SafeLens: Deliberate and Efficient Video Guardrails with Fast-and-Slow Screening
Pith reviewed 2026-05-20 13:59 UTC · model grok-4.3
The pith
SafeLens delivers state-of-the-art video moderation through fast-and-slow screening at reduced cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SafeLens combines a fast-and-slow screening architecture with a filtered training dataset and structured chain-of-thought augmentation to perform accurate and efficient video content moderation, outperforming existing guardrails on benchmarks while reducing computational expense.
What carries the argument
The fast-and-slow inference architecture, which routes simple inputs to fast pattern recognition and complex ones to slower, more deliberate reasoning.
If this is right
- Video platforms can moderate content with lower latency and resource use.
- AI-generated video safety checks become more practical at scale.
- Training on smaller but higher-quality datasets can match or exceed results from larger ones.
- Test-time reasoning augmentation improves performance without additional training data.
Where Pith is reading between the lines
- Similar fast-and-slow designs might apply to other content moderation tasks like text or image safety.
- Reducing inference cost could enable real-time moderation on smaller hardware.
- The method highlights the value of data filtering over data scaling in safety applications.
Load-bearing premise
The small filtered subset of the SafeWatch Dataset still represents the full distribution of policy-violating and non-violating videos well enough for accurate generalization.
What would settle it
Training the same model architecture on the unfiltered full SafeWatch Dataset and comparing its benchmark performance and inference cost to SafeLens would test whether the filtering step is necessary or beneficial.
Figures









read the original abstract
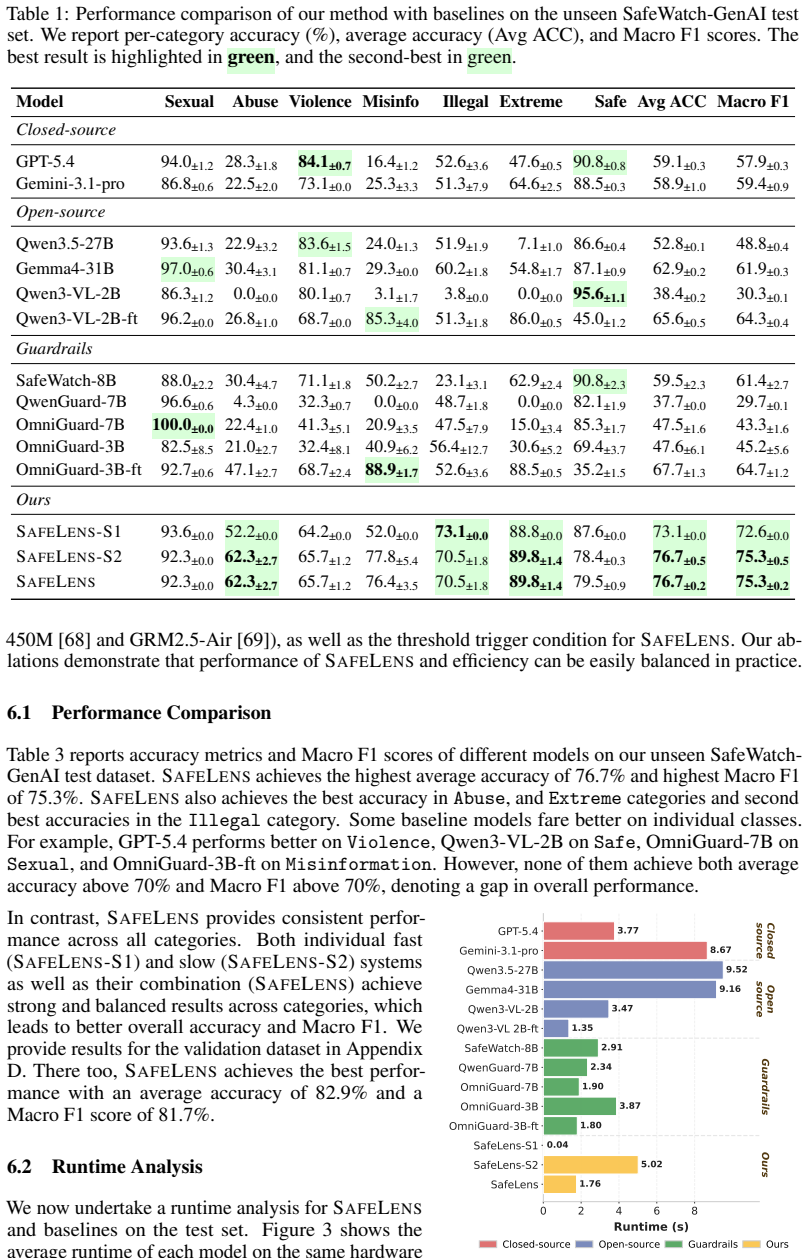
The rapid growth of online video platforms and AI-generated content has made reliable video guardrails a key challenge for safety and real-world deployment. While most videos can be screened through fast pattern recognition, a small subset requires deeper reasoning over temporally complex content and nuanced policy constraints. Existing approaches typically rely on large vision-language models applied uniformly across all inputs, resulting in high inference costs and inefficient allocation of computation. We propose SafeLens, a video guardrail framework that introduces