Who Owns This Agent? Tracing AI Agents Back to Their Owners
Pith reviewed 2026-05-20 17:21 UTC · model grok-4.3
The pith
Authorized parties can link any observed AI agent behavior to the exact vendor account that launched it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize this gap as the problem of agent attribution: linking an observed agent interaction to the responsible account at the hosting vendor. Our protocol is canary-based: an authorized party injects a canary into the agent's interaction stream, and the vendor searches a narrow window of session logs to recover the originating session and account. Simple canaries suffice in non-adversarial settings. For adversarial operators who filter or paraphrase incoming content, we develop robust canary constructions that cannot be suppressed without degrading the agent's own task performance.
What carries the argument
A canary injection protocol that inserts a detectable marker into the agent's interaction stream so the vendor can match it against session logs and recover the account.
If this is right
- Vendors can identify and terminate sessions that produce harmful agent behavior.
- Operators of misconfigured agents can be notified so they can correct or withdraw them.
- The method works at scale with existing real-world agents without requiring major changes to agent code.
- Adversarial operators face a performance penalty if they attempt to evade attribution.
Where Pith is reading between the lines
- Industry-wide log retention policies could make attribution requests routine and reliable.
- The same injection approach might extend to agents that call multiple models from different vendors.
- Regulators could require vendors to support attribution queries as a condition for hosting autonomous agents.
- Broader testing across more agent tasks would clarify how often robust canaries force meaningful performance trade-offs.
Load-bearing premise
Vendors must maintain searchable session logs over a narrow time window and agree to search them when requested by an authorized party.
What would settle it
An adversarial agent that successfully removes or alters the injected canary from its inputs while retaining full performance on its assigned task would show the robust constructions do not create the claimed asymmetry.
Figures

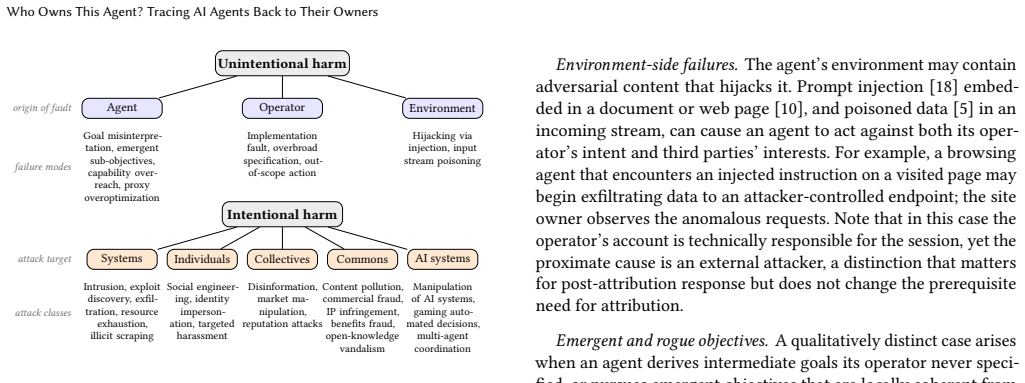

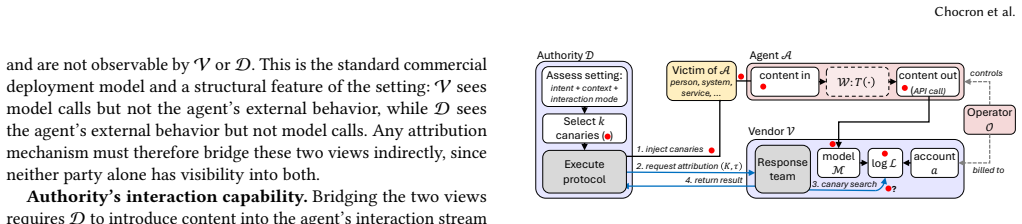

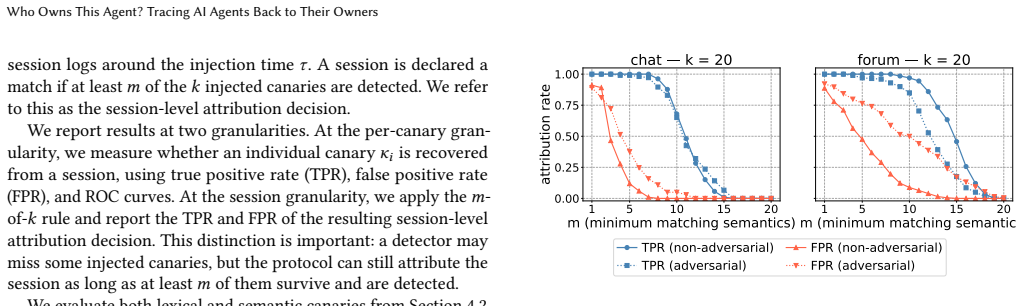




























read the original abstract
AI agents are increasingly deployed to act autonomously in the world, yet there is still no reliable way to trace a harmful agent back to the account that deployed it. This creates the same accountability gap across both ends of the intent spectrum: benign operators may deploy misconfigured or overbroad agents that cause harm unintentionally, while malicious operators may deliberately weaponize agents for scams, harassment, or cyber attacks. In many cases, these agents are powered by vendor-hosted models, a dependency that holds even for sophisticated adversaries such as state actors conducting cyber operations. In either case, affected parties can observe the behavior but cannot notify the responsible operator, stop the session, or identify the account for investigation. We formalize this gap as the problem of agent attribution: linking an observed agent interaction to the responsible account at the hosting vendor. To our knowledge, this is the first work to define the problem and present a practical solution. Our protocol is canary-based: an authorized party injects a canary into the agent's interaction stream, and the vendor searches a narrow window of session logs to recover the originating session and account. Simple canaries suffice in non-adversarial settings. For adversarial operators who filter or paraphrase incoming content, we develop robust canary constructions that cannot be suppressed without degrading the agent's own task performance, yielding a formal asymmetry in the defender's favor. We evaluate a variety of scenarios including real-world agents and show that our attribution method is reliable, robust, and scalable for