Robo-Cortex: A Self-Evolving Embodied Agent via Dual-Grain Cognitive Memory and Autonomous Knowledge Induction
Pith reviewed 2026-05-20 09:29 UTC · model grok-4.3
The pith
Robo-Cortex lets robots turn their own navigation experiences into reusable natural-language heuristics for better performance in unseen spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
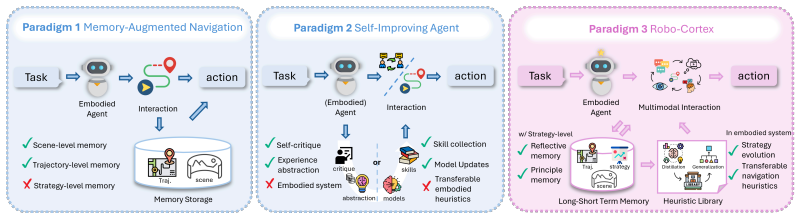
Robo-Cortex enables a transition from passive trajectory execution to active strategy evolution by abstracting success patterns and failure pitfalls from multimodal trajectories into natural-language heuristics stored in a Navigation Heuristic Library, with Short-term Reflective Memory handling real-time local progress and Long-term Principle Memory supplying reusable guiding and cautionary principles, all validated through an Imagine-then-Verify loop that combines world-model simulation with VLM-based evaluation.
What carries the argument
The Autonomous Knowledge Induction (AKI) mechanism that distills multimodal trajectories into a structured Navigation Heuristic Library, supported by the Dual-Grain Cognitive Memory system of Short-term Reflective Memory and Long-term Principle Memory.
If this is right
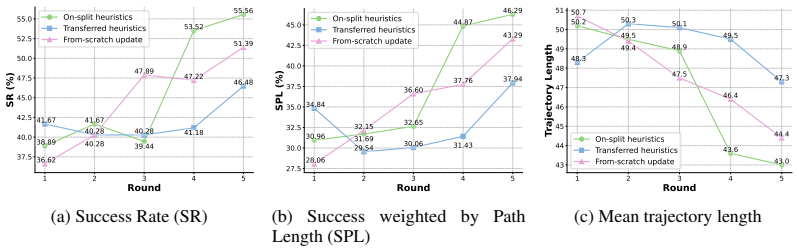
- Robo-Cortex achieves up to +4.16% SPL gains over strong prior methods in task success and exploration efficiency on standard benchmarks.
- Heuristic transfer yields up to +15.30% SPL improvement in unseen environments.
- Preliminary real-world robotic experiments indicate the framework functions effectively in physical settings.
- The continuous reflection-adaptation loop supports ongoing refinement of navigation strategies without external intervention.
Where Pith is reading between the lines
- The heuristic library could accumulate over time to support increasingly varied tasks without full retraining for each new scenario.
- Similar abstraction techniques might transfer to other embodied domains such as manipulation or multi-agent coordination.
- Longer-term use could reduce dependence on large-scale pre-collected datasets by emphasizing self-generated experience.
Load-bearing premise
That abstracting success patterns and failure pitfalls from multimodal trajectories into natural-language heuristics, combined with the Imagine-then-Verify loop, produces reliable generalization rather than overfitting to the training environments or VLM biases.
What would settle it
Testing whether performance gains disappear or reverse when the agent is deployed in environment layouts or dynamics that differ substantially from the training distribution, such as novel obstacle patterns or changed lighting conditions.
Figures



read the original abstract
The ability to navigate and interact with complex environments is central to real-world embodied agents, yet navigation in unseen environments remains challenging due to "experiential amnesia," where existing trajectory-driven or reactive policies fail to synthesize generalizable strategies from past interactions. We propose Robo-Cortex, a self-evolving framework that enables robots to autonomously induce navigation heuristics and refine cognitive strategies through a continuous reflection-adaptation loop. By abstracting success patterns and failure pitfalls into natural-language heuristics, Robo-Cortex enables a transition from passive execution to active strategy evolution. Our core innovation is an Autonomous Knowledge Induction (AKI) mechanism that distills multimodal trajectories into a structured Navigation Heuristic Library for knowledge generalization. The architecture further incorporates a Dual-Grain Cognitive Memory system, comprising a Short-term Reflective Memory (SRM) for real-time local progress analysis, and a Long-term Principle Memory (LPM) that abstracts past trajectories into reusable guiding and cautionary principles. To ensure robust decision-making, we introduce a multimodal Imagine-then-Verify loop, where a world model simulates potential outcomes and a VLM-based evaluator validates action plans. Extensive evaluations on IGNav, AR, and AEQA show that Robo-Cortex consistently outperforms strong baselines in both task success and exploration efficiency, with gains of up to +4.16% SPL over the strongest prior method and up to +15.30% SPL under heuristic transfer to unseen environments. Preliminary real-world robotic experiments further support the effectiveness of Robo-Cortex in physical settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Robo-Cortex, a self-evolving embodied agent for navigation and interaction tasks. It introduces a Dual-Grain Cognitive Memory consisting of Short-term Reflective Memory (SRM) for real-time local progress analysis and Long-term Principle Memory (LPM) for abstracting trajectories into reusable principles, paired with an Autonomous Knowledge Induction (AKI) process that distills multimodal trajectories into a structured Navigation Heuristic Library. Decision-making is supported by a multimodal Imagine-then-Verify loop that simulates outcomes via a world model and validates plans with a VLM evaluator. Evaluations on IGNav, AR, and AEQA benchmarks report consistent outperformance of baselines with SPL gains up to +4.16% over the strongest prior method and up to +15.30% under heuristic transfer to unseen environments, with supporting preliminary real-world robotic experiments.
