MHMamba: Multi-Head Mamba for 3D Brain Tumor Segmentation
Pith reviewed 2026-05-20 18:18 UTC · model grok-4.3
The pith
MHMamba splits MRI channels into parallel Mamba heads to raise accuracy and boundary precision in 3D brain tumor segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
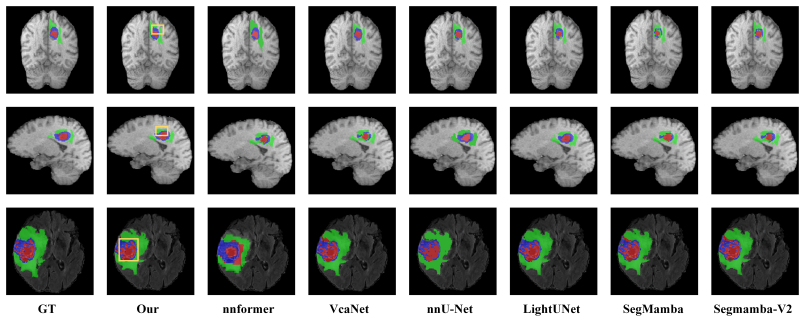
By splitting the channel dimension into parallel state-space model heads, aggregating their outputs with residuals, and adding channel-space calibration plus adaptive skip fusion, MHMamba improves long-range representation and multimodal stability in 3D MRI volumes while retaining linear complexity and delivering measurable gains in accuracy, boundary smoothness, and small-lesion sensitivity on BraTS2021 and BraTS2023.
What carries the argument
Multi-head state-space model that splits the channel dimension into parallel SSM heads, aggregates them with residuals, then applies channel-space calibration and adaptive fusion at skip connections.
If this is right
- Long-range dependencies in full 3D MRI volumes can be modeled without the quadratic memory cost of self-attention.
- Boundary consistency and detection of small enhancing tumor volumes improve through explicit alignment of global and local signals.
- Multimodal training remains stable across heterogeneous contrasts because parallel heads reduce contextual incoherence.
- Linear scaling is preserved, allowing practical processing of high-resolution 3D scans on standard clinical hardware.
Where Pith is reading between the lines
- The same parallel-head pattern could be tested on other 3D medical volumes such as CT organ segmentation where both wide context and fine edges are needed.
- Varying the number of heads may expose an optimal width for different tumor grades or acquisition protocols.
- Pairing MHMamba with self-supervised pretraining on unlabeled MRI could further lift performance in low-data hospital settings.
Load-bearing premise
That splitting channels into parallel SSM heads with residual aggregation plus calibration and adaptive fusion will reliably improve long-range modeling and stability without losing local features or introducing new instabilities in 3D MRI volumes.
What would settle it
An ablation on the same BraTS2021 or BraTS2023 data in which the multi-head splitting is removed and no drop occurs in tumor-core or enhancing-tumor Dice scores or boundary metrics.
Figures


read the original abstract
Brain tumors exhibit high heterogeneity in morphology and multimodal contrast, making manual slice-by-slice de lineation time-consuming and experience-dependent, thus necessitating efficient and stable automated segmentation methods. To address the limitations of CNNs in modeling long-range dependencies, and the heavy computational and memory overhead and inter-block contextual in coherence of Transformers in 3D MRI, this paper proposes Multi-Head Mamba (MHMamba). This method combines a U-shaped architecture with a multi-head state-space model (Mamba), splitting the channel dimension into parallel SSM heads and aggregating them with residuals. This enhances long-range representation and improves the stability of multimodal training while maintaining linear complexity. To further align statistics and enhance lesion response, we designed a channel-space calibration module for multi-head outputs and introduced an adaptive fusion mechanism at skip connections to dynamically connect global semantics with local details, thereby improving boundary consistency and the detection of small-volume lesions. We conducted experiments and ablations on BraTS2021 and BraTS2023. The results showed that MHMamba achieved stable and significant improvements in overall accuracy, boundary smoothness, and sensitivity to tumor core and small-volume enhancement areas, while preserving the linear-complexity advantage of Mamba-based modeling, thus verifying the effectiveness and versatility of the method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MHMamba, a U-shaped architecture for 3D brain tumor segmentation that integrates multi-head state-space models (Mamba). It splits the channel dimension into parallel SSM heads, aggregates outputs with residuals, adds a channel-space calibration module, and introduces adaptive fusion at skip connections to improve long-range multimodal modeling while preserving linear complexity. Experiments and ablations on BraTS2021 and BraTS2023 are claimed to show stable improvements in overall accuracy, boundary smoothness, and sensitivity to tumor core and small-volume enhancing regions.
