Accelerating Video Inverse Problem Solvers with Autoregressive Diffusion Models
Pith reviewed 2026-05-21 06:09 UTC · model grok-4.3
The pith
Autoregressive diffusion models restore videos chunk by chunk to eliminate initial latency and raise throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
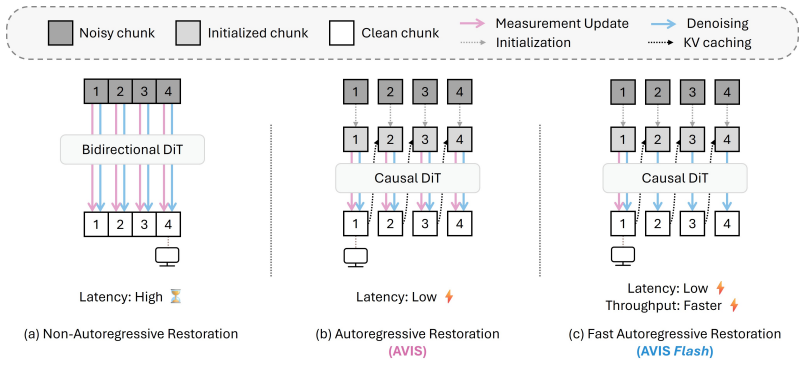
AVIS restores videos autoregressively by processing successive chunks with an autoregressive video diffusion model whose reverse diffusion is initialized by a measurement-consistent estimate, thereby removing holistic latency and reducing sampling steps while preserving restoration quality.
What carries the argument
Autoregressive chunk-wise processing with measurement-consistent initialization of the reverse diffusion process.
If this is right
- Initial latency falls from 114 s to 4 s.
- Throughput rises from 0.71 FPS to 1.18 FPS with better restoration quality than non-autoregressive baselines.
- AVIS Flash reaches 5.91 FPS on a single RTX 4090 GPU by enforcing consistency only on the opening chunk.
- The method offers a practical efficiency-quality trade-off that supports real-time deployment.
Where Pith is reading between the lines
- The same chunk-wise streaming pattern could be tested on other sequential inverse problems such as audio or sensor-data restoration.
- Adaptive chunk lengths might further improve the latency-throughput curve for videos of varying motion complexity.
- Hardware-specific optimizations of the first-chunk consistency step could push frame rates higher on edge devices.
Load-bearing premise
That processing successive video chunks autoregressively with measurement-consistent initialization keeps temporal consistency and quality intact across chunk boundaries in long videos.
What would settle it
A long video restored by AVIS that exhibits visible temporal drift or artifacts exactly at the points where chunks meet.
Figures








read the original abstract
Diffusion models provide powerful priors for zero-shot video inverse problems, but their real-time deployment is hindered by two inefficiencies: high initial latency caused by holistic video restoration, and low throughput resulting from multiple VAE passes to enforce measurement consistency in pixel space. To overcome these limitations, we propose Autoregressive Video Inverse problem Solver (AVIS). The AVIS framework leverages autoregressive video diffusion models to restore videos in a streaming manner, naturally eliminating latency bottlenecks. Specifically, AVIS initializes reverse diffusion with a measurement-consistent estimate, reducing the required sampling steps. Compared to leading non-autoregressive solvers, AVIS drastically reduces initial latency from 114s to 4s and increases throughput from 0.71 to 1.18 FPS while achieving superior restoration quality. We further introduce a highly accelerated variant, dubbed AVIS Flash, that enforces measurement consistency solely on the first chunk. AVIS Flash substantially boosts throughput to 5.91 FPS on a single RTX 4090 GPU while maintaining competitive performance and achieving a favorable efficiency-performance trade-off, paving the way toward real-time deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Autoregressive Video Inverse problem Solver (AVIS) that leverages autoregressive video diffusion models to restore videos in a streaming manner. This eliminates holistic-video latency bottlenecks and reduces VAE passes for measurement consistency. AVIS reports reducing initial latency from 114s to 4s and raising throughput from 0.71 to 1.18 FPS versus leading non-autoregressive solvers while improving restoration quality. AVIS Flash further accelerates by enforcing measurement consistency only on the first chunk, reaching 5.91 FPS on an RTX 4090 with competitive performance.
