Reasoning Can Be Restored by Correcting a Few Decision Tokens
Pith reviewed 2026-05-19 20:52 UTC · model grok-4.3
pith:3RES4GZV Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{3RES4GZV}
Prints a linked pith:3RES4GZV badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Base LLMs lose most reasoning ability at a few early planning tokens that can be fixed by brief stronger-model intervention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The reasoning advantage of large reasoning models over base models is sparse and localized to early planning-related decision tokens. On Qwen3-0.6B, only about 8 percent of generated tokens drive the salient distributional disagreement; these tokens appear early, occur 17 times more often in planning decisions than elsewhere, and align with elevated uncertainty in the base model. This pattern indicates that base models mainly derail at initial planning points that steer the rest of the trajectory.
What carries the argument
Disagreement-guided token intervention: a one-token takeover by the reasoning model performed only at positions of high likelihood-based divergence, followed by an immediate switch back to the base model for the remainder of generation.
Load-bearing premise
That the positions of high distributional disagreement are precisely the causal points where early planning errors derail the base model's subsequent reasoning, rather than merely correlated symptoms of some other problem.
What would settle it
A controlled test showing that swapping in the reasoning model's token at the identified high-disagreement positions produces no improvement in final reasoning accuracy would falsify the claim.
Figures

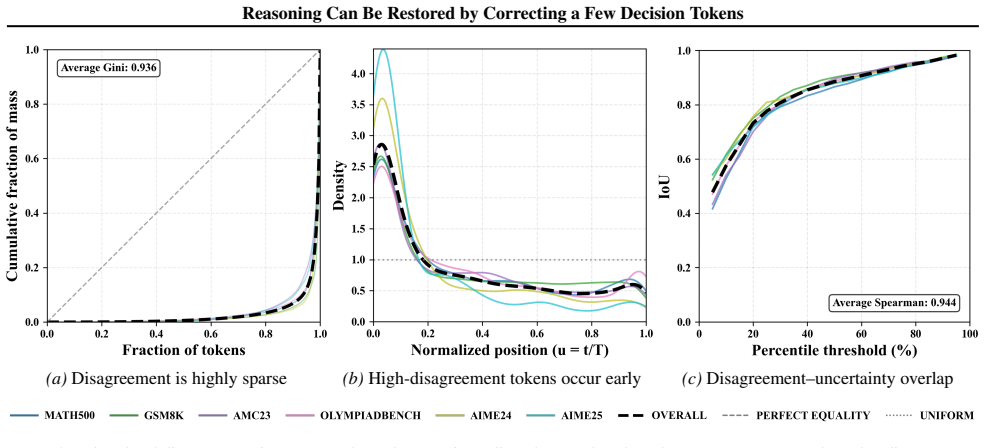
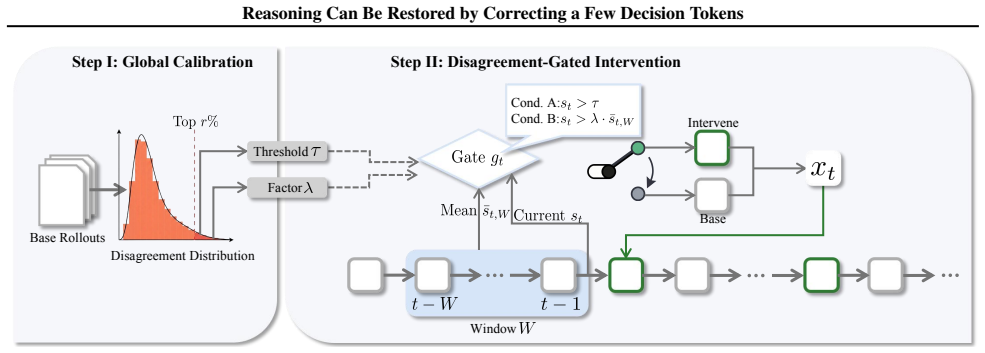
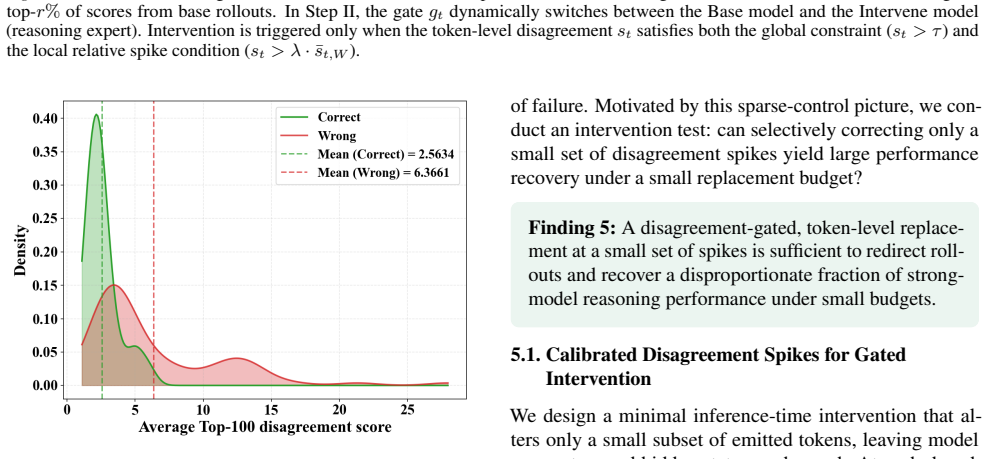




read the original abstract
Large reasoning models (LRMs) substantially outperform their base LLM counterparts on challenging reasoning benchmarks, yet it remains poorly understood where base models go wrong during token-by-token generation and how to narrow this gap efficiently. We study the base-reasoning gap through quantifying token-level distributional disagreement between a base model and a stronger reasoning model using likelihood-based divergences. Across benchmarks, we find that the reasoning advantage is highly sparse and concentrates on a small set of early, planning-related decision tokens. For instance, on Qwen3-0.6B, only ~8% of generated tokens account for the salient disagreement, and these tokens concentrate early in the response, are strongly enriched in planning-related decisions (17x), and coincide with high base-model uncertainty -- suggesting that base models fail mainly at early planning points that steer the subsequent reasoning trajectory. Building on these findings, we propose disagreement-guided token intervention, a simple inference-time delegation scheme that performs a one-token takeover by the reasoning model only at