BLAgent: Agentic RAG for File-Level Bug Localization
Pith reviewed 2026-05-20 09:27 UTC · model grok-4.3
The pith
BLAgent's agentic RAG localizes bugs to the right file at over 78% top-1 accuracy using open-source models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
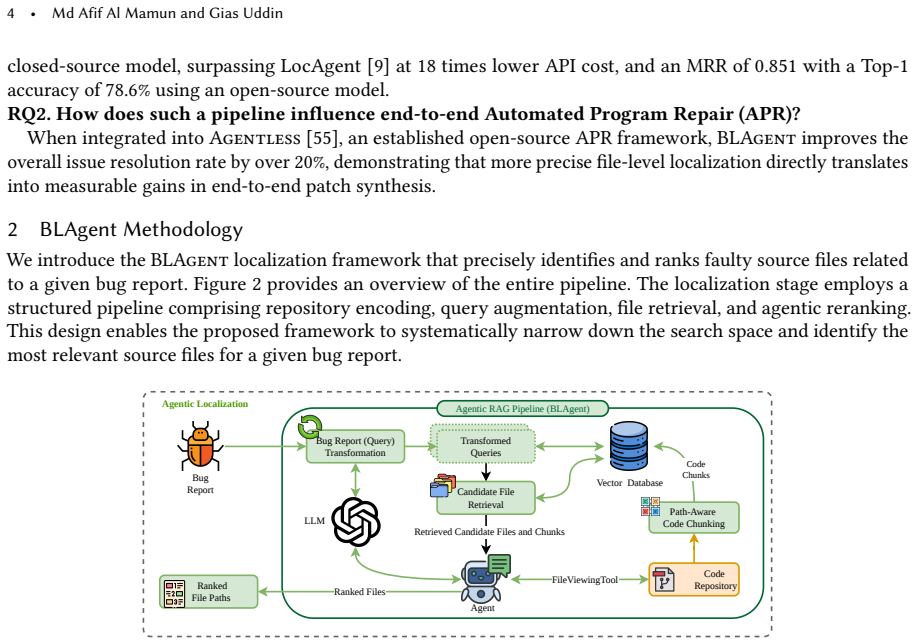
BLAgent integrates code structure-aware repository encoding with path-augmented AST-based chunking, dual-perspective query transformation capturing both structural and behavioral signals, and two-phase agentic reranking combining symbolic inspection with evidence-grounded reasoning to perform accurate file-level bug localization over a compact candidate set.
What carries the argument
The agentic RAG framework with path-augmented AST chunking for repository encoding, dual-perspective query transformation, and two-phase symbolic-plus-reasoning reranking that balances accuracy and cost through bounded reasoning.
If this is right
- BLAgent reaches over 78% top-1 accuracy with open-source models on SWE-bench Lite.
- Accuracy exceeds 86% when a closed-source model is used instead.
- The method runs more than 18 times cheaper than the strongest baseline that uses the same model.
- Plugging BLAgent into an automated program repair pipeline raises the final repair success rate by over 20%.
Where Pith is reading between the lines
- The same bounded-reasoning pattern could reduce wasted context in other code-search tasks such as finding functions to edit during refactoring.
- Cost reductions of this size might let teams run file-level checks on every commit rather than only on reported bugs.
- If the dual-perspective rewrite proves robust, it could be reused as a lightweight add-on for any retrieval system that needs both static and dynamic cues.
Load-bearing premise
The three components of path-augmented AST chunking, dual-perspective query transformation, and two-phase reranking together produce accurate reasoning over a compact set of files that works across benchmarks and models.
What would settle it
Accuracy falling well below 50 percent top-1 on a fresh set of bug reports from different repositories or languages would show the components do not deliver the claimed bounded accuracy.
