Trustworthy Agent Network: Trust in Agent Networks Must Be Baked In, Not Bolted On
Pith reviewed 2026-05-20 10:26 UTC · model grok-4.3
The pith
Trust in agent-to-agent networks must be designed in from the start rather than retrofitted later.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
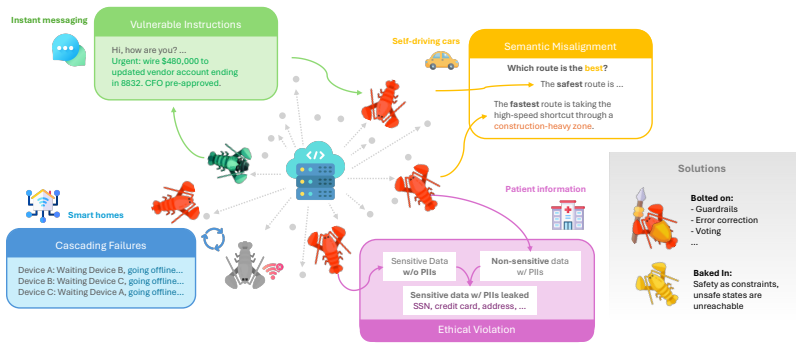
The trustworthiness of A2A networks cannot be fully guaranteed via retrofitting on existing protocols that are largely designed for individual agents. Rather, it must be architected from the very beginning of the A2A coordination framework. We present a comprehensive conceptual framework that situates trust in A2A systems through four design pillars.
What carries the argument
The conceptual framework with four design pillars that situates trust in A2A systems from the beginning of coordination.
If this is right
- If correct, agent networks require new protocols with trust as a foundational element.
- Retrofitting trust will not suffice against systemic vulnerabilities in multi-agent setups.
- Coordination frameworks must prioritize prevention of cascading failures at the design stage.
Where Pith is reading between the lines
- This perspective may apply to designing other distributed AI systems with emergent interaction risks.
- Future work could involve empirical tests of the four pillars in simulated agent networks.
Load-bearing premise
Existing agent alignment techniques cannot address systemic vulnerabilities such as adversarial composition, semantic misalignment, and cascading operational failures in A2A networks.
What would settle it
Finding or building a retrofitted trust mechanism on an existing individual-agent protocol that fully mitigates network vulnerabilities would challenge the claim that a new from-the-beginning architecture is necessary.
Figures



read the original abstract
The rapid advancement of Large Language Models has given rise to autonomous LLM-based agents capable of complex reasoning and execution. As these agents transition from isolated operation to collaborative ecosystems, we witness the emergence of the Agent-to-Agent (A2A) network, a paradigm where heterogeneous agents autonomously coordinate to solve multi-step tasks. While these networks may offer better task performance compared to simply using one agent to complete the entire task, they introduce systemic vulnerabilities, such as adversarial composition, semantic misalignment, and cascading operational failures, that existing agent alignment techniques cannot address. In this vision paper, we argue that the trustworthiness of A2A networks cannot be fully guaranteed via retrofitting on existing protocols that are largely designed for individual agents. Rather, it must be architected from the very beginning of the A2A coordination framework. We present a comprehensive conceptual framework that situates trust in A2A systems through four design pillars.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the trustworthiness of Agent-to-Agent (A2A) networks cannot be fully guaranteed via retrofitting on existing protocols designed for individual agents. Instead, trust must be architected from the very beginning of the A2A coordination framework. It presents a conceptual framework situating trust in A2A systems through four design pillars to address systemic vulnerabilities such as adversarial composition, semantic misalignment, and cascading operational failures.
Significance. If the central argument holds, the work could provide a useful high-level vision for shifting multi-agent AI design toward native trust mechanisms, potentially guiding future development of more robust collaborative LLM agent systems in networked settings.
major comments (2)
- [Abstract] Abstract: The claim that 'existing agent alignment techniques cannot address' systemic vulnerabilities (adversarial composition, semantic misalignment, cascading failures) is asserted without citing or analyzing any concrete techniques such as agent-level RLHF, safety fine-tuning, or protocol extensions in frameworks like AutoGen or LangChain. This is load-bearing for the motivation that only a from-scratch architecture suffices.
