PromptRad: Knowledge-Enhanced Multi-Label Prompt-Tuning for Low-Resource Radiology Report Labeling
Pith reviewed 2026-05-21 07:49 UTC · model grok-4.3
The pith
PromptRad labels radiology reports accurately with prompt-tuning and medical synonyms using only 32 examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PromptRad reformulates multi-label classification as masked language modeling and incorporates synonyms from the UMLS Metathesaurus into a multi-word verbalizer to enrich category representations. By fine-tuning the PLM without additional classification layers, PromptRad requires substantially less labeled data than conventional fine-tuning. On liver CT reports it outperforms dictionary-based and fine-tuning baselines with only 32 labeled training examples and achieves competitive performance with GPT-4 despite using a much smaller model.
What carries the argument
Multi-word verbalizer augmented with UMLS synonyms, which supplies enriched prompt tokens so the model can perform masked-language-modeling-style prediction over clinical categories.
If this is right
- The method achieves strong multi-label accuracy on liver CT reports with only 32 labeled examples.
- It matches or approaches GPT-4 performance while using a far smaller model.
- It handles complex negation patterns better than dictionary or standard fine-tuning approaches.
- No extra classification head is needed, so the same pre-trained language model serves both prompting and prediction.
Where Pith is reading between the lines
- The same verbalizer enrichment could be tested on other report types such as chest X-ray or pathology notes to check cross-domain transfer.
- Replacing the fixed UMLS synonym list with a learned or context-aware synonym selector might further reduce noise on rare findings.
- Because the approach stays within the original language-model head, it could be combined with retrieval-augmented prompts to handle even scarcer data regimes.
Load-bearing premise
Adding UMLS synonyms to the multi-word verbalizer reliably enriches category representations without introducing noise or conflicting signals on negation and rare findings.
What would settle it
A controlled run on the same liver CT test set in which the UMLS synonyms are removed from the verbalizer and performance on negation-heavy or low-frequency findings drops sharply below the reported baseline.
Figures



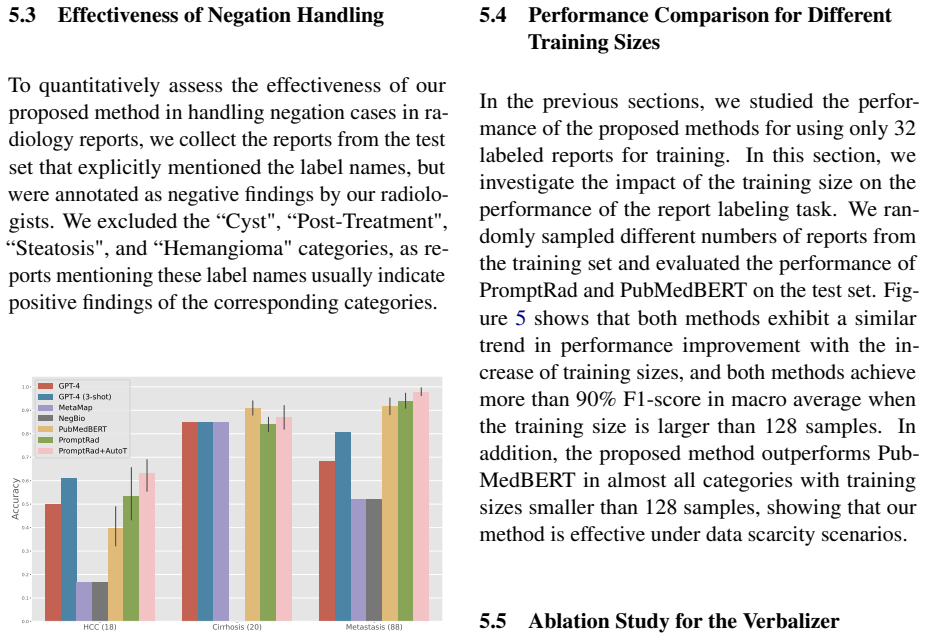
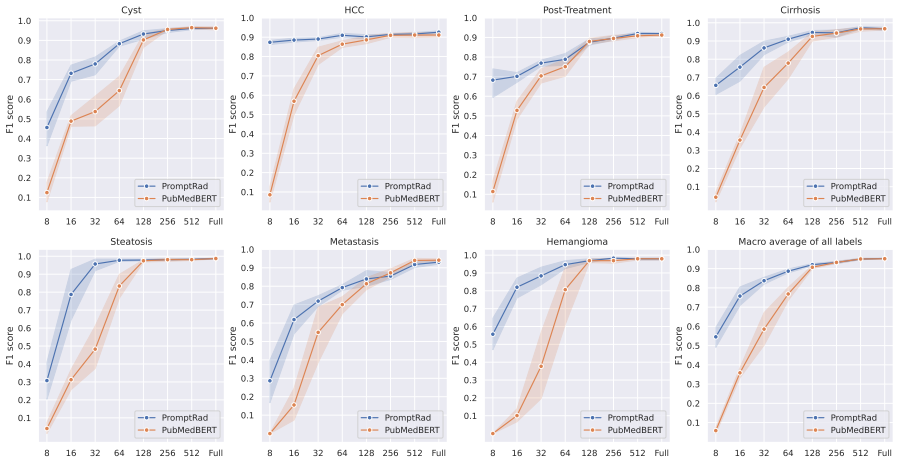
read the original abstract
Automatic report labeling facilitates the identification of clinical findings from unstructured text and enables large-scale annotation for medical imaging research. Existing rule-based labelers struggle with the diverse descriptions in clinical reports, while fine-tuning pre-trained language models (PLMs) requires large amounts of labeled data that are often unavailable in clinical settings. In this paper, we propose PromptRad, a knowledge-enhanced multi-label \textbf{prompt}-tuning approach for \textbf{rad}iology report labeling under