Significance. If the performance claims hold under rigorous verification, the work would meaningfully advance practical deployment of diffusion priors for video inverse problems by enabling low-latency streaming inference. The reported order-of-magnitude latency reduction and FPS gains on consumer hardware represent a concrete step toward real-time video restoration pipelines.
major comments (1)
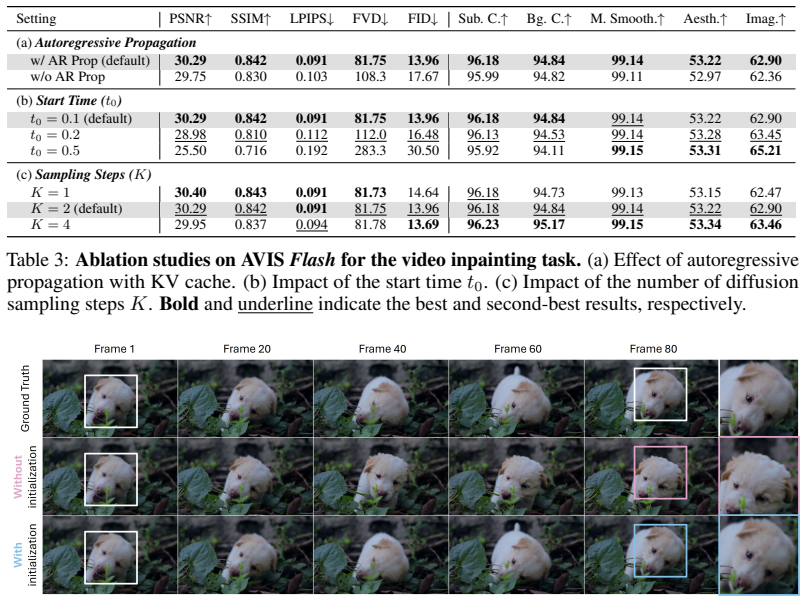
- [AVIS Flash description] The central speedup claim for AVIS Flash rests on enforcing measurement consistency only on the first chunk while autoregressively generating subsequent chunks. This implicitly assumes that the diffusion prior plus the initial consistent seed is sufficient to prevent drift or boundary artifacts over many chunks. For video inverse problems, even small per-chunk deviations from the measurement can compound temporally; the abstract reports competitive performance but provides no quantitative check (e.g., per-chunk PSNR decay or optical-flow consistency scores) on sequences longer than the training chunk length.
minor comments (2)
- [Abstract] The abstract should explicitly state the video resolutions, lengths, and inverse-problem tasks (denoising, deblurring, etc.) used to obtain the 114 s / 0.71 FPS baseline numbers.
- [Abstract] Clarify the precise hardware configuration and batching details for all reported FPS figures to enable direct reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the significance of our work and for the constructive major comment. We address the concern point by point below and outline the planned revisions.
read point-by-point responses
-
Referee: The central speedup claim for AVIS Flash rests on enforcing measurement consistency only on the first chunk while autoregressively generating subsequent chunks. This implicitly assumes that the diffusion prior plus the initial consistent seed is sufficient to prevent drift or boundary artifacts over many chunks. For video inverse problems, even small per-chunk deviations from the measurement can compound temporally; the abstract reports competitive performance but provides no quantitative check (e.g., per-chunk PSNR decay or optical-flow consistency scores) on sequences longer than the training chunk length.
