The Alpha Illusion: Reported Alpha from LLM Trading Agents Should Not Be Treated as Deployment Evidence
Pith reviewed 2026-05-19 19:14 UTC · model grok-4.3
pith:EAKE5DYU Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{EAKE5DYU}
Prints a linked pith:EAKE5DYU badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Reported alpha from LLM trading agents should not be treated as deployment evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reported alpha from end-to-end LLM trading agents should not be treated as deployment evidence. Before such returns can support claims of deployable trading capability, they must survive structural validity tests for temporal integrity, real-world frictions, counterfactual robustness, predictive calibration, numerical execution, and multi-agent disaggregation. Current public evidence cannot yet distinguish robust predictive ability from temporal contamination, unmodeled frictions, short-window Sharpe uncertainty, narrative fitting, and parametric priors. The problem is not only evaluative but structural. Language confidence is not tradable probability, narrative reasoning is not numerical n,
What carries the argument
A minimum reporting protocol suite P1-P6 with tiered applicability by claim strength, plus a modular alternative that uses LLMs as auditable information interfaces upstream of independent calibration, risk, and execution modules.
If this is right
- Reported returns require explicit checks for temporal integrity to exclude data leakage.
- Real-world frictions including transaction costs must be modeled before any deployment claim.
- Counterfactual robustness tests are needed to confirm decisions hold under varied conditions.
- Predictive calibration must ensure stated confidence matches observed outcome frequencies.
- Multi-agent disaggregation is required to isolate individual component contributions.
Where Pith is reading between the lines
- Existing LLM trading benchmarks may require updates to incorporate these validity criteria.
- The modular design offers a practical way to add language models to trading pipelines without full end-to-end reliance.
- Standardized test harnesses implementing the proposed protocols could become a community resource for future studies.
Load-bearing premise
Current public evidence cannot yet distinguish robust predictive ability from temporal contamination, unmodeled frictions, short-window Sharpe uncertainty, narrative fitting, and parametric priors.
What would settle it
Demonstration of an LLM trading agent whose returns survive all six validity tests and then deliver positive risk-adjusted performance in a live market with real capital and frictions would settle the claim.
Figures




read the original abstract
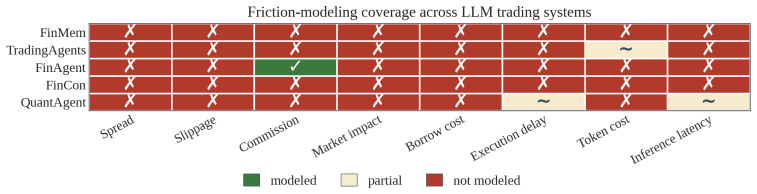
End-to-end LLM trading agents have moved quickly from research curiosity to a small ecosystem of named systems, including FinCon, FinMem, TradingAgents, FinAgent, QuantAgent, and FLAG-Trader. Several of these report headline Sharpe ratios that would be material if read at face value on a deployment desk, and associated benchmarks such as FinBen report trading-task Sharpe statistics in the same range. The gap between architecture research and deployment claim has been crossed too freely on both sides of the academia--industry divide. We take a position on that gap: reported alpha from end-to-end LLM trading agents should not be treated as deployment evidence. Before such returns can support claims of deployable trading capability, they must survive structural validity tests for temporal integrity, real-world frictions, counterfactual robustness, predictive calibration, numerical execution, and multi-agent disaggregation. Current public evidence cannot yet distinguish robust predictive ability from temporal contamination, unmodeled frictions, short-window Sharpe uncertainty, narrative fitting, and parametric priors. The problem is not only evaluative but structural. Language confidence is not tradable probability, narrative reasoning is not numerical execution, and model priors may become undisclosed implicit factor exposures. We contribute a minimum reporting protocol suite, P1--P6, with tiered applicability by claim strength, and a conservative modular alternative that uses LLMs as auditable information interfaces upstream of independent calibration, risk, and execution modules. Code and reproduction harness: \url{https://github.com/hj1650782738/Trading}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that headline performance metrics (e.g., Sharpe ratios) reported by end-to-end LLM trading agents such as FinCon, FinMem, TradingAgents, FinAgent, QuantAgent, and FLAG-Trader, as well as benchmarks like FinBen, should not be treated as deployment evidence. It enumerates structural validity requirements—temporal integrity, real-world frictions, counterfactual robustness, predictive calibration, numerical execution, and multi-agent disaggregation—and states that current public evidence cannot yet distinguish robust predictive ability from temporal contamination, unmodeled frictions, short-window Sharpe uncertainty, narrative fitting, and parametric priors. The authors contribute a tiered minimum reporting protocol (P1–P6) and a conservative modular architecture that positions LLMs as auditable information interfaces upstream of independent calibration, risk, and execution modules.
