Semantic Generative Tuning for Unified Multimodal Models
Pith reviewed 2026-05-20 11:28 UTC · model grok-4.3
The pith
Image segmentation as a generative proxy aligns understanding and generation in unified multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
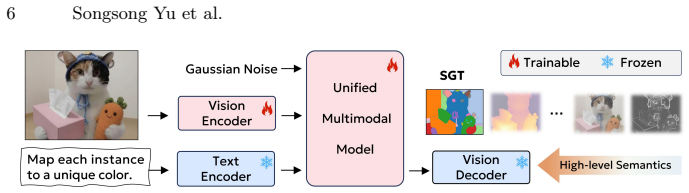
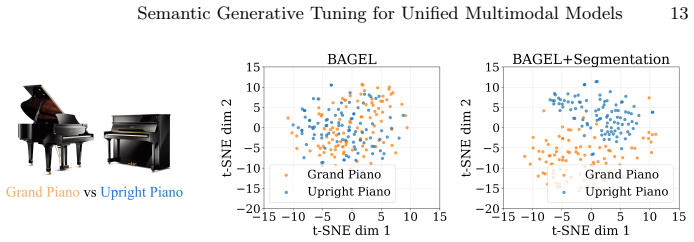
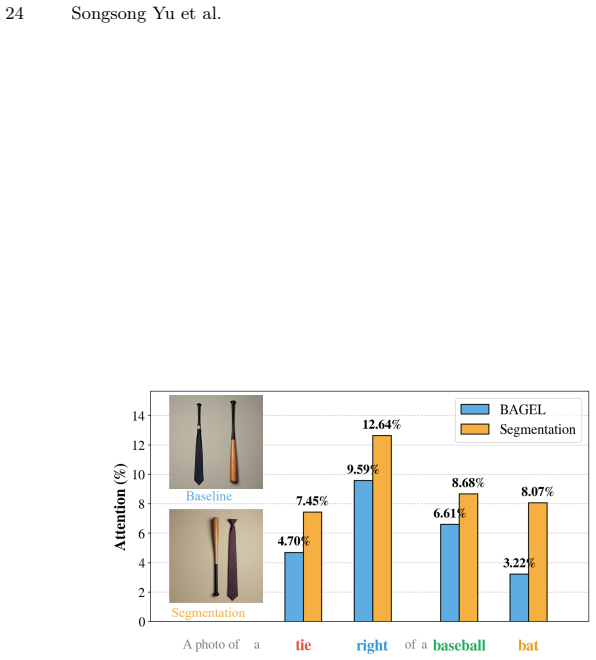
High-level semantic tasks, particularly image segmentation, serve as optimal proxies that significantly enhance both vision-centric perception and generative layout fidelity. SGT formulates these tasks as generative objectives to bridge the isolation between understanding and generation, improving feature linear separability and optimizing visual-textual attention allocation.
What carries the argument
Semantic Generative Tuning (SGT), a post-training method that treats image segmentation as the central generative proxy to align multimodal representation spaces.
If this is right
- Better linear separability of visual features.
- More effective visual-textual attention patterns.
- Higher scores on both understanding and generation benchmarks.
- Tighter coupling between perception and layout fidelity in generated images.
Where Pith is reading between the lines
- Similar proxy tasks could be tested for video or 3D generation to check if structural semantics remain effective.
- The method might reduce reliance on separate specialist models for understanding versus creation.
- Real-world editing or scene synthesis pipelines could gain from the reported layout improvements.
Load-bearing premise
Segmentation supplies structural semantics without introducing its own biases or texture distractions, and the observed gains on tested benchmarks and models will transfer to other architectures and real-world data.
What would settle it
Running SGT on a new model or dataset yields no gain or a drop in both comprehension accuracy and generative layout metrics relative to the decoupled baseline.
