FineBench: Benchmarking and Enhancing Vision-Language Models for Fine-grained Human Activity Understanding
Pith reviewed 2026-05-20 06:03 UTC · model grok-4.3
The pith
Open-source vision-language models underperform on fine-grained human activity understanding in videos, but FineAgent boosts their performance on the FineBench benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
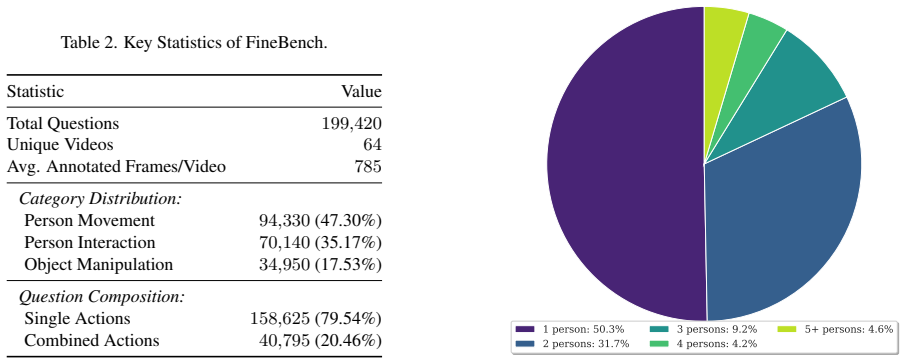
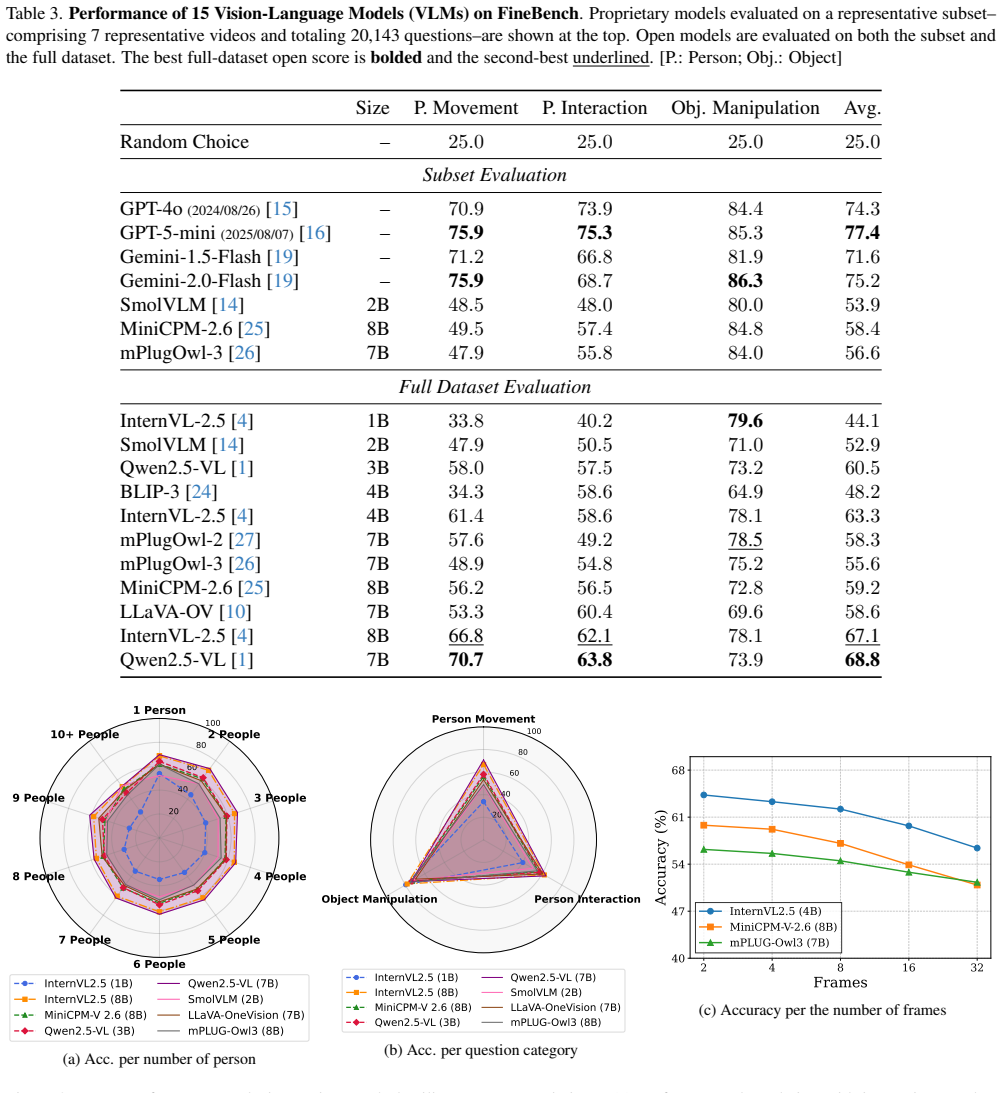
FineBench is introduced as a human-centric video VQA benchmark with 199,420 multiple-choice QA pairs across 64 long-form videos of about 15 minutes each, with dense annotations on person movement, interaction, and object manipulation including compositional actions. The paper's evaluations show that while proprietary models achieve respectable performance, current open-source VLMs significantly underperform, with particular difficulties in spatial reasoning within multi-person scenes and in distinguishing subtle differences in human movements and interactions. To mitigate these issues, FineAgent is proposed as a modular framework that enhances VLMs through a Localizer and a Descriptor, and 1
What carries the argument
FineBench, the densely annotated long-form video VQA benchmark focused on fine-grained human activities with frame-level spatial and temporal grounding, and FineAgent, the modular framework that uses a Localizer to identify relevant video regions and a Descriptor to generate detailed descriptions for improved VLM reasoning.
Load-bearing premise
The benchmark's dense annotations and multiple-choice questions accurately measure genuine fine-grained understanding rather than rewarding superficial correlations or annotation artifacts.
What would settle it
A finding that FineAgent-enhanced models excel on FineBench but show no improvement when tested on independently annotated videos depicting similar fine-grained human activities would challenge whether the benchmark truly captures general understanding.
Figures


read the original abstract
