STAR-P\'olyaMath: Multi-Agent Reasoning under Persistent Meta-Strategic Supervision
Pith reviewed 2026-05-20 02:51 UTC · model grok-4.3
The pith
STAR-PólyaMath uses a persistent Meta-Strategist to orchestrate multi-agent math reasoning and reach state-of-the-art results on eight top competition benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a multi-agent system built as an orchestrated state machine with nested loops and governed by a persistent Meta-Strategist that maintains cross-attempt memory and issues meta-level directives can systematically bound error propagation and deliver superior results on extended competition mathematics problems.
What carries the argument
The persistent Meta-Strategist, which maintains cross-attempt memory and supplies high-level strategic guidance or mandatory directives to steer the Reasoner-Verifier pairs out of unproductive loops.
If this is right
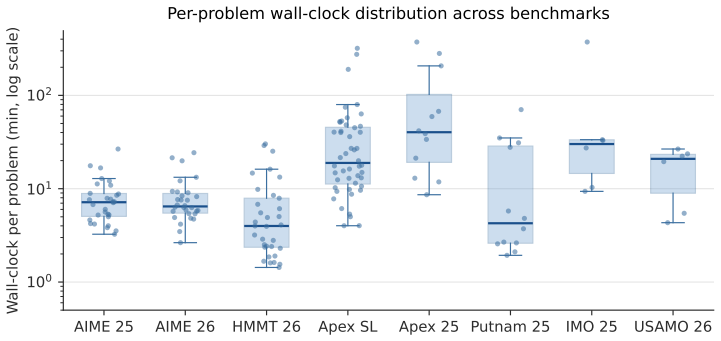
- The framework produces perfect scores on AIME, Putnam, and HMMT 2025-2026 problems.
- The largest reported margin appears on MathArena Apex 2025, where the system scores 93.75 percent against 80.21 percent for the strongest baseline.
- Ablations confirm that removing key orchestration components or swapping backbones reduces results, pointing to the structure as the source of gains.
- The design separates control flow from inference through a reasoning-free orchestrator that enables trace-back and re-planning.
Where Pith is reading between the lines
- The same separation of meta-control from inference steps could be tested on non-math tasks that also require sustained multi-step planning.
- Persistent memory across attempts might be adapted to domains where agents must learn from prior failed trajectories rather than resetting each time.
- If the Meta-Strategist can issue directives without calling the underlying models, the approach may lower overall inference cost on long problems.
Load-bearing premise
The meta-level supervision and structured replanning loops can reliably prevent error accumulation without themselves introducing new inconsistencies or excessive overhead.
What would settle it
Measure performance on the same eight benchmarks with the Meta-Strategist component removed or disabled; a large drop relative to the full system would support the claim, while little or no change would indicate the orchestration is not the decisive factor.
Figures



read the original abstract
Frontier AI models and multi-agent systems have led to significant improvements in mathematical reasoning. However, for problems requiring extended, long-horizon reasoning, existing systems continue to suffer from fundamental reliability issues: hallucination accumulation, memory fragmentation, and imbalanced reasoning-tool trade-offs. In this paper, we introduce STAR-P\'olyaMath, a multi-agent framework that systematically addresses these challenges through meta-level supervision and structured Reasoner-Verifier interaction. STAR-P\'olyaMath is structured as an orchestrated state machine with nested challenge-step-replan loops, governed by a reasoning-free Python orchestrator that separates control from inference and bounds error propagation through trace-back and re-planning. Our key innovation is a persistent Meta-Strategist that maintains cross-attempt memory and exercises meta-level control by issuing high-level strategic guidance or mandatory directives, so the system can escape unproductive loops rather than stagnate or over-rely on tools. STAR-P\'olyaMath achieves state-of-the-art results on all eight top-tier competition benchmarks: AIME 2025-2026, MathArena Apex Shortlist, MathArena Apex 2025, Putnam 2025, IMO 2025, HMMT February 2026, and USAMO 2026. It obtains perfect scores on AIMEs, Putnam, and HMMT, and shows its largest margin on Apex 2025, scoring 93.75% compared with 80.21% by the strongest baseline GPT-5.5. Ablation studies show that the gains arise from the framework's orchestration rather than from model-level diversity since removing key components or substituting in mixed backbones consistently weakens performance. Code is available at https://github.com/Julius-Woo/STAR-PolyaMath.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STAR-PólyaMath, a multi-agent framework for long-horizon mathematical reasoning. It features a reasoning-free Python orchestrator implementing nested challenge-step-replan loops, trace-back mechanisms, and a persistent Meta-Strategist that maintains cross-attempt memory and issues high-level strategic guidance or mandatory directives. The central empirical claim is state-of-the-art performance across eight competition benchmarks (AIME 2025-2026, MathArena Apex Shortlist, MathArena Apex 2025, Putnam 2025, IMO 2025, HMMT February 2026, USAMO 2026), including perfect scores on AIME, Putnam, and HMMT, with the largest margin on Apex 2025 (93.75% vs. 80.21% for GPT-5.5). Ablation studies are presented to attribute gains to the orchestration framework rather than model diversity.