Figures













read the original abstract
Bug localization remains a key bottleneck in downstream software maintenance tasks, including root cause analysis, triage, and automated program repair (APR), despite recent advances in large language model (LLM)-based repair systems. File-level bug localization is especially critical in hierarchical pipelines, where errors can propagate to downstream stages such as statement-level localization or patch generation. While Retrieval-Augmented Generation (RAG) offers a promising direction for grounding LLMs in repository context, existing RAG pipelines rely on static retrieval and lack the reasoning needed to identify faulty code accurately. In this work, we present BLAgent, a novel agentic RAG framework for file-level bug localization that integrates three key ideas: (i) code structure-aware repository encoding with path-augmented AST-based chunking, (ii) dual-perspective query transformation capturing both structural and behavioral signals, and (iii) two-phase agentic reranking combining symbolic inspection with evidence-grounded reasoning. Unlike prior graph-based or multi-hop agentic approaches, BLAgent performs bounded reasoning over a compact candidate set, balancing accuracy and cost. On SWE-bench Lite, BLAgent attains over 78% Top-1 accuracy with open-source models and over 86% with a closed-source model, while being over 18x cheaper than the strongest baseline using the same model. When integrated into an APR framework, it improves end-to-end repair success by over 20%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BLAgent, an agentic RAG framework for file-level bug localization in software repositories. It proposes three components: (i) path-augmented AST-based chunking for code structure-aware encoding, (ii) dual-perspective query transformation for structural and behavioral signals, and (iii) two-phase agentic reranking with symbolic inspection and evidence-grounded reasoning. The central empirical claims are that BLAgent achieves over 78% Top-1 accuracy on SWE-bench Lite using open-source models and over 86% with closed-source models, is more than 18x cheaper than the strongest baseline with the same model, and yields over 20% improvement in end-to-end repair success when integrated into an APR pipeline.
Significance. If the reported performance gains and cost reductions are shown to be robust and attributable to the proposed mechanisms, the work would represent a meaningful advance in repository-scale bug localization. It could improve the reliability of hierarchical software maintenance pipelines and APR systems by providing a more accurate and efficient way to ground LLMs in repository context without unbounded reasoning costs.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Evaluation): The manuscript reports strong Top-1 accuracy, cost reduction, and APR improvement figures but provides no ablation studies that isolate the individual contributions of path-augmented AST chunking, dual-perspective query transformation, and two-phase reranking. Without these results it is impossible to determine whether the claimed gains are caused by the agentic RAG design or by properties of the base models, prompt engineering, or the SWE-bench Lite bug distribution.
- [§4.1] §4.1 (Baselines and Metrics): The abstract states that BLAgent is over 18x cheaper than the strongest baseline using the same model, yet the paper supplies no description of the baseline systems, their retrieval mechanisms, or the exact cost metric (token usage, API calls, or wall-clock time). This omission prevents verification of the cost claim and its load-bearing role in the central argument.
- [§4.3] §4.3 (Generalization): No results are presented on repositories or benchmarks outside SWE-bench Lite. The claim that the three components produce bounded, accurate reasoning over a compact candidate set therefore rests on a single benchmark whose bug distribution may not be representative, weakening the assertion that the framework generalizes.
minor comments (2)
- [Abstract] The abstract and introduction use the term 'bounded reasoning' without a precise definition or complexity bound; a short paragraph clarifying what 'bounded' means in terms of candidate set size or reasoning steps would improve clarity.
- [Figures and Tables] Figure captions and table headers should explicitly state the models (open-source vs. closed-source) and the exact Top-1 accuracy numbers rather than relying on the prose description.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment point by point below, indicating where we will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] The manuscript reports strong Top-1 accuracy, cost reduction, and APR improvement figures but provides no ablation studies that isolate the individual contributions of path-augmented AST chunking, dual-perspective query transformation, and two-phase reranking. Without these results it is impossible to determine whether the claimed gains are caused by the agentic RAG design or by properties of the base models, prompt engineering, or the SWE-bench Lite bug distribution.