Figures










read the original abstract
Unified multimodal models (UMMs) strive to consolidate visual understanding and visual generation within a single architecture. However, prevailing training paradigms independently optimize understanding via sparse text signals and generation through dense pixel objectives. Such a decoupled strategy yields misaligned representation spaces, isolating visual understanding from generation and hindering their mutual reinforcement. This work presents the first systematic investigation into generative post-training, where we formulate hierarchical visual tasks as generative proxies to bridge the isolation in UMMs. Our empirical investigation reveals that high-level semantic tasks, particularly image segmentation, serve as optimal proxies. Unlike low-level tasks that distract models with texture details, segmentation provides structural semantics that significantly enhance both vision-centric perception and generative layout fidelity. Building upon these insights, we introduce Semantic Generative Tuning (SGT), a novel paradigm that leverages segmentation as a generative proxy to align and synergize multimodal capabilities. Mechanistic analyses further demonstrate that SGT fundamentally improves feature linear separability and optimizes visual-textual attention allocation pattern. Extensive evaluations show that SGT consistently improves both multimodal comprehension and generative fidelity across mainstream benchmarks. Our code is available on the https://song2yu.github.io/SGT/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Semantic Generative Tuning (SGT), a generative post-training paradigm for unified multimodal models (UMMs). It formulates hierarchical visual tasks as generative proxies to address the misalignment between sparse-text understanding and dense-pixel generation. The central empirical finding is that high-level semantic tasks, particularly image segmentation, serve as optimal proxies by supplying structural semantics that improve vision-centric perception and generative layout fidelity, in contrast to low-level tasks that introduce texture distractions. The work supports this with mechanistic analyses of feature linear separability and visual-textual attention allocation, plus benchmark evaluations showing consistent gains; code is released.
Significance. If the empirical results and mechanistic claims hold under rigorous controls, the work would offer a practical and conceptually clean route to joint optimization of understanding and generation in UMMs. The emphasis on mechanistic diagnostics (separability, attention patterns) and the release of code are positive contributions that aid reproducibility and follow-up work. The absence of concrete numerical results, error bars, baseline tables, or dataset specifications in the abstract, however, prevents a precise evaluation of effect sizes or generalizability at this stage.
major comments (1)
- The optimality claim for segmentation as a proxy (abstract and empirical investigation section) rests on the assertion that benefits arise specifically from structural semantics rather than from any dense pixel-level supervision. The manuscript compares segmentation against low-level tasks but does not report a controlled ablation that replaces segmentation with another high-level dense generative proxy (e.g., depth estimation or panoptic segmentation) under identical generative formulation, loss weighting, and compute budget. Without this isolation, it remains unclear whether the observed gains are attributable to the claimed semantic property or to generic properties of dense supervision; this directly affects the load-bearing distinction drawn in the abstract.
minor comments (2)
- Abstract: the statement that SGT 'consistently improves both multimodal comprehension and generative fidelity across mainstream benchmarks' is presented without any quantitative deltas, baseline names, or dataset identifiers, which reduces immediate assessability of the empirical contribution.
- The mechanistic analysis section would benefit from explicit statements of the linear-separability metric and the precise attention-allocation statistic used, together with statistical significance tests against the untuned baseline.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. We address the major comment point by point below, providing clarifications and outlining revisions where appropriate.
read point-by-point responses
-
Referee: The optimality claim for segmentation as a proxy (abstract and empirical investigation section) rests on the assertion that benefits arise specifically from structural semantics rather than from any dense pixel-level supervision. The manuscript compares segmentation against low-level tasks but does not report a controlled ablation that replaces segmentation with another high-level dense generative proxy (e.g., depth estimation or panoptic segmentation) under identical generative formulation, loss weighting, and compute budget. Without this isolation, it remains unclear whether the observed gains are attributable to the claimed semantic property or to generic properties of dense supervision; this directly affects the load-bearing distinction drawn in the abstract.