Vision-Language Models (VLMs) have demonstrated remarkable capabilities in general video understanding, yet they often struggle with the fine-grained comprehension crucial for real-world applications requiring nuanced interpretation of human actions and interactions. While some recent human-centric benchmarks evaluate aspects of model behaviour such as fairness/ethics, emotion perception, and broader human-centric metrics, they do not combine long-form videos, very dense QA coverage, and frame-level spatial/temporal grounding at scale. To bridge this gap, we introduce FineBench, a human-centric video question answering (VQA) benchmark specifically designed to assess fine-grained understanding. FineBench comprises 199,420 multiple-choice QA pairs densely annotated across 64 long-form videos (15 minutes each), focusing on detailed person movement, person interaction, and object manipulation, including compositional actions. Our extensive evaluation reveals that while proprietary models like GPT-5 achieve respectable performance, current open-source VLMs significantly underperform, struggling particularly with spatial reasoning in multi-person scenes and distinguishing subtle differences in human movements and interactions. To address these identified weaknesses, we propose FineAgent, a modular framework that enhances VLMs by leveraging a Localizer and a Descriptor. Experiments show that FineAgent consistently improves the performance of various open VLMs on FineBench. FineBench provides a rigorous testbed for future research into fine-grained human-centric video understanding, while FineAgent offers a practical approach to enhance such reasoning in current VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FineBench, a human-centric VQA benchmark with 199,420 densely annotated multiple-choice QA pairs across 64 long-form (15-minute) videos, targeting fine-grained aspects of person movement, interactions, and object manipulation. It reports that proprietary VLMs (e.g., GPT-5) achieve respectable results while open-source VLMs underperform, especially on spatial reasoning in multi-person scenes and subtle movement distinctions. To address these gaps, the authors propose FineAgent, a modular framework using a Localizer and Descriptor that yields consistent gains across several open VLMs on the benchmark.