a fast-and-slow inference architecture for efficient and accurate content moderation with variable computational cost across inputs. Additionally, we construct a high-quality dataset by applying influence-guided filtering to the SafeWatch Dataset, retaining only 2.4% of the original data. To further address limitations of training-time scaling, we enable test-time reasoning by augmenting the filtered data with structured Chain-of-Thought traces. Across real-world and AI-generated video benchmarks, SafeLens achieves state-of-the-art performance, outperforming strong open-source video guardrails (e.g., SafeWatch-8B, OmniGuard-7B) and closed-source models (e.g., GPT-5.4, Gemini-3.1-pro) while significantly reducing inference cost, demonstrating that efficient design serves to be more effective than scaling data or model size alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SafeLens, a fast-and-slow video guardrail framework that applies influence-guided filtering to retain only 2.4% of the SafeWatch Dataset, augments the subset with structured Chain-of-Thought traces, and deploys variable-depth inference to achieve state-of-the-art performance on real-world and AI-generated video benchmarks while reducing inference cost relative to larger open-source models (SafeWatch-8B, OmniGuard-7B) and closed-source models (GPT-5.4, Gemini-3.1-pro).
Significance. If the empirical claims hold after proper validation, the work would show that deliberate data curation combined with test-time reasoning can outperform uniform scaling of model size or training data volume in safety guardrails, offering a practical route to lower-cost deployment on video platforms.
major comments (2)
- [§3] §3 (Dataset Construction): The central SOTA claim rests on training and evaluating on the influence-filtered 2.4% subset. No coverage metrics, t-SNE embeddings, or performance numbers on the discarded 97.6% are reported, leaving open the possibility that high-influence examples preferentially retained do not represent the full distribution of temporal and nuanced policy violations needed for generalization to the benchmarks.
- [§4] §4 (Experiments): The abstract asserts outperformance and cost reduction, yet the text provides neither quantitative tables with error bars, ablation results isolating the contribution of the fast-and-slow router versus the filtered data, nor explicit comparison protocols against the cited baselines; without these, the load-bearing performance claims cannot be verified.