Authors: We thank the referee for highlighting this important aspect of our empirical investigation. Our current comparisons focus on contrasting high-level semantic tasks like segmentation with low-level tasks (e.g., edge detection) to demonstrate that structural semantics, rather than mere dense pixel supervision, drive the improvements in perception and generation. However, we acknowledge that a direct comparison with other high-level dense proxies such as depth estimation or panoptic segmentation, under matched conditions, would further strengthen the specificity of our claims regarding segmentation's optimality. We will incorporate additional ablation studies in the revised version, ensuring identical generative formulation, loss weighting, and compute budget. This will help isolate whether the benefits are unique to segmentation's structural semantics or shared among high-level tasks. revision: yes
Circularity Check
No circularity: empirical proxy selection rests on external benchmarks
full rationale
The paper conducts an empirical investigation comparing hierarchical visual tasks as generative proxies for UMM post-training. The claim that segmentation is optimal is grounded in benchmark improvements and mechanistic analyses (linear separability, attention patterns) rather than any internal derivation, fitted parameter renamed as prediction, or self-referential definition. No equations reduce outputs to inputs by construction, and evaluations use external datasets and models. The contribution is self-contained against independent measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decoupled optimization of understanding via text and generation via pixels produces misaligned representation spaces that hinder mutual reinforcement.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
high-level semantic tasks, particularly image segmentation, serve as optimal proxies... segmentation provides structural semantics that significantly enhance both vision-centric perception and generative layout fidelity
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SGT fundamentally improves feature linear separability and optimizes visual-textual attention allocation pattern
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv:2502.13923 (2025) 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., Ng, C., Wang, R., Ramesh, A.: Video gener- ation models as world simulators (2024),https://openai.com/research/video- generation-models-as-world-simulators1
work page 2024
- [4]
-
[5]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., et al.: Are we on the right way for evaluating large vision-language models? NeurIPS37, 27056–27087 (2024) 6, 9, 11, 17
work page 2024
-
[6]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv:2501.17811 (2025) 3, 5, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Chen, X., Liu, Z., Xie, S., He, K.: Deconstructing denoising diffusion models for self-supervised learning. arXiv:2401.14404 (2024) 4
-
[8]
NeurIPS36, 49250–49267 (2023) 2
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. NeurIPS36, 49250–49267 (2023) 2
work page 2023
-
[9]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv:2505.14683 (2025) 3, 5, 7, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: ICLR (2024),https://openreview.net/forum? id=y01KGvd9Bw2
Dong, R., Han, C., Peng, Y., Qi, Z., Ge, Z., Yang, J., Zhao, L., Sun, J., Zhou, H., Wei, H., Kong, X., Zhang, X., Ma, K., Yi, L.: DreamLLM: Synergistic multimodal comprehension and creation. In: ICLR (2024),https://openreview.net/forum? id=y01KGvd9Bw2
work page 2024
-
[11]
arXiv preprint arXiv:2511.23386 (2025) 4, 7, 9
Du, S., Guo, J., Li, B., Cui, S., Xu, Z., Luo, Y., Wei, Y., Gai, K., Wang, X., Wu, K., et al.: Vqrae: Representation quantization autoencoders for multimodal understanding, generation and reconstruction. arXiv:2511.23386 (2025) 4
- [12]
-
[13]
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024) 1, 4
work page 2024
-
[14]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv:2306.13394 (2023) 9, 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [15]
-
[16]
BLINK: Multimodal Large Language Models Can See but Not Perceive
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not per- ceive. arXiv:2404.12390 (2024) 9, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Fuest, M., Ma, P., Gui, M., Schusterbauer, J., Hu, V.T., Ommer, B.: Diffusion models and representation learning: A survey. arXiv:2407.00783 (2024) 4
-
[18]
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Ge,Y.,Zhao,S.,Zhu,J.,Ge,Y.,Yi,K.,Song,L.,Li,C.,Ding,X.,Shan,Y.:Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv:2404.14396 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
NeurIPS36, 52132–52152 (2023) 3, 6, 9, 14