Significance. If the position holds, the work supplies a timely, principle-based corrective to the rapid expansion of LLM trading-agent papers by clarifying the evidentiary threshold between architectural results and deployable alpha. The P1–P6 protocol and modular alternative constitute constructive, actionable contributions that could raise reporting standards without requiring new empirical results from the authors themselves. The argument correctly invokes standard quantitative-finance evaluation criteria rather than deriving performance from the authors’ own fitted parameters.
major comments (1)
- [Section discussing public evidence and the gap between architecture research and deployment claim] Discussion of cited systems (FinCon, FinMem, TradingAgents, FinAgent, QuantAgent, FLAG-Trader): the central claim that 'current public evidence cannot yet distinguish robust predictive ability from temporal contamination...' is load-bearing yet rests on the absence of explicit robustness statements rather than documented properties of the specific numbers. The manuscript would be strengthened by at least one concrete audit or citation—for example, confirming whether any reported backtest used non-overlapping temporal splits or modeled bid-ask spreads—rather than general inference from missing statements.
minor comments (2)
- [Abstract] Abstract: the phrasing 'the gap between architecture research and deployment claim has been crossed too freely on both sides' risks implying authorial intent; a neutral rephrasing focused solely on the evidentiary shortfall would improve precision.
- [Proposal of minimum reporting protocol suite] P1–P6 protocol: while the tiered applicability is a useful contribution, the manuscript would benefit from a brief illustrative application of one or two protocols to an existing cited system to demonstrate practicality.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. The single major comment is addressed point-by-point below with a commitment to strengthen the evidentiary presentation while preserving the manuscript's core argument.
read point-by-point responses
-
Referee: Discussion of cited systems (FinCon, FinMem, TradingAgents, FinAgent, QuantAgent, FLAG-Trader): the central claim that 'current public evidence cannot yet distinguish robust predictive ability from temporal contamination...' is load-bearing yet rests on the absence of explicit robustness statements rather than documented properties of the specific numbers. The manuscript would be strengthened by at least one concrete audit or citation—for example, confirming whether any reported backtest used non-overlapping temporal splits or modeled bid-ask spreads—rather than general inference from missing statements.
