CLAP: Contrastive Latent-space Prompt Optimization for End-to-end Autonomous Driving
Pith reviewed 2026-05-20 14:52 UTC · model grok-4.3
The pith
CLAP optimizes soft prompts along a contrastive hard-scene direction in VLA latent space to cut errors in rare driving scenarios by 24% with no effect on normal ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
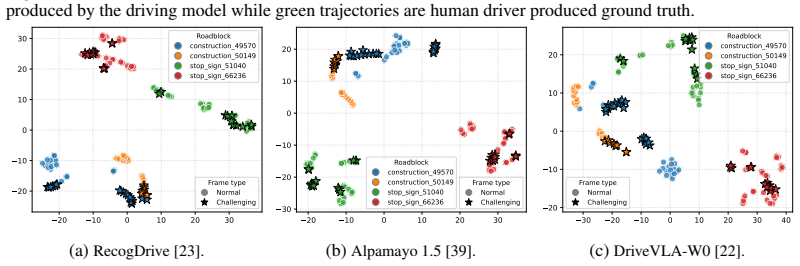
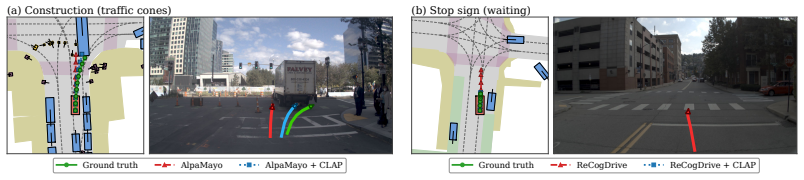
Scenarios from the same roadblock form compact clusters in the VLA hidden-state layer, yet long-tail and normal frames remain heavily intermixed within each cluster. CLAP discovers a roadblock-specific hard-scene direction through supervised contrastive learning and then performs directionally regularized prompt optimization to raise performance on challenging frames while leaving normal-frame behavior unchanged. When evaluated on the NAVSIM benchmark with multiple state-of-the-art VLA backbones, the resulting per-roadblock prompts reduce planning error on challenging scenarios by 24 percent with no regression on normal frames.
What carries the argument
The roadblock-specific hard-scene direction obtained via supervised contrastive learning on VLA hidden states, which guides regularized optimization of location-specific soft prompts.
If this is right
- Challenging-scenario planning error falls by 24 percent on the NAVSIM benchmark.
- Normal-frame performance stays the same across tested VLA backbones.
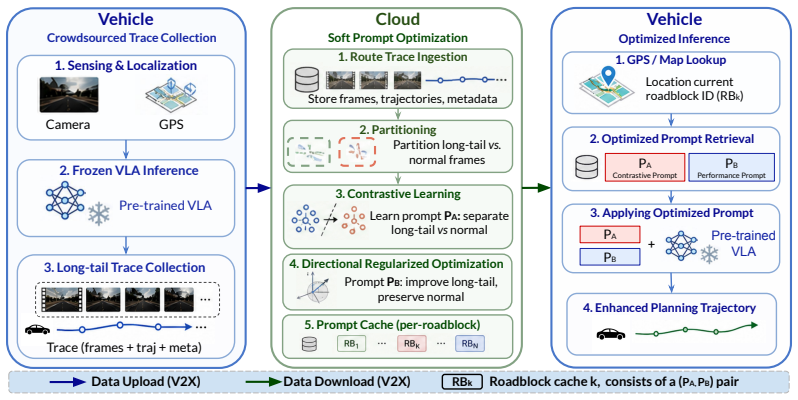
- Per-roadblock prompts can be prepared from crowdsourced data and activated on demand via V2X.
- The frozen base model requires no retraining for the adaptation to take effect.
Where Pith is reading between the lines
- The same contrastive-direction approach could be tested on other long-tail failure modes such as specific weather patterns or unusual traffic configurations.
- Widespread V2X deployment would allow dynamic loading of location-tuned prompts without storing them all onboard.
- The technique may transfer to other sequential decision systems whose latent spaces exhibit similar roadblock-style clustering.
Load-bearing premise
The latent space of the VLA model contains a discoverable direction that points toward hard scenes for a given roadblock and remains sufficiently separate from normal scenes at the same location.
What would settle it
If optimizing the prompt along the discovered contrastive direction produces measurable changes to planning outputs on normal frames from the same roadblock, the claim of selective improvement would be falsified.
