Reliability and Effectiveness of Autonomous AI Agents in Supply Chain Management
Pith reviewed 2026-05-22 09:45 UTC · model grok-4.3
The pith
Autonomous AI agents using reasoning models can outperform human teams in supply chain tasks while post-training improves their reliability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
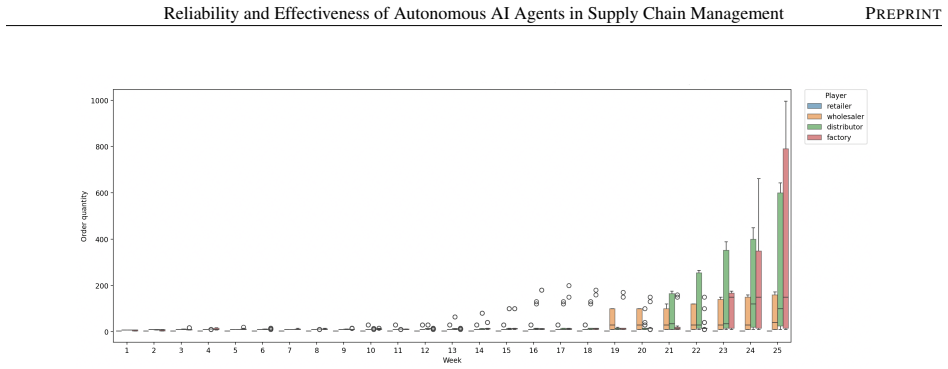
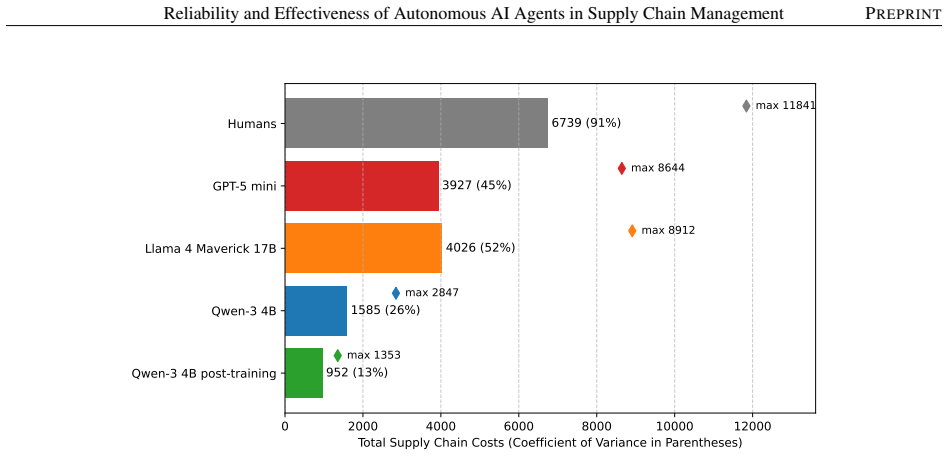
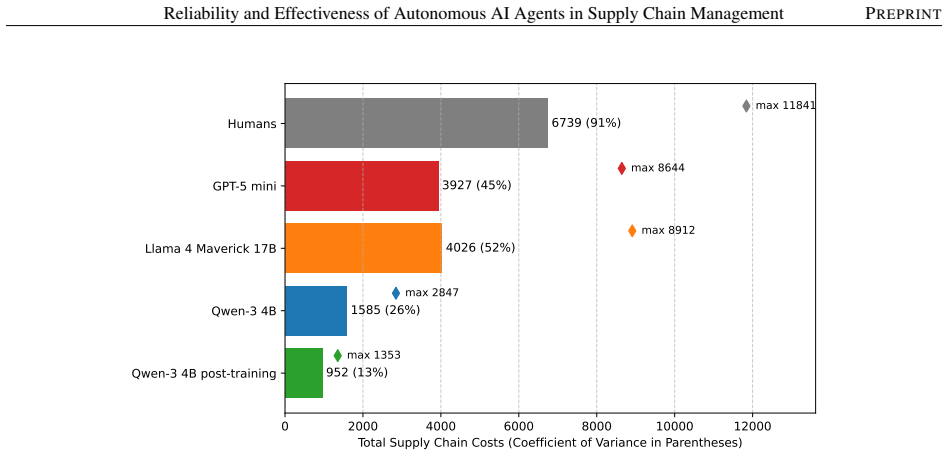
The central claim is that model capability is the main driver of performance for autonomous AI agents in supply chains, where out-of-the-box reasoning models already surpass human-level results and optimized ones achieve up to 67% cost reduction, yet average success hides risks from decision instability that amplifies both spatially and temporally; GRPO-based post-training on system-level rewards substantially mitigates tail events and agent bullwhip.