high-disagreement positions and immediately switches back to the base model. With a small intervention budget, this sparse delegation substantially recovers and can even surpass the performance of a same-size reasoning model on challenging reasoning tasks. Code is available at https://github.com/AlphaLab-USTC/RRTokenIntervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper quantifies token-level distributional disagreement (via likelihood divergences) between base LLMs and larger reasoning models across benchmarks. It reports that the reasoning advantage is sparse (~8% of tokens on Qwen3-0.6B), concentrated on early planning-related decision tokens that are enriched 17x for planning decisions and coincide with high base-model uncertainty. Building on this, it introduces a disagreement-guided one-token intervention that delegates only at high-disagreement positions and claims this recovers (or surpasses) same-size reasoning-model performance with small budget.
Significance. If the sparsity and intervention results hold under proper controls, the work would be significant for providing an empirical map of where base models derail on reasoning trajectories and a lightweight inference-time fix. The reproducible code and cross-benchmark consistency are strengths; the approach could inform efficient hybrid decoding strategies.
major comments (2)
- [Intervention Experiment] Intervention section: the performance recovery is shown for the disagreement-guided scheme, but no ablations are reported that compare it to intervening at random early tokens, low-disagreement positions, or uncertainty-matched positions while holding the one-token takeover budget fixed. Without these controls it remains possible that any early delegation to the stronger model produces the gains, weakening the claim that high-disagreement tokens are the specific causal sites.
- [Token Disagreement Analysis] Token analysis (around the Qwen3-0.6B ~8% figure and 17x planning enrichment): the positions of high disagreement are shown to correlate with uncertainty and planning labels, yet the manuscript does not include trajectory-level analysis or counterfactual rollouts demonstrating that errors at these exact tokens propagate to derail later reasoning. This leaves the 'steer the subsequent trajectory' interpretation as an association rather than a demonstrated causal mechanism.
minor comments (2)
- [Methods] Methods: specify whether the planning-related token labeling criteria were pre-registered or chosen after inspecting the data; if post-hoc, discuss potential selection bias.
- [Results] Figures and tables: ensure all reported percentages (e.g., 8%, 17x) are accompanied by exact token counts, benchmark breakdowns, and confidence intervals or standard errors.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of our experimental design and causal interpretations. We address each major comment below and have revised the manuscript accordingly to strengthen the claims.