Authors: We agree that explicit ablation studies are required to attribute performance gains to the proposed mechanisms. In the revised manuscript we will add a new subsection in §4 that reports results after systematically ablating each component in turn (path-augmented AST chunking, dual-perspective query transformation, and two-phase reranking) while keeping all other factors fixed. These experiments will quantify the contribution of each element to Top-1 accuracy and cost. revision: yes
-
Referee: [§4.1] The abstract states that BLAgent is over 18x cheaper than the strongest baseline using the same model, yet the paper supplies no description of the baseline systems, their retrieval mechanisms, or the exact cost metric (token usage, API calls, or wall-clock time). This omission prevents verification of the cost claim and its load-bearing role in the central argument.
Authors: We accept that the current description of baselines and cost measurement is insufficient. We will expand §4.1 with full specifications of every baseline, including their retrieval strategies and implementation details, and will state explicitly that cost is measured as total input plus output tokens across all LLM calls (retrieval and generation) using the same model for fair comparison. This will allow direct verification of the 18x reduction. revision: yes
-
Referee: [§4.3] No results are presented on repositories or benchmarks outside SWE-bench Lite. The claim that the three components produce bounded, accurate reasoning over a compact candidate set therefore rests on a single benchmark whose bug distribution may not be representative, weakening the assertion that the framework generalizes.
Authors: SWE-bench Lite is the current standard benchmark for repository-level bug localization because it consists of real GitHub issues with full repository context. Nevertheless, we acknowledge that results on additional benchmarks would strengthen the generalization argument. In the revision we will add a dedicated paragraph in §4.3 discussing the representativeness of SWE-bench Lite and will include a limitations subsection that explicitly notes the single-benchmark scope and outlines plans for future multi-benchmark evaluation. revision: partial
Circularity Check
No circularity: empirical performance claims on external benchmark
full rationale
The paper presents BLAgent as a novel agentic RAG framework incorporating path-augmented AST chunking, dual-perspective query transformation, and two-phase reranking, then reports empirical results on SWE-bench Lite (over 78% Top-1 with open-source models, over 86% with closed-source, 18x cheaper, and 20% APR improvement). No mathematical derivations, equations, fitted parameters, or self-referential definitions appear in the provided text. The performance figures are tied directly to an external benchmark rather than any internal reduction or self-citation chain, making the central claims self-contained empirical observations without circular structure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can perform reliable symbolic inspection and evidence-grounded reasoning when given compact, well-structured code context.
Reference graph
Works this paper leans on
- [1]
-
[2]
M. Asad, R. M. Yasir, A. Geramirad, and S. Malek. Leveraging large language model for information retrieval-based bug localization. arXiv preprint arXiv:2508.00253, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
N. Bettenburg, S. Just, A. Schröter, C. Weiss, R. Premraj, and T. Zimmermann. What makes a good bug report? InProceedings of the 16th ACM SIGSOFT International Symposium on Foundations of software engineering, pages 308–318, 2008
work page 2008
- [4]
-
[5]
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
I. Bouzenia, P. Devanbu, and M. Pradel. Repairagent: An autonomous, llm-based agent for program repair.arXiv preprint arXiv:2403.17134, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [6]
- [7]
-
[8]
A. R. Chen, T.-H. Chen, and S. Wang. Pathidea: Improving information retrieval-based bug localization by re-constructing execution paths using logs.IEEE Transactions on Software Engineering, 48(8):2905–2919, 2021
work page 2021
-
[9]
Z. Chen, R. Tang, G. Deng, F. Wu, J. Wu, Z. Jiang, V. Prasanna, A. Cohan, and X. Wang. Locagent: Graph-guided llm agents for code localization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8697–8727, 2025
work page 2025
-
[10]
Z. Fan, X. Gao, M. Mirchev, A. Roychoudhury, and S. H. Tan. Automated repair of programs from large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1469–1481. IEEE, 2023
work page 2023
-
[11]
T. Guo, X. Chen, Y. Wang, R. Chang, S. Pei, N. V. Chawla, O. Wiest, and X. Zhang. Large language model based multi-agents: A survey of progress and challenges.arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025. , Vol. 1, No. 1, Article . Publication date: May 2026. BLAgent: Agentic RAG for File-Level Bug Loca...