Authors: We agree that the claim benefits from greater specificity. We have re-reviewed the methodology sections of the six cited papers and confirm that none explicitly report non-overlapping temporal splits, bid-ask spread modeling, or slippage in their backtests; several rely on daily or lower-frequency data without stating execution assumptions. We will add a concise supplementary table (or expanded footnote) that maps each system to the presence or absence of these elements as stated in the original publications. This converts the inference from pure absence into a documented literature review. A full re-audit of non-public code or proprietary data remains outside the scope of this work, but the proposed addition directly addresses the request for concrete citation. revision: yes
Circularity Check
No circularity: critique relies on external quant-finance benchmarks rather than internal re-derivation
full rationale
The paper enumerates established validity tests (temporal integrity, frictions, counterfactual robustness, etc.) drawn from quantitative finance literature and proposes an independent reporting protocol P1-P6. No equations, fitted parameters, or self-citations reduce the central claim to quantities defined by the authors' own priors or prior work. The assertion that public LLM-agent results fail to distinguish skill from contamination is an inference from missing robustness statements in the cited systems, not a self-referential loop or renamed fit. The derivation chain is self-contained against external standards.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Language confidence is not tradable probability
- domain assumption Narrative reasoning is not numerical execution
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean; IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanwashburn_uniqueness_aczel; reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PnLnet = PnL gross − ∑ (c·|Δwt| + st·|Δwt| + κ·|Δwt|^β) (eq. 1); ECE = ∑ |Bm|/n |acc(Bm)−conf(Bm)| (eq. 3); P1–P6 protocols for temporal contamination, calibration, multi-agent disaggregation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Optimal execution of portfolio transactions.Journal of Risk, 3(2):5–39, 2000
Robert Almgren and Neil Chriss. Optimal execution of portfolio transactions.Journal of Risk, 3(2):5–39, 2000
work page 2000
-
[2]
Yanxu Chen, Zijun Yao, Yantao Liu, Amy Xin, Jin Ye, Jianing Yu, Lei Hou, and Juanzi Li. StockBench: Can LLM agents trade stocks profitably in real-world markets?arXiv preprint arXiv:2510.02209, 2025
-
[3]
Empirical asset pricing via machine learning.The Review of Financial Studies, 33(5):2223–2273, 2020
Shihao Gu, Bryan Kelly, and Dacheng Xiu. Empirical asset pricing via machine learning.The Review of Financial Studies, 33(5):2223–2273, 2020
work page 2020
-
[4]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InInternational Conference on Machine Learning (ICML), pages 1321–1330. PMLR, 2017
work page 2017
-
[5]
Harvey, Yan Liu, and Heqing Zhu
Campbell R. Harvey, Yan Liu, and Heqing Zhu. . . . and the cross-section of expected returns. The Review of Financial Studies, 29(1):5–68, 2016
work page 2016
-
[6]
Ojha, Ross Spoon, Jiatong Han, and Colin F
Thomas Henning, Siddhartha M. Ojha, Ross Spoon, Jiatong Han, and Colin F. Camerer. LLM agents do not replicate human market traders: Evidence from experimental finance.arXiv preprint arXiv:2502.15800, 2025
-
[7]
The losing winner: An LLM agent that predicts the market but loses money
Youwon Jang, Joochan Kim, and Byoung-Tak Zhang. The losing winner: An LLM agent that predicts the market but loses money. InNeurIPS 2025 Workshop on Generative AI in Finance,
work page 2025
-
[8]
OpenReview:https://openreview.net/forum?id=FzahgVWy59
-
[9]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Haoqiang Kang and Xiao-Yang Liu. Deficiency of large language models in finance: An empirical examination of hallucination.arXiv preprint arXiv:2311.15548, 2023