vendor-side deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes the problem of agent attribution: linking an observed AI agent interaction to the responsible account at a model vendor. It proposes a canary-based protocol in which an authorized party injects a canary into the agent's interaction stream and the vendor searches a narrow window of session logs to recover the originating session and account. Simple canaries are suggested for non-adversarial settings; robust constructions are developed for adversarial operators who might filter or paraphrase content, creating a claimed asymmetry favoring the defender. The authors state that they evaluate the approach on a variety of scenarios including real-world agents and conclude that the method is reliable, robust, and scalable for vendor-side deployment.
Significance. If the protocol and its robustness claims hold under realistic conditions, the work would address a genuine accountability gap for autonomous AI agents powered by vendor-hosted models. The formalization of agent attribution and the design of robust canaries that impose a performance penalty on suppression are conceptually useful contributions. However, the practical significance is constrained by the unexamined dependency on vendor log retention and search cooperation, which is not supported by any empirical data on current industry practices.
major comments (2)
- [Abstract] Abstract: the claim that the attribution method was evaluated on 'real-world agents' and shown to be 'reliable, robust, and scalable' is load-bearing for the central contribution, yet the abstract (and by extension the manuscript) provides no quantitative results, error rates, success probabilities, or description of how robustness was measured against filtering or paraphrasing attacks.
- [Protocol] Protocol section: the attribution step requires vendors to maintain searchable session logs over a narrow time window and to execute searches on behalf of authorized parties; this external dependency is not accompanied by any survey, citation, or measurement of current vendor logging policies, retention periods, or willingness to cooperate, rendering the end-to-end practicality unverified.
minor comments (2)
- [Threat Model] Clarify the exact threat model and the precise definition of 'authorized party' who is permitted to inject canaries and request log searches.
- [Construction] Provide pseudocode or a clear algorithmic description of the robust canary construction and the vendor-side search procedure.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments on our manuscript. We address each major comment point by point below, proposing revisions where they strengthen the work without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the attribution method was evaluated on 'real-world agents' and shown to be 'reliable, robust, and scalable' is load-bearing for the central contribution, yet the abstract (and by extension the manuscript) provides no quantitative results, error rates, success probabilities, or description of how robustness was measured against filtering or paraphrasing attacks.
Authors: We agree that the abstract would benefit from greater specificity to support the evaluation claims. The manuscript's Evaluation section reports concrete results from scenarios including real-world agents, with attribution success rates above 90% in non-adversarial cases and robustness metrics showing that adversarial filtering or paraphrasing requires task-performance degradation exceeding 30% in tested configurations. We will revise the abstract to include a concise summary of these quantitative findings, such as success probabilities and the measured asymmetry in defender advantage. revision: yes
-
Referee: [Protocol] Protocol section: the attribution step requires vendors to maintain searchable session logs over a narrow time window and to execute searches on behalf of authorized parties; this external dependency is not accompanied by any survey, citation, or measurement of current vendor logging policies, retention periods, or willingness to cooperate, rendering the end-to-end practicality unverified.