minor comments (1)
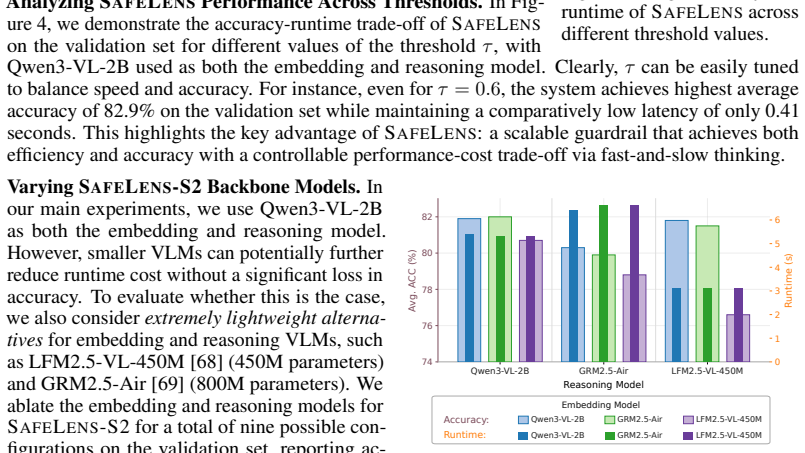
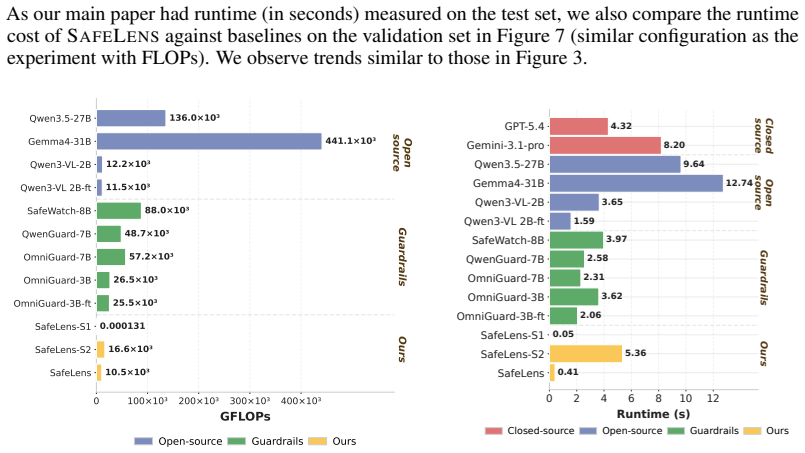
- [Abstract] Abstract: The phrasing 'significantly reducing inference cost' is not accompanied by concrete latency or FLOPs numbers even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): The central SOTA claim rests on training and evaluating on the influence-filtered 2.4% subset. No coverage metrics, t-SNE embeddings, or performance numbers on the discarded 97.6% are reported, leaving open the possibility that high-influence examples preferentially retained do not represent the full distribution of temporal and nuanced policy violations needed for generalization to the benchmarks.
Authors: We agree that additional analysis of the filtered subset's coverage is necessary to fully support the generalization claims. The influence-guided selection prioritizes examples with high impact on model behavior, but we did not report explicit distribution comparisons in the original submission. In the revised version we will add t-SNE embeddings of the full SafeWatch dataset versus the retained 2.4% subset, together with performance numbers obtained when models are trained on the discarded portion, to demonstrate that the high-influence examples preserve the necessary temporal and policy-violation diversity. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts outperformance and cost reduction, yet the text provides neither quantitative tables with error bars, ablation results isolating the contribution of the fast-and-slow router versus the filtered data, nor explicit comparison protocols against the cited baselines; without these, the load-bearing performance claims cannot be verified.
Authors: We acknowledge that the current experimental presentation lacks the quantitative rigor needed to verify the central claims. While the manuscript reports comparative results, it does not include error bars, isolated ablations, or detailed protocol descriptions. We will expand §4 with tables reporting mean performance and standard deviations across multiple runs, ablation studies that separately quantify the fast-and-slow router and the influence-filtered data, and an explicit subsection detailing the evaluation protocol, prompt templates, and inference settings used for all baselines including SafeWatch-8B, OmniGuard-7B, GPT-5.4, and Gemini-3.1-pro. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmark evaluation rather than self-referential derivations
full rationale
The paper presents SafeLens as a fast-and-slow architecture trained on an influence-filtered subset (2.4% of SafeWatch) augmented with CoT traces, with SOTA performance reported as direct empirical outcomes on real-world and AI-generated video benchmarks. No equations, fitted parameters, or mathematical derivations appear that would reduce a claimed prediction back to the training choices by construction. Dataset filtering and augmentation are methodological steps whose validity is asserted via external benchmark comparisons rather than tautological self-definition. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are described in the provided text. The results are therefore self-contained against external benchmarks and falsifiable independently of the paper's internal choices.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video interactions in online video social networks.ACM Trans
Fabrício Benevenuto, Tiago Rodrigues, Virgilio Almeida, Jussara Almeida, and Keith Ross. Video interactions in online video social networks.ACM Trans. Multimedia Comput. Commun. Appl., 5(4), November 2009
work page 2009
-
[2]
Vlm as policy: Common-law content moderation framework for short video platform
Xingyu Lu, Tianke Zhang, Chang Meng, Xiaobei Wang, Jinpeng Wang, Yi-Fan Zhang, Shisong Tang, Changyi Liu, Haojie Ding, Kaiyu Jiang, Kaiyu Tang, Bin Wen, Hai-Tao Zheng, Fan Yang, Tingting Gao, Di Zhang, and Kun Gai. Vlm as policy: Common-law content moderation framework for short video platform. InProceedings of the 31st ACM SIGKDD Conference on Knowledge ...