Significance. If the performance claims and ablation attributions hold under detailed scrutiny, the work offers a concrete architecture for bounding error propagation and escaping unproductive loops in multi-agent reasoning systems. The separation of control logic into a reasoning-free orchestrator and the explicit cross-attempt memory mechanism address documented failure modes (hallucination accumulation, memory fragmentation) in a reproducible way; the public code release further strengthens the contribution by enabling direct replication and extension.
major comments (3)
- Ablation studies section: the statement that 'removing key components or substituting in mixed backbones consistently weakens performance' does not report whether the Persistent Meta-Strategist itself was ablated, held fixed at full strength, or replaced by a weaker model in the mixed-backbone runs. Because the central claim attributes gains to 'framework orchestration' rather than raw model capability, this omission is load-bearing; the skeptic note correctly identifies that any strategic directive must originate from an LLM component, so the current ablation design leaves open the possibility that observed improvements still trace to frontier-model strength rather than the nested meta-strategic structure.
- Methods / Experimental Setup: the manuscript does not specify the number of independent attempts, the exact prompting templates used by the Meta-Strategist, or the failure criteria that trigger re-planning versus mandatory directives. These details are required to evaluate whether the reported perfect scores on AIME/Putnam/HMMT reflect genuine escape from loops or simply higher per-attempt success rates of the underlying model.
- Results on MathArena Apex 2025: the 13.54-point margin over GPT-5.5 is the largest reported; however, without an error breakdown (e.g., percentage of problems solved only after Meta-Strategist intervention versus solved on first attempt), it is impossible to quantify how much of the margin is attributable to the persistent memory and meta-level control versus baseline model improvement.
minor comments (3)
- Abstract: the list of eight benchmarks appears to enumerate seven distinct contests (AIME 2025-2026 may be intended as two separate years); clarify the exact count and provide a table mapping each benchmark to its reported score and baseline.
- Notation: the term 'reasoning-free Python orchestrator' is used repeatedly but never formally defined; a short pseudocode block or state-machine diagram in §3 would remove ambiguity about which decisions are made outside any LLM call.
- Figure clarity: the state-machine diagram (if present) should explicitly label the trace-back and re-planning edges so readers can map them to the error-bounding claim in the abstract.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments on our manuscript. We address each of the major comments point by point below and describe the revisions we intend to make.
read point-by-point responses
-
Referee: [—] Ablation studies section: the statement that 'removing key components or substituting in mixed backbones consistently weakens performance' does not report whether the Persistent Meta-Strategist itself was ablated, held fixed at full strength, or replaced by a weaker model in the mixed-backbone runs. Because the central claim attributes gains to 'framework orchestration' rather than raw model capability, this omission is load-bearing; the skeptic note correctly identifies that any strategic directive must originate from an LLM component, so the current ablation design leaves open the possibility that observed improvements still trace to frontier-model strength rather than the nested meta-strategic structure.