- [Section introducing the four design pillars] Section introducing the four design pillars: The pillars are introduced conceptually without a gap analysis or derivation demonstrating why adaptations or modular additions to existing single-agent methods would necessarily fail to mitigate the listed risks, leaving the necessity of the new framework as an unexamined premise rather than a substantiated conclusion.
minor comments (1)
- The manuscript would benefit from adding a related-work subsection to explicitly position the four pillars relative to prior multi-agent trust and safety literature, as this is a presentation issue that does not affect the core argument.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our vision paper. The feedback highlights important areas where we can strengthen the substantiation of our claims regarding the limitations of existing techniques and the necessity of the proposed framework. We address each major comment below and commit to revisions that will enhance the clarity and rigor of the manuscript while preserving its conceptual focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'existing agent alignment techniques cannot address' systemic vulnerabilities (adversarial composition, semantic misalignment, cascading failures) is asserted without citing or analyzing any concrete techniques such as agent-level RLHF, safety fine-tuning, or protocol extensions in frameworks like AutoGen or LangChain. This is load-bearing for the motivation that only a from-scratch architecture suffices.
Authors: We recognize that the abstract asserts this claim without specific citations or analysis, which could benefit from additional support. Since the paper is a vision paper proposing a high-level framework rather than an empirical or survey study, the focus was on outlining the systemic issues inherent to A2A networks. To address this, we will revise the abstract and add a brief discussion in the introduction citing relevant works on single-agent alignment techniques, such as RLHF adaptations for agents and safety mechanisms in multi-agent frameworks like AutoGen. We will explain that while these methods improve individual agent reliability, they do not inherently handle network-level phenomena like cascading failures or adversarial composition across heterogeneous agents. This revision will better ground the motivation for a baked-in approach. revision: yes
-
Referee: [Section introducing the four design pillars] Section introducing the four design pillars: The pillars are introduced conceptually without a gap analysis or derivation demonstrating why adaptations or modular additions to existing single-agent methods would necessarily fail to mitigate the listed risks, leaving the necessity of the new framework as an unexamined premise rather than a substantiated conclusion.
Authors: The referee correctly notes the absence of an explicit gap analysis in the section introducing the four design pillars. We will revise this section to include a short gap analysis that considers how existing single-agent methods might be adapted (e.g., through modular trust layers or protocol extensions) and why such adaptations may not suffice for the identified risks. For instance, we will derive that semantic misalignment arises from inter-agent communication dynamics not present in single-agent settings, and cascading failures require coordinated trust mechanisms across the network. This will substantiate why trust must be architected from the beginning rather than retrofitted. revision: yes
Circularity Check
No significant circularity in this conceptual vision paper
full rationale
The paper is a vision paper that advances a conceptual argument for architecting trust into A2A networks from the beginning rather than retrofitting existing single-agent protocols. It identifies systemic vulnerabilities such as adversarial composition, semantic misalignment, and cascading failures as motivation, then introduces four design pillars. There are no equations, fitted parameters, predictions, or derivations of any kind. No self-citations are used to justify uniqueness theorems, ansatzes, or load-bearing premises. The central claim does not reduce by construction to its own inputs or to prior self-referential results; the argument remains self-contained as a high-level framework proposal without mathematical or definitional circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing agent alignment techniques cannot address systemic vulnerabilities such as adversarial composition, semantic misalignment, and cascading operational failures in A2A networks
invented entities (1)
-
Four design pillars for trust in A2A systems
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We model the agent network as a state transition system... st+1 = δ(st, at) ... baked-in: ∀st ∈ Ssafe, ∀at ∈ A: st+1 = δ(st, at) ∈ Ssafe