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. NeurIPS36, 52132–52152 (2023) 3, 6, 9, 14
work page 2023
- [20]
-
[21]
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., et al.: Hallusionbench: an advanced diagnostic suite for entangled lan- guage hallucination and visual illusion in large vision-language models. In: CVPR. pp. 14375–14385 (2024) 6, 9, 11, 17
work page 2024
- [22]
- [23]
-
[24]
Jin, Y., Sun, Z., Xu, K., Chen, L., Jiang, H., Huang, Q., Song, C., Liu, Y., Zhang, D., Song, Y., et al.: Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization. arXiv:2402.03161 (2024) 2
-
[25]
Jin, Y., Xu, K., Chen, L., Liao, C., Tan, J., Huang, Q., Chen, B., Lei, C., Liu, A., Song, C., et al.: Unified language-vision pretraining in llm with dynamic discrete visual tokenization. arXiv:2309.04669 (2023) 2
- [26]
-
[27]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Li, Y., Liu, Z., Li, C.: Llava-onevision: Easy visual task transfer. arXiv:2408.03326 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
Li, Z., Liu, Z., Zhang, Q., Lin, B., Yuan, S., Yan, Z., Ye, Y., Yu, W., Niu, Y., Yuan, L.: Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback. arXiv:2510.16888 (2025) 2
work page internal anchor Pith review arXiv 2025
-
[30]
Liao, X., He, Q., Xu, K., Qu, X., Li, Y., Wei, W., Yao, A.: Va-π: Variational policy alignment for pixel-aware autoregressive generation. arXiv:2512.19680 (2025) 5
-
[31]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Lin, B., Li, Z., Cheng, X., Niu, Y., Ye, Y., He, X., Yuan, S., Yu, W., Wang, S., Ge, Y., et al.: Uniworld: High-resolution semantic encoders for unified visual understanding and generation. arXiv:2506.03147 (2025) 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Transactions of the Association for Computational Linguistics (2023) 6, 9, 17
Liu, F., Emerson, G.E.T., Collier, N.: Visual spatial reasoning. Transactions of the Association for Computational Linguistics (2023) 6, 9, 17
work page 2023
-
[33]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023) 1
work page 2023
-
[34]
Step1X-Edit: A Practical Framework for General Image Editing
Liu, S., Han, Y., Xing, P., Yin, F., Wang, R., Cheng, W., Liao, J., Wang, Y., Fu, H., Han, C., Li, G., Peng, Y., Sun, Q., Wu, J., Cai, Y., Ge, Z., Ming, R., Xia, L., Semantic Generative Tuning for Unified Multimodal Models 27 Zeng, X., Zhu, Y., Jiao, B., Zhang, X., Yu, G., Jiang, D.: Step1x-edit: A practical framework for general image editing. arXiv:2504...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: ECCV. pp. 216–233. Springer (2024) 9
work page 2024
-
[36]
Science China Information Sciences67(12), 220102 (2024) 6, 17
Liu, Y., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.C., Liu, C.L., Jin, L., Bai, X.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences67(12), 220102 (2024) 6, 17
work page 2024
-
[37]
Lu, J., Clark, C., Lee, S., Zhang, Z., Khosla, S., Marten, R., Hoiem, D., Kembhavi, A.: Unified-io 2: Scaling autoregressive multimodal models with vision, language, audio, and action. arXiv:2312.17172 (2023) 3
-
[38]
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In: ICLR (2024) 6, 9, 17
work page 2024
-
[39]
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: NeurIPS (2022) 6, 17
work page 2022
-
[40]
Luo, R., Li, Y., Chen, L., He, W., Lin, T.E., Liu, Z., Zhang, L., Song, Z., Xia, X., Liu, T., et al.: Deem: Diffusion models serve as the eyes of large language models for image perception. arXiv:2405.15232 (2024) 4
-
[41]
Ma, C., Jiang, Y., Wu, J., Yang, J., Yu, X., Yuan, Z., Peng, B., Qi, X.: Unitok: A unified tokenizer for visual generation and understanding. arXiv:2502.20321 (2025) 3
- [42]
- [43]
- [44]
-
[45]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Niu, Y., Ning, M., Zheng, M., Jin, W., Lin, B., Jin, P., Liao, J., Ning, K., Feng, C., Zhu, B., Yuan, L.: Wise: A world knowledge-informed semantic evaluation for text-to-image generation. arXiv:2503.07265 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Transfer between Modalities with MetaQueries
Pan, X., Shukla, S.N., Singh, A., Zhao, Z., Mishra, S.K., Wang, J., Xu, Z., Chen, J., Li, K., Juefei-Xu, F., et al.: Transfer between modalities with metaqueries. arXiv:2504.06256 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [48]
-
[49]
Peng, X., Wei, Y., Deng, A., Wang, D., Hu, D.: Balanced multimodal learning via on-the-fly gradient modulation. In: CVPR (2022) 14
work page 2022
- [50]
-
[51]
2025.doi:10.48550/arXiv.2412.15188
Shi,W.,Han,X.,Zhou,C.,Liang,W.,Lin,X.V.,Zettlemoyer,L.,Yu,L.:Lmfusion: Adapting pretrained language models for multimodal generation. arXiv:2412.15188 (2024) 2 28 Songsong Yu et al
- [52]
-
[53]
Generation enhances understanding in unified multimodal models via multi-representation generation