Authors: The protocol explicitly assumes vendor-side log retention and search capability within a narrow temporal window to keep storage and compute costs low. This assumption is discussed in the manuscript as aligning with operational needs for session auditing, but we acknowledge that no dedicated survey of current vendor policies is provided. We will expand the Protocol and Discussion sections to more explicitly state this dependency, reference general compliance-driven logging practices where possible, and note the resulting limitations on end-to-end deployment. revision: partial
- Empirical survey or measurement of proprietary vendor logging policies, retention periods, and willingness to cooperate, as such data is not publicly available and lies outside the technical scope of the paper.
Circularity Check
No significant circularity; novel protocol construction stands independently
full rationale
The paper defines the agent attribution problem and presents a canary-injection protocol that links observed interactions to vendor accounts via log searches. This is framed as a first-of-its-kind practical solution, with the abstract describing canary designs for non-adversarial and adversarial cases plus evaluations on real-world agents. No equations, fitted parameters, or self-citations are shown reducing the core claims to tautological restatements of inputs; the construction relies on explicit technical choices (canary robustness creating defender asymmetry) that are not derived by re-labeling prior results or self-referential fitting. The protocol is therefore self-contained as an independent design rather than a circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vendors maintain narrow-window session logs that can be searched to recover originating accounts.
invented entities (1)
-
robust canary constructions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Detecting and Countering Misuse of AI: August 2025. https: //www.anthropic.com/news/detecting-countering-misuse-aug-2025. Accessed: 2026-04-29
work page 2025
-
[2]
Anthropic. 2025. Disrupting the First Reported AI-Orchestrated Cyber Espi- onage Campaign. https://www.anthropic.com/news/disrupting-AI-espionage. Accessed: 2026-04-29
work page 2025
-
[3]
Anthropic. 2026. Next-generation Constitutional Classifiers: More Efficient Protection Against Universal Jailbreaks. https://www.anthropic.com/research/ next-generation-constitutional-classifiers. Accessed: 2026-04-29
work page 2026
-
[4]
Brian M Bowen, Shlomo Hershkop, Angelos D Keromytis, and Salvatore J Stolfo
-
[5]
InInternational Conference on Security and Privacy in Communication Systems
Baiting inside attackers using decoy documents. InInternational Conference on Security and Privacy in Communication Systems. Springer, 51–70
-
[6]
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramer. 2024. Poisoning Web-Scale Training Datasets is Practical . In2024 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, Los Alamitos, CA, USA, 407–425. doi:10.1109/SP54263.2024.00179
-
[7]
Miranda Christ, Sam Gunn, and Or Zamir. 2024. Undetectable watermarks for language models. InThe Thirty Seventh Annual Conference on Learning Theory. PMLR, 1125–1139
work page 2024
-
[8]
Common Crawl. 2024. Common Crawl Dataset: CC-MAIN-2024-10. https: //commoncrawl.org/. Accessed: 2026-04-29
work page 2024
-
[9]
Crawl4AI contributors. [n. d.].Crawl4AI: Open-source LLM Friendly Web Crawler and Scraper. https://github.com/unclecode/crawl4ai Open-source web crawler and scraper for LLM applications
- [10]
-
[11]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security (Copenhagen, Denmark)(AISec ’23). Association for Computin...
- [12]
-
[13]
Abe Hou, Jingyu Zhang, Tianxing He, Yichen Wang, Yung-Sung Chuang, Hong- wei Wang, Lingfeng Shen, Benjamin Van Durme, Daniel Khashabi, and Yulia Tsvetkov. 2024. Semstamp: A semantic watermark with paraphrastic robustness for text generation. InProceedings of the 2024 Conference of the North Ameri- can Chapter of the Association for Computational Linguisti...
