AdaptiveLoad: Towards Efficient Video Diffusion Transformer Training
Pith reviewed 2026-05-20 00:57 UTC · model grok-4.3
The pith
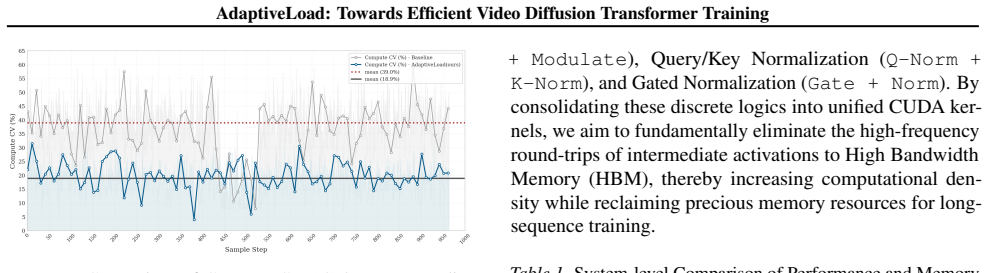
AdaptiveLoad reduces computational imbalance in video diffusion transformer training from 39% to 18.9% using dual constraints and a fused kernel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdaptiveLoad consists of a dual-constraint adaptive load balancing system that applies B × S^p ≤ M_comp to limit memory consumption and computational load simultaneously, eliminating long-sequence bottlenecks, and a fused LayerNorm-Modulate CUDA kernel that uses D-tile coalesced reduction to increase throughput and reduce memory pressure. On the Wan 2.1 world model this yields a drop in computational imbalance rate from 39% to 18.9%, a 22.7% improvement in peak VRAM utilization efficiency, and a 27.2% rise in overall training throughput.
What carries the argument
The dual-constraint load balancing formula B × S^p ≤ M_comp that enforces balance on both memory and compute, together with the fused LayerNorm-Modulate CUDA kernel for accelerated execution.
If this is right
- GPU resources are utilized more evenly across training steps for mixed-length video data.
- Overall training runs complete faster due to the measured 27.2% throughput gain.
- Peak memory usage becomes more predictable and efficient, supporting larger scale experiments.
- Imbalance reduction from 39% to 18.9% translates to fewer idle cycles on multi-GPU setups.
Where Pith is reading between the lines
- This balancing technique could extend to training other variable-length sequence models beyond video diffusion.
- Integrating the fused kernel might offer speedups in related operations like inference as well.
- Testing on different model sizes or hardware configurations would reveal how broadly the gains apply.
Load-bearing premise
The dual constraints and fused kernel improve efficiency without slowing convergence or reducing the quality of the trained model.
What would settle it
Running the same training experiment with and without AdaptiveLoad and comparing both final model performance scores and training time to see if quality stays the same while speed improves.
Figures







read the original abstract
In video generation models, particularly world models, training large-scale video diffusion Transformers (such as DiT and MMDiT) poses significant computational challenges due to the extreme variance in sequence lengths within mixed-mode datasets. Existing bucket-based data loading strategies typically rely on "equal token length" constraints. This approach fails to account for the quadratic complexity of self-attention mechanisms, leading to severe load imbalance and underutilization of GPU resources. This paper proposes \textit{AdaptiveLoad}, an integrated optimization framework consisting of two core components: (1) A dual-constraint adaptive load balancing system, which eliminates long-sequence bottlenecks by simultaneously limiting memory consumption and computational load ($B \times S^p \le M_{\text{comp}}$); (2) A fused LayerNorm-Modulate CUDA kernel, which utilizes a D-tile coalesced reduction strategy to increase throughput and alleviate memory pressure. Experimental results on the Wan 2.1 world model demonstrate that our method reduces the computational imbalance rate from 39\% to 18.9\%, improves peak VRAM utilization efficiency by 22.7\%, and achieves an overall training throughput increase of 27.2\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaptiveLoad, an optimization framework for training video diffusion Transformers (DiT/MMDiT) on mixed-length video datasets. It introduces a dual-constraint load balancer (B × S^p ≤ M_comp) to reduce self-attention compute imbalance and a fused LayerNorm-Modulate CUDA kernel with D-tile coalesced reduction. On the Wan 2.1 world model, the method is reported to lower computational imbalance from 39% to 18.9%, raise peak VRAM utilization efficiency by 22.7%, and boost overall training throughput by 27.2%.