low-resource settings. PromptRad reformulates multi-label classification as masked language modeling and incorporates synonyms from the UMLS Metathesaurus into a multi-word verbalizer to enrich category representations. By fine-tuning the PLM without additional classification layers, PromptRad requires substantially less labeled data than conventional fine-tuning. Experiments on liver CT (computed tomography) reports show that PromptRad outperforms dictionary-based and fine-tuning baselines with only 32 labeled training examples, and achieves competitive performance with GPT-4 despite using a much smaller model. Further analysis demonstrates that PromptRad captures complex negation patterns more effectively than existing methods, making it a promising solution for report labeling in data-scarce clinical scenarios. Our code is available at https://github.com/ila-lab/PromptRad.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PromptRad, a knowledge-enhanced multi-label prompt-tuning method for radiology report labeling in low-resource settings. It reformulates multi-label classification as masked language modeling and incorporates UMLS Metathesaurus synonyms into multi-word verbalizers to enrich category representations. Experiments on liver CT reports claim that PromptRad outperforms dictionary-based and fine-tuning baselines using only 32 labeled training examples, achieves competitive performance with GPT-4 using a smaller model, and handles complex negation patterns more effectively.
Significance. If the low-resource empirical gains prove robust, the work would be significant for clinical NLP by demonstrating a data-efficient alternative to full fine-tuning or large generative models in annotation-scarce medical domains. The integration of domain knowledge via UMLS into prompt verbalizers and the avoidance of additional classification layers address a practical bottleneck, and the reported competitiveness with GPT-4 highlights potential efficiency advantages.
major comments (2)
- [Experiments] Experiments section (liver CT results with 32 examples): The reported outperformance over dictionary and fine-tuning baselines is presented without averaging F1 or AUC over multiple independent draws of the 32-example training set or standard deviations across random seeds. This directly affects the central low-resource claim, as the observed margins could depend on a single fortunate split rather than the method's properties.
- [Method] Method section (UMLS verbalizer construction): The claim that adding UMLS synonyms reliably enriches category representations without introducing noise is load-bearing for the knowledge-enhancement contribution, yet no ablation isolates the multi-word verbalizer's effect on negation or rare findings, leaving the weakest assumption untested.
minor comments (2)
- [Abstract] Abstract: The statement that PromptRad 'captures complex negation patterns more effectively' lacks any mention of the specific metrics, examples, or analysis method used to support this post-hoc claim.