work page 2025
-
[3]
Fatmaelzahraa Eltaher, Rahul Krishna Gajula, Luis Miralles-Pechuán, Patrick Crotty, Juan Martínez-Otero, Christina Thorpe, and Susan McKeever. Protecting young users on social media: Evaluating the effectiveness of content moderation and legal safeguards on video sharing platforms.arXiv preprint arXiv:2505.11160, 2025
-
[4]
Video is worth a thousand images: Exploring the latest trends in long video generation.ACM Comput
Faraz Waseem and Muhammad Shahzad. Video is worth a thousand images: Exploring the latest trends in long video generation.ACM Comput. Surv., 58(6), December 2025
work page 2025
-
[5]
Moderating synthetic content: the challenge of generative ai.Philosophy & Technology, 37, 11 2024
Sarah Fisher, Jeffrey Howard, and Beatriz Kira. Moderating synthetic content: the challenge of generative ai.Philosophy & Technology, 37, 11 2024
work page 2024
-
[6]
Akash Bonagiri, Lucen Li, Rajvardhan Oak, Zeerak Babar, Magdalena Wojcieszak, and Anshu- man Chhabra. Towards safer social media platforms: scalable and performant few-shot harmful content moderation using large language models.arXiv preprint arXiv:2501.13976, 2025
-
[7]
Adi Levi, Or Levi, Sardhendu Mishra, and Jonathan Morra. Ai vs. human moderators: A com- parative evaluation of multimodal llms in content moderation for brand safety. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5965–5973, 2025
work page 2025
-
[8]
Rajvardhan Oak, Muhammad Haroon, Claire Wonjeong Jo, Magdalena Wojcieszak, and An- shuman Chhabra. Re-ranking using large language models for mitigating exposure to harmful content on social media platforms. InACL, 2025
work page 2025
-
[9]
Kuleen Sasse, Efsun Sarioglu Kayi, and Arun Reddy. Controllable hybrid captioner for improved long-form video understanding.arXiv preprint arXiv:2507.17047, 2025
-
[10]
Evaluating multimodal large language models on video captioning via Monte Carlo tree search
Linhao Yu, Xingguang Ji, Yahui Liu, Fanheng Kong, Chenxi Sun, Jingyuan Zhang, Hongzhi Zhang, Victoria W., Fuzheng Zhang, and Deyi Xiong. Evaluating multimodal large language models on video captioning via Monte Carlo tree search. InACL, 2025
work page 2025
-
[11]
Li Liu, Diji Yang, Sijia Zhong, Kalyana S Tholeti, Lei Ding, Yi Zhang, and Leilani H Gilpin. Right this way: Can vlms guide us to see more to answer questions?Advances in Neural Information Processing Systems, 37:132946–132976, 2024
work page 2024
-
[12]
Neelabh Sinha, Vinija Jain, and Aman Chadha. Guiding vision-language model selection for visual question-answering across tasks, domains, and knowledge types. In Wei Emma Zhang, Xiang Dai, Desmond Elliot, Byron Fang, Mongyuan Sim, Haojie Zhuang, and Weitong Chen, editors,Proceedings of the First Workshop of Evaluation of Multi-Modal Generation, pages 76–9...