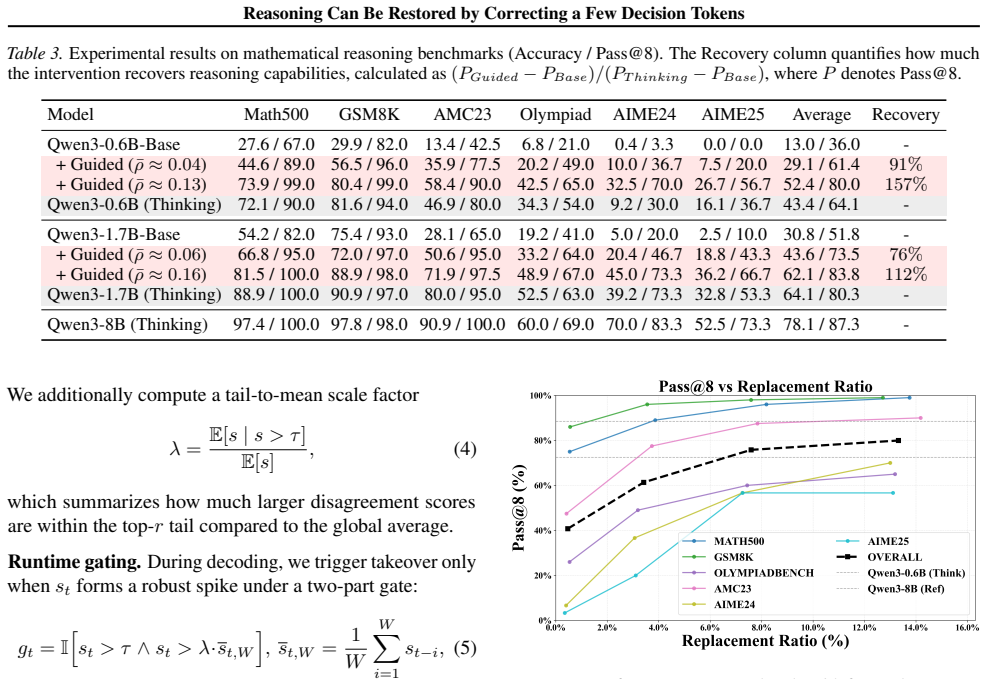
read point-by-point responses
-
Referee: [Intervention Experiment] Intervention section: the performance recovery is shown for the disagreement-guided scheme, but no ablations are reported that compare it to intervening at random early tokens, low-disagreement positions, or uncertainty-matched positions while holding the one-token takeover budget fixed. Without these controls it remains possible that any early delegation to the stronger model produces the gains, weakening the claim that high-disagreement tokens are the specific causal sites.
Authors: We agree that these controls are necessary to isolate the role of high-disagreement positions. In the revised manuscript we have added a new ablation subsection (Section 4.3) that reports exactly these comparisons: intervening at random early tokens, at low-disagreement positions, and at uncertainty-matched positions, all under an identical one-token takeover budget. The results confirm that only the disagreement-guided selection recovers (and in some cases exceeds) the reasoning-model performance; random or uncertainty-matched early interventions yield substantially smaller gains. These new figures and tables are now included. revision: yes
-
Referee: [Token Disagreement Analysis] Token analysis (around the Qwen3-0.6B ~8% figure and 17x planning enrichment): the positions of high disagreement are shown to correlate with uncertainty and planning labels, yet the manuscript does not include trajectory-level analysis or counterfactual rollouts demonstrating that errors at these exact tokens propagate to derail later reasoning. This leaves the 'steer the subsequent trajectory' interpretation as an association rather than a demonstrated causal mechanism.