- [Method] The paper provides a code link but does not specify the exact prompt templates or verbalizer word lists in the main text, which would aid reproducibility of the multi-label prompt setup.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the suggested improvements where they strengthen the work.
read point-by-point responses
-
Referee: [Experiments] Experiments section (liver CT results with 32 examples): The reported outperformance over dictionary and fine-tuning baselines is presented without averaging F1 or AUC over multiple independent draws of the 32-example training set or standard deviations across random seeds. This directly affects the central low-resource claim, as the observed margins could depend on a single fortunate split rather than the method's properties.
Authors: We agree that the current single-split results for the 32-example setting limit the strength of the low-resource claims. In the revised manuscript we will sample five independent 32-example training sets using different random seeds, rerun all methods, and report mean F1 and AUC together with standard deviations. These results will be added to the Experiments section and to Table 2. revision: yes
-
Referee: [Method] Method section (UMLS verbalizer construction): The claim that adding UMLS synonyms reliably enriches category representations without introducing noise is load-bearing for the knowledge-enhancement contribution, yet no ablation isolates the multi-word verbalizer's effect on negation or rare findings, leaving the weakest assumption untested.
Authors: We acknowledge that an explicit ablation isolating the multi-word UMLS verbalizer would more directly test its contribution to negation handling and rare findings. In the revision we will add an ablation comparing the full PromptRad verbalizer against a single-word baseline and against a version without UMLS synonyms, with separate analysis on negated and rare-finding subsets. This will be included in the Method and Analysis sections. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The paper presents PromptRad as an empirical method that reformulates multi-label radiology report labeling as masked language modeling and augments a multi-word verbalizer with UMLS synonyms. All load-bearing results are experimental comparisons against dictionary and fine-tuning baselines on a fixed liver CT dataset using 32 examples. No equations or steps reduce by construction to fitted parameters renamed as predictions, no self-definitional loops appear in the method description, and no uniqueness theorems or ansatzes are imported via self-citation chains. The approach is self-contained against external benchmarks and does not rely on prior author work to justify its core construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- choice of prompt template and verbalizer words
axioms (1)
- domain assumption Masked language modeling objective can be directly used for multi-label classification without additional classification layers
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PromptRad reformulates multi-label classification as masked language modeling and incorporates synonyms from the UMLS Metathesaurus into a multi-word verbalizer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Chen, Matthew C. and Ball, Robyn L. and Yang, Lingyao and Moradzadeh, Nathaniel and Chapman, Brian E. and Larson, David B. and Langlotz, Curtis P. and Amrhein, Timothy J. and Lungren, Matthew P. , doi =. Deep Learning to Classify Radiology Free-Text Reports , url =. 2018 , bdsk-url-1 =. https://doi.org/10.1148/radiol.2017171115 , journal =
-
[9]
Pons, Ewoud and Braun, Loes M. M. and Hunink, M. G. Myriam and Kors, Jan A. , title =. Radiology , volume =. 2016 , doi =
work page 2016
-
[10]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[11]
On the Stratification of Multi-label Data , booktitle =
Sechidis, Konstantinos and Tsoumakas, Grigorios and Vlahavas, Ioannis , editor =. On the Stratification of Multi-label Data , booktitle =. 2011 , publisher =
work page 2011
-
[12]
SciFive: a text-to-text transformer model for biomedical literature , author =. 2021 , eprint =
work page 2021
-
[13]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , year =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and K\". PyTorch: An Imperative Style, High-Performance Deep Learning Library , year =. Proceedings of the 33rd International Conference on Neural Informa...