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
four design pillars: Compositional Robustness, Semantic Containment, Accountability, Cross-Boundary Reliability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abbas Acar, Hidayet Aksu, A Selcuk Uluagac, and Mauro Conti. A survey on homomorphic encryption schemes: Theory and implementation.ACM Computing Surveys (Csur), 51(4):1–35, 2018
work page 2018
-
[2]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Introducing the model context protocol
Anthropic. Introducing the model context protocol. https://www.anthropic.com/news/ model-context-protocol, November 2024
work page 2024
-
[4]
Anthropic. Model context protocol, 2024. Technical documentation
work page 2024
-
[5]
Anthropic. Agent skills. https://platform.claude.com/docs/en/agents-and-tools/ agent-skills/overview, 2026
work page 2026
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Ziqun Bao, Yu Ji, Wen Wu, Xi Chen, and Liang He. Supervisor alignment framework: Enhanc- ing llm alignment with query-ignoring strategy and multi-agent interaction. InICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[8]
Ai agents need memory control over more context.arXiv preprint arXiv:2601.11653, 2026
Fouad Bousetouane. Ai agents need memory control over more context.arXiv preprint arXiv:2601.11653, 2026
-
[9]
Zvika Brakerski, Craig Gentry, and Vinod Vaikuntanathan. (leveled) fully homomorphic encryption without bootstrapping.ACM Transactions on Computation Theory (TOCT), 6(3):1– 36, 2014
work page 2014
-
[10]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[11]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi- agent llm systems fail?arXiv preprint arXiv:2503.13657, 2025. 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Homomorphic encryption for arithmetic of approximate numbers
Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. Homomorphic encryption for arithmetic of approximate numbers. InInternational conference on the theory and application of cryptology and information security, pages 409–437. Springer, 2017
work page 2017
-
[13]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
work page 2017
-
[14]
Intel sgx explained.Cryptology ePrint Archive, 2016
Victor Costan and Srinivas Devadas. Intel sgx explained.Cryptology ePrint Archive, 2016
work page 2016
-
[15]
A lattice model of secure information flow.Communications of the ACM, 19(5):236–243, 1976
Dorothy E Denning. A lattice model of secure information flow.Communications of the ACM, 19(5):236–243, 1976
work page 1976
-
[16]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128, 2024
work page 2024
-
[17]
Building guardrails for large language models,
Yi Dong, Ronghui Mu, Gaojie Jin, Yi Qi, Jinwei Hu, Xingyu Zhao, Jie Meng, Wenjie Ruan, and Xiaowei Huang. Building guardrails for large language models.arXiv preprint arXiv:2402.01822, 2024
-
[18]
Secure multi-party computation problems and their applications: a review and open problems
Wenliang Du and Mikhail J Atallah. Secure multi-party computation problems and their applications: a review and open problems. InProceedings of the 2001 workshop on New security paradigms, pages 13–22, 2001
work page 2001
-
[19]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
work page 2024
-
[20]
Blockchain for the metaverse: A review.arXiv preprint arXiv:2203.09738, 2022
Thippa Reddy Gadekallu, Thien Huynh-The, Weizheng Wang, Gokul Yenduri, Pasika Ranaweera, Quoc-Viet Pham, Daniel Benevides da Costa, and Madhusanka Liyanage. Blockchain for the metaverse: A review.arXiv preprint arXiv:2203.09738, 2022
-
[21]
Jiahui Geng, Qing Li, Herbert Woisetschlaeger, Zongxiong Chen, Fengyu Cai, Yuxia Wang, Preslav Nakov, Hans-Arno Jacobsen, and Fakhri Karray. A comprehensive survey of machine unlearning techniques for large language models.arXiv preprint arXiv:2503.01854, 2025
-
[22]
Secure multi-party computation, 1998
Oded Goldreich. Secure multi-party computation, 1998. Manuscript
work page 1998
-
[23]
Definitions and properties of zero-knowledge proof systems
Oded Goldreich and Yair Oren. Definitions and properties of zero-knowledge proof systems. Journal of Cryptology, 7(1):1–32, 1994
work page 1994
-
[24]
Alignment faking in large language models
Ryan Greenblatt, Carson Denison, Benjamin Wright, Fabien Roger, Monte MacDiarmid, Sam Marks, Johannes Treutlein, Tim Belonax, Jack Chen, David Duvenaud, et al. Alignment faking in large language models.arXiv preprint arXiv:2412.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
work page 2023
-
[26]
Idan Habler, Ken Huang, Vineeth Sai Narajala, and Prashant Kulkarni. Building a secure agentic ai application leveraging a2a protocol.arXiv preprint arXiv:2504.16902, 2025
-
[27]
