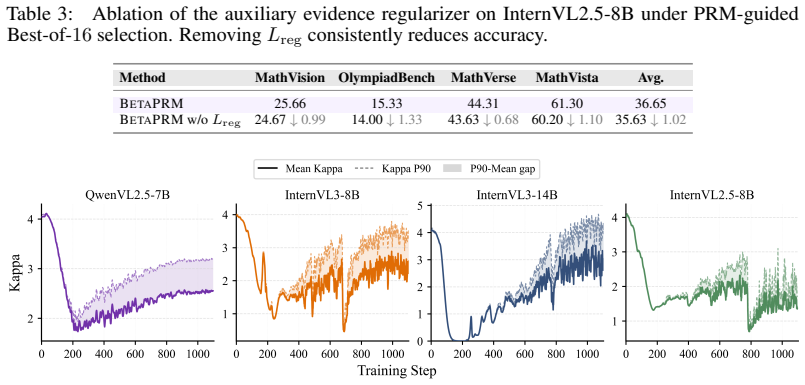
- BetaPRM improves PRM-guided Best-of-N selection across four backbones and four reasoning benchmarks while preserving step-level error detection.
- Adaptive Computation Allocation built on the reliability signal improves accuracy-token tradeoff over fixed-budget Best-of-16.
- Token usage drops by up to 33.57 percent with simultaneous gains in final-answer accuracy.
- The reliability signal lets systems distinguish trustworthy rewards from uncertain ones for better allocation decisions.
Where Pith is reading between the lines
- The same Beta modeling could extend to outcome reward models to decide when to trust final-answer scores.
- Search algorithms might dynamically branch more when reliability is low and prune when it is high.
- Calibration of the reliability signal could be tested directly against human step-by-step correctness judgments.
- Combining this learned reliability with ensemble or temperature-based uncertainty estimates might improve robustness further.
Load-bearing premise
The uncertainty captured by the Beta posterior from finite Monte Carlo continuations reflects genuine prediction reliability rather than sampling noise or biases in the continuation process itself.
What would settle it
Check whether steps assigned both high reward and high reliability actually produce correct final answers at higher rates than high-reward but low-reliability steps, measured on held-out problems.
Figures


read the original abstract
Process Reward Models (PRMs) provide step-level feedback for reasoning, but current PRMs usually output only a single reward score for each step. Downstream methods must therefore treat imperfect step-level reward predictions as reliable decision signals, with no indication of when these predictions should be trusted. We propose BetaPRM, a distributional PRM that predicts both a step-level success probability and the reliability of that prediction. Given step-success supervision from Monte Carlo continuations, BetaPRM learns a Beta belief that explains the observed number of successful continuations through a Beta-Binomial likelihood, rather than regressing to the finite-sample success ratio as a point target. This learned reliability signal indicates when a step reward should be trusted, enabling downstream applications to distinguish reliable rewards from uncertain ones. As one application, we introduce Adaptive Computation Allocation (ACA) for PRM-guided Best-of-N reasoning. ACA uses the learned reliability signal to stop when a high-reward solution is reliable and to spend additional computation on uncertain candidate prefixes. Experiments across four backbones and four reasoning benchmarks show that BetaPRM improves PRM-guided Best-of-N selection while preserving standard step-level error detection. Built on this signal, ACA improves the accuracy--token tradeoff over fixed-budget Best-of-16, reducing token usage by up to 33.57% while improving final-answer accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BetaPRM, a distributional process reward model that outputs both a step-level success probability and a reliability measure for each reasoning step. It models the reliability via a Beta posterior learned from Monte Carlo continuation successes under a Beta-Binomial likelihood, rather than regressing to the empirical success ratio. This reliability signal is then used in Adaptive Computation Allocation (ACA) to dynamically stop or continue computation in PRM-guided Best-of-N search. Experiments across four backbones and four reasoning benchmarks claim that BetaPRM improves standard PRM-guided selection while ACA achieves up to 33.57% token reduction with accuracy gains over fixed-budget Best-of-16.