-
[14]
Transformers: State-of-the-Art Natural Language Processing , booktitle =
Transformers: State-of-the-Art Natural Language Processing , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , month = oct, year =. doi:10.18653/v1/2020.emnlp-demos.6 , pages =
-
[15]
XLNet: Generalized Autoregressive Pretraining for Language Understanding , url =
Yang, Zhilin and Dai, Zihang and Yang, Yiming and Carbonell, Jaime and Salakhutdinov, Russ R and Le, Quoc V , booktitle =. XLNet: Generalized Autoregressive Pretraining for Language Understanding , url =. 2019 , bdsk-url-1 =
work page 2019
-
[16]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf , title =. CoRR , volume =. 2019 , url =. 1910.01108 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , year =
-
[18]
The Unified Medical Language System (UMLS): integrating biomedical terminology , volume =
Olivier Bodenreider , doi =. The Unified Medical Language System (UMLS): integrating biomedical terminology , volume =. Nucleic Acids Research , month =
-
[19]
Gu, Yu and Tinn, Robert and Cheng, Hao and Lucas, Michael and Usuyama, Naoto and Liu, Xiaodong and Naumann, Tristan and Gao, Jianfeng and Poon, Hoifung , title =. ACM Trans. Comput. Healthcare , month =. 2021 , issue_date =. doi:10.1145/3458754 , abstract =
-
[20]
Jia Li and Yucong Lin and Pengfei Zhao and Wenjuan Liu and Linkun Cai and Jing Sun and Lei Zhao and Zhenghan Yang and Hong Song and Han Lv and Zhenchang Wang , doi =. Automatic text classification of actionable radiology reports of tinnitus patients using bidirectional encoder representations from transformer (BERT) and in-domain pre-training (IDPT) , vol...
-
[21]
Vincent M D’Anniballe and Fakrul Islam Tushar and Khrystyna Faryna and Songyue Han and Maciej A Mazurowski and Geoffrey D Rubin and Joseph Y Lo , doi =. Multi-label annotation of text reports from computed tomography of the chest, abdomen, and pelvis using deep learning , volume =. BMC Medical Informatics and Decision Making , pages =
-
[22]
Schick, Timo and Sch. It. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , month = jun, year =. doi:10.18653/v1/2021.naacl-main.185 , pages =
-
[23]
Tianyi Zhang and Felix Wu and Arzoo Katiyar and Kilian Q Weinberger and Yoav Artzi , booktitle =. Revisiting Few-sample. 2021 , url =
work page 2021
-
[24]
Jesse Dodge and Gabriel Ilharco and Roy Schwartz and Ali Farhadi and Hannaneh Hajishirzi and Noah A. Smith , title =. CoRR , volume =. 2020 , url =. 2002.06305 , timestamp =
-
[25]
Supervised and unsupervised language modelling in Chest X-Ray radiological reports , author=. Plos one , volume=. 2020 , publisher=
work page 2020
-
[26]
Transformer-based structuring of free-text radiology report databases , author=. European Radiology , volume=. 2023 , publisher=
work page 2023
-
[27]
Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference , author =. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , month = apr, year =. doi:10.18653/v1/2021.eacl-main.20 , pages =
-
[28]
Alsentzer, Emily and Murphy, John and Boag, William and Weng, Wei-Hung and Jindi, Di and Naumann, Tristan and McDermott, Matthew , booktitle =. Publicly Available Clinical. 2019 , address =. doi:10.18653/v1/W19-1909 , pages =
-
[29]
Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo , title =. Bioinformatics , volume =. 2019 , month =. doi:10.1093/bioinformatics/btz682 , url =
-
[30]
Proceedings of the Third Conference on Medical Imaging with Deep Learning , pages =
Automated Labelling using an Attention model for Radiology reports of MRI scans (ALARM) , author =. Proceedings of the Third Conference on Medical Imaging with Deep Learning , pages =. 2020 , editor =
work page 2020
-
[31]
Fredrik A Dahl and Taraka Rama and Petter Hurlen and Pål H Brekke and Haldor Husby and Tore Gundersen and Øystein Nytrø and Lilja Øvrelid , doi =. Neural classification of Norwegian radiology reports: using NLP to detect findings in CT-scans of children , volume =. BMC Medical Informatics and Decision Making , pages =
-
[32]
Transfer Learning in Biomedical Natural Language Processing: An Evaluation of
Peng, Yifan and Yan, Shankai and Lu, Zhiyong , booktitle =. Transfer Learning in Biomedical Natural Language Processing: An Evaluation of. 2019 , address =. doi:10.18653/v1/W19-5006 , pages =