-
[11]
Hoyoung Lee, Junhyuk Seo, Suhwan Park, Junhyeong Lee, Wonbin Ahn, Chanyeol Choi, Alejandro Lopez-Lira, and Yongjae Lee. Your AI, not your view: The bias of LLMs in investment analysis.arXiv preprint arXiv:2507.20957, 2025. ACM International Conference on AI in Finance (ICAIF) 2025
-
[12]
Xiangyu Li, Yawen Zeng, Xiaofen Xing, Jin Xu, and Xiangmin Xu. Profit mirage: Revisiting information leakage in LLM-based financial agents.arXiv preprint arXiv:2510.07920, 2025
-
[13]
Troubling Trends in Machine Learning Scholarship
Zachary C. Lipton and Jacob Steinhardt. Troubling trends in machine learning scholarship. arXiv preprint arXiv:1807.03341, 2018. Presented at ICML 2018: The Debates
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representatio...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
arXiv preprint arXiv:2112.06753 , year =
Xiao-Yang Liu, Jingyang Rui, Jiechao Gao, Liuqing Yang, Hongyang Yang, Zhaoran Wang, Christina Dan Wang, and Jian Guo. FinRL-Meta: A universe of near-real market environments for data-driven deep reinforcement learning in quantitative finance. InNeurIPS 2021 Workshop on Data-Centric AI, 2021. arXiv:2112.06753
-
[16]
Andrew W. Lo. The statistics of Sharpe ratios.Financial Analysts Journal, 58(4):36–52, 2002. 10
work page 2002
-
[17]
Alejandro Lopez-Lira and Yuehua Tang. Can ChatGPT forecast stock price movements? Return predictability and large language models.arXiv preprint arXiv:2304.07619, 2023
-
[18]
Jiaxuan Lu, Kong Wang, Yemin Wang, Qingmei Tang, Hongwei Zeng, Xiang Chen, Jiahao Pi, Shujian Deng, Lingzhi Chen, Yi Fu, Kehua Yang, and Xiao Sun. FinToolBench: Evaluating LLM agents for real-world financial tool use.arXiv preprint arXiv:2603.08262, 2026
-
[19]
Tianmi Ma, Jiawei Du, Wenxin Huang, Wenjie Wang, Liang Xie, Xian Zhong, and Joey Tianyi Zhou. Agent trading arena: A study on numerical understanding in LLM-based agents.arXiv preprint arXiv:2502.17967, 2025
-
[20]
Humzah Merchant and Bradford Levy. A fast and effective solution to the problem of look-ahead bias in LLMs.arXiv preprint arXiv:2512.06607, 2025
-
[21]
Robert Novy-Marx and Mihail Z. Velikov. AI-powered (finance) scholarship. NBER Working Paper 33363, National Bureau of Economic Research, 2025
work page 2025
-
[22]
Anna A. Obizhaeva and Jiang Wang. Optimal trading strategy and supply/demand dynamics. Journal of Financial Markets, 16(1):1–32, 2013
work page 2013
-
[23]
Lingfei Qian, Xueqing Peng, Yan Wang, Vincent Jim Zhang, Huan He, Hanley Smith, Yi Han, Yueru He, Haohang Li, Yupeng Cao, Yangyang Yu, Alejandro Lopez-Lira, Peng Lu, Jian-Yun Nie, Guojun Xiong, Jimin Huang, and Sophia Ananiadou. When agents trade: Live multi-market trading benchmark for LLM agents.arXiv preprint arXiv:2510.11695, 2025
-
[24]
Beyond the reported cutoff: Where large language models fall short on financial knowledge
Agam Shah, Liqin Ye, Sebastian Jaskowski, Wei Xu, and Sudheer Chava. Beyond the reported cutoff: Where large language models fall short on financial knowledge. InConference on Language Modeling (COLM), 2025. arXiv:2504.00042
-
[25]
Algorithms with calibrated ma- chine learning predictions
Judy Hanwen Shen, Ellen Vitercik, and Anders Wikum. Algorithms with calibrated ma- chine learning predictions. InInternational Conference on Machine Learning (ICML), 2025. arXiv:2502.02861
-
[26]
TradingAgents: Multi-agents LLM financial trading framework.arXiv preprint arXiv:2412.20138, 2024
Yijia Xiao, Edward Sun, Di Luo, and Wei Wang. TradingAgents: Multi-agents LLM financial trading framework.arXiv preprint arXiv:2412.20138, 2024
-
[27]
FinBen: A holistic financial benchmark for large language models
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, Yijing Xu, Haoqiang Kang, Ziyan Kuang, Chenhan Yuan, Kailai Yang, Zheheng Luo, Tianlin Zhang, Zhiwei Liu, Guojun Xiong, Zhiyang Deng, Yuechen Jiang, Zhiyuan Yao, Haohang Li, Yangyang Yu, Gang Hu, Jiajia Huang, Xiao-Yang Liu, Alejandr...