Authors: The referee correctly notes that the current description does not specify the status of the Persistent Meta-Strategist in the ablations. We will revise the Ablation studies section to report in detail the configurations used for the Meta-Strategist across the ablation runs, including cases where it was ablated or replaced by weaker models. This revision will directly address the concern about whether improvements trace to the nested meta-strategic structure. revision: yes
-
Referee: [—] Methods / Experimental Setup: the manuscript does not specify the number of independent attempts, the exact prompting templates used by the Meta-Strategist, or the failure criteria that trigger re-planning versus mandatory directives. These details are required to evaluate whether the reported perfect scores on AIME/Putnam/HMMT reflect genuine escape from loops or simply higher per-attempt success rates of the underlying model.
Authors: We thank the referee for pointing out these omissions, which are important for reproducibility and for distinguishing the effects of the framework from baseline model performance. We will update the Methods / Experimental Setup section to include the number of independent attempts, the exact prompting templates for the Meta-Strategist, and the specific failure criteria that trigger re-planning versus mandatory directives. These details will be added to the main text or as supplementary material to allow readers to better evaluate the reported results. revision: yes
-
Referee: [—] Results on MathArena Apex 2025: the 13.54-point margin over GPT-5.5 is the largest reported; however, without an error breakdown (e.g., percentage of problems solved only after Meta-Strategist intervention versus solved on first attempt), it is impossible to quantify how much of the margin is attributable to the persistent memory and meta-level control versus baseline model improvement.
Authors: The referee makes a valid observation that an error breakdown would help quantify the contribution of the meta-level mechanisms to the performance margin on MathArena Apex 2025. We will incorporate such an analysis into the Results section, providing a breakdown of problems solved with and without Meta-Strategist intervention. This will offer a more precise attribution of the 13.54-point margin. revision: yes
Circularity Check
No circularity: empirical benchmark claims rest on external comparisons
full rationale
The paper introduces a multi-agent framework (STAR-PólyaMath) with a reasoning-free Python orchestrator and persistent Meta-Strategist, then reports direct empirical results on eight external competition benchmarks (AIME, Putnam, IMO, etc.) plus ablation studies. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the manuscript. Central claims are falsifiable against public benchmarks and do not reduce to inputs by construction; ablations compare against mixed backbones and component removals without self-referential fitting. This is a standard empirical systems paper whose performance assertions are independent of any internal derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Persistent Meta-Strategist
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ablation studies show that the gains arise from the framework's orchestration rather than from model-level diversity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
OpenAI. Introducing GPT-5.2. https://openai.com/index/introducing-gpt-5-2/ , 2025
work page 2025
-
[2]
Google DeepMind. Gemini 3 pro. https://deepmind.google/models/gemini/pro/, 2025
work page 2025
-
[3]
Jasper Dekoninck, Ivo Petrov, Kristian Minchev, Mislav Balunovic, Martin Vechev, Miroslav Marinov, Maria Drencheva, Lyuba Konova, Milen Shumanov, Kaloyan Tsvetkov, et al. The open proof corpus: A large-scale study of LLM-generated mathematical proofs.arXiv preprint arXiv:2506.21621, 2025
-
[4]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, et al. FrontierMath: A benchmark for evaluating advanced mathematical reasoning in AI.arXiv preprint arXiv:2411.04872, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 24824–24837, 2022
work page 2022
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
The Lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The Lean 4 theorem prover and programming language. InInternational Conference on Automated Deduction (CADE), pages 625–635. Springer, 2021