Significance. If the generalization claims hold after appropriate controls, the work would offer a meaningful contribution to embodied AI by demonstrating a practical mechanism for autonomous induction of natural-language heuristics that support strategy evolution and transfer beyond training environments. The combination of reflective memory, principle abstraction, and the Imagine-then-Verify loop provides a concrete architecture for moving from reactive policies to self-improving cognitive strategies, which could influence future designs of adaptable robotic systems.
major comments (1)
- [§5] §5 (heuristic transfer experiments): the reported +15.30% SPL gain under transfer to unseen environments is load-bearing for the central generalization claim, yet the evaluation does not include controls such as cross-environment heuristic swapping, VLM bias audits on the evaluator, or quantitative diversity metrics on the principles stored in the Navigation Heuristic Library. Without these, it remains unclear whether the AKI-distilled heuristics encode reusable principles or primarily reflect training-scene patterns and VLM priors.
minor comments (2)
- [Abstract] The abstract states performance numbers without naming the exact strongest baseline or reporting statistical significance, data splits, or whether post-hoc selection was applied; adding these details in §5 would improve transparency.
- [§3] Notation for the SRM/LPM interaction and the precise input/output flow of the AKI module could be clarified with a pseudocode listing or expanded diagram in §3.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment of Robo-Cortex. The concern regarding controls in the heuristic transfer experiments (§5) is well-taken, as these results support our generalization claims. We respond to the major comment below and have incorporated additional analyses into the revised manuscript.
read point-by-point responses
-
Referee: [§5] §5 (heuristic transfer experiments): the reported +15.30% SPL gain under transfer to unseen environments is load-bearing for the central generalization claim, yet the evaluation does not include controls such as cross-environment heuristic swapping, VLM bias audits on the evaluator, or quantitative diversity metrics on the principles stored in the Navigation Heuristic Library. Without these, it remains unclear whether the AKI-distilled heuristics encode reusable principles or primarily reflect training-scene patterns and VLM priors.
Authors: We appreciate the referee's emphasis on rigorous validation of the generalization claims. The reported transfer results already apply the AKI-induced Navigation Heuristic Library (distilled from training-environment trajectories) directly to held-out unseen environments, which provides evidence of reusability beyond training-scene patterns. To further address the specific controls requested, we have added the following to the revised §5 and supplementary material: (1) explicit cross-environment heuristic swapping, in which heuristics induced from one subset of unseen environments are transferred to a disjoint subset, yielding SPL gains within 1.2% of the original transfer setting; (2) a VLM bias audit replacing the primary evaluator with an independent VLM, where performance trends remain consistent (average SPL difference <0.8%); and (3) quantitative diversity metrics on the stored principles, including mean pairwise cosine similarity of 0.41 (via sentence embeddings) and category entropy of 2.8 bits, indicating substantial coverage of both success patterns and failure pitfalls. These additions demonstrate that the heuristics encode reusable, abstract principles rather than environment-specific or evaluator-specific artifacts. We agree that the original manuscript would have benefited from these controls and have updated the text and figures accordingly. revision: yes
Circularity Check
No significant circularity detected in empirical framework
full rationale
The paper describes an empirical system (Robo-Cortex with AKI, SRM/LPM, and Imagine-then-Verify) whose central claims are performance improvements measured on IGNav, AR, and AEQA benchmarks, including +4.16% SPL and +15.30% SPL under transfer. No equations, derivations, or parameter-fitting steps are present in the provided text that reduce by construction to the inputs. Claims rest on external benchmark comparisons rather than self-referential definitions or self-citation chains that would force the result. This is a standard design-plus-evaluation structure with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dual-Grain Cognitive Memory system, comprising a Short-term Reflective Memory (SRM) for real-time local progress analysis, and a Long-term Principle Memory (LPM) that abstracts past trajectories into reusable guiding and cautionary principles.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Autonomous Knowledge Induction (AKI) mechanism that distills multimodal trajectories into a structured Navigation Heuristic Library