Figures





read the original abstract
End-to-end autonomous driving systems powered by Vision-Language-Action (VLA) models achieve strong performance on common driving scenarios, yet remain brittle in rare but safety-critical long-tail situations such as active construction zones and complex yielding geometries. In this paper, we present a method that addresses the long-tail challenging scenes beyond data scaling and model training. We introduce CLAP (Contrastive Latent-space Prompt optimization), a location-aware adaptation framework that augments a frozen VLA driving model with per-roadblock soft prompts, optimized from crowdsourced data and retrieved on demand via Vehicle-to-Everything (V2X) communication. Our approach rests on two observations from VLAs' latent space: (i) at the VLA's hidden-state layer, scenarios from the same roadblock cluster tightly and occupy compact regions of the latent space; and (ii) within a single roadblock, long-tail and normal frames are heavily intermixed in the latent representation, making it difficult to improve one without disturbing the other. CLAP addresses this via a two-stage pipeline: supervised contrastive learning to discover a roadblock-specific hard-scene direction, followed by directionally regularized prompt optimization that selectively improves challenging frames while preserving normal frame performance. On the NAVSIM benchmark with various state-of-the-art VLA backbones, CLAP reduces challenging scenario planning error by 24% with no regression on normal frames, significantly improving planning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLAP, a location-aware adaptation framework for frozen Vision-Language-Action (VLA) models in end-to-end autonomous driving. It uses two observations about latent-space clustering at the hidden-state layer—tight per-roadblock grouping and intermixing of long-tail vs. normal frames—to motivate a two-stage pipeline: supervised contrastive learning to extract a roadblock-specific hard-scene direction, followed by directionally regularized soft-prompt optimization. Per-roadblock prompts are derived from crowdsourced data and retrieved via V2X. On the NAVSIM benchmark the method is reported to reduce planning error by 24% on challenging scenarios while producing no regression on normal frames across multiple VLA backbones.
Significance. If the directional-regularization mechanism demonstrably isolates improvement to challenging frames, the approach would supply a practical, low-cost route to handling long-tail safety-critical situations without retraining the base VLA model. The combination of contrastive direction discovery with prompt tuning and V2X retrieval is a concrete engineering contribution that could be adopted by existing end-to-end stacks.
major comments (3)
- [§4.3] §4.3 (directional regularization): the claim that the regularization term keeps normal-frame metrics flat rests on the assumption that the discovered hard-scene direction is sufficiently orthogonal to normal-frame variation; no ablation that removes or weakens this term is presented, so it is impossible to verify that the reported zero-regression result is caused by the regularization rather than conservative optimization.
- [Table 2] Table 2 / Results section: the 24% reduction on challenging scenarios is stated without error bars, number of random seeds, or statistical significance tests; given the intermixing noted in the latent-space analysis, these omissions make it difficult to judge whether the selectivity is robust or an artifact of a single run.
- [§5.1] §5.1 (experimental protocol): the manuscript provides no definition or quantitative criterion for labeling frames as “challenging” versus “normal” within the NAVSIM splits, nor any description of how roadblock boundaries are determined for prompt retrieval; both are load-bearing for the central selectivity claim.
minor comments (2)
- [Abstract] The abstract and §3.2 use the phrase “various state-of-the-art VLA backbones” without listing the concrete models or citing their original papers; this should be made explicit.
- [Figure 2] Figure 2 (latent-space visualization) would benefit from a quantitative inset reporting intra- vs. inter-cluster distances or silhouette scores to support the qualitative claim of tight roadblock clustering.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment below and will revise the manuscript to strengthen the presentation of our results and experimental details.
read point-by-point responses
-
Referee: [§4.3] §4.3 (directional regularization): the claim that the regularization term keeps normal-frame metrics flat rests on the assumption that the discovered hard-scene direction is sufficiently orthogonal to normal-frame variation; no ablation that removes or weakens this term is presented, so it is impossible to verify that the reported zero-regression result is caused by the regularization rather than conservative optimization.
Authors: We appreciate this point. To directly demonstrate the role of directional regularization, we will add an ablation in the revised manuscript that performs prompt optimization without the regularization term. We will report planning errors on both challenging and normal frames for this variant across the evaluated VLA backbones, allowing readers to verify that the regularization is responsible for preserving normal-frame performance. revision: yes
-
Referee: Table 2 / Results section: the 24% reduction on challenging scenarios is stated without error bars, number of random seeds, or statistical significance tests; given the intermixing noted in the latent-space analysis, these omissions make it difficult to judge whether the selectivity is robust or an artifact of a single run.