Su, Z., Wei, H., Cen, K., Wang, Y., Chen, G., Yuan, C., Chu, X.: Generation en- hances understanding in unified multimodal models via multi-representation gen- eration. arXiv:2601.21406 (2026) 4, 10
-
[54]
Tang, H., Xie, C., Bao, X., Weng, T., Li, P., Zheng, Y., Wang, L.: Unilip: Adapting clip for unified multimodal understanding, generation and editing. arXiv:2507.23278 (2025) 10
-
[55]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team, C.: Chameleon: Mixed-modal early-fusion foundation models. arXiv:2405.09818 (2024) 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
NeurIPS37, 84839–84865 (2024) 1
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive model- ing: Scalable image generation via next-scale prediction. NeurIPS37, 84839–84865 (2024) 1
work page 2024
-
[57]
NeurIPS 36, 48382–48402 (2023) 4
Tian, Y., Fan, L., Isola, P., Chang, H., Krishnan, D.: Stablerep: Synthetic images from text-to-image models make strong visual representation learners. NeurIPS 36, 48382–48402 (2023) 4
work page 2023
-
[58]
NeurIPs37, 87310–87356 (2024) 3, 6, 9, 11, 17
Tong, P., Brown, E., Wu, P., Woo, S., Iyer, A.J.V., Akula, S.C., Yang, S., Yang, J., Middepogu, M., Wang, Z., et al.: Cambrian-1: A fully open, vision-centric ex- ploration of multimodal llms. NeurIPs37, 87310–87356 (2024) 3, 6, 9, 11, 17
work page 2024
-
[59]
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Tong, S., Fan, D., Zhu, J., Xiong, Y., Chen, X., Sinha, K., Rabbat, M., LeCun, Y., Xie, S., Liu, Z.: Metamorph: Multimodal understanding and generation via instruction tuning. arXiv:2412.14164 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [60]
-
[61]
Reconstructive visual instruction tuning.arXiv preprint arXiv:2410.09575, 2024
Wang, H., Zheng, A., Zhao, Y., Wang, T., Ge, Z., Zhang, X., Zhang, Z.: Recon- structive visual instruction tuning. arXiv:2410.09575 (2024) 4, 5
-
[62]
Wang, P., Peng, Y., Gan, Y., Hu, L., Xie, T., Wang, X., Wei, Y., Tang, C., Zhu, B., Li, C., et al.: Skywork unipic: Unified autoregressive modeling for visual un- derstanding and generation. arXiv:2508.03320 (2025) 2
-
[63]
arXiv preprint arXiv:2407.20171 , year=
Wang, W., Sun, Q., Zhang, F., Tang, Y., Liu, J., Wang, X.: Diffusion feedback helps clip see better. arXiv:2407.20171 (2024) 4, 5
-
[64]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv:2409.18869 (2024) 3, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [65]
-
[66]
Wang, Z., Chen, Z., Gou, C., Li, F., Deng, C., Zhu, D., Li, K., Yu, W., Tu, H., Fan, H., et al.: Lightfusion: A light-weighted, double fusion framework for unified multimodal understanding and generation. arXiv:2510.22946 (2025) 3
- [67]
- [68]
-
[69]
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Wu, C., Chen, X., Wu, Z., Ma, Y., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C., et al.: Janus: Decoupling visual encoding for unified multimodal understanding and generation. arXiv:2410.13848 (2024) 2 Semantic Generative Tuning for Unified Multimodal Models 29
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., et al.: Omnigen2: Exploration to advanced multimodal generation. arXiv:2506.18871 (2025) 3, 5, 7, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
arXiv preprint arXiv:2507.01467 (2025)
Wu, G., Zhang, S., Shi, R., Gao, S., Chen, Z., Wang, L., Chen, Z., Gao, H., Tang, Y., Yang, J., et al.: Representation entanglement for generation: Training diffusion transformers is much easier than you think. arXiv:2507.01467 (2025) 4
-
[72]
Wu, J., Jiang, Y., Ma, C., Liu, Y., Zhao, H., Yuan, Z., Bai, S., Bai, X.: Liquid: Language models are scalable and unified multi-modal generators. IJCV (2025) 3
work page 2025
-
[73]
Wu, S., Wu, Z., Gong, Z., Tao, Q., Jin, S., Li, Q., Li, W., Loy, C.C.: Ope- nuni: A simple baseline for unified multimodal understanding and generation. arXiv:2505.23661 (2025) 5, 10
- [74]
-
[75]
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Wu, Y., Zhang, Z., Chen, J., Tang, H., Li, D., Fang, Y., Zhu, L., Xie, E., Yin, H., Yi, L., et al.: Vila-u: a unified foundation model integrating visual understanding and generation. arXiv:2409.04429 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
xAI: Grok-1.5 vision preview.https://x.ai/news/grok-1.5v(2024) 9
work page 2024
-
[77]
"Your output must be a single JSON object.\n\n
Xie, J., Darrell, T., Zettlemoyer, L., Wang, X.: Reconstruction alignment improves unified multimodal models. arXiv:2509.07295 (2025) 2, 4, 8, 10
-
[78]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. arXiv:2408.12528 (2024) 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Show-o2: Improved Native Unified Multimodal Models
Xie,J.,Yang,Z.,Shou,M.Z.:Show-o2:Improvednativeunifiedmultimodalmodels. arXiv:2506.15564 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [80]
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.