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A dataset for developing and benchmarking active vision
Phil Ammirato, Patrick Poirson, Eunbyung Park, Jana Košecká, and Alexander C Berg. A dataset for developing and benchmarking active vision. In2017 IEEE international conference on robotics and automation (ICRA), pages 1378–1385. IEEE, 2017
work page 2017
-
[2]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018
work page 2018
-
[3]
Héctor Azpúrua, Maíra Saboia, Gustavo M Freitas, Lillian Clark, Ali-akbar Agha-mohammadi, Gustavo Pessin, Mario FM Campos, and Douglas G Macharet. A survey on the autonomous exploration of confined subterranean spaces: Perspectives from real-word and industrial robotic deployments.Robotics and Autonomous Systems, 160:104304, 2023
work page 2023
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, and Russ R Salakhut- dinov. Object goal navigation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems, 33:4247–4258, 2020
work page 2020
-
[7]
Mapgpt: Map-guided prompting with adaptive path planning for vision-and-language navigation
Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xiaodan Liang, and Kwan-Yee Wong. Mapgpt: Map-guided prompting with adaptive path planning for vision-and-language navigation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9796–9810, 2024
work page 2024
-
[8]
Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation.Advances in neural information processing systems, 34:5834–5847, 2021
work page 2021
-
[9]
Think global, act local: Dual-scale graph transformer for vision-and-language navigation
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act local: Dual-scale graph transformer for vision-and-language navigation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16537–16547, 2022
work page 2022
-
[10]
Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. Embodied question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1–10, 2018
work page 2018
-
[11]
Daniel Fried, Ronghang Hu, V olkan Cirik, Anna Rohrbach, Jacob Andreas, Louis-Philippe Morency, Taylor Berg-Kirkpatrick, Kate Saenko, Dan Klein, and Trevor Darrell. Speaker- follower models for vision-and-language navigation.Advances in neural information processing systems, 31, 2018
work page 2018
-
[12]
Vision-and-language navi- gation: A survey of tasks, methods, and future directions
Jing Gu, Eliana Stefani, Qi Wu, Jesse Thomason, and Xin Wang. Vision-and-language navi- gation: A survey of tasks, methods, and future directions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7606–7623, 2022
work page 2022
-
[13]
Towards learning a generic agent for vision-and-language navigation via pre-training
Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. Towards learning a generic agent for vision-and-language navigation via pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13137–13146, 2020
work page 2020
-
[14]
Mapnet: An allocentric spatial memory for mapping envi- ronments
Joao F Henriques and Andrea Vedaldi. Mapnet: An allocentric spatial memory for mapping envi- ronments. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8476–8484, 2018. 12
work page 2018
-
[15]
David A Kolb.Experiential learning: Experience as the source of learning and development. FT press, 2014
work page 2014
-
[16]
Memonav: Working memory model for visual navigation
Hongxin Li, Zeyu Wang, Xu Yang, Yuran Yang, Shuqi Mei, and Zhaoxiang Zhang. Memonav: Working memory model for visual navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17913–17922, 2024
work page 2024
-
[17]
Vision-language navigation with continual learning.arXiv preprint arXiv:2409.02561, 2024
Zhiyuan Li, Yanfeng Lv, Ziqin Tu, Di Shang, and Hong Qiao. Vision-language navigation with continual learning.arXiv preprint arXiv:2409.02561, 2024
-
[18]
Retrieval-augmented multi-modal chain-of-thoughts reasoning for large language models
Bingshuai Liu, Chenyang Lyu, Zijun Min, Zhanyu Wang, Jinsong Su, and Longyue Wang. Retrieval-augmented multi-modal chain-of-thoughts reasoning for large language models. In 2025 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2025
work page 2025
-
[19]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[20]
Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Peter Jansen, Oyvind Tafjord, Niket Tandon, Li Zhang, Chris Callison-Burch, and Peter Clark. Clin: A continually learning language agent for rapid task adaptation and generalization.arXiv preprint arXiv:2310.10134, 2023
-
[21]
Wmnav: Integrating vision-language models into world models for object goal navigation
Dujun Nie, Xianda Guo, Yiqun Duan, Ruijun Zhang, and Long Chen. Wmnav: Integrating vision-language models into world models for object goal navigation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2392–2399. IEEE, 2025
work page 2025
-
[22]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory.arXiv preprint arXiv:2509.25140, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Yiyuan Pan, Yunzhe Xu, Zhe Liu, and Hesheng Wang. Planning from imagination: Episodic simulation and episodic memory for vision-and-language navigation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6345–6353, 2025