Significance. If the benchmark questions genuinely require frame-level visual reasoning rather than linguistic priors, FineBench could serve as a useful large-scale testbed for fine-grained human activity understanding, an area relevant to applications such as robotics and surveillance. FineAgent provides a practical, modular enhancement strategy that avoids full model retraining. The work's value depends on verification that performance gaps reflect visual deficits.
major comments (1)
- Evaluation section / abstract: The claim that open-source VLMs 'significantly underperform' and 'struggle particularly with spatial reasoning in multi-person scenes' (abstract) rests on the premise that the 199k QA pairs test visual fine-grained understanding. No text-only baseline (e.g., GPT-4 or Llama-3 answering from question text + options without video) is reported. This is load-bearing; if a language-only model exceeds chance substantially, the reported deficits and FineAgent gains (via Localizer+Descriptor) could reflect annotation artifacts or common-sense leakage instead of genuine visual limitations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern about verifying that FineBench truly evaluates visual fine-grained understanding, rather than linguistic priors, is well-taken and we address it directly below.
read point-by-point responses
-
Referee: The claim that open-source VLMs 'significantly underperform' and 'struggle particularly with spatial reasoning in multi-person scenes' (abstract) rests on the premise that the 199k QA pairs test visual fine-grained understanding. No text-only baseline (e.g., GPT-4 or Llama-3 answering from question text + options without video) is reported. This is load-bearing; if a language-only model exceeds chance substantially, the reported deficits and FineAgent gains (via Localizer+Descriptor) could reflect annotation artifacts or common-sense leakage instead of genuine visual limitations.
Authors: We agree that explicitly demonstrating the visual nature of the benchmark is important. FineBench questions target fine-grained details such as precise hand-object interactions, subtle movement distinctions, and spatial configurations in multi-person scenes that are not reliably solvable from question text and common-sense reasoning alone. For example, many questions concern specific left/right distinctions or exact sequences of actions visible only in particular frames. Nevertheless, we acknowledge that including text-only baselines would provide stronger evidence against linguistic leakage. We will add these baselines (using Llama-3 and GPT-4 in text-only mode) to the evaluation section in the revised manuscript, expecting performance near chance on these fine-grained items. This addition will also clarify that FineAgent's gains stem from its visual localization and description modules rather than textual cues. revision: yes
Circularity Check
Empirical benchmark paper with no derivation chain or self-referential reduction
full rationale
The paper introduces FineBench as a new dataset of 199k QA pairs from 64 videos and evaluates existing VLMs plus a proposed FineAgent framework on it. All claims rest on fresh data collection, annotation, and model testing rather than any equation, fitted parameter, or prediction that reduces to the paper's own inputs. No self-citation is invoked as a load-bearing uniqueness theorem or ansatz; the work is self-contained against external benchmarks and does not rename known results or smuggle assumptions via prior self-work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FineBench comprises 199,420 multiple-choice QA pairs densely annotated across 64 long-form videos... focusing on detailed person movement, person interaction, and object manipulation
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FineAgent integrates two key components: a Localizer... and a Descriptor that generates frame summaries
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 3, 5, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, et al. Temporalbench: Benchmarking fine- grained temporal understanding for multimodal video mod- els.arXiv preprint arXiv:2410.10818, 2024. 2, 3
-
[3]
Yuxuan Cai, Jiangning Zhang, Zhenye Gan, Qingdong He, Xiaobin Hu, Junwei Zhu, Yabiao Wang, Chengjie Wang, Zhucun Xue, Xinwei He, et al. Hv-mmbench: Benchmark- ing mllms for human-centric video understanding.arXiv preprint arXiv:2507.04909, 2025. 3