Significance. If the performance gains are shown to preserve model convergence and output quality, the dual-constraint scheduler combined with the fused kernel would constitute a practical systems contribution for efficient large-scale video model training. The approach directly targets quadratic attention costs under variable sequence lengths, which is a recurring bottleneck in distributed video generation workloads.
major comments (2)
- [Abstract / Experimental Results] Abstract and Experimental Results: The headline claims (imbalance rate 39%→18.9%, +22.7% VRAM efficiency, +27.2% throughput) are presented without any description of the experimental protocol, baseline implementations, dataset statistics, number of runs, or error bars. This absence makes the quantitative improvements impossible to evaluate or reproduce.
- [Method / Experimental Results] Method and Experimental Results: The central assumption that the dual-constraint scheduler (B × S^p ≤ M_comp) and fused kernel preserve training dynamics is untested. No loss curves, validation metrics, or downstream quality measures (FID, CLIP-score, etc.) are reported comparing AdaptiveLoad against the equal-token baseline on Wan 2.1. This directly undermines the claim of net efficiency improvement.
minor comments (2)
- [Method] The variables p and M_comp in the dual-constraint equation are introduced without explicit definitions or guidance on how they are chosen in practice.
- [Method] The description of the D-tile coalesced reduction strategy in the fused kernel would benefit from a small diagram or pseudocode to clarify memory access patterns.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments on experimental reporting and validation of training dynamics are well-taken, and we will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results: The headline claims (imbalance rate 39%→18.9%, +22.7% VRAM efficiency, +27.2% throughput) are presented without any description of the experimental protocol, baseline implementations, dataset statistics, number of runs, or error bars. This absence makes the quantitative improvements impossible to evaluate or reproduce.
Authors: We agree that the current presentation lacks sufficient detail for reproducibility. In the revised manuscript we will expand the Experimental Results section with a full description of the protocol, including the equal-token baseline implementation, dataset statistics for the mixed-length videos in the Wan 2.1 training set, the number of independent runs (reported over three runs with standard deviation), and error bars on all headline metrics. revision: yes
-
Referee: [Method / Experimental Results] Method and Experimental Results: The central assumption that the dual-constraint scheduler (B × S^p ≤ M_comp) and fused kernel preserve training dynamics is untested. No loss curves, validation metrics, or downstream quality measures (FID, CLIP-score, etc.) are reported comparing AdaptiveLoad against the equal-token baseline on Wan 2.1. This directly undermines the claim of net efficiency improvement.
Authors: We acknowledge that confirming preservation of training dynamics is necessary to support the net benefit claim. While the submitted manuscript prioritizes systems-level efficiency results, we agree this is a gap. In revision we will add training loss curves and downstream quality metrics (FID, CLIP-score) comparing AdaptiveLoad to the equal-token baseline on Wan 2.1 to demonstrate that convergence and generation quality are maintained. revision: yes
Circularity Check
No circularity: claims rest on empirical measurements of throughput and utilization
full rationale
The paper describes an engineering optimization consisting of a dual-constraint scheduler (B × S^p ≤ M_comp) and a fused CUDA kernel, then reports measured improvements on the Wan 2.1 model (imbalance rate 39%→18.9%, +22.7% VRAM efficiency, +27.2% throughput). No derivation chain, fitted-parameter prediction, or self-citation is invoked to justify the performance numbers; the results are presented as direct experimental outcomes. The central claims therefore remain independent of any self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- exponent p
- threshold M_comp
axioms (1)
- domain assumption Quadratic complexity of self-attention is the dominant source of load imbalance in mixed-length video data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-constraint adaptive load balancing system... B×S^p ≤ M_comp... fused LayerNorm-Modulate CUDA kernel... D-tile coalesced reduction
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduces the computational imbalance rate from 39% to 18.9%, improves peak VRAM utilization efficiency by 22.7%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the ACM SIGCOMM 2025 Conference , pages=
ByteScale: Communication-Efficient Scaling of LLM Training with a 2048K Context Length on 16384 GPUs , author=. Proceedings of the ACM SIGCOMM 2025 Conference , pages=
work page 2025
-
[2]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[4]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. arXiv preprint arXiv:2307.08691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
Flashattention-3: Fast and accurate attention with asynchrony and low-precision , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Zero: Memory optimizations toward training trillion parameter models , author=. SC20: international conference for high performance computing, networking, storage and analysis , pages=. 2020 , organization=