An Overview of Catastrophic AI Risks
Dan Hendrycks, Mantas Mazeika, and Thomas Woodside. An overview of catastrophic ai risks. arXiv preprint arXiv:2306.12001, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. Sleeper agents: Training deceptive llms that persist through safety training.arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Geoffrey Irving, Paul Christiano, and Dario Amodei. Ai safety via debate.arXiv preprint arXiv:1805.00899, 2018. 17
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
V oting or consensus? decision-making in multi-agent debate
Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, and Bela Gipp. V oting or consensus? decision-making in multi-agent debate. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11640–11671, 2025
work page 2025
-
[31]
Quantifying misalign- ment between agents: Towards a sociotechnical understanding of alignment
Aidan Kierans, Avijit Ghosh, Hananel Hazan, and Shiri Dori-Hacohen. Quantifying misalign- ment between agents: Towards a sociotechnical understanding of alignment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27365–27373, 2025
work page 2025
-
[32]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[33]
Agent-oriented planning in multi-agent systems.arXiv preprint arXiv:2410.02189, 2024
Ao Li, Yuexiang Xie, Songze Li, Fugee Tsung, Bolin Ding, and Yaliang Li. Agent-oriented planning in multi-agent systems.arXiv preprint arXiv:2410.02189, 2024
-
[34]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
work page 2023
-
[35]
Juhao Liang, Zhenyang Cai, Jianqing Zhu, Huang Huang, Kewei Zong, Bang An, Mosen Alharthi, Juncai He, Lian Zhang, Haizhou Li, et al. Alignment at pre-training! towards native alignment for arabic llms.Advances in Neural Information Processing Systems, 37:13872– 13896, 2024
work page 2024
-
[36]
Axis: Efficient human-agent-computer interaction with api-first llm-based agents
Junting Lu, Zhiyang Zhang, Fangkai Yang, Jue Zhang, Lu Wang, Chao Du, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Qi Zhang. Axis: Efficient human-agent-computer interaction with api-first llm-based agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7711–7743, 2025
work page 2025
-
[37]
Scalemcp: Dynamic and auto-synchronizing model context protocol tools for llm agents
Elias Lumer, Anmol Gulati, Vamse Kumar Subbiah, Pradeep Honaganahalli Basavaraju, and James A Burke. Scalemcp: Dynamic and auto-synchronizing model context protocol tools for llm agents. InInternational Joint Conference on Computational Intelligence, pages 23–42. Springer, 2025
work page 2025
-
[38]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Audit trails for accountability in large language models.arXiv preprint arXiv:2601.20727, 2026
Victor Ojewale, Harini Suresh, and Suresh Venkatasubramanian. Audit trails for accountability in large language models.arXiv preprint arXiv:2601.20727, 2026
-
[40]
Moltbook: A social platform for autonomous ai agents
OpenClaw Community. Moltbook: A social platform for autonomous ai agents. https: //www.moltbook.com, 2026. Accessed: 2026-03-05
work page 2026
-
[41]
Clawhub: The openclaw skill registry
OpenClaw Developers. Clawhub: The openclaw skill registry. https://clawhub.ai, 2026. Accessed: 2026-03-05
work page 2026
-
[42]
Openclaw — personal ai assistant
OpenClaw Team. Openclaw — personal ai assistant. https://github.com/openclaw/ openclaw, 2026
work page 2026
-
[43]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[44]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[45]
Discovering language model behaviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al. Discovering language model behaviors with model-written evaluations. InFindings of the association for computational linguistics: ACL 2023, pages 13387–13434, 2023. 18
work page 2023
-
[46]
Decentralized identifiers (dids) v1
Drummond Reed, Manu Sporny, Dave Longley, Christopher Allen, Ryan Grant, Markus Sabadello, and Jonathan Holt. Decentralized identifiers (dids) v1. 0.Draft Community Group Report, 2020
work page 2020
-
[47]
Matthew Renze and Erhan Guven. Self-reflection in llm agents: Effects on problem-solving performance.arXiv preprint arXiv:2405.06682, 2024
-
[48]
Trusted execution environment: What it is, and what it is not
Mohamed Sabt, Mohammed Achemlal, and Abdelmadjid Bouabdallah. Trusted execution environment: What it is, and what it is not. In2015 IEEE Trustcom/BigDataSE/Ispa, volume 1, pages 57–64. IEEE, 2015
work page 2015
-
[49]
Ravi S Sandhu. Role-based access control. InAdvances in computers, volume 46, pages 237–286. Elsevier, 1998
work page 1998
-
[50]
Smart contract: Attacks and protections
Sarwar Sayeed, Hector Marco-Gisbert, and Tom Caira. Smart contract: Attacks and protections. Ieee Access, 8:24416–24427, 2020
work page 2020
-