-
[4]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 3, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM international conference on multimedia, pages 11198–11201, 2024. 5
work page 2024
-
[6]
Gueter Josmy Faure, Jia-Fong Yeh, Min-Hung Chen, Hung- Ting Su, Winston H. Hsu, and Shang-Hong Lai. Hermes: temporal-coherent long-form understanding with episodes and semantics, 2024. 3
work page 2024
-
[7]
Gueter Josmy Faure, Min-Hung Chen, Jia-Fong Yeh, Ying Cheng, Hung-Ting Su, Yung-Hao Tang, Shang-Hong Lai, and Winston H. Hsu. Moviecore: Cognitive reasoning in movies, 2025. 2
work page 2025
-
[8]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever compre- hensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Ava: A video dataset of spatio-temporally localized atomic visual actions
Chunhui Gu, Chen Sun, David A Ross, Carl V ondrick, Car- oline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6047–6056,
-
[10]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195– 22206, 2024. 2, 3
work page 2024
-
[12]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 3
work page 2023
-
[13]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding.Advances in Neural In- formation Processing Systems, 36:46212–46244, 2023. 2, 3
work page 2023
-
[14]
SmolVLM: Redefining small and efficient multimodal models
Andr ´es Marafioti, Orr Zohar, Miquel Farr ´e, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Hello gpt-4o.https : / / openai
OpenAI. Hello gpt-4o.https : / / openai . com / index/hello-gpt-4o/, 2024. [Accessed 01-11-2024]. 6
work page 2024
-
[16]
Introducing gpt-5.https://openai.com/ index/introducing- gpt- 5/, 2025
OpenAI. Introducing gpt-5.https://openai.com/ index/introducing- gpt- 5/, 2025. [Accessed 31- 08-2025]. 5, 6
work page 2025
-
[17]
Shaina Raza, Aravind Narayanan, Vahid Reza Khazaie, Ash- mal Vayani, Mukund S Chettiar, Amandeep Singh, Mubarak Shah, and Deval Pandya. Humanibench: A human-centric framework for large multimodal models evaluation.arXiv preprint arXiv:2505.11454, 2025. 2
-
[18]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024. 2, 3
work page 2024
-
[19]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv preprint arXiv:2403.05530, 2024. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Star: A benchmark for situated reasoning in real-world videos
Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. Star: A benchmark for situated reasoning in real-world videos. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2024. 2, 3
work page 2024
-
[21]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024. 3
work page 2024
-
[22]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9777–9786, 2021. 2, 3
work page 2021
-
[23]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016. 2, 3
work page 2016
-
[24]
xgen-mm (blip-3): A family of open large multimodal models.arXiv preprint arXiv:2408.08872, 2024
Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yu- tong Dai, Michael S Ryoo, et al. xgen-mm (blip-3): A family of open large multimodal models.arXiv preprint arXiv:2408.08872, 2024. 6
-
[25]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 3, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024. 3, 6, 8
work page internal anchor Pith review arXiv 2024
-
[27]
mplug- owl2: Revolutionizing multi-modal large language model with modality collaboration
Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, and Fei Huang. mplug- owl2: Revolutionizing multi-modal large language model with modality collaboration. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 13040–13051, 2024. 6
work page 2024
-
[28]
Activitynet-qa: A dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yuet- ing Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 9127–9134, 2019. 2, 3
work page 2019
-
[29]
Evf-sam: Early vision-language fusion for text-prompted segment anything model, 2024
Yuxuan Zhang, Tianheng Cheng, Lianghui Zhu, Rui Hu, Lei Liu, Heng Liu, Longjin Ran, Xiaoxin Chen, Wenyu Liu, and Xinggang Wang. Evf-sam: Early vision-language fusion for text-prompted segment anything model, 2024. 7
work page 2024
-
[30]
Ting Zhou, Daoyuan Chen, Qirui Jiao, Bolin Ding, Yaliang Li, and Ying Shen. Humanvbench: Exploring human-centric video understanding capabilities of mllms with synthetic benchmark data.arXiv preprint arXiv:2412.17574, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.