What carries the argument
Group Relative Policy Optimization (GRPO)-based reinforcement-learning post-training framework that optimizes a shared base LLM using system-level supply-chain rewards to reduce decision variability.
If this is right
- Out-of-the-box reasoning models exceed human performance in supply chain cost management.
- Optimized models can achieve up to 67% cost reduction compared to human teams.
- Decision instability amplifies across facilities and over time even with fixed demand.
- Repeated sampling of model outputs does not sufficiently reduce instability.
- GRPO post-training reduces tail events and improves overall reliability of the agents.
Where Pith is reading between the lines
- If the Beer Game results generalize, real supply chains might see similar cost savings but would require custom post-training for stability.
- Agent bullwhip could appear in other domains where multiple AI agents interact sequentially, suggesting a need for system-level optimization in multi-agent setups.
- Companies might test these agents in their own simulated environments before deployment to identify instability patterns.
- Future work could explore combining GRPO with other methods like centralized data sharing for even better performance.
Load-bearing premise
The MIT Beer Game with its fixed demand patterns and four-echelon structure is representative of real multi-echelon supply chains so that the performance and instability results will transfer.
What would settle it
Deploying the trained AI agents in an actual multi-echelon supply chain and measuring whether order variability from agent decisions exceeds that expected from demand changes alone, or whether cost reductions fall short of the reported levels.
Figures






read the original abstract
This paper studies autonomous generative AI agents in multi-echelon supply chains using the MIT Beer Game. We identify four inference-time levers that shape performance: model selection, policies and guardrails, centralized data sharing, and prompt engineering. Model capability is the dominant factor: an out-of-the-box reasoning model exceeds human-level performance, and optimized reasoning models reduce costs by up to 67% relative to human teams. However, strong average performance masks substantial reliability risks. We introduce agent bullwhip: the amplification of run-to-run decision instability in autonomous multi-echelon systems. A central component is decision bullwhip, the portion of order variability generated by stochastic agent decisions rather than by changes in customer demand. We show that decision instability can amplify both across facilities at a fixed point in time and within the same facility over time, even when the demand path is held fixed. Repeated sampling, a natural test-time remedy, fails to meaningfully reduce this instability, suggesting that reliability requires changing the underlying decision policy rather than merely averaging over model outputs. To address this limitation, we propose a Group Relative Policy Optimization (GRPO)-based reinforcement-learning post-training framework that trains a shared base LLM using system-level supply-chain rewards. Post-training substantially reduces tail events, curtails agent bullwhip, and improves the reliability of autonomous supply-chain agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies autonomous generative AI agents in multi-echelon supply chains via the MIT Beer Game simulation. It identifies four inference-time levers (model selection, policies/guardrails, centralized data sharing, prompt engineering) and claims that out-of-the-box reasoning models exceed human performance while optimized models achieve up to 67% cost reduction. The work defines agent bullwhip and decision bullwhip to quantify decision instability, shows that repeated sampling does not mitigate it, and proposes GRPO-based post-training on system-level rewards to reduce tail events, curtail bullwhip, and improve reliability.