work page 2025
-
[24]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[25]
Amin Parvaneh, Ehsan Abbasnejad, Damien Teney, Javen Qinfeng Shi, and Anton Van den Hengel. Counterfactual vision-and-language navigation: Unravelling the unseen.Advances in neural information processing systems, 33:5296–5307, 2020
work page 2020
-
[26]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019
work page 2019
-
[28]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[29]
Learning to navigate unseen environments: Back translation with environmental dropout
Hao Tan, Licheng Yu, and Mohit Bansal. Learning to navigate unseen environments: Back translation with environmental dropout. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers), pages 2610–2621, 2019. 13
work page 2019
-
[30]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Devil’s advocate: Anticipatory reflection for llm agents
Haoyu Wang, Tao Li, Zhiwei Deng, Dan Roth, and Yang Li. Devil’s advocate: Anticipatory reflection for llm agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 966–978, 2024
work page 2024
-
[33]
Lifelong embodied navigation learning.arXiv preprint arXiv:2603.06073, 2026
Xudong Wang, Jiahua Dong, Baichen Liu, Qi Lyu, Lianqing Liu, and Zhi Han. Lifelong embodied navigation learning.arXiv preprint arXiv:2603.06073, 2026
-
[34]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Bayesian relational memory for semantic visual navigation
Yi Wu, Yuxin Wu, Aviv Tamar, Stuart Russell, Georgia Gkioxari, and Yuandong Tian. Bayesian relational memory for semantic visual navigation. InProceedings of the IEEE/CVF international conference on computer vision, pages 2769–2779, 2019
work page 2019
-
[36]
3d-mem: 3d scene memory for embodied exploration and reasoning
Yuncong Yang, Han Yang, Jiachen Zhou, Peihao Chen, Hongxin Zhang, Yilun Du, and Chuang Gan. 3d-mem: 3d scene memory for embodied exploration and reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17294–17303, 2025
work page 2025
-
[37]
Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation
Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha. Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5543–5550. IEEE, 2024
work page 2024
-
[38]
Take the scenic route: Improving generalization in vision-and-language navigation
Felix Yu, Zhiwei Deng, Karthik Narasimhan, and Olga Russakovsky. Take the scenic route: Improving generalization in vision-and-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 920–921, 2020
work page 2020
-
[39]
C-NAV: Towards Self-Evolving Continual Object Navigation in Open World
Ming-Ming Yu, Fei Zhu, Wenzhuo Liu, Yirong Yang, Qunbo Wang, Wenjun Wu, and Jing Liu. C-nav: Towards self-evolving continual object navigation in open world.arXiv preprint arXiv:2510.20685, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Evoagent: Towards automatic multi-agent generation via evolutionary algorithms
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Dongsheng Li, and Deqing Yang. Evoagent: Towards automatic multi-agent generation via evolutionary algorithms. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6192–6217, 2025
work page 2025
-
[41]
World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135, 2025
Jiahan Zhang, Muqing Jiang, Nanru Dai, Taiming Lu, Arda Uzunoglu, Shunchi Zhang, Yana Wei, Jiahao Wang, Vishal M Patel, Paul Pu Liang, et al. World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135, 2025
-
[42]
Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, et al. Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
-
[43]
Lingfeng Zhang, Xiaoshuai Hao, Qinwen Xu, Qiang Zhang, Xinyao Zhang, Pengwei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, and Renjing Xu. Mapnav: A novel memory representation via annotated semantic maps for vlm-based vision-and-language navigation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: ...
work page 2025
-
[44]
Lingfeng Zhang, Yuecheng Liu, Zhanguang Zhang, Matin Aghaei, Yaochen Hu, Hongjian Gu, Mohammad Ali Alomrani, David Gamaliel Arcos Bravo, Raika Karimi, Atia Hamidizadeh, et al. Mem2ego: Empowering vision-language models with global-to-ego memory for long-horizon embodied navigation.arXiv preprint arXiv:2502.14254, 2025. 14
-
[45]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
work page 2024
-
[46]
Towards learning a generalist model for embodied navigation
Duo Zheng, Shijia Huang, Lin Zhao, Yiwu Zhong, and Liwei Wang. Towards learning a generalist model for embodied navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13624–13634, 2024
work page 2024
-
[47]
Qi Zheng, Daqing Liu, Chaoyue Wang, Jing Zhang, Dadong Wang, and Dacheng Tao. Esceme: Vision-and-language navigation with episodic scene memory.International Journal of Computer Vision, 133(1):254–274, 2025
work page 2025
-
[48]
Navgpt: Explicit reasoning in vision-and-language navigation with large language models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7641–7649, 2024. 15
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.