work page 2025
-
[13]
Bodhisatta Maiti. Multilingual evaluation of image-text retrieval in vision–language models: A metric-based perspective. InProceedings of the 4th International Workshop on Multimodal Human Understanding for the Web and Social Media, MUWS ’25, page 10–16, New York, NY , USA, 2025. Association for Computing Machinery
work page 2025
-
[14]
Bulat Khaertdinov, Mirela Popa, and Nava Tintarev. A little more like this: Text-to-image re- trieval with vision-language models using relevance feedback. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3825–3834, 2026
work page 2026
-
[15]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625– 5644, 2024. 10
work page 2024
-
[16]
Towards policy-adaptive image guardrail: Benchmark and method.arXiv preprint arXiv:2603.01228, 2026
Caiyong Piao, Zhiyuan Yan, Haoming Xu, Yunzhen Zhao, Kaiqing Lin, Feiyang Xu, and Shuigeng Zhou. Towards policy-adaptive image guardrail: Benchmark and method.arXiv preprint arXiv:2603.01228, 2026
-
[17]
Memeguard: An llm and vlm-based framework for advancing content moderation via meme intervention
Prince Jha, Raghav Jain, Kumar Mandal, Aman Chadha, Sriparna Saha, and Pushpak Bhat- tacharyya. Memeguard: An llm and vlm-based framework for advancing content moderation via meme intervention. InAnnual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[18]
Shieldgemma 2: Robust and tractable image content moderation, 2025.URL https://arxiv
Wenjun Zeng, Dana Kurniawan, Ryan Mullins, Yuchi Liu, Tamoghna Saha, Dirichi Ike-Njoku, Jindong Gu, Yiwen Song, Cai Xu, Jingjing Zhou, et al. Shieldgemma 2: Robust and tractable image content moderation, 2025.URL https://arxiv. org/abs/2504.01081
-
[19]
Lukas Helff, Felix Friedrich, Manuel Brack, Kristian Kersting, and Patrick Schramowski. Llavaguard: An open vlm-based framework for safeguarding vision datasets and models.arXiv preprint arXiv:2406.05113, 2024
-
[20]
Jianfeng Chi, Ujjwal Karn, Hongyuan Zhan, Eric Smith, Javier Rando, Yiming Zhang, Kate Plawiak, Zacharie Delpierre Coudert, Kartikeya Upasani, and Mahesh Pasupuleti. Llama guard 3 vision: Safeguarding human-ai image understanding conversations.arXiv preprint arXiv:2411.10414, 2024
-
[21]
MULTIGUARD: An efficient approach for AI safety moderation across languages and modalities
Sahil Verma, Keegan Hines, Jeff Bilmes, Charlotte Siska, Luke Zettlemoyer, Hila Gonen, and Chandan Singh. MULTIGUARD: An efficient approach for AI safety moderation across languages and modalities. InEMNLP, 2025
work page 2025
-
[22]
Vidguard-r1: Ai-generated video detection and explanation via reasoning mllms and rl
Kyoungjun Park, Yifan Yang, Juheon Yi, Shicheng Zheng, Yifei Shen, Dongqi Han, Caihua Shan, Muhammad Muaz, and Lili Qiu. Vidguard-r1: Ai-generated video detection and explanation via reasoning mllms and rl.arXiv preprint arXiv:2510.02282, 2025
-
[23]
Filter-and-refine: A MLLM based cascade system for industrial-scale video content moderation
Zixuan Wang, Jinghao Shi, Hanzhong Liang, Xiang Shen, Vera Wen, Zhiqian Chen, Yifan Wu, Zhixin Zhang, and Hongyu Xiong. Filter-and-refine: A MLLM based cascade system for industrial-scale video content moderation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), 2025
work page 2025
-
[24]
Zhenhao Zhu, Yue Liu, Yanpei Guo, Wenjie Qu, Cancan Chen, Yufei He, Yibo Li, Yulin Chen, Tianyi Wu, Huiying Xu, et al. Guardreasoner-omni: A reasoning-based multi-modal guardrail for text, image, and video.arXiv preprint arXiv:2602.03328, 2026
-
[25]
Safewatch: An efficient safety-policy following video guardrail model with transparent explanations
Zhaorun Chen, Francesco Pinto, Minzhou Pan, and Bo Li. Safewatch: An efficient safety-policy following video guardrail model with transparent explanations. InInternational Conference on Learning Representations, volume 2025, pages 76566–76608, 2025
work page 2025
-
[26]
Jiaheng Wei, Zhaowei Zhu, Hao Cheng, Tongliang Liu, Gang Niu, and Yang Liu. Learning with noisy labels revisited: A study using real-world human annotations.arXiv preprint arXiv:2110.12088, 2021
-
[27]
Scaling laws for data filtering–data curation cannot be compute agnostic, 2024.URL https://arxiv