work page 2025
-
[13]
Understanding the planning of LLM agents: A survey
X. Huang, W. Liu, X. Chen, X. Wang, H. Wang, D. Lian, Y. Wang, R. Tang, and E. Chen. Understanding the planning of llm agents: A survey.arXiv preprint arXiv:2402.02716, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
-
[15]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[16]
J. A. Jones, M. J. Harrold, and J. Stasko. Visualization of test information to assist fault localization. InProceedings of the 24th international conference on Software engineering, pages 467–477, 2002
work page 2002
- [17]
-
[18]
R. Just, D. Jalali, and M. D. Ernst. Defects4j: a database of existing faults to enable controlled testing studies for java programs. In Proceedings of the 2014 International Symposium on Software Testing and Analysis, ISSTA 2014, page 437–440, New York, NY, USA, 2014. Association for Computing Machinery
work page 2014
-
[19]
S. Kang, G. An, and S. Yoo. A quantitative and qualitative evaluation of llm-based explainable fault localization.Proceedings of the ACM on Software Engineering, 1(FSE):1424–1446, 2024
work page 2024
-
[20]
A. N. Lam, A. T. Nguyen, H. A. Nguyen, and T. N. Nguyen. Bug localization with combination of deep learning and information retrieval. In2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC), pages 218–229. IEEE, 2017
work page 2017
-
[21]
X. B. D. Le, D. Lo, and C. Le Goues. History driven program repair. In2016 IEEE 23rd international conference on software analysis, evolution, and reengineering (SANER), volume 1, pages 213–224. IEEE, 2016
work page 2016
- [22]
-
[23]
F. Li, J. Jiang, J. Sun, and H. Zhang. Hybrid automated program repair by combining large language models and program analysis.ACM Transactions on Software Engineering and Methodology, 34(7):1–28, 2025
work page 2025
-
[24]
X. Li, W. Li, Y. Zhang, and L. Zhang. Deepfl: Integrating multiple fault diagnosis dimensions for deep fault localization. InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis, pages 169–180, 2019
work page 2019
- [25]
- [26]
-
[27]
K. Liu, A. Koyuncu, D. Kim, and T. F. Bissyandé. Tbar: Revisiting template-based automated program repair. InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis, pages 31–42, 2019
work page 2019
-
[28]
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [29]
-
[30]
X. Ma, Y. Gong, P. He, N. Duan, et al. Query rewriting in retrieval-augmented large language models. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[31]
Y. Ma, Q. Yang, R. Cao, B. Li, F. Huang, and Y. Li. Alibaba lingmaagent: Improving automated issue resolution via comprehensive repository exploration. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, pages 238–249, 2025
work page 2025
-
[32]
Z. Ma, A. R. Chen, D. J. Kim, T.-H. Chen, and S. Wang. Llmparser: An exploratory study on using large language models for log parsing. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
work page 2024
-
[33]
R. Macháček, A. Grishina, M. Hort, and L. Moonen. The impact of fine-tuning large language models on automated program repair. arXiv preprint arXiv:2507.19909, 2025
-
[34]
Y. A. Malkov and D. A. Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence, 42(4):824–836, 2018
work page 2018
-
[35]
X. Meng, X. Wang, H. Zhang, H. Sun, and X. Liu. Improving fault localization and program repair with deep semantic features and transferred knowledge. InProceedings of the 44th International Conference on Software Engineering, pages 1169–1180, 2022
work page 2022
-
[36]
F. Niu, C. Li, K. Liu, X. Xia, and D. Lo. When deep learning meets information retrieval-based bug localization: A survey.ACM Computing Surveys, 57(11):1–41, 2025
work page 2025
- [37]
- [38]
-
[39]
R. Qu, R. Tu, and F. Bao. Is semantic chunking worth the computational cost? InFindings of the Association for Computational Linguistics: NAACL 2025, pages 2155–2177, 2025