Significance. If the reliability signal is shown to be calibrated beyond sampling artifacts, the work offers a principled way to make step-level rewards actionable for adaptive reasoning, potentially improving the accuracy-token tradeoff in large-scale inference. The Beta-Binomial separation of mean and variance is a clear technical strength over point-estimate PRMs, and the multi-backbone empirical results provide a solid starting point for practical adoption in reasoning pipelines.
major comments (2)
- [Method, Beta-Binomial formulation] Beta-Binomial likelihood description: the model treats the N Monte Carlo continuations as i.i.d. Bernoulli trials with fixed p, yet all continuations share the identical prefix and are sampled from the same base model, inducing positive dependence through common reasoning paths. This dependence can inflate the concentration parameters and make the learned reliability reflect sampling noise rather than true step uncertainty, which is load-bearing for the central claim that the signal enables reliable ACA stopping and Best-of-N gains.
- [Experiments] Experiments section, ACA results: the reported 33.57% token reduction and accuracy lift are presented without statistical significance tests, variance across runs, or details on hyperparameter search and exclusion criteria. This makes it hard to confirm that gains arise from the reliability signal rather than tuning, directly affecting the strength of the accuracy-token tradeoff claim.
minor comments (2)
- [Method] Clarify how the Beta prior hyperparameters are set or learned, and whether they remain fixed across benchmarks.
- [ACA description] Add a short discussion of how the reliability threshold for ACA stopping is chosen and whether it is tuned per backbone.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify key aspects of our Beta-Binomial modeling and experimental reporting. We respond to each major comment below and outline the revisions we will make to address the concerns raised.
read point-by-point responses
-
Referee: [Method, Beta-Binomial formulation] Beta-Binomial likelihood description: the model treats the N Monte Carlo continuations as i.i.d. Bernoulli trials with fixed p, yet all continuations share the identical prefix and are sampled from the same base model, inducing positive dependence through common reasoning paths. This dependence can inflate the concentration parameters and make the learned reliability reflect sampling noise rather than true step uncertainty, which is load-bearing for the central claim that the signal enables reliable ACA stopping and Best-of-N gains.
Authors: We acknowledge that the Monte Carlo continuations exhibit positive dependence due to the shared prefix and common sampling process from the base model. The Beta-Binomial is nevertheless used to model the observed success counts directly, yielding a posterior that reflects empirical variability in outcomes for that step. This still provides a separation between the estimated success probability and its associated uncertainty, which is the core technical contribution relative to point-estimate PRMs. We will add an explicit discussion of this modeling assumption, its limitations, and the empirical validation through downstream ACA and Best-of-N results in the revised method section. revision: partial
-
Referee: [Experiments] Experiments section, ACA results: the reported 33.57% token reduction and accuracy lift are presented without statistical significance tests, variance across runs, or details on hyperparameter search and exclusion criteria. This makes it hard to confirm that gains arise from the reliability signal rather than tuning, directly affecting the strength of the accuracy-token tradeoff claim.
Authors: We agree that stronger statistical reporting is needed to substantiate the accuracy-token tradeoff claims. In the revised manuscript we will report mean and standard deviation across multiple independent runs, include statistical significance tests comparing ACA against fixed-budget baselines, and add details on the hyperparameter search procedure together with any exclusion criteria applied to runs or configurations. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core derivation trains BetaPRM by maximizing a Beta-Binomial likelihood on the observed count of successful Monte Carlo continuations per step. The success probability is recovered as the mean of the fitted Beta posterior while reliability is recovered from its concentration parameters; these two quantities are mathematically separable under the Beta-Binomial model and are not forced to be identical or direct functions of each other by construction. No self-citation chains, imported uniqueness theorems, or ansatzes are invoked to justify the modeling choice. The downstream ACA procedure and empirical gains on Best-of-N selection are presented as applications of the learned signal rather than tautological restatements of the training targets. The derivation therefore remains self-contained against the external Monte Carlo supervision and does not reduce any claimed prediction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Beta prior hyperparameters
axioms (1)
- domain assumption Monte Carlo continuations provide unbiased samples of step success
invented entities (1)
-
Learned reliability signal
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We model it with a Beta belief, q_t ∼ Beta(α_t, β_t)... Marginalizing out the latent q_t yields a Beta-Binomial distribution over K_t
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
κ_t = softplus(g_ϕ(h_t)) + κ_min ... α_t = μ_t κ_t and β_t = (1−μ_t)κ_t
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv e-prints, pages arXiv–2502, 2025
work page 2025
-
[2]
What If We Allocate Test-Time Compute Adaptively?