Sachin Goyal, Pratyush Maini, Zachary C Lipton, Aditi Raghunathan, and J Zico Kolter. Scaling laws for data filtering–data curation cannot be compute agnostic, 2024.URL https://arxiv. org/abs/2404.07177
-
[28]
Gaurav Shinde, Anuradha Ravi, Emon Dey, Shadman Sakib, Milind Rampure, and Nirmalya Roy. A survey on efficient vision-language models.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 15(3):e70036, 2025
work page 2025
-
[29]
Boyu Zhu, Xiaofei Wen, Wenjie Jacky Mo, Tinghui Zhu, Yanan Xie, Peng Qi, and Muhao Chen. Omniguard: Unified omni-modal guardrails with deliberate reasoning.arXiv preprint arXiv:2512.02306, 2025
-
[30]
Valerie Thompson.Dual-process theories: A metacognitive perspective, pages 171–196. 01 2009
work page 2009
-
[31]
ThinkGuard: Deliberative slow thinking leads to cautious guardrails
Xiaofei Wen, Wenxuan Zhou, Wenjie Jacky Mo, and Muhao Chen. ThinkGuard: Deliberative slow thinking leads to cautious guardrails. InACL (Findings), 2025. 11
work page 2025
-
[32]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations, 2023.URL https://arxiv. org/abs/2312.06674, 2(6):15, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.Advances in neural information processing systems, 37:8093–8131, 2024
work page 2024
-
[34]
Bingoguard: Llm content moderation tools with risk levels.arXiv preprint arXiv:2503.06550, 2025
Fan Yin, Philippe Laban, Xiangyu Peng, Yilun Zhou, Yixin Mao, Vaibhav Vats, Linnea Ross, Divyansh Agarwal, Caiming Xiong, and Chien-Sheng Wu. Bingoguard: Llm content moderation tools with risk levels.arXiv preprint arXiv:2503.06550, 2025
-
[35]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harkous, Karthik Narasimhan, Drew Proud, Piyush Kumar, Bhaktipriya Radharapu, et al. Shieldgemma: Genera- tive ai content moderation based on gemma, 2024.URL https://arxiv. org/abs/2407.21772
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Jonathan St.B.T. Evans. In two minds: dual-process accounts of reasoning.Trends in Cognitive Sciences, 7(10):454–459, 2003
work page 2003
-
[37]
Thinking, fast and slow.Farrar, Straus and Giroux, 2011
Daniel Kahneman. Thinking, fast and slow.Farrar, Straus and Giroux, 2011
work page 2011
-
[38]
Bill Yuchen Lin, Yicheng Fu, Karina Yang, Faeze Brahman, Shiyu Huang, Chandra Bhagavatula, Prithviraj Ammanabrolu, Yejin Choi, and Xiang Ren. Swiftsage: A generative agent with fast and slow thinking for complex interactive tasks.Advances in Neural Information Processing Systems, 36:23813–23825, 2023
work page 2023
-
[39]
Dynathink: Fast or slow? a dynamic decision-making framework for large language models
Jiabao Pan, Yan Zhang, Chen Zhang, Zuozhu Liu, Hongwei Wang, and Haizhou Li. Dynathink: Fast or slow? a dynamic decision-making framework for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14686– 14695, 2024
work page 2024
-
[40]
Dualformer: Controllable fast and slow thinking by learning with randomized reasoning traces
Andy DiJia Su, Sainbayar Sukhbaatar, Michael Rabbat, Yuandong Tian, and Qinqing Zheng. Dualformer: Controllable fast and slow thinking by learning with randomized reasoning traces. InInternational Conference on Learning Representations, volume 2025, pages 95080–95117, 2025
work page 2025
-
[41]
Fast-slow thinking grpo for large vision-language model reasoning
Wenyi Xiao and Leilei Gan. Fast-slow thinking grpo for large vision-language model reasoning. Advances in Neural Information Processing Systems, 38:171601–171631, 2026
work page 2026
-
[42]
Learning to think fast and slow for visual language models.arXiv preprint arXiv:2511.16670, 2025
Chenyu Lin, Cheng Chi, Jinlin Wu, Sharon Li, and Kaiyang Zhou. Learning to think fast and slow for visual language models.arXiv preprint arXiv:2511.16670, 2025
-
[43]
Kangan Qian, Zhikun Ma, Yangfan He, Ziang Luo, Tianyu Shi, Tianze Zhu, Jiayin Li, Jianhui Wang, Ziyu Chen, Xiao He, et al. Fasionad: Fast and slow fusion thinking systems for human- like autonomous driving with adaptive feedback.arXiv preprint arXiv:2411.18013, 2024
-
[44]
Alex Havrilla and Maia Iyer. Understanding the effect of noise in llm training data with algorithmic chains of thought.arXiv preprint arXiv:2402.04004, 2024