Significance. If the empirical claims hold with proper validation, the work could demonstrate a practical way to extend Mamba's efficiency advantages to heterogeneous 3D medical volumes, offering a lower-complexity alternative to Transformers for tasks requiring both global context and fine local contrast in multimodal MRI.
major comments (2)
- The central design choice of splitting the channel dimension into parallel SSM heads (described in the method) risks reducing per-head representational capacity for spatially localized high-frequency features in 3D BraTS volumes; the manuscript should supply a concrete analysis or ablation demonstrating that residual aggregation, channel-space calibration, and adaptive skip fusion compensate without loss of detail relative to single-head Mamba or standard CNN baselines.
- The abstract and results description assert 'stable and significant improvements' on BraTS2021 and BraTS2023 but supply no quantitative metrics, error bars, ablation tables, baseline comparisons, or statistical tests, so the data-to-claim link cannot be evaluated.
minor comments (2)
- Abstract: 'de lineation' appears to be a typo and should read 'delineation'.
- The phrase 'inter-block contextual incoherence' for Transformers would benefit from a brief clarification or citation to make the motivation more precise.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications on the design rationale and committing to revisions that strengthen the empirical presentation without altering the core contributions.
read point-by-point responses
-
Referee: The central design choice of splitting the channel dimension into parallel SSM heads (described in the method) risks reducing per-head representational capacity for spatially localized high-frequency features in 3D BraTS volumes; the manuscript should supply a concrete analysis or ablation demonstrating that residual aggregation, channel-space calibration, and adaptive skip fusion compensate without loss of detail relative to single-head Mamba or standard CNN baselines.
Authors: We thank the referee for highlighting this potential concern. The multi-head splitting is motivated by enabling parallel specialization across channel subspaces for heterogeneous multimodal MRI features, while residual aggregation explicitly preserves the full input representation to each head. The channel-space calibration module then recalibrates statistics to enhance lesion-specific responses, and adaptive skip fusion dynamically balances global context with local high-frequency details. Our existing ablation studies (Section 4) compare multi-head configurations against single-head Mamba variants and show maintained or improved boundary and small-lesion metrics. To more directly address the request for concrete analysis on high-frequency feature preservation, we have added targeted visualizations of feature maps and an expanded ablation table in the revised manuscript demonstrating no loss of detail relative to baselines. revision: yes
-
Referee: The abstract and results description assert 'stable and significant improvements' on BraTS2021 and BraTS2023 but supply no quantitative metrics, error bars, ablation tables, baseline comparisons, or statistical tests, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract and narrative summaries would benefit from more explicit quantitative support to strengthen the data-to-claim connection. While the experimental section and tables already present Dice, HD95, sensitivity metrics, ablation results, and baseline comparisons on BraTS2021 and BraTS2023, we acknowledge the high-level claims in the abstract and results overview lack specific numbers and statistical backing. In the revised manuscript we have updated the abstract with key quantitative metrics and improvement deltas, added error bars to performance figures, expanded the ablation tables with direct single-head and CNN comparisons, and included results from statistical significance tests to substantiate the reported improvements. revision: yes
Circularity Check
