Not What You Asked For: Typographic Attacks in Household Robot Manipulation
Pith reviewed 2026-05-20 09:22 UTC · model grok-4.3
The pith
Typographic attacks using printed stickers cause household robots to physically grasp and deliver the wrong objects with a 67.8% success rate in simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a controlled evaluation pool of 59 attributable episodes, the attack achieves an overall Attack Success Rate (ASR) of 67.8%, rising to 70.0% among fully successful episodes, under uncontrolled viewing angles and occlusion with no perceptual optimization. Perceptual errors propagate through the persistent 3D semantic map to produce kinetic failures where the robot physically grasps and delivers the wrong object.
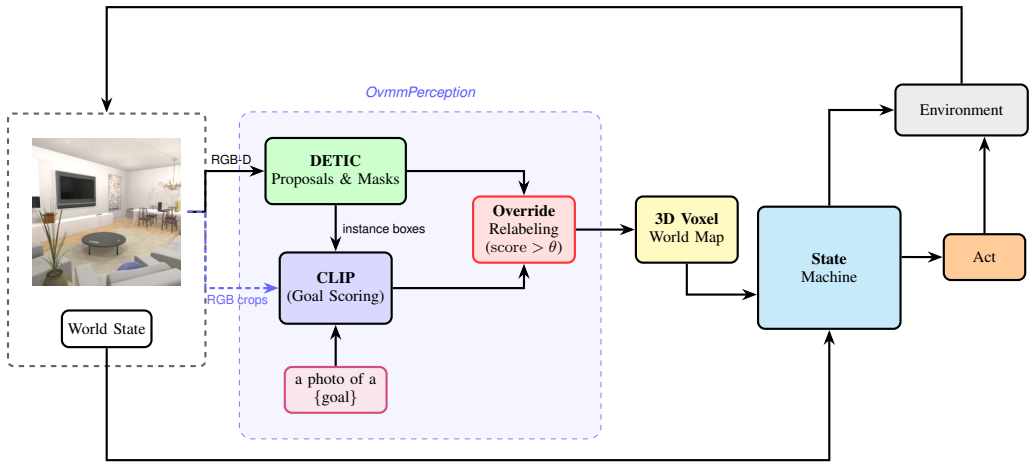
What carries the argument
The decoupled CLIP+DETIC perception architecture that exposes a frozen CLIP encoder to adversarial stickers while maintaining geometric grounding via DETIC.
Load-bearing premise
The Habitat-based HomeRobot simulation with the decoupled CLIP+DETIC perception architecture accurately captures how typographic misclassifications would propagate to physical actions in real modular robot systems.
What would settle it
A physical experiment where a typographic sticker is placed on an object and the robot is observed to grasp a different object matching the text instead.
Figures

read the original abstract
Open-vocabulary embodied AI agents increasingly rely on vision-language models such as CLIP for object perception and task grounding. However, the shared embedding space that enables this flexibility introduces a structural vulnerability to typographic attacks, where printed text in a physical scene semantically overrides visual judgment. While prior work has quantified this threat in static 2D benchmarks and 3D navigation tasks, its impact on the full Sense-Plan-Act pipeline of household robot manipulation remains unexplored. This work evaluates typographic attacks in a Habitat-based simulation using the HomeRobot benchmark. We introduce a decoupled perception architecture that exposes a frozen CLIP encoder to adversarial stickers while maintaining geometric grounding via DETIC. In a controlled evaluation pool of 59 attributable episodes, the attack achieves an overall Attack Success Rate (ASR) of 67.8%, rising to 70.0% among fully successful episodes, under uncontrolled viewing angles and occlusion with no perceptual optimization. Critically, we find that perceptual errors propagate through the persistent 3D semantic map to produce kinetic failures, defined here as physically executed grasping and transport of the wrong object driven by an adversarially poisoned semantic state. In these cases, the robot physically grasps and delivers the wrong object to a target receptacle. These results establish typographic misclassification as a real, measurable, and physically consequential threat to the safety of modular manipulation pipelines that prior typographic attack research has left unexamined.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates typographic attacks on open-vocabulary household robot manipulation in a Habitat-based HomeRobot simulation. It introduces a decoupled perception architecture using a frozen CLIP encoder alongside DETIC for geometric grounding. Over a controlled set of 59 attributable episodes with uncontrolled viewing angles and occlusion, the attack achieves a 67.8% overall Attack Success Rate (rising to 70.0% in fully successful episodes) with no perceptual optimization. Perceptual misclassifications from adversarial text stickers propagate through the persistent 3D semantic map, leading to kinetic failures in which the robot physically grasps and delivers the wrong object.