-
[33]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[34]
Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using
Smit, Akshay and Jain, Saahil and Rajpurkar, Pranav and Pareek, Anuj and Ng, Andrew and Lungren, Matthew , booktitle =. Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using. 2020 , address =. doi:10.18653/v1/2020.emnlp-main.117 , pages =
-
[35]
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (
Convolutional Neural Networks for Sentence Classification , author =. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (. 2014 , address =. doi:10.3115/v1/D14-1181 , pages =
-
[36]
Proceedings of the 15th Conference of the
Very Deep Convolutional Networks for Text Classification , author =. Proceedings of the 15th Conference of the. 2017 , address =
work page 2017
-
[37]
X. Wang and Y. Peng and L. Lu and Z. Lu and M. Bagheri and R. M. Summers , booktitle =. ChestX-Ray8: Hospital-Scale Chest X-Ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases , year =. doi:10.1109/CVPR.2017.369 , url =
-
[38]
Wordpress: Luke Oakden Rayner , volume =
Exploring the ChestXray14 dataset: problems , author =. Wordpress: Luke Oakden Rayner , volume =
-
[39]
and Lee, Timothy and Choi, Jinho D
Shin, Bonggun and Chokshi, Falgun H. and Lee, Timothy and Choi, Jinho D. , booktitle =. Classification of radiology reports using neural attention models , year =
-
[40]
Chest radiograph interpretation with deep learning models: assessment with radiologist-adjudicated reference standards and population-adjusted evaluation , author =. Radiology , volume =. 2020 , publisher =
work page 2020
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison , volume =. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2019 , month =. doi:10.1609/aaai.v33i01.3301590 , abstractnote =
-
[42]
Medical image analysis , volume =
Padchest: A large chest x-ray image dataset with multi-label annotated reports , author =. Medical image analysis , volume =. 2020 , publisher =
work page 2020
-
[43]
Proceedings of the Third Conference on Medical Imaging with Deep Learning , pages =
On the limits of cross-domain generalization in automated X-ray prediction , author =. Proceedings of the Third Conference on Medical Imaging with Deep Learning , pages =. 2020 , editor =
work page 2020
-
[44]
Machine Learning for Healthcare Conference , pages =
Contrastive learning of medical visual representations from paired images and text , author =. Machine Learning for Healthcare Conference , pages =. 2022 , organization =
work page 2022
-
[45]
Proceedings of the 2019 Conference of the North
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , editor =. Proceedings of the 2019 Conference of the North. 2019 , address =. doi:10.18653/v1/N19-1423 , pages =
-
[46]
Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer
Deep Contextualized Word Representations , author =. Proceedings of the 2018 Conference of the North. 2018 , address =. doi:10.18653/v1/N18-1202 , pages =
-
[47]
ACM Transactions on Computing for Healthcare (HEALTH) , volume =
Domain-specific language model pretraining for biomedical natural language processing , author =. ACM Transactions on Computing for Healthcare (HEALTH) , volume =. 2021 , publisher =
work page 2021
-
[48]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =
work page 2019
-
[49]
Mednli-a natural language inference dataset for the clinical domain , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium. Association for Computational Linguistics , pages =
work page 2018
-
[50]
BIOSSES: a semantic sentence similarity estimation system for the biomedical domain , author =. Bioinformatics , volume =. 2017 , publisher =
work page 2017
-
[51]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author =. arXiv preprint arXiv:1907.11692 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[52]
Majkowska, Anna and Mittal, Sid and Steiner, David F. and Reicher, Joshua J. and McKinney, Scott Mayer and Duggan, Gavin E. and Eswaran, Krish and Cameron Chen, Po-Hsuan and Liu, Yun and Kalidindi, Sreenivasa Raju and Ding, Alexander and Corrado, Greg S. and Tse, Daniel and Shetty, Shravya , title =. Radiology , volume =. 2020 , doi =. https://doi.org/10....