Authors: We agree that additional statistical reporting is warranted. In the revision we will rerun all experiments with at least five random seeds, include standard-deviation error bars in Table 2, and report statistical significance (e.g., paired t-tests or Wilcoxon tests) comparing CLAP against the frozen baseline on both challenging and normal subsets. This will substantiate that the observed selectivity is robust rather than run-specific. revision: yes
-
Referee: [§5.1] §5.1 (experimental protocol): the manuscript provides no definition or quantitative criterion for labeling frames as “challenging” versus “normal” within the NAVSIM splits, nor any description of how roadblock boundaries are determined for prompt retrieval; both are load-bearing for the central selectivity claim.
Authors: Thank you for highlighting this omission. We will expand §5.1 to provide (i) a quantitative definition of challenging frames (e.g., frames whose planning error exceeds the 90th percentile of the NAVSIM validation distribution or that contain annotated long-tail events such as construction zones) and (ii) the precise procedure for determining roadblock boundaries, including how V2X location data and crowdsourced annotations are used to delineate per-roadblock regions for prompt retrieval. These additions will make the selectivity evaluation fully reproducible. revision: yes
Circularity Check
No circularity; standard contrastive + prompt pipeline with external benchmark evaluation
full rationale
The derivation chain consists of two explicit stages: (1) supervised contrastive learning on observed latent-space clustering to extract a roadblock-specific direction, and (2) directionally regularized soft-prompt optimization whose selectivity is then measured on the held-out NAVSIM benchmark. Neither stage reduces to a self-definition, a fitted parameter relabeled as a prediction, or a load-bearing self-citation. The central performance claim (24 % error reduction with zero normal-frame regression) is an empirical outcome on an external test set rather than an algebraic identity with the training objective. No uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Scenarios from the same roadblock cluster tightly and occupy compact regions at the VLA's hidden-state layer
- domain assumption Within a single roadblock, long-tail and normal frames are heavily intermixed in the latent representation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
supervised contrastive learning to discover a roadblock-specific hard-scene direction, followed by directionally regularized prompt optimization
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
scenarios from the same roadblock cluster tightly and occupy compact regions of the latent space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Baidu Apollo.https://www.apollo.auto/, 2022
work page 2022
-
[2]
Waymo - Self-Driving Cars - Autonomous Vehicles - Ride-Hail.https://waymo.com/, 2026
work page 2026
-
[3]
Autoware: Open-source software for self-driving vehicles.https: //www.autoware.org/, 2015
Autoware Foundation. Autoware: Open-source software for self-driving vehicles.https: //www.autoware.org/, 2015
work page 2015
- [4]
-
[5]
D. Bogdoll, S. Guneshka, and J. M. Z ¨ollner. One ontology to rule them all: Corner case scenarios for autonomous driving. InEuropean Conference on Computer Vision, pages 409–
-
[6]
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
work page 2024
-
[7]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
work page 2024
-
[8]
C.-H. Cheng, C.-H. Huang, and H. Yasuoka. Quantitative projection coverage for testing ml- enabled autonomous systems. InInternational Symposium on Automated Technology for Veri- fication and Analysis, pages 126–142. Springer, 2018
work page 2018
- [9]
-
[10]
Claude sonnet 4.6.https://www.anthropic.com/claude/sonnet, 2026
Claude. Claude sonnet 4.6.https://www.anthropic.com/claude/sonnet, 2026
work page 2026
-
[11]
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta. Navsim: Data-driven non-reactive au- tonomous vehicle simulation and benchmarking. InAdvances in Neural Information Process- ing Systems (NeurIPS), 2024. URLhttps://github.com/autonomousvision/navsim
work page 2024
-
[12]
Google gemini.https://gemini.google.com/, 2026
Google. Google gemini.https://gemini.google.com/, 2026
work page 2026
- [13]
-
[14]
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 17853–17862, 2023
work page 2023
-
[15]
EMMA: End-to-End Multimodal Model for Autonomous Driving
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
- [17]
-
[18]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [19]
-
[20]
X. L. Li and P. Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021
work page 2021
-
[21]
Y . Li, S. Ren, P. Wu, S. Chen, C. Feng, and W. Zhang. Learning distilled collaboration graph for multi-agent perception.Advances in Neural Information Processing Systems, 34:29541– 29552, 2021
work page 2021
-
[22]
Y . Li, S. Shang, W. Liu, B. Zhan, H. Wang, Y . Wang, Y . Chen, X. Wang, Y . An, C. Tang, et al. Drivevla-w0: World models amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796 (accpeted to ICLR 2026), 2025
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052 (accepted to ICLR 2026), 2025