-
[28]
Fei Xiong, Xiang Zhang, Aosong Feng, Siqi Sun, and Chenyu You. QuantAgent: Price-driven multi-agent LLMs for high-frequency trading.arXiv preprint arXiv:2509.09995, 2025
-
[29]
Smith, Xiao-Yang Liu, Jimin Huang, Sophia Ananiadou, and Qianqian Xie
Guojun Xiong, Zhiyang Deng, Keyi Wang, Yupeng Cao, Haohang Li, Yangyang Yu, Xueqing Peng, Mingquan Lin, Kaleb E. Smith, Xiao-Yang Liu, Jimin Huang, Sophia Ananiadou, and Qianqian Xie. FLAG-Trader: Fusion LLM-agent with gradient-based reinforcement learning for financial trading.arXiv preprint arXiv:2502.11433, 2025
-
[30]
Suchow, and Khaldoun Khashanah
Yangyang Yu, Haohang Li, Zhi Chen, Yuechen Jiang, Yang Li, Denghui Zhang, Rong Liu, Jordan W. Suchow, and Khaldoun Khashanah. FinMem: A performance-enhanced LLM trading agent with layered memory and character design.arXiv preprint arXiv:2311.13743, 2023
-
[31]
Yangyang Yu, Zhiyuan Yao, Haohang Li, Zhiyang Deng, Yupeng Cao, Zhi Chen, Jordan W. Suchow, Rong Liu, Zhenyu Cui, Zhaozhuo Xu, Denghui Zhang, Koduvayur Subbalakshmi, Guojun Xiong, Yueru He, Jimin Huang, Dong Li, and Qianqian Xie. FinCon: A synthe- sized LLM multi-agent system with conceptual verbal reinforcement for enhanced financial decision making. InA...
-
[32]
Xiaochuang Yuan, Hui Xu, Silvia Xu, Cui Zou, and Jing Xiong. TraderBench: How robust are AI agents in adversarial capital markets?arXiv preprint arXiv:2603.00285, 2026
-
[33]
Hangfan Zhang, Zhiyao Cui, Jianhao Chen, Xinrun Wang, Qiaosheng Zhang, Zhen Wang, Dinghao Wu, and Shuyue Hu. Stop overvaluing multi-agent debate—we must rethink evaluation and embrace model heterogeneity.arXiv preprint arXiv:2502.08788, 2025
-
[34]
A multimodal foundation agent for financial trading: Tool-augmented, diversified, and generalist
Wentao Zhang, Lingxuan Zhao, Haochong Xia, Shuo Sun, Jiaze Sun, Molei Qin, Xinyi Li, Yuqing Zhao, Yilei Zhao, Xinyu Cai, Longtao Zheng, Xinrun Wang, and Bo An. A multimodal foundation agent for financial trading: Tool-augmented, diversified, and generalist. InProceed- ings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD),
-
[35]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2307.13854. A Per-Ticker Reported Sharpe across Three ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Information ex- traction LLM-led, schema-bound Extract structured propositions from news, filings, calls, announce- ments Source span, publication time, re- trieval time, entity/event labels
-
[37]
Feature construc- tion Quant module Provides candidate structured in- puts, does not set feature weights Point-in-time feature table, missing- data handling, normalization rules
-
[38]
Signal synthesis Quant model One of many information sources Ablation and marginal contribution of LLM-derived features
-
[39]
Probability cali- bration Independent statistical module Does not provide self-rated trading probabilities ECE, reliability curves, regime- conditioned calibration, out-of- sample stability
-
[40]
Sizing and risk control Portfolio and risk mod- ules Explains sources of risk, does not directly determine size Factor exposures, sector exposures, leverage, drawdown, liquidity con- straints
-
[41]
Suppose at time t an 8-K is released stating that company X is cutting next-quarter revenue guidance
Execution and au- dit Execution system Observer or summarizer Order log, fill prices, slippage, latency, failed orders, risk-stop records E Worked Example: 8-K Guidance Cut Through the Modular Pipeline This appendix walks the modular stage structure (Table 5) on a concrete event, as a description of existing practice rather than a proposal. Suppose at tim...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.