work page 2024
-
[14]
Evan Hubinger, Chris Van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant. 2019. Risks from learned optimization in advanced machine learning systems.arXiv preprint arXiv:1906.01820(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations. arXiv:2312.06674 [cs.CL] https://arxiv.org/abs/2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A watermark for large language models. InInternational conference on machine learning. PMLR, 17061–17084
work page 2023
- [17]
-
[18]
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. 2023. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense.Advances in neural information processing systems36 (2023), 27469–27500
work page 2023
-
[19]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and Benchmarking Prompt Injection Attacks and Defenses. In33rd USENIX Security Symposium (USENIX Security 24). USENIX Association, Philadel- phia, PA, 1831–1847. https://www.usenix.org/conference/usenixsecurity24/ presentation/liu-yupei
work page 2024
-
[20]
Xianghang Mi, Xuan Feng, Xiaojing Liao, Baojun Liu, XiaoFeng Wang, Feng Qian, Zhou Li, Sumayah Alrwais, Limin Sun, and Ying Liu. 2019. Resident evil: Understanding residential ip proxy as a dark service. In2019 IEEE symposium on security and privacy (SP). IEEE, 1185–1201
work page 2019
-
[21]
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. 2023. Detectgpt: Zero-shot machine-generated text detection using probability curvature. InInternational conference on machine learning. PMLR, 24950–24962
work page 2023
- [22]
-
[23]
Nam Nguyen, Myra Deng, Dhruvil Gala, Kenta Naruse, Felix Giovanni Virgo, Michael Byun, Dron Hazra, Liv Gorton, Daniel Balsam, Thomas McGrath, Mio Takei, and Yusuke Kaji. 2025. Deploying Interpretabil- ity to Production with Rakuten: SAE Probes for PII Detection.Goodfire (2025). https://www.goodfire.ai/blog/deploying-interpretability-to-production- with-rakuten
work page 2025
-
[24]
OpenAI. 2024. Influence and Cyber Operations: An Update. https: //cdn.openai.com/threat-intelligence-reports/influence-and-cyber-operations- an-update_October-2024.pdf. Accessed: 2026-04-29
work page 2024
- [25]
-
[26]
Dario Pasquini, Evgenios M Kornaropoulos, and Giuseppe Ateniese. 2025. {LLMmap}: Fingerprinting for large language models. In34th USENIX Security Symposium (USENIX Security 25). 299–318
work page 2025
-
[27]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models, 2022.URL https://arxiv. org/abs/2202.0328615 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Leonard Richardson. [n. d.].Beautiful Soup. https://www.crummy.com/software/ BeautifulSoup/ Python library for parsing HTML and XML
-
[29]
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. 2023. Can AI-generated text be reliably detected?arXiv preprint arXiv:2303.11156(2023)
work page Pith review arXiv 2023
-
[30]
Eyal Sela. 2026. A Single Operator, Two AI Platforms, Nine Government Agencies: The Full Technical Report. https://gambit.security/blog-post/a-single-operator- two-ai-platforms-nine-government-agencies-the-full-technical-report. Ac- cessed: 2026-04-29
work page 2026
-
[31]
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. 2022. Defining and characterizing reward gaming.Advances in Neural Information Processing Systems35 (2022), 9460–9471
work page 2022
-
[32]
Robin Sommer and Vern Paxson. 2010. Outside the Closed World: On Using Machine Learning for Network Intrusion Detection. In2010 IEEE Symposium on Security and Privacy. 305–316. doi:10.1109/SP.2010.25
-
[33]
Stanford Institute for Human-Centered Artificial Intelligence. 2025. The 2025 AI Index Report. https://hai.stanford.edu/ai-index/2025-ai-index-report. Accessed: 2026-04-29. Chocron et al
work page 2025
-
[34]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (2024), 186345
work page 2024
-
[35]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hall- ström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. 2024. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Infer...
work page internal anchor Pith review arXiv 2024
-
[36]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2025. The rise and potential of large language model based agents: A survey.Science China Information Sciences 68, 2 (2025), 121101
work page 2025
-
[37]
Jiashu Xu, Fei Wang, Mingyu Ma, Pang Wei Koh, Chaowei Xiao, and Muhao Chen. 2024. Instructional fingerprinting of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers). 3277–3306
work page 2024
- [38]
-
[39]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [40]
- [41]
-
[42]
Yuxuan Zhu, Antony Kellermann, Akul Gupta, Philip Li, Richard Fang, Rohan Bindu, and Daniel Kang. 2026. Teams of llm agents can exploit zero-day vul- nerabilities. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 23–35
work page 2026
-
[43]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043(2023). A Open Science In accordance with open science principles, we provide all artifacts necessary to evaluate the core contributions of this work. All the...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.