Ahsan Bilal, Ahmed Mohsin, Muhammad Umer, Ali Subhan, Hassan Rizwan, Ayesha Mohsin, and Dean Hougen. What if we allocate test-time compute adaptively?arXiv preprint arXiv:2602.01070, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
An augmented benchmark dataset for geometric question answering through dual parallel text encoding
Jie Cao and Jing Xiao. An augmented benchmark dataset for geometric question answering through dual parallel text encoding. InProceedings of the 29th international conference on computational linguistics, pages 1511–1520, 2022
work page 2022
-
[5]
Web-shepherd: Advancing PRMs for reinforcing web agents
Hyungjoo Chae, Sunghwan Kim, Junhee Cho, Seungone Kim, Seungjun Moon, Gyeom Hwangbo, Dongha Lim, Minjin Kim, Yeonjun Hwang, Minju Gwak, Dongwook Choi, Minseok Kang, Gwanhoon Im, ByeongUng Cho, Hyojun Kim, Jun Hee Han, Taeyoon Kwon, Minju Kim, Beong woo Kwak, Dongjin Kang, and Jinyoung Yeo. Web-shepherd: Advancing PRMs for reinforcing web agents. InThe Thi...
work page 2026
-
[6]
MapQA: A dataset for question answering on choropleth maps
Shuaichen Chang, David Palzer, Jialin Li, Eric Fosler-Lussier, and Ningchuan Xiao. MapQA: A dataset for question answering on choropleth maps. InNeurIPS 2022 First Table Representation Workshop, 2022. URLhttps://openreview.net/forum?id=znKbVjeR0yI
work page 2022
-
[7]
Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression
Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3313–3323, 2022
work page 2022
-
[8]
M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought
Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8199–8221, 2024
work page 2024
-
[9]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
From mathematical reasoning to code: Generalization of process reward models in test-time scaling
Zhengyu Chen, Yudong Wang, Teng Xiao, Ruochen Zhou, Xusheng Yang, Wei Wang, Zhifang Sui, and Jingang Wang. From mathematical reasoning to code: Generalization of process reward models in test-time scaling. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30368–30376, 2026
work page 2026
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Process supervision-guided policy optimization for code generation
Ning Dai, Zheng Wu, Renjie Zheng, Ziyun Wei, Wenlei Shi, Xing Jin, Guanlin Liu, Chen Dun, Liang Huang, and Lin Yan. Process supervision-guided policy optimization for code generation. arXiv preprint arXiv:2410.17621, 2024. 10
-
[13]
Lingxiao Du, Fanqing Meng, Zongkai Liu, Zhixiang Zhou, Ping Luo, Qiaosheng Zhang, and Wenqi Shao. Mm-prm: Enhancing multimodal mathematical reasoning with scalable step-level supervision.arXiv preprint arXiv:2505.13427, 2025
-
[14]
Efficient process reward model training via active learning
Keyu Duan, Zichen Liu, Xin Mao, Tianyu Pang, Changyu Chen, Qiguang Chen, Michael Qizhe Shieh, and Longxu Dou. Efficient process reward model training via active learning. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= CJ2FmPmoDE
work page 2025
-
[15]
G-LLaV A: Solving geometric problem with multi-modal large language model
Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing HONG, Jianhua Han, Hang Xu, Zhenguo Li, and Lingpeng Kong. G-LLaV A: Solving geometric problem with multi-modal large language model. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=px1674Wp3C
work page 2025
-
[16]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
work page 2017
-
[17]
rstar-math: Small LLMs can master math reasoning with self-evolved deep thinking
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small LLMs can master math reasoning with self-evolved deep thinking. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=5zwF1GizFa
work page 2025
-
[18]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
work page 2024
-
[19]
Advancing process verification for large language models via tree-based preference learning
Mingqian He, Yongliang Shen, Wenqi Zhang, Zeqi Tan, and Weiming Lu. Advancing process verification for large language models via tree-based preference learning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2086–2099, 2024
work page 2024
-
[20]