Significance. If the central empirical findings hold, the work is significant for demonstrating that typographic vulnerabilities in vision-language models can produce physically executed errors in the full Sense-Plan-Act pipeline of modular manipulation systems. The concrete ASR measurements, focus on propagation to kinetic failures, and use of an existing benchmark provide a measurable baseline that prior 2D and navigation-focused typographic attack studies have not addressed. The decoupled architecture isolates the contribution of the frozen CLIP component, which strengthens the mechanistic interpretation.
major comments (2)
- [Evaluation setup and results sections] Evaluation setup and results sections: The headline 67.8% ASR and kinetic-failure propagation claim rest on the assumption that the Habitat HomeRobot simulator with decoupled CLIP+DETIC faithfully reproduces how typographic misclassifications affect real modular robot systems. No ablations or sensitivity analysis are reported for simulator-specific factors such as depth noise, variable illumination on printed stickers, or partial occlusions from robot motion, leaving the least-secured step of the pipeline under-supported.
- [Results on kinetic failures] Results on kinetic failures: The manuscript defines kinetic failures as physically executed wrong-object grasps and transports driven by poisoned semantic state, yet provides no comparison against integrated (non-decoupled) perception stacks or real-robot validation. This comparison is load-bearing for the claim that the observed failures are representative of deployed modular systems rather than an artifact of the chosen simulation architecture.
minor comments (2)
- [Abstract] The abstract states the attack succeeds 'with no perceptual optimization,' but the main text should explicitly confirm whether any attack generation or sticker placement heuristics were used beyond random or fixed placement.
- [Figures and evaluation description] Figure captions and the episode-selection description would benefit from a brief statement of how 'attributable episodes' were filtered to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important considerations regarding the scope of our simulation-based evaluation, and we address each point below while clarifying the design choices and limitations of the current study.
read point-by-point responses
-
Referee: [Evaluation setup and results sections] Evaluation setup and results sections: The headline 67.8% ASR and kinetic-failure propagation claim rest on the assumption that the Habitat HomeRobot simulator with decoupled CLIP+DETIC faithfully reproduces how typographic misclassifications affect real modular robot systems. No ablations or sensitivity analysis are reported for simulator-specific factors such as depth noise, variable illumination on printed stickers, or partial occlusions from robot motion, leaving the least-secured step of the pipeline under-supported.
Authors: We agree that further sensitivity analysis on simulator-specific factors would strengthen the presentation. In the revised manuscript we will add ablations that vary depth noise levels and occlusion parameters within the Habitat simulator, reporting the resulting impact on ASR to demonstrate stability of the attack propagation. The HomeRobot benchmark already incorporates variable lighting and motion-induced occlusions; we will expand the results section with explicit discussion of these modeled factors and their relation to the observed kinetic failures. revision: yes
-
Referee: [Results on kinetic failures] Results on kinetic failures: The manuscript defines kinetic failures as physically executed wrong-object grasps and transports driven by poisoned semantic state, yet provides no comparison against integrated (non-decoupled) perception stacks or real-robot validation. This comparison is load-bearing for the claim that the observed failures are representative of deployed modular systems rather than an artifact of the chosen simulation architecture.
Authors: The decoupled CLIP+DETIC architecture was deliberately selected to isolate the contribution of the frozen vision-language model, thereby providing a direct mechanistic account of how typographic misclassifications in the semantic map lead to kinetic failures. Adding comparisons to integrated perception stacks would require re-implementing and re-evaluating alternative pipelines on the same episode set, which lies outside the scope of the present work. Real-robot validation is an important direction for future research but is not addressed by the current simulation study, which instead supplies a controlled baseline using an established benchmark. revision: no
- Real-robot validation of typographic attacks under physical lighting and sticker conditions
- Direct empirical comparisons against non-decoupled integrated perception stacks on the identical evaluation episodes
Circularity Check
Empirical measurement of attack success in simulation
full rationale