No circularity; claims rest on empirical results from external BraTS benchmarks
full rationale
The paper proposes an architectural extension (multi-head SSM splitting, residual aggregation, channel calibration, adaptive skip fusion) inside a U-Net and validates it via experiments and ablations on the independent BraTS2021/BraTS2023 datasets. No equations, uniqueness theorems, or self-citations are invoked to derive the performance gains; the improvements are presented as observed outcomes rather than forced by construction or prior self-referential results. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean, IndisputableMonolith/Foundation/AlexanderDuality.leanreality_from_one_distinction, alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
splitting the channel dimension into parallel SSM heads and aggregating them with residuals... Channel-Spatial Calibration (CSCA) module... Adaptive Gated Fusion (AGF) module
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Danish Ali, Ajmal Mian, Naveed Akhtar, and Ghu- lam Mubashar Hassan. Drbd-mamba for robust and efficient brain tumor segmentation with analytical insights.arXiv preprint arXiv:2510.14383, 2025. 4
-
[2]
Ujjwal Baid, Satyam Ghodasara, Suyash Mohan, Michel Bilello, Evan Calabrese, Errol Colak, Keyvan Farahani, Jayashree Kalpathy-Cramer, Felipe C Kitamura, Sarthak Pati, et al. The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv preprint arXiv:2107.02314, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Bingzhi Chen, Yishu Liu, Zheng Zhang, Guangming Lu, and Adams Wai Kin Kong. Transattunet: Multi-level attention- guided u-net with transformer for medical image segmenta- tion.IEEE Transactions on Emerging Topics in Computa- tional Intelligence, 8(1):55–68, 2023. 2
work page 2023
-
[4]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L Yuille, and Yuyin Zhou. Transunet: Transformers make strong encoders for medi- cal image segmentation.arXiv preprint arXiv:2102.04306,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Offset: Segmentation-based focus shift revision for composed image retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Xuemeng Song, and Liqiang Nie. Offset: Segmentation-based focus shift revision for composed image retrieval. InProceedings of the ACM International Conference on Multimedia, page 6113–6122, 2025. 6
work page 2025
-
[6]
Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Haokun Wen, and Weili Guan. Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval. In Proceedings of the ACM International Conference on Mul- timedia, page 6143–6152, 2025. 6
work page 2025
-
[7]
Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, pages 20463–20471, 2026. 6
work page 2026
-
[8]
Xiang Cheng and Hong Lei. Semantic segmentation of re- mote sensing imagery based on multiscale deformable cnn and densecrf.Remote Sensing, 15(5):1229, 2023. 2
work page 2023
-
[9]
Mamba: Linear-time sequence mod- eling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence mod- eling with selective state spaces. InFirst conference on lan- guage modeling, 2024. 1
work page 2024
-
[10]
Squeeze-and-excitation net- works
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net- works. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018. 2
work page 2018
-
[11]
Refine: Composed video retrieval via shared and differential semantics enhancement
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. Refine: Composed video retrieval via shared and differential semantics enhancement. ACM Transactions on Multimedia Computing, Communica- tions and Applications, 2026. 5
work page 2026
-
[12]
Yonghao Huang, Leiting Chen, and Chuan Zhou. Multi-modal brain tumor segmentation via 3d multi- scale self-attention and cross-attention.arXiv preprint arXiv:2504.09088, 2025. 2
-
[13]
Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Pe- tersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmen- tation.Nature methods, 18(2):203–211, 2021. 3, 7
work page 2021
-
[14]