Vlad Hosu, Hanhe Lin, Tamas Sziranyi, and Dietmar Saupe. Koniq-10k: An ecologically valid database for deep learning of blind image quality assessment.IEEE Transactions on Image Processing, 29:4041–4056, 2020
work page 2020
-
[21]
Pengfei Hu, Zhenrong Zhang, Qikai Chang, Shuhang Liu, Jiefeng Ma, Jun Du, Jianshu Zhang, Quan Liu, Jianqing Gao, Feng Ma, et al. Prm-bas: Enhancing multimodal reasoning through prm-guided beam annealing search.arXiv preprint arXiv:2504.10222, 2025
-
[22]
Efficient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031, 2025
Chengsong Huang, Langlin Huang, Jixuan Leng, Jiacheng Liu, and Jiaxin Huang. Efficient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031, 2025
-
[23]
Icdar2019 competition on scanned receipt ocr and information extraction
Zheng Huang, Kai Chen, Jianhua He, Xiang Bai, Dimosthenis Karatzas, Shijian Lu, and CV Jawahar. Icdar2019 competition on scanned receipt ocr and information extraction. In2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1516–1520. IEEE, 2019
work page 2019
-
[24]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017
work page 2017
-
[25]
Dvqa: Understanding data visualizations via question answering
Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. Dvqa: Understanding data visualizations via question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5648–5656, 2018
work page 2018
-
[26]
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, Ákos Kádár, Adam Trischler, and Yoshua Bengio. Figureqa: An annotated figure dataset for visual reasoning.arXiv preprint arXiv:1710.07300, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Geomverse: A systematic evaluation of large models for geometric reasoning
Mehran Kazemi, Hamidreza Alvari, Ankit Anand, Jialin Wu, Xi Chen, and Radu Soricut. Geomverse: A systematic evaluation of large models for geometric reasoning. InAI for Math Workshop@ ICML 2024, 2024
work page 2024
-
[28]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InEuropean conference on computer vision, pages 235–251. Springer, 2016
work page 2016
-
[29]
Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
Muhammad Khalifa, Rishabh Agarwal, Lajanugen Logeswaran, Jaekyeom Kim, Hao Peng, Moontae Lee, Honglak Lee, and Lu Wang. Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
-
[30]
Seungone Kim, Ian Wu, Jinu Lee, Xiang Yue, Seongyun Lee, Mingyeong Moon, Kiril Gash- teovski, Carolin Lawrence, Julia Hockenmaier, Graham Neubig, et al. Scaling evaluation-time compute with reasoning models as process evaluators.arXiv preprint arXiv:2503.19877, 2025
work page internal anchor Pith review arXiv 2025
-
[31]
Training data efficiency in multimodal process reward models.arXiv preprint arXiv:2602.04145, 2026
Jinyuan Li, Chengsong Huang, Langlin Huang, Shaoyang Xu, Haolin Liu, Wenxuan Zhang, and Jiaxin Huang. Training data efficiency in multimodal process reward models.arXiv preprint arXiv:2602.04145, 2026
-
[32]
Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning
Zhuowan Li, Xingrui Wang, Elias Stengel-Eskin, Adam Kortylewski, Wufei Ma, Benjamin Van Durme, and Alan L Yuille. Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14963–14973, 2023
work page 2023
-
[33]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
work page 2024
-
[34]
Haolin Liu, Dian Yu, Sidi Lu, Yujun Zhou, Rui Liu, Zhenwen Liang, Haitao Mi, Chen-Yu Wei, and Dong Yu. Save the good prefix: Precise error penalization via process-supervised rl to enhance llm reasoning.arXiv preprint arXiv:2601.18984, 2026
-
[35]
Can 1b LLM surpass 405b LLM? rethinking compute-optimal test-time scaling
Runze Liu, Junqi Gao, Jian Zhao, Kaiyan Zhang, Xiu Li, Biqing Qi, Wanli Ouyang, and Bowen Zhou. Can 1b LLM surpass 405b LLM? rethinking compute-optimal test-time scaling. InWorkshop on Reasoning and Planning for Large Language Models, 2025. URL https: //openreview.net/forum?id=CvjX9Lhpze
work page 2025
-
[36]
Diving into self- evolving training for multimodal reasoning
Wei Liu, Junlong Li, Xiwen Zhang, Fan Zhou, Yu Cheng, and Junxian He. Diving into self- evolving training for multimodal reasoning. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=X3ikghfWwD
work page 2025
-
[37]
Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th I...