work page 2025
-
[40]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[41]
R. K. Saha, M. Lease, S. Khurshid, and D. E. Perry. Improving bug localization using structured information retrieval. In2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 345–355. IEEE, 2013
work page 2013
- [42]
-
[43]
K. Sawarkar, A. Mangal, and S. R. Solanki. Blended rag: Improving rag (retriever-augmented generation) accuracy with semantic search and hybrid query-based retrievers. In2024 IEEE 7th international conference on multimedia information processing and retrieval (MIPR), pages 155–161. IEEE, 2024
work page 2024
-
[44]
S. Shao and T. Yu. Enhancing ir-based fault localization using large language models.arXiv preprint arXiv:2412.03754, 2024
-
[45]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
The developer coefficient: Software engineering efficiency and its $3 trillion impact on global GDP
Stripe. The developer coefficient: Software engineering efficiency and its $3 trillion impact on global GDP. https://stripe.com/files/ reports/the-developer-coefficient.pdf, Sept. 2018. Accessed: 2026-03-24
work page 2018
-
[47]
Y. Tao, Y. Qin, and Y. Liu. Retrieval-augmented code generation: A survey with focus on repository-level approaches.arXiv preprint arXiv:2510.04905, 2025
work page internal anchor Pith review arXiv 2025
-
[48]
Q. Wang, C. Parnin, and A. Orso. Evaluating the usefulness of ir-based fault localization techniques. InProceedings of the 2015 international symposium on software testing and analysis, pages 1–11, 2015
work page 2015
-
[49]
S. Wang and D. Lo. Version history, similar report, and structure: Putting them together for improved bug localization. InProceedings of the 22nd international conference on program comprehension, pages 53–63, 2014
work page 2014
-
[50]
X. Wang, B. Li, Y. Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y. Song, B. Li, J. Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
W. E. Wong, V. Debroy, R. Gao, and Y. Li. The dstar method for effective software fault localization.IEEE Transactions on Reliability, 63(1):290–308, 2013
work page 2013
-
[52]
W. E. Wong, R. Gao, Y. Li, R. Abreu, and F. Wotawa. A survey on software fault localization.IEEE Transactions on Software Engineering, 42(8):707–740, 2016
work page 2016
-
[53]
W. E. Wong, R. Gao, Y. Li, R. Abreu, F. Wotawa, and D. Li. Software fault localization: An overview of research, techniques, and tools. Handbook of Software Fault Localization: Foundations and Advances, pages 1–117, 2023
work page 2023
- [54]
-
[55]
C. S. Xia, Y. Deng, S. Dunn, and L. Zhang. Demystifying llm-based software engineering agents.Proc. ACM Softw. Eng., 2(FSE), June 2025
work page 2025
-
[56]
C. S. Xia, Y. Wei, and L. Zhang. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1482–1494. IEEE, 2023
work page 2023
- [57]
-
[58]
Y. Xiao, J. Keung, K. E. Bennin, and Q. Mi. Improving bug localization with word embedding and enhanced convolutional neural networks.Information and Software Technology, 105:17–29, 2019
work page 2019
- [59]
-
[60]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[61]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations, 2022
work page 2022
- [62]
- [63]
- [64]
- [65]
- [66]
-
[67]
Z. Zhang, Q. Dai, X. Bo, C. Ma, R. Li, X. Chen, J. Zhu, Z. Dong, and J.-R. Wen. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems, 43(6):1–47, 2025. , Vol. 1, No. 1, Article . Publication date: May 2026. BLAgent: Agentic RAG for File-Level Bug Localization•45
work page 2025
- [68]
- [69]
-
[70]
J. Zhou, H. Zhang, and D. Lo. Where should the bugs be fixed? more accurate information retrieval-based bug localization based on bug reports. In2012 34th International conference on software engineering (ICSE), pages 14–24. IEEE, 2012. , Vol. 1, No. 1, Article . Publication date: May 2026
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.