The paper reports direct experimental results from running a fixed number of episodes in the Habitat HomeRobot simulator with a decoupled CLIP+DETIC perception stack. The central numbers (67.8% ASR over 59 episodes, 70.0% among fully successful episodes, and the occurrence of kinetic failures) are obtained by counting observable outcomes under the stated conditions. No equations, fitted parameters presented as predictions, self-referential definitions, or load-bearing self-citations appear in the derivation chain. The evaluation is therefore self-contained empirical data collection rather than a derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Habitat simulation with HomeRobot benchmark and DETIC geometric grounding sufficiently models real-world perceptual and action propagation under typographic attacks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a decoupled perception architecture that exposes a frozen CLIP encoder to adversarial stickers while maintaining geometric grounding via DETIC... perceptual errors propagate through the persistent 3D semantic map to produce kinetic failures
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the attack achieves an overall Attack Success Rate (ASR) of 67.8%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Visual Genome: Connecting language and vision using crowdsourced dense image annotations,
R. Krishna et al., “Visual Genome: Connecting language and vision using crowdsourced dense image annotations,”Int. J. Comput. Vis., vol. 123, no. 1, pp. 32–73, 2017
work page 2017
-
[2]
Learning transferable visual models from natural language supervision,
A. Radford et al., “Learning transferable visual models from natural language supervision,” inProc. ICML, 2021
work page 2021
-
[3]
Simple but effective: CLIP embeddings for embodied AI,
A. Khandelwal, L. Weihs, R. Mottaghi, and A. Kembhavi, “Simple but effective: CLIP embeddings for embodied AI,” inProc. CVPR, 2022, pp. 14809–14818
work page 2022
-
[4]
TidyBot: Personalized robot assistance with large language models,
J. Wu et al., “TidyBot: Personalized robot assistance with large language models,”Autonomous Robots, 2023
work page 2023
-
[5]
CLIPort: What and where pathways for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “CLIPort: What and where pathways for robotic manipulation,” inProc. CoRL, 2021
work page 2021
-
[6]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim et al., “OpenVLA: An open-source vision-language-action model,” arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Sigmoid loss for language image pre-training,
X. Zhai et al., “Sigmoid loss for language image pre-training,” inProc. ICCV, 2023
work page 2023
-
[8]
SCAM: A real-world typographic robustness evaluation for multimodal foundation models,
J. Westerhoff et al., “SCAM: A real-world typographic robustness evaluation for multimodal foundation models,” arXiv:2504.04893, 2025
-
[9]
Dyslexify: A mechanistic defense against typographic attacks in CLIP,
L. Hufe et al., “Dyslexify: A mechanistic defense against typographic attacks in CLIP,” arXiv preprint, 2025
work page 2025
-
[10]
Multimodal neurons in artificial neural networks,
G. Goh et al., “Multimodal neurons in artificial neural networks,”Distill,
-
[11]
Available: https://distill.pub/2021/multimodal-neurons
[Online]. Available: https://distill.pub/2021/multimodal-neurons
work page 2021
-
[12]
Y . Cao et al., “SceneTAP: Scene-coherent typographic adversarial planner against vision-language models in real-world environments,” arXiv:2412.00114, 2024
-
[13]
Habitat: A platform for embodied AI research,
M. Savva et al., “Habitat: A platform for embodied AI research,” in Proc. ICCV, 2019
work page 2019
-
[14]
RoboTHOR: An open simulation-to-real embodied AI platform,
M. Deitke et al., “RoboTHOR: An open simulation-to-real embodied AI platform,” inProc. CVPR, 2020
work page 2020
-
[15]
HomeRobot: Open-vocabulary mobile manipu- lation,
A. Yenamandra et al., “HomeRobot: Open-vocabulary mobile manipu- lation,” inProc. CoRL, 2023
work page 2023
-
[16]
RT-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich et al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,” inProc. CoRL, 2023
work page 2023
-
[17]
Exploring the adversarial vulnerabilities of vision- language-action models in robotics,
T. Wang et al., “Exploring the adversarial vulnerabilities of vision- language-action models in robotics,” inProc. ICCV, 2025
work page 2025
-
[18]
Tex3D: Objects as attack surfaces via adversarial 3D textures for vision-language-action models,
J. Chen et al., “Tex3D: Objects as attack surfaces via adversarial 3D textures for vision-language-action models,” arXiv:2604.01618, 2025
-
[19]
Freezevla: Action-freezing attacks against vision- language-action models,
X. Wang et al., “FreezeVLA: Action-freezing attacks against vision- language-action models,” arXiv:2509.19870, 2025
-
[20]
CHAI: Command hijacking against embodied AI,
L. Burbano et al., “CHAI: Command hijacking against embodied AI,” inProc. IEEE SaTML, 2026
work page 2026
-
[21]
Robot collapse: Supply chain backdoor attacks against VLM-based robotic manipulation,
X. Wang et al., “Robot collapse: Supply chain backdoor attacks against VLM-based robotic manipulation,” arXiv:2411.11683, 2024
-
[22]
LoRATK: LoRA once, backdoor everywhere in the share- and-play ecosystem,
H. Liu et al., “LoRATK: LoRA once, backdoor everywhere in the share- and-play ecosystem,” inProc. EMNLP Findings, 2025
work page 2025
-
[23]
Defense-Prefix for preventing typographic attacks on CLIP,
H. Azuma and Y . Matsui, “Defense-Prefix for preventing typographic attacks on CLIP,” inProc. ICCVW, 2023, pp. 3646–3655
work page 2023
-
[24]
Detecting twenty-thousand classes using image-level supervision,
X. Zhou et al., “Detecting twenty-thousand classes using image-level supervision,” inProc. ECCV, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.