Significance. If the empirical results on cost reduction and reliability gains transfer beyond the specific simulation, the paper would make a meaningful contribution by demonstrating both the potential of reasoning models in supply-chain control and the need for post-training to address instability. The GRPO framework for shared base-LLM training with system-level rewards is a concrete technical step that could be adopted in other multi-agent settings.
major comments (2)
- [Abstract and §3] Abstract and §3 (Experimental Setup): the headline quantitative claims (67% cost reduction, tail-event reduction, out-of-the-box model exceeding human performance) are presented without any description of the number of simulation runs, statistical tests, variance estimates, or how the human baseline teams were constructed and incentivized. These omissions make it impossible to assess whether the reported gains are robust or statistically distinguishable from noise.
- [§4 and §5] §4 (Beer Game Configuration) and §5 (Results): all performance, bullwhip, and reliability metrics are obtained exclusively inside the deterministic four-echelon MIT Beer Game with fixed demand paths. No sensitivity analysis to stochastic lead times, multi-product flows, or external shocks is reported; because the definitions of agent bullwhip and decision bullwhip are tied to this structure, the claimed superiority of GRPO post-training over baselines does not yet have evidence of transferability to more realistic supply-chain environments.
minor comments (2)
- [Abstract and §5] The notation for 'agent bullwhip' and 'decision bullwhip' is introduced in the abstract and results but never given an explicit mathematical definition or formula; adding a short equation or pseudocode block would improve reproducibility.
- [Results figures] Figure captions and axis labels in the results section should explicitly state the number of independent runs and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We are grateful to the referee for these constructive comments, which help strengthen the presentation of our results. We respond to each major comment below and note the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Experimental Setup): the headline quantitative claims (67% cost reduction, tail-event reduction, out-of-the-box model exceeding human performance) are presented without any description of the number of simulation runs, statistical tests, variance estimates, or how the human baseline teams were constructed and incentivized. These omissions make it impossible to assess whether the reported gains are robust or statistically distinguishable from noise.
Authors: We agree that these details are necessary to evaluate robustness. In the revised manuscript we will expand §3 to describe the number of simulation runs performed for each configuration, the statistical tests used for comparisons, variance estimates, and the construction and incentivization of the human baseline teams. revision: yes
-
Referee: [§4 and §5] §4 (Beer Game Configuration) and §5 (Results): all performance, bullwhip, and reliability metrics are obtained exclusively inside the deterministic four-echelon MIT Beer Game with fixed demand paths. No sensitivity analysis to stochastic lead times, multi-product flows, or external shocks is reported; because the definitions of agent bullwhip and decision bullwhip are tied to this structure, the claimed superiority of GRPO post-training over baselines does not yet have evidence of transferability to more realistic supply-chain environments.
Authors: The deterministic MIT Beer Game with fixed demand was chosen deliberately to isolate agent bullwhip as variability arising from stochastic agent decisions rather than demand changes. We acknowledge that this controlled setting does not provide direct evidence of transferability to stochastic lead times, multi-product flows, or external shocks. In the revision we will add a limitations discussion in §5 that explicitly addresses this scope and outlines how the GRPO framework could be extended, while noting that comprehensive sensitivity experiments lie beyond the current study. revision: partial
Circularity Check
No significant circularity: empirical simulation results stand independently
full rationale
The paper reports direct empirical measurements from MIT Beer Game simulations rather than any closed-form derivation or mathematical chain. Performance gains, cost reductions, and reliability improvements (including GRPO effects on tail events and agent bullwhip) are quantified as observed outcomes in the fixed four-echelon setup; no equations or fitted parameters are redefined as predictions. New terms such as agent bullwhip and decision bullwhip are introduced as operational definitions extracted from simulation variability, not as self-referential constructs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the reported results. The work is self-contained as a simulation study whose claims can be externally replicated or falsified against the same benchmark without reducing to internal inputs.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.