work page 2021
-
[38]
IconQA: A new benchmark for abstract diagram understanding and visual language reasoning
Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. IconQA: A new benchmark for abstract diagram understanding and visual language reasoning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/forum? id=uXa9oBDZ9V1
work page 2021
-
[39]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35: 2507–2521, 2022. 12
work page 2022
-
[40]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=KUNzEQMWU7
work page 2024
-
[41]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Ruilin Luo, Zhuofan Zheng, Yifan Wang, Xinzhe Ni, Zicheng Lin, Songtao Jiang, Yiyao Yu, Chufan Shi, Lei Wang, Ruihang Chu, et al. Unlocking multimodal mathematical reasoning via process reward model.arXiv preprint arXiv:2501.04686, 2025
-
[43]
Qianli Ma, Haotian Zhou, Tingkai Liu, Jianbo Yuan, Pengfei Liu, Yang You, and Hongxia Yang. Let’s reward step by step: Step-level reward model as the navigators for reasoning.arXiv preprint arXiv:2310.10080, 2023
-
[44]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
work page 2022
-
[45]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021
work page 2021
-
[46]
Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and C.V . Jawahar. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1697–1706, January 2022
work page 2022
-
[47]
Tej Deep Pala, Panshul Sharma, Amir Zadeh, Chuan Li, and Soujanya Poria. Error typing for smarter rewards: Improving process reward models with error-aware hierarchical supervision. arXiv preprint arXiv:2505.19706, 2025
-
[48]
MPBench: A comprehensive multimodal reasoning benchmark for process errors identification
xu Zhao Pan, Pengfei Zhou, Jiaxin Ai, Wangbo Zhao, Kai Wang, Xiaojiang Peng, Wenqi Shao, Hongxun Yao, and Kaipeng Zhang. MPBench: A comprehensive multimodal reasoning benchmark for process errors identification. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics...
-
[49]
Know what you don’t know: Uncertainty calibration of process reward models
Young-Jin Park, Kristjan Greenewald, Kaveh Alim, Hao Wang, and Navid Azizan. Know what you don’t know: Uncertainty calibration of process reward models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview.net/forum?id=hzMkfIrdDT
work page 2026
-
[50]
Solving geometry problems: Combining text and diagram interpretation
Minjoon Seo, Hannaneh Hajishirzi, Ali Farhadi, Oren Etzioni, and Clint Malcolm. Solving geometry problems: Combining text and diagram interpretation. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 1466–1476, 2015
work page 2015
-
[51]
Math-llava: Bootstrapping mathematical reasoning for multimodal large language models
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See Kiong Ng, Lidong Bing, and Roy Ka-Wei Lee. Math-llava: Bootstrapping mathematical reasoning for multimodal large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4663–4680, 2024
work page 2024
-
[52]
Benchmarking object detectors with coco: A new path forward
Shweta Singh, Aayan Yadav, Jitesh Jain, Humphrey Shi, Justin Johnson, and Karan Desai. Benchmarking object detectors with coco: A new path forward. InEuropean Conference on Computer Vision, pages 279–295. Springer, 2024
work page 2024
-
[53]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Prmbench: A fine- grained and challenging benchmark for process-level reward models
Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. Prmbench: A fine- grained and challenging benchmark for process-level reward models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25299–25346, 2025
work page 2025
-
[55]
A corpus for reasoning about natural language grounded in photographs
Alane Suhr, Stephanie Zhou, Ally Zhang, Iris Zhang, Huajun Bai, and Yoav Artzi. A corpus for reasoning about natural language grounded in photographs. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 6418–6428, 2019
work page 2019
-
[56]
Lin Sun, Chuang Liu, Xiaofeng Ma, Tao Yang, Weijia Lu, and Ning Wu. Freeprm: Training process reward models without ground truth process labels.arXiv preprint arXiv:2506.03570, 2025