work page 2020
-
[7]
Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models , author=. arXiv preprint arXiv:2309.14509 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2603.07169 , year=
Making LLMs Optimize Multi-Scenario CUDA Kernels Like Experts , author=. arXiv preprint arXiv:2603.07169 , year=
-
[9]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-lm: Training multi-billion parameter language models using model parallelism , author=. arXiv preprint arXiv:1909.08053 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
TF-TI2I: Training-Free Text-and-Image-to-Image Generation via Multi-Modal Implicit-Context Learning in Text-to-Image Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[12]
Multimodal diffusion transformer: Learning versatile behavior from multimodal goals , author=. arXiv preprint arXiv:2407.05996 , year=
-
[13]
arXiv preprint arXiv:2408.00370 , year=
Dim-gesture: Co-speech gesture generation with adaptive layer normalization mamba-2 framework , author=. arXiv preprint arXiv:2408.00370 , year=
-
[14]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2 , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Text2video-zero: Text-to-image diffusion models are zero-shot video generators , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[17]
Journal of Parallel and Distributed Computing , volume=
Bandwidth optimal all-reduce algorithms for clusters of workstations , author=. Journal of Parallel and Distributed Computing , volume=. 2009 , publisher=
work page 2009
-
[18]
International Conference on Computer Aided Verification , pages=
Rigorous roundoff error analysis of probabilistic floating-point computations , author=. International Conference on Computer Aided Verification , pages=. 2021 , organization=
work page 2021
-
[19]
Nemotron-CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training , author=. arXiv preprint arXiv:2504.13161 , year=
-
[20]
MegaScale-Data: Scaling Dataloader for Multisource Large Foundation Model Training , author=. 2026 , eprint=
work page 2026
-
[21]
arXiv preprint arXiv:2507.10069 , year=
Elasticmm: Efficient multimodal llms serving with elastic multimodal parallelism , author=. arXiv preprint arXiv:2507.10069 , year=
-
[22]
21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , pages=
\ DISTMM \ : Accelerating distributed multimodal model training , author=. 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , pages=
-
[23]
Proceedings of the ACM SIGCOMM 2025 Conference , pages=
Disttrain: Addressing model and data heterogeneity with disaggregated training for multimodal large language models , author=. Proceedings of the ACM SIGCOMM 2025 Conference , pages=
work page 2025
-
[24]
Ai and memory wall , author=. IEEE Micro , volume=. 2024 , publisher=
work page 2024
-
[25]
RL-VLA$^3$: A Flexible and Asynchronous Reinforcement Learning Framework for VLA Training
RL-VLA 3: Reinforcement Learning VLA Accelerating via Full Asynchronism , author=. arXiv preprint arXiv:2602.05765 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [26]
-
[27]
arXiv preprint arXiv:2002.11054 , year=
MLIR: A compiler infrastructure for the end of Moore's law , author=. arXiv preprint arXiv:2002.11054 , year=
-
[28]
Linear Attention for Efficient Bidirectional Sequence Modeling , author=. 2025 , eprint=
work page 2025
-
[29]
From S4 to Mamba: A Comprehensive Survey on Structured State Space Models , author=. 2025 , eprint=
work page 2025
-
[30]
Advances in neural information processing systems , volume=
Large scale distributed deep networks , author=. Advances in neural information processing systems , volume=
-
[31]
Advances in neural information processing systems , volume=
Gpipe: Efficient training of giant neural networks using pipeline parallelism , author=. Advances in neural information processing systems , volume=
-
[32]
Usp: A unified sequence parallelism approach for long context generative ai
Usp: A unified sequence parallelism approach for long context generative ai , author=. arXiv preprint arXiv:2405.07719 , year=
-
[33]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
- [34]
-
[35]
Proceedings of the SIGGRAPH Asia 2025 Posters , pages=
PolyArt: Customizable Multilingual Movie Poster Generation via Diffusion Transformer , author=. Proceedings of the SIGGRAPH Asia 2025 Posters , pages=
work page 2025
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
EmoVid: A Multimodal Emotion Video Dataset for Emotion-Centric Video Understanding and Generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
arXiv preprint arXiv:2506.01466 , year=
Towards Scalable Video Anomaly Retrieval: A Synthetic Video-Text Benchmark , author=. arXiv preprint arXiv:2506.01466 , year=
-
[38]
arXiv preprint arXiv:2512.24165 , year=
Diffthinker: Towards generative multimodal reasoning with diffusion models , author=. arXiv preprint arXiv:2512.24165 , year=
- [39]
-
[40]
Kling-Omni Technical Report , author=. arXiv preprint arXiv:2512.16776 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Scalable Training of Mixture-of-Experts Models with Megatron Core , author=. 2026 , eprint=
work page 2026
-
[42]
ACM SIGARCH computer architecture news , volume=
Hitting the memory wall: Implications of the obvious , author=. ACM SIGARCH computer architecture news , volume=. 1995 , publisher=
work page 1995
-
[43]
Nvidia developer technology , volume=
Optimizing parallel reduction in CUDA , author=. Nvidia developer technology , volume=. 2007 , publisher=
work page 2007
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.