work page 2021
-
[8]
doi:10.1038/s41586-025-09833-y , url =
Thomas Hubert, Remi Mehta, Laurent Sartran, et al. Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, 2025. doi: 10.1038/s41586-025-09833-y
-
[9]
doi:10.48550/arXiv.2512.17260 , url =
Jiangjie Chen, Wenxiang Chen, Jiacheng Du, Jinyi Hu, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Cheng Li, Zheng Yuan, et al. Seed-Prover 1.5: Mastering undergraduate-level theorem proving via learning from experience.arXiv preprint arXiv:2512.17260, 2025
-
[10]
ToRA: A tool-integrated reasoning agent for mathematical problem solving
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. ToRA: A tool-integrated reasoning agent for mathematical problem solving. InInterna- tional Conference on Learning Representations (ICLR), 2024. 10
work page 2024
-
[11]
PAL: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: Program-aided language models. InInternational Conference on Machine Learning (ICML), pages 10764–10799, 2023
work page 2023
-
[12]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xiny- ing Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[13]
MACM: Utilizing a multi-agent system for condition mining in solving complex mathematical problems
Bin Lei, Yi Zhang, Shan Zuo, Ali Payani, and Caiwen Ding. MACM: Utilizing a multi-agent system for condition mining in solving complex mathematical problems. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
- [14]
-
[15]
Bowman, Trevor Darrell, and Ethan Perez
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Trevor Darrell, and Ethan Perez. Debating with more persuasive LLMs leads to more truthful answers. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[16]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Sumanth Varambally, Thomas V oice, Yanchao Sun, Zhifeng Chen, Rose Yu, and Ke Ye. Hilbert: Recursively building formal proofs with informal reasoning.arXiv preprint arXiv:2509.22819, 2025
-
[18]
Toolorchestra: Elevating intelligence via efficient model and tool orchestration
Hongjin Su, Shizhe Diao, Ximing Lu, Mingjie Liu, Jiacheng Xu, Xin Dong, Yonggan Fu, Peter Belcak, Hanrong Ye, et al. ToolOrchestra: Elevating intelligence via efficient model and tool orchestration.arXiv preprint arXiv:2511.21689, 2025
- [19]
- [20]
-
[21]
To code or not to code? adaptive tool integration for math language models
Jiaheng Wang et al. To code or not to code? adaptive tool integration for math language models. arXiv preprint, 2025
work page 2025
-
[22]
Diverse inference and verification for advanced reasoning.arXiv preprint arXiv:2502.09955, 2025
Iddo Drori, Gaston Longhitano, Mao Mao, Seunghwan Hyun, Yuke Zhang, Sungjun Park, Zachary Meeks, Xin-Yu Zhang, and Ben Segev. Diverse inference and verification for advanced reasoning.arXiv preprint arXiv:2502.09955, 2025
-
[23]
Princeton University Press, 1945
George Pólya.How to Solve It: A New Aspect of Mathematical Method. Princeton University Press, 1945
work page 1945
-
[24]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[25]
Aojun Zhou, Ke Wang, Zimu Lu, Weikang Shi, Sichun Luo, Zipeng Qin, Shaoqing Lu, Anya Jia, Linqi Song, Mingjie Zhan, and Hongsheng Li. Solving challenging math word problems using GPT-4 code interpreter with code-based self-verification. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[26]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InInternational Conference on Machine Learning (ICML), 2024. 11
work page 2024
-
[27]
CAMEL: Communicative agents for "mind" exploration of large language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for "mind" exploration of large language model society. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
work page 2023
-
[28]
Sumeet Ramesh Motwani, Chandler Smith, Rocktim Jyoti Das, Rafael Rafailov, Ivan Laptev, Philip H. S. Torr, Fabio Pizzati, Ronald Clark, and Christian Schroeder de Witt. MALT: Improving reasoning with multi-agent LLM training. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[29]
ReMA: Learning to meta-think for LLMs with multi-agent reinforcement learning
Ziyu Wan, Yunxiang Li, Xiaoyu Wen, Yan Song, Hanjing Wang, Linyi Yang, Mark Schmidt, Jun Wang, Weinan Zhang, Shuyue Hu, and Ying Wen. ReMA: Learning to meta-think for LLMs with multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[30]
Self- refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Sy...