-
[57]
Vilbench: A suite for vision-language process reward modeling
Haoqin Tu, Weitao Feng, Hardy Chen, Hui Liu, Xianfeng Tang, and Cihang Xie. Vilbench: A suite for vision-language process reward modeling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6775–6790, 2025
work page 2025
-
[58]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[59]
Jun Wang, Meng Fang, Ziyu Wan, Muning Wen, Jiachen Zhu, Anjie Liu, Ziqin Gong, Yan Song, Lei Chen, Lionel M Ni, et al. Openr: An open source framework for advanced reasoning with large language models.arXiv preprint arXiv:2410.09671, 2024
-
[60]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37:95095–95169, 2024
work page 2024
-
[61]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
work page 2024
-
[62]
Shuai Wang, Zhenhua Liu, Jiaheng Wei, Xuanwu Yin, Dong Li, and Emad Barsoum. Athena: Enhancing multimodal reasoning with data-efficient process reward models.arXiv preprint arXiv:2506.09532, 2025
-
[63]
VisualPRM400k: An effective dataset for training multimodal process reward models
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, Lewei Lu, Haodong Duan, Yu Qiao, Jifeng Dai, and Wenhai Wang. VisualPRM400k: An effective dataset for training multimodal process reward models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https...
work page 2026
-
[64]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=1PL1NIMMrw
work page 2023
-
[65]
Stepwiser: Stepwise generative judges for wiser reasoning.arXiv preprint arXiv:2508.19229, 2025
Wei Xiong, Wenting Zhao, Weizhe Yuan, Olga Golovneva, Tong Zhang, Jason Weston, and Sainbayar Sukhbaatar. Stepwiser: Stepwise generative judges for wiser reasoning.arXiv preprint arXiv:2508.19229, 2025
-
[66]
Parallel Test-Time Scaling for Latent Reasoning Models
Runyang You, Yongqi Li, Meng Liu, Wenjie Wang, Liqiang Nie, and Wenjie Li. Parallel test-time scaling for latent reasoning models.arXiv preprint arXiv:2510.07745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Ovm, outcome-supervised value models for plan- ning in mathematical reasoning
Fei Yu, Anningzhe Gao, and Benyou Wang. Ovm, outcome-supervised value models for plan- ning in mathematical reasoning. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 858–875, 2024
work page 2024
-
[68]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186. Springer, 2024. 14
work page 2024
-
[69]
MA VIS: Mathematical visual instruction tuning with an automatic data engine
Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Ziyu Guo, Yichi Zhang, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Shanghang Zhang, Peng Gao, and Hongsheng Li. MA VIS: Mathematical visual instruction tuning with an automatic data engine. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=MnJzJ2gvuf
work page 2025
-
[70]
Wenlin Zhang, Xiangyang Li, Kuicai Dong, Yichao Wang, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Derong Xu, Zhaocheng Du, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. Process vs. outcome reward: Which is better for agentic RAG reinforcement learning. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview...
work page 2026
-
[71]
Yuxin Zhang, Meihao Fan, Ju Fan, Mingyang Yi, Yuyu Luo, Jian Tan, and Guoliang Li. Reward- sql: Boosting text-to-sql via stepwise reasoning and process-supervised rewards.arXiv preprint arXiv:2505.04671, 2025
-
[72]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025
work page 2025
-
[73]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1009–1024, 2025
work page 2025
-
[74]
Tong Zheng, Chengsong Huang, Runpeng Dai, Yun He, Rui Liu, Xin Ni, Huiwen Bao, Kaishen Wang, Hongtu Zhu, Jiaxin Huang, et al. Parallel-probe: Towards efficient parallel thinking via 2d probing.arXiv preprint arXiv:2602.03845, 2026
-
[75]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 15 Table 6: Source coverage of VisualPRM400K-v1.1 used for PRM training. Group Representative sourc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.