Authors: We acknowledge that explicit counterfactual rollouts would provide the strongest causal demonstration. Performing full trajectory-level counterfactuals (forcing the base model to adopt the reasoning-model token at each high-disagreement site and then continuing generation) is computationally expensive and was outside the scope of the original submission. However, the one-token intervention results themselves constitute a direct causal test: correcting only those specific tokens and immediately returning control to the base model is sufficient to restore performance. This outcome is difficult to explain unless errors at precisely those positions derail the subsequent trajectory. We have added a dedicated paragraph in Section 5 discussing this interpretation, the correlational nature of the token-level statistics, and the limitation regarding exhaustive counterfactuals. revision: partial
Circularity Check
No significant circularity; empirical token-disagreement measurements and intervention are self-contained
full rationale
The paper quantifies token-level distributional disagreement via likelihood-based divergences between base and reasoning models, reports empirical sparsity and enrichment statistics on planning tokens, and evaluates a disagreement-guided one-token intervention. These steps consist of direct distributional comparisons and controlled experiments on benchmarks; none reduce by construction to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The derivation chain is therefore independent of its own outputs and remains falsifiable against external task performance.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
token-level distributional disagreement ... Cross Entropy (CE) ... st = D_CE(pb(·|xt), pr(·|xt)) ... disagreement-gated token intervention
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
planning enrichment ... 17× ... early positions ... uncertainty alignment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford,...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Cai, Y ., Cao, D., Xu, X., Yao, Z., Huang, Y ., Tan, Z., Zhang, B., Liu, G., and Fang, J. On predictability of reinforce- ment learning dynamics for large language models.CoRR, abs/2510.00553,
- [3]
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.CoRR, abs/2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gandhi, K., Chakravarthy, A., Singh, A., Lile, N., and Goodman, N. D. Cognitive behaviors that enable self- improving reasoners, or, four habits of highly effective stars.CoRR, abs/2503.01307,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Minillm: Knowl- edge distillation of large language models
Gu, Y ., Dong, L., Wei, F., and Huang, M. Minillm: Knowl- edge distillation of large language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7–11,
work page 2024
-
[7]
He, Q., Ren, Q., Lei, S., Wang, X., and Wang, Y . Be- yond correctness: Confidence-aware reward modeling for enhancing large language model reasoning.CoRR, abs/2511.07483,
-
[8]
Distilling the Knowledge in a Neural Network
Hinton, G. E., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.CoRR, abs/1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., and Chen, W. Lora: Low-rank adaptation of large language models.CoRR, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
ISSN 0018-9448. doi: 10.1109/TIT.2009. 2027527. URL https://doi.org/10.1109/TIT. 2009.2027527. Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., Iftimie, A., Karpenko, A., Passos, A. T., Neitz, A., Prokofiev, A., Wei, A., Tam, A., Bennett, A., Kumar, A., Saraiva, A., Vallone, A., Dubers...
-
[11]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. CoRR, abs/2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[12]
Li, C., Xu, T., and Guo, Y . Reasoning-as-logic-units: Scal- ing test-time reasoning in large language models through logic unit alignment.arXiv preprint arXiv:2502.07803,
-
[13]
URL https://doi.org/10.2307/2276207
doi: 10.2307/2276207. URL https://doi.org/10.2307/2276207. Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y ., Gupta, S., Majumder, B. P., Hermann, K., Welleck, S., Yazdanbakhsh, A., and Clark, P. Self-refine: Iterative refinement with self-feedback. InNeurIPS,
-
[15]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C
Ac- cessed: 2025-12-23. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. InNeurIPS,
work page 2025
-
[16]
Adaswitch: Adaptive switching genera- tion for knowledge distillation.CoRR, abs/2510.07842,
Peng, J., Wang, M., Cai, H., Li, Y ., Zhang, K., Wang, S., Yin, D., and Zhao, X. Adaswitch: Adaptive switching genera- tion for knowledge distillation.CoRR, abs/2510.07842,
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https: //openreview.net/forum?id=Ti67584b98. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Emotionshapesthediffusionofmoralizedcontentinsocialnetworks
doi: 10.1073/pnas. 0506580102. URL https://www.pnas.org/doi/ abs/10.1073/pnas.0506580102. Sun, H., Wu, J., Cai, H., Wei, X., Feng, Y ., Wang, B., Wang, S., Zhang, Y ., and Yin, D. Adaswitch: Adaptive switching between small and large agents for effective cloud-local collaborative learning. InEMNLP, pp. 8052–
-
[19]
Team, L. The llama 3 herd of models.CoRR, abs/2407.@articleDBLP:journals/corr/abs-2504- 07128, author = Sara Vera Marjanovic and Arkil Patel and Vaibhav Adlakha and Milad Aghajohari and Parishad BehnamGhader and Mehar Bhatia and Aditi Khandelwal and Austin Kraft and Benno Krojer and Xing Han L `u and Nicholas Meade and Dongchan Shin and Amirhossein Kazemn...
-
[20]
URL https: //openreview.net/forum?id=2XBPdPIcFK. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need.CoRR, abs/1706.03762,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Base models know how to reason, thinking models learn when.CoRR, abs/2510.07364,
11 Reasoning Can Be Restored by Correcting a Few Decision Tokens Venhoff, C., Arcuschin, I., Torr, P., Conmy, A., and Nanda, N. Base models know how to reason, thinking models learn when.CoRR, abs/2510.07364,
-
[22]
Wang, S., Yu, L., Gao, C., Zheng, C., Liu, S., Lu, R., Dang, K., Chen, X., Yang, J., Zhang, Z., Liu, Y ., Yang, A., Zhao, A., Yue, Y ., Song, S., Yu, B., Huang, G., and Lin, J. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. CoRR, abs/2506.01939, 2025a. Wang, X., Wei, J., Schuurmans, D., Le, Q....