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [24]
-
[25]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
work page 2025
-
[26]
H. X. Liu and S. Feng. Curse of rarity for autonomous vehicles.Nature Communications, 15 (1):4808, 2024
work page 2024
-
[27]
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys, 55(9):1–35, 2023
work page 2023
-
[28]
X. Liu, N. Xu, M. Chen, and C. Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Y . Luo, Z. Yang, F. Meng, Y . Li, J. Zhou, and Y . Zhang. An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-Tuning.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 33:3776–3786, 2025
work page 2025
-
[30]
O. Makansi, ¨O. C ¸ ic ¸ek, Y . Marrakchi, and T. Brox. On exposing the challenging long tail in future prediction of traffic actors. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13147–13157, 2021
work page 2021
-
[31]
NVIDIA. NVIDIA A40: Powerful Data Center GPU For Visual Computing.https://imag es.nvidia.com/content/Solutions/data-center/a40/nvidia-a40-datasheet.p df, 2022
work page 2022
-
[32]
C. Sakaridis, D. Dai, and L. Van Gool. Acdc: The adverse conditions dataset with correspon- dences for semantic driving scene understanding. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 10765–10775, 2021. 11
work page 2021
-
[33]
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li. Lmdrive: Closed-loop end-to-end driving with large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15120–15130, 2024
work page 2024
- [34]
-
[35]
Y . Sun, X. Wang, Z. Liu, J. Miller, A. Efros, and M. Hardt. Test-time training with self- supervision for generalization under distribution shifts. InInternational conference on machine learning, pages 9229–9248. PMLR, 2020
work page 2020
-
[36]
R. S. Sutton and A. G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cam- bridge, MA, second edition, 2018
work page 2018
-
[37]
L. Van der Maaten and G. Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
work page 2008
-
[38]
H. Wang, T. Li, Y . Li, L. Chen, C. Sima, Z. Liu, B. Wang, P. Jia, Y . Wang, S. Jiang, et al. Openlane-v2: A topology reasoning benchmark for unified 3d hd mapping.Advances in Neural Information Processing Systems, 36:18873–18884, 2023
work page 2023
-
[39]
Y . Wang, W. Luo, J. Bai, Y . Cao, T. Che, K. Chen, Y . Chen, J. Diamond, Y . Ding, W. Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
S. Wei, Y . Wei, Y . Hu, Y . Lu, Y . Zhong, S. Chen, and Y . Zhang. Asynchrony-robust collabora- tive perception via bird’s eye view flow.Advances in Neural Information Processing Systems, 36:28462–28477, 2023
work page 2023
-
[41]
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S.-m. Yin, S. Bai, X. Xu, Y . Chen, et al. Qwen- image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
J. Wu, T. Yu, R. Wang, Z. Song, R. Zhang, H. Zhao, C. Lu, S. Li, and R. Henao. Infoprompt: Information-theoretic soft prompt tuning for natural language understanding.Advances in neural information processing systems, 36:61060–61084, 2023
work page 2023
-
[43]
Y . Xie, R. Xu, T. He, J.-J. Hwang, K. Luo, J. Ji, H. Lin, L. Chen, Y . Lu, Z. Leng, et al. S4-driver: Scalable self-supervised driving multimodal large language model with spatio-temporal visual representation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1622–1632, 2025
work page 2025
-
[44]
S. Xing, C. Qian, Y . Wang, H. Hua, K. Tian, Y . Zhou, and Z. Tu. Openemma: Open-source multimodal model for end-to-end autonomous driving. InProceedings of the Winter Confer- ence on Applications of Computer Vision, pages 1001–1009, 2025
work page 2025
-
[45]
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin. Goalflow: Goal- driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025
work page 2025
- [46]
-
[47]
D. Zhao, J. Li, S. Wang, M. Wu, Q. Zang, N. Sebe, and Z. Zhong. Fishertune: Fisher-guided robust tuning of vision foundation models for domain generalized segmentation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Conference, pages 15043–15054, 2025
work page 2025
- [48]
-
[49]
Z. Zhou, T. Cai, S. Z. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and rein- forcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shao, et al. In- ternvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
R. Zhu, X. Zhu, A. Zhang, X. Zhang, J. Sun, F. Qian, H. Qiu, Z. M. Mao, and M. Lee. Boost- ing collaborative vehicular perception on the edge with vehicle-to-vehicle communication. In Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems, pages 141–154, 2024
work page 2024
-
[52]
R. Zhu, M. Cho, S. Zeng, F. Bai, X. Gao, and Z. M. Mao. Scalable crowd-sourced global hd map construction via collaborative map perception and sparse graph fusion. InThe 4th Workshop on Transformers for Vision (T4V) at CVPR 2025, 2025
work page 2025
-
[53]
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson. Universal and transfer- able adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 13 A Appendix Figure 7:Rain augmentation examples across three roadblocks. In each panel, columns are left, front, right, and back cameras; top row is the original NA VSIM...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.