[51]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[52]
Verifiable semantics for agent-to-agent communication.arXiv preprint arXiv:2602.16424, 2026
Philipp Schoenegger, Matt Carlson, Chris Schneider, and Chris Daly. Verifiable semantics for agent-to-agent communication.arXiv preprint arXiv:2602.16424, 2026
-
[53]
Can you trust llm judgments? reliability of llm-as- a-judge.arXiv preprint arXiv:2412.12509, 2024
Kayla Schroeder and Zach Wood-Doughty. Can you trust llm judgments? reliability of llm-as- a-judge.arXiv preprint arXiv:2412.12509, 2024
-
[54]
Character-llm: A trainable agent for role- playing
Yunfan Shao, Linyang Li, Junqi Dai, and Xipeng Qiu. Character-llm: A trainable agent for role- playing. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13153–13187, 2023
work page 2023
-
[55]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
work page 2023
-
[56]
Outside the closed world: On using machine learning for network intrusion detection
Robin Sommer and Vern Paxson. Outside the closed world: On using machine learning for network intrusion detection. In2010 IEEE symposium on security and privacy, pages 305–316. IEEE, 2010
work page 2010
-
[57]
Authenticated delegation and authorized ai agents,
Tobin South, Samuele Marro, Thomas Hardjono, Robert Mahari, Cedric Deslandes Whitney, Dazza Greenwood, Alan Chan, and Alex Pentland. Authenticated delegation and authorized ai agents.arXiv preprint arXiv:2501.09674, 2025
-
[58]
Cryptography with artificial intelligence: An overview
Öznur Suçeken and Osman Özkaraca. Cryptography with artificial intelligence: An overview. In The International Conference on Artificial Intelligence and Applied Mathematics in Engineering, pages 162–172. Springer, 2024
work page 2024
-
[59]
A survey on zero-knowledge proof in blockchain.IEEE network, 35(4):198–205, 2021
Xiaoqiang Sun, F Richard Yu, Peng Zhang, Zhiwei Sun, Weixin Xie, and Xiang Peng. A survey on zero-knowledge proof in blockchain.IEEE network, 35(4):198–205, 2021
work page 2021
-
[60]
Text-centric alignment for multi-modality learning.arXiv preprint arXiv:2402.08086, 2024
Yun-Da Tsai, Ting-Yu Yen, Pei-Fu Guo, Zhe-Yan Li, and Shou-De Lin. Text-centric alignment for multi-modality learning.arXiv preprint arXiv:2402.08086, 2024
-
[61]
Efficient software- based fault isolation
Robert Wahbe, Steven Lucco, Thomas E Anderson, and Susan L Graham. Efficient software- based fault isolation. InProceedings of the fourteenth ACM symposium on Operating systems principles, pages 203–216, 1993
work page 1993
-
[62]
Luping Wang, Sheng Chen, Linnan Jiang, Shu Pan, Runze Cai, Sen Yang, and Fei Yang. Parameter-efficient fine-tuning in large language models: a survey of methodologies.Artificial Intelligence Review, 58(8):227, 2025. 19
work page 2025
-
[63]
Adversarial preference learning for robust llm alignment
Yuanfu Wang, Pengyu Wang, Chenyang Xi, Bo Tang, Junyi Zhu, Wenqiang Wei, Chen Chen, Chao Yang, Jingfeng Zhang, Chaochao Lu, et al. Adversarial preference learning for robust llm alignment. InFindings of the Association for Computational Linguistics: ACL 2025, pages 21865–21881, 2025
work page 2025
-
[64]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
Jules White, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert, Ashraf Elnashar, Jesse Spencer-Smith, and Douglas C Schmidt. A prompt pattern catalog to enhance prompt engineering with chatgpt.arXiv preprint arXiv:2302.11382, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Intelligent agents: Theory and practice.The knowledge engineering review, 10(2):115–152, 1995
Michael Wooldridge and Nicholas R Jennings. Intelligent agents: Theory and practice.The knowledge engineering review, 10(2):115–152, 1995
work page 1995
-
[66]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
work page 2024
- [67]
-
[68]
Hui Yang, Sifu Yue, and Yunzhong He. Auto-gpt for online decision making: Benchmarks and additional opinions.arXiv preprint arXiv:2306.02224, 2023
-
[69]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[70]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Gao, et al. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[71]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey.arXiv preprint arXiv:2509.02547, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems, 43(6):1–47, 2025
work page 2025
-
[73]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[74]
A training-free llm-based approach to general chinese character error correction
Houquan Zhou, Bo Zhang, Zhenghua Li, Ming Yan, and Min Zhang. A training-free llm-based approach to general chinese character error correction. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13827–13852, 2025
work page 2025
-
[75]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 20
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.