Hongwei Bran Li, Gian Marco Conte, Qingqiao Hu, Syed Muhammad Anwar, Florian Kofler, Ivan Ezhov, Koen van Leemput, Marie Piraud, Maria Diaz, Byrone Cole, et al. The brain tumor segmentation (brats) challenge 2023: Brain mr image synthesis for tumor segmentation (brasyn).ArXiv, pages arXiv–2305, 2024. 2
work page 2023
-
[15]
Encoder: Entity mining and modifica- tion relation binding for composed image retrieval
Zixu Li, Zhiwei Chen, Haokun Wen, Zhiheng Fu, Yupeng Hu, and Weili Guan. Encoder: Entity mining and modifica- tion relation binding for composed image retrieval. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 5101–5109, 2025. 5
work page 2025
-
[16]
Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, and Liqiang Nie. Finecir: Explicit parsing of fine- grained modification semantics for composed image re- trieval.https://arxiv.org/abs/2503.21309, 2025. 5
-
[17]
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. Retrack: Evidence-driven dual-stream directional anchor calibration network for com- posed video retrieval. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 23373–23381, 2026. 6
work page 2026
-
[18]
Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 6762–6770, 2026. 7
work page 2026
-
[19]
Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen A.W.M
Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Ar- naud A.A. Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen A.W.M. van der Laak, Bram van Ginneken, and Clara I. S´anchez. A survey on deep learning in medical im- age analysis.Medical Image Analysis, 42:60–88, 2017. 1
work page 2017
-
[20]
Debao Liu, Xiaozhi Zhang, Hong Zhou, and Kok Lay Teo. Consistency-driven state-space model for incomplete multi- modal mri brain tumor segmentation.Meta-Radiology, page 100185, 2025. 4
work page 2025
-
[21]
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024. 3
work page 2024
-
[22]
U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
Jun Ma, Feifei Li, and Bo Wang. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Bjoern H Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy-Cramer, Keyvan Farahani, Justin Kirby, Yuliya Burren, Nicole Porz, Johannes Slotboom, Roland Wiest, et al. The multimodal brain tumor image segmentation benchmark (brats).IEEE transactions on medical imaging, 34(10):1993–2024, 2014. 1
work page 1993
-
[24]
V-net: Fully convolutional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In2016 fourth international conference on 3D vision (3DV), pages 565–571. Ieee, 2016. 2
work page 2016
-
[25]
Attention U-Net: Learning Where to Look for the Pancreas
Ozan Oktay, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, Bernhard Kainz, et al. Atten- tion u-net: Learning where to look for the pancreas.arXiv preprint arXiv:1804.03999, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Quinn T Ostrom, Mackenzie Price, Corey Neff, Gino Cioffi, Kristin A Waite, Carol Kruchko, and Jill S Barnholtz-Sloan. Cbtrus statistical report: primary brain and other central ner- vous system tumors diagnosed in the united states in 2015– 2019.Neuro-oncology, 24(Supplement 5):v1–v95, 2022. 1
work page 2015
-
[27]
Dichao Pan, Jianguo Shen, Zaid Al-Huda, and Mo- hammed AA Al-Qaness. Vcanet: Vision transformer with fusion channel and spatial attention module for 3d brain tu- mor segmentation.Computers in Biology and Medicine, 186: 109662, 2025. 3, 7
work page 2025
-
[28]
Saqib Qamar, Hai Jin, Ran Zheng, Parvez Ahmad, and Mohd Usama. A variant form of 3d-unet for infant brain segmen- tation.Future Generation Computer Systems, 108:613–623,
-
[29]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 1, 2
work page 2015
-
[30]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 1
work page 2017
-
[31]
Computing nodes for plane data points by constructing cubic polynomial with constraints
Hua Wang and Fan Zhang. Computing nodes for plane data points by constructing cubic polynomial with constraints. Computer Aided Geometric Design, 111:102308, 2024. 3
work page 2024
-
[32]
Hua Wang, Jinghao Lu, and Fan Zhang. Eeo-tfv: Escape- explore optimizer for web-scale time-series forecasting and vision analysis.arXiv preprint arXiv:2602.02551, 2026. 2
-
[33]