-
[53]
PadChest: A large chest x-ray image dataset with multi-label annotated reports , journal =
Aurelia Bustos and Antonio Pertusa and Jose-Maria Salinas and Maria. PadChest: A large chest x-ray image dataset with multi-label annotated reports , journal =. 2020 , issn =. doi:https://doi.org/10.1016/j.media.2020.101797 , url =
-
[54]
Wordpress: Luke Oakden Rayner , month =
Oakden-Rayner, Luke , title =. Wordpress: Luke Oakden Rayner , month =
-
[55]
Bulletin of the Medical Library Association , volume =
Medical subject headings (MeSH) , author =. Bulletin of the Medical Library Association , volume =. 2000 , publisher =
work page 2000
-
[56]
Proceedings of the National Academy of Sciences , volume =
PubMed Central: The GenBank of the published literature , author =. Proceedings of the National Academy of Sciences , volume =. 2001 , publisher =
work page 2001
- [57]
-
[58]
Proceedings of the 11th International Workshop on Semantic Evaluation (
Cer, Daniel and Diab, Mona and Agirre, Eneko and Lopez-Gazpio, I. Proceedings of the 11th International Workshop on Semantic Evaluation (. 2017 , address =. doi:10.18653/v1/S17-2001 , pages =
-
[59]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[60]
Training language models to follow instructions with human feedback , url =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[61]
Making Pre-trained Language Models Better Few-shot Learners , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2021.acl-long.295 , pages =
-
[62]
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
Hu, Shengding and Ding, Ning and Wang, Huadong and Liu, Zhiyuan and Wang, Jingang and Li, Juanzi and Wu, Wei and Sun, Maosong. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.186...
-
[63]
Liu, Pengfei and Yuan, Weizhe and Fu, Jinlan and Jiang, Zhengbao and Hayashi, Hiroaki and Neubig, Graham , title =. ACM Comput. Surv. , month =. 2023 , issue_date =. doi:10.1145/3560815 , abstract =
-
[64]
Logan IV and Eric Wallace and Sameer Singh , title =
Taylor Shin and Yasaman Razeghi and Robert L. Logan IV and Eric Wallace and Sameer Singh , title =. Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[65]
Factual Probing Is [MASK]: Learning vs. Learning to Recall , author =. North American Association for Computational Linguistics (NAACL) , year =
-
[66]
Effective mapping of biomedical text to the UMLS Metathesaurus: the MetaMap program , author =. 2001 , journal =
work page 2001
-
[67]
Any domain parsing: automatic domain adaptation for natural language parsing , author=. 2010 , publisher=
work page 2010
-
[68]
NegBio: a high-performance tool for negation and uncertainty detection in radiology reports , author =. 2018 , journal =
work page 2018
-
[69]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2021.acl-long.353 , pages =
- [70]
-
[71]
Long short-term memory , author =. Neural Computation , volume =. 1997 , publisher =
work page 1997
-
[72]
Fytas, Panagiotis and Breger, Anna and Selby, Ian and Baker, Simon and Shahipasand, Shahab and Korhonen, Anna. Can Rule-Based Insights Enhance LLM s for Radiology Report Classification? Introducing the R ad P rompt Methodology. Proceedings of the 23rd Workshop on Biomedical Natural Language Processing. 2024. doi:10.18653/v1/2024.bionlp-1.17
-
[73]
Abdullah, Abdullah and Kim, Seong Tae. Automated Radiology Report Labeling in Chest X-Ray Pathologies: Development and Evaluation of a Large Language Model Framework. JMIR Med Inform. 2025. doi:10.2196/68618
-
[74]
Radiology-Llama2: Best-in-Class Large Language Model for Radiology , author=. 2023 , eprint=
work page 2023
-
[75]
CheX-GPT: Harnessing Large Language Models for Enhanced Chest X-ray Report Labeling , author=. 2024 , eprint=
work page 2024
- [76]
- [77]
-
[78]
Wei, Liting and Li, Yun and Zhu, Yi and Li, Bin and Zhang, Lejun , TITLE =. Applied Sciences , VOLUME =. 2022 , NUMBER =
work page 2022
-
[79]
Wu, Yu-Hsuan and Lin, Ying-Jia and Kao, Hung-Yu. IKM \_ L ab at B io L ay S umm Task 1: Longformer-based Prompt Tuning for Biomedical Lay Summary Generation. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks. 2023. doi:10.18653/v1/2023.bionlp-1.64
-
[80]
Journal of Healthcare Informatics Research , author =
Prompt. Journal of Healthcare Informatics Research , author =. 2024 , pages =. doi:10.1007/s41666-024-00162-9 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.