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Wang, Y ., Yang, Q., Zeng, Z., Ren, L., Liu, L., Peng, B., Cheng, H., He, X., Wang, K., Gao, J., Chen, W., Wang, S., Du, S. S., and Shen, Y . Reinforcement learning for reasoning in large language models with one training example.CoRR, abs/2504.20571, 2025b. Ward, J., Lin, C., Venhoff, C., and Nanda, N. Reasoning- finetuning repurposes latent representati...
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E. H., Le, Q., and Zhou, D. Chain of thought prompt- ing elicits reasoning in large language models.CoRR, abs/2201.11903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Wen, X., Liu, Z., Zheng, S., Xu, Z., Ye, S., Wu, Z., Liang, X., Wang, Y ., Li, J., Miao, Z., Bian, J., and Yang, M. Reinforcement learning with verifiable rewards implic- itly incentivizes correct reasoning in base llms.CoRR, abs/2506.14245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
M., Pehlevan, C., Je- lassi, S., and Malach, E
Zhao, R., Meterez, A., Kakade, S. M., Pehlevan, C., Je- lassi, S., and Malach, E. Echo chamber: RL post- training amplifies behaviors learned in pretraining.CoRR, abs/2504.07912,
-
[28]
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y ., Min, Y ., Zhang, B., Zhang, J., Dong, Z., Du, Y ., Yang, C., Chen, Y ., Chen, Z., Jiang, J., Ren, R., Li, Y ., Tang, X., Liu, Z., Liu, P., Nie, J., and Wen, J. A survey of large language models.CoRR, abs/2303.18223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
First return, entropy-eliciting explore.CoRR, abs/2507.07017,
Zheng, T., Xing, T., Gu, Q., Liang, T., Qu, X., Zhou, X., Li, Y ., Wen, Z., Lin, C., Huang, W., Liu, Q., Zhang, G., and Ma, Z. First return, entropy-eliciting explore.CoRR, abs/2507.07017,
-
[30]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A., Phan, L., Chen, S. L., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A., Goel, S., Li, N., Byun, M. J., Wang, Z., Mallen, A., Basart, S., Koyejo, S., Song, D., Fredrikson, M., Kolter, J. Z., and Hendrycks, D. Representation engineering: A top-down approach to AI transparency.CoRR, abs/2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
All evaluations are conducted on a single compute node equipped with an NVIDIA A100 GPU
for efficient, high-throughput inference. All evaluations are conducted on a single compute node equipped with an NVIDIA A100 GPU. To enable a controlled comparison between base generation and reasoning guidance (with a shared tokenizer and vocabulary), we use the Qwen3 model family (Yang et al., 2025). Specifically, we use Qwen3-0.6B-Base as the primary ...
work page 2025
-
[32]
Output:responsey 1:t. 1:// — Phase I: Offline calibration (run once) — 2:Run base rollouts onCand collectS={s t}withs t = CE(pb(· |xt), p r(· |xt)) 3:τ←Q 1−r(S)//(1−r)-quantile threshold 4:λ←E[s|s > τ]/E[s]// tail-to-mean scale 5:// — Phase II: Online decoding for promptx 0 — 6:Initializey 1:0 ← ∅ 7:fort= 1, . . . , T max do 8:x t ←(x 0, y1:t−1) 9:Compute...
work page 2021
-
[33]
and the reasoning guide is DeepSeek-R1-Distill-Llama-8B (Guo et al., 2025). Calibration follows the same procedure as in the main experiments (held-out GSM8K-style prompts, sliding windowW= 64). Table 11 reports the average performance over the six math benchmarks. The same monotonic recovery pattern holds: with ¯ρ≈0.20, guided intervention recovers ∼91% ...
work page 2025
-
[34]
This indicates that the disagreement-spike phenomenon and the resulting recovery curve are not specific to a single model family or training pipeline. Table 11.Cross-family generalization on the LLaMA pair (Accuracy / Pass@8).Base model: LLaMA-3.1-8B; reasoning guide: DeepSeek-R1-Distill-Llama-8B. The Recovery column quantifies how much the intervention r...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.