-
[45]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational conference on machine learning, pages 1885–1894. PMLR, 2017
work page 2017
-
[46]
LayerIF: Estimating Layer Quality for Large Language Models using Influence Functions
Hadi Askari, Shivanshu Gupta, Fei Wang, Anshuman Chhabra, and Muhao Chen. LayerIF: Estimating Layer Quality for Large Language Models using Influence Functions. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[47]
Datainf: Efficiently estimating data influence in lora-tuned llms and diffusion models
Yongchan Kwon, Eric Wu, Kevin Wu, and James Y Zou. Datainf: Efficiently estimating data influence in lora-tuned llms and diffusion models. InInternational Conference on Learning Representations, volume 2024, pages 21921–21942, 2024
work page 2024
-
[48]
Anshuman Chhabra, Peizhao Li, Prasant Mohapatra, and Hongfu Liu. What Data Benefits My Classifier? Enhancing Model Performance and Interpretability through Influence-Based Data Selection. InInternational Conference on Learning Representations, 2024. 12
work page 2024
-
[49]
Influence functions for efficient data selection in reasoning.arXiv preprint arXiv:2510.06108, 2025
Prateek Humane, Paolo Cudrano, Daniel Z Kaplan, Matteo Matteucci, Supriyo Chakraborty, and Irina Rish. Influence functions for efficient data selection in reasoning.arXiv preprint arXiv:2510.06108, 2025
-
[50]
Qirun Dai, Dylan Zhang, Jiaqi W. Ma, and Hao Peng. Improving influence-based instruction tuning data selection for balanced learning of diverse capabilities. InEMNLP (Findings), 2025
work page 2025
-
[51]
Dmytro Vitel and Anshuman Chhabra. First is Not Really Better Than Last: Evaluating Layer Choice and Aggregation Strategies in Language Model Data Influence Estimation. In International Conference on Learning Representations, 2026
work page 2026
-
[52]
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent.Advances in Neural Information Processing Systems, 33:19920–19930, 2020
work page 2020
-
[53]
Anshuman Chhabra, Bo Li, Jian Chen, Prasant Mohapatra, and Hongfu Liu. Outlier Gradient Analysis: Efficiently Identifying Detrimental Training Samples for Deep Learning Models. In International Conference on Machine Learning, 2025
work page 2025
-
[54]
Kartik Sharma, Yiqiao Jin, Rakshit Trivedi, and Srijan Kumar. Efficient knowledge probing of large language models by adapting pre-trained embeddings.arXiv preprint arXiv:2508.06030, 2025
-
[55]
Building production-ready probes for gemini.arXiv preprint arXiv:2601.11516, 2026
János Kramár, Joshua Engels, Zheng Wang, Bilal Chughtai, Rohin Shah, Neel Nanda, and Arthur Conmy. Building production-ready probes for gemini.arXiv preprint arXiv:2601.11516, 2026
-
[56]
Training data influence analysis and estimation: a survey
Zayd Hammoudeh and Daniel Lowd. Training data influence analysis and estimation: a survey. Machine Learning, 113(5):2351–2403, March 2024
work page 2024
-
[57]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024.URL https://arxiv. org/abs/2408.03314, 20, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InEMNLP, 2025
work page 2025
-
[59]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[60]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
work page 2022
-
[61]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Mul- timodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
work page 2026
-
[65]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Florence-2: Advancing a unified representation for a variety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4818–4829, June 2024
work page 2024
-
[68]
Lfm2 technical report.arXiv preprint arXiv:2511.23404, 2025
Liquid AI. Lfm2 technical report.arXiv preprint arXiv:2511.23404, 2025
-
[69]
Orion LLM Labs. GRM-2.5-Air. https://huggingface.co/OrionLLM/GRM-2.5-Air, 2026. 14 Appendix A Limitations SAFELENSdemonstrates strong performance and efficiency across benchmarks, but there are some limitations. Runtime depends on hardware, inference stack, and implementation details. While our results are based on B200 GPUs (using the HuggingFace inferen...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.