work page 2023
-
[31]
Proof or bluff? evaluating LLMs on 2025 USA math olympiad.arXiv preprint arXiv:2503.21934, 2025
Ivo Petrov, Jasper Dekoninck, Lyuben Baltadzhiev, Maria Drencheva, Kristian Minchev, Mislav Balunovi´c, Nikola Jovanovi´c, and Martin Vechev. Proof or bluff? evaluating LLMs on 2025 USA math olympiad.arXiv preprint arXiv:2503.21934, 2025
-
[32]
Trieu H. Trinh, Yuhuai Wu, Quoc V . Le, He He, and Thang Luong. Solving olympiad geometry without human demonstrations.Nature, 625:476–482, 2024
work page 2024
-
[33]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625:468–475, 2024
work page 2024
-
[34]
Agentic reasoning: A streamlined framework for enhancing LLM reasoning with agentic tools
Jingyuan Wu et al. Agentic reasoning: A streamlined framework for enhancing LLM reasoning with agentic tools. InProceedings of ACL, 2025
work page 2025
-
[35]
Math- Arena: Evaluating LLMs on uncontaminated math competitions, 2025
Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Math- Arena: Evaluating LLMs on uncontaminated math competitions, 2025
work page 2025
-
[36]
MathArena Apex: Uncon- quered final-answer problems, 2025
Jasper Dekoninck, Nikola Jovanovi´c, Ivo Petrov, and Martin Vechev. MathArena Apex: Uncon- quered final-answer problems, 2025. URLhttps://matharena.ai/apex/. A System Configuration and Budgets Runtime and Loop Bounds.Table 4 summarizes the hard limits governing the STAR-PólyaMath orchestrator. All timeouts apply to LLM inference and verification code exec...
work page 2025
-
[37]
Plan Creation: decompose the problem into 3-10 numbered steps
-
[38]
Step Execution: execute one step at a time with rigorous reasoning
-
[39]
Verification Tagging: tag every nontrivial claim with one of [verified] / [easy-verify] / [hard-verify]
-
[40]
Challenge Response: address the Verifier’s concerns with evidence
-
[41]
Code Execution: run code yourself to verify computational claims; do not propose code with [easy-verify] when you can run it. ## Verification Tags Load the ‘verification-tag-protocol‘ skill for full definitions. - [verified] - You actually ran code; report the real output. - [easy-verify] - Use only when you cannot run code yourself. - [hard-verify] - Log...
work page 2025
-
[42]
Fix the exact combinatorial model
-
[43]
Split the counts into inside and outside contributions
-
[44]
Find the correct candidate constant from fresh evidence
-
[45]
Prove the universal lower bound
-
[46]
Make the discharging proof independent of shape pathologies
-
[47]
Construct polygons approaching equality
-
[48]
Conclude sharpness and the largest value. Step 3 (new candidate).Re-running candidate search on a denser 4×4 motif (rows#.#.,####, #.#.,....) tiledn×nproduced a1 = 9n, a 2 = 4n 2 −n, a 3 = 8n 2 −n, and forn= 50the ratio is208/399≈0.5213— already well below3/4atn= 5. Step 4 (cap-map proof).The verified lemmas establishing a3 ≤a 1 + 2a2 are recorded in the ...
work page 2025
-
[49]
Recast the grid condition exactly. 23
-
[50]
Replace tilings by a rectilinear-geometry invariant
-
[51]
Specialize good chords to permutation geometry
-
[52]
Translate chord selection into a bipartite matching problem
-
[53]
Independently search for the extremal construction
-
[54]
Prove the construction’s upper bound geometrically
-
[55]
Prove the matching lower bound for every permutation
-
[56]
Assemble the final equality. Reformulation phase (Steps 1–3).Step 1 establishes that any valid configuration has uncovered set Uπ ={(i, π(i)) : 1≤i≤2025} for some permutation π∈S 2025, and conversely; the problem reduces to minπ T(π) , where T(π) is the minimum number of rectangles partitioning the complement ofU π. Step 2 entered a multi-round debate. Th...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.