Transbts: Multimodal brain tumor seg- mentation using transformer
Wenxuan Wang, Chen Chen, Meng Ding, Hong Yu, Sen Zha, and Jiangyun Li. Transbts: Multimodal brain tumor seg- mentation using transformer. InInternational conference on medical image computing and computer-assisted interven- tion, pages 109–119. Springer, 2021. 2
work page 2021
-
[34]
Cbam: Convolutional block attention module
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), pages 3–19, 2018. 2
work page 2018
-
[35]
From points to coalitions: Hierarchical contrastive shapley values for prioritizing data samples
Canran Xiao, Jiabao Dou, Zhiming Lin, Zong Ke, and Li- wei Hou. From points to coalitions: Hierarchical contrastive shapley values for prioritizing data samples. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 15995–16003, 2026. 7
work page 2026
-
[36]
Reversible primitive–composition align- ment for continual vision–language learning
Canran Xiao, Tianxiang Xu, Yiyang Jiang, Haoyu Gao, Yuhan Wu, et al. Reversible primitive–composition align- ment for continual vision–language learning. InThe Four- teenth International Conference on Learning Representa- tions, 2026. 5
work page 2026
-
[37]
Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation
Zhaohu Xing, Tian Ye, Yijun Yang, Guang Liu, and Lei Zhu. Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. InInternational conference on medical image computing and computer-assisted interven- tion, pages 578–588. Springer, 2024. 4, 7
work page 2024
-
[38]
Zhaohu Xing, Tian Ye, Yijun Yang, Du Cai, Baowen Gai, Xiao-Jian Wu, Feng Gao, and Lei Zhu. Segmamba-v2: Long-range sequential modeling mamba for general 3d med- ical image segmentation.IEEE Transactions on Medical Imaging, 2025. 7
work page 2025
-
[39]
Fan Zhang, Gongguan Chen, Hua Wang, Jinjiang Li, and Caiming Zhang. Multi-scale video super-resolution trans- former with polynomial approximation.IEEE Transactions on Circuits and Systems for Video Technology, 33(9):4496– 4506, 2023. 3
work page 2023
-
[40]
Fan Zhang, Gongguan Chen, Hua Wang, and Caiming Zhang. Cf-dan: Facial-expression recognition based on cross-fusion dual-attention network.Computational Visual Media, 10(3):593–608, 2024. 3
work page 2024
-
[41]
Fan Zhang, Zhiwei Gu, and Hua Wang. Decoding with struc- tured awareness: integrating directional, frequency-spatial, and structural attention for medical image segmentation. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 12421–12429, 2026. 6
work page 2026
-
[42]
Light-unet: An efficient segmentation network for medical image
Yue Zhang, Chao Xu, Zhifan Zhang, and Jianjun Wang. Light-unet: An efficient segmentation network for medical image. InInternational Conference on Intelligent Comput- ing, pages 302–313. Springer, 2024. 7
work page 2024
-
[43]
Incomplete multi-modal brain tumor segmentation via learnable sorting state space model
Zheyu Zhang, Yayuan Lu, Feipeng Ma, Yueyi Zhang, Huan- jing Yue, and Xiaoyan Sun. Incomplete multi-modal brain tumor segmentation via learnable sorting state space model. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 25982–25992, 2025. 4
work page 2025
-
[44]
nnformer: Interleaved transformer for volumetric segmentation.arXiv preprint arXiv:2109.03201, 2021
Hong-Yu Zhou, Jiansen Guo, Yinghao Zhang, Lequan Yu, Liansheng Wang, and Yizhou Yu. nnformer: Interleaved transformer for volumetric segmentation.arXiv preprint arXiv:2109.03201, 2021. 7
-
[45]
Mingzhe Zhou, Jinbao Li, and Yahong Guo. Multi-level channel-spatial attention and light-weight scale-fusion net- work (mcslf-net): multi-level channel-spatial attention and light-weight scale-fusion transformer for 3d brain tumor seg- mentation.Quantitative Imaging in Medicine and Surgery, 15(7):6301–6325, 2025. 3
work page 2025
-
[46]
Xiangrong Zhou, Ryosuke Takayama, Song Wang, Takeshi Hara, and Hiroshi Fujita. Deep learning of the sectional ap- pearances of 3d ct images for anatomical structure segmen- tation based on an fcn voting method.Medical physics, 44 (10):5221–5233, 2017. 2
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.