Authors: We agree that explicit quantitative verification of temporal stability is important for the AVIS Flash variant. The current manuscript reports overall competitive performance on standard benchmarks but does not include per-chunk PSNR decay curves or optical-flow consistency metrics specifically for sequences exceeding the training chunk length. In the revised version we will add these analyses on long video sequences (e.g., 100+ frames) to quantify any drift or boundary artifacts and to demonstrate that the autoregressive diffusion prior combined with the initial consistent seed maintains measurement fidelity over time. revision: yes
Circularity Check
No significant circularity; claims rest on external baselines and standard priors
full rationale
The paper's core claims concern empirical speedups (latency from 114s to 4s, throughput to 1.18 FPS or 5.91 FPS for AVIS Flash) measured against leading non-autoregressive solvers on external benchmarks. These are not derived by fitting parameters to the target metrics or by renaming inputs as predictions. The autoregressive chunk-wise initialization and measurement consistency enforcement are presented as engineering choices leveraging existing diffusion priors, without reducing the reported performance gains to quantities defined inside the paper itself. No load-bearing self-citation chain or uniqueness theorem is invoked to force the architecture. The derivation chain is therefore self-contained against external validation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AVIS initializes reverse diffusion with a measurement-consistent estimate... AVIS Flash enforces measurement consistency solely on the first chunk
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
autoregressive video diffusion models... KV cache... periodic re-injection of measurement consistency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
work page 2020
-
[2]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2020
work page 2020
-
[3]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[4]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[5]
Jonathan Ho, Tim Salimans, Alexey A Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. InICLR Workshop on Deep Generative Models for Highly Structured Data, 2022
work page 2022
-
[6]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=di52zR8xgf
work page 2024
-
[7]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://arxiv.org/abs/2209.03003
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
-
[10]
Pascal Chang, Jingwei Tang, Markus Gross, and Vinicius C. Azevedo. How i warped your noise: a temporally-correlated noise prior for diffusion models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=pzElnMrgSD
work page 2024
-
[11]
Warped diffusion: Solving video inverse problems with image diffusion models
Giannis Daras, Weili Nie, Karsten Kreis, Alexandros G Dimakis, Morteza Mardani, Nikola B Kovachki, and Arash Vahdat. Warped diffusion: Solving video inverse problems with image diffusion models. Advances in Neural Information Processing Systems, 37:101116–101143, 2024
work page 2024
-
[12]
Solving video inverse problems using image diffusion models
Taesung Kwon and Jong Chul Ye. Solving video inverse problems using image diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=TRWxFUzK9K
work page 2025
-
[13]
Vision-xl: High definition video inverse problem solver using latent image diffusion models
Taesung Kwon and Jong Chul Ye. Vision-xl: High definition video inverse problem solver using latent image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10465–10474, 2025
work page 2025
-
[14]
Taesung Kwon, Gookho Song, Yoosun Kim, Jeongsol Kim, Jong Chul Ye, and Mooseok Jang. Video diffusion posterior sampling for seeing beyond dynamic scattering layers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[15]
LVTINO: LAtent video consistency INverse solver for high definition video restoration
Alessio Spagnoletti, Andres Almansa, and Marcelo Pereyra. LVTINO: LAtent video consistency INverse solver for high definition video restoration. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=8SyEcWVe10
work page 2026
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
Silo: Solving inverse problems with latent operators
Ron Raphaeli, Sean Man, and Michael Elad. Silo: Solving inverse problems with latent operators. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10570–10580, 2025
work page 2025
-
[23]
Yeobin Hong, Suhyeon Lee, Hyungjin Chung, and Jong Chul Ye. Inversecrafter: Efficient video recapture as a latent domain inverse problem.arXiv preprint arXiv:2512.05672, 2025
-
[24]
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
work page 2024
-
[25]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
work page 2025
-
[26]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[27]
Hyungjin Chung, Byeongsu Sim, and Jong Chul Ye. Come-closer-diffuse-faster: Accelerating conditional diffusion models for inverse problems through stochastic contraction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12413–12422, 2022
work page 2022
-
[28]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=OnD9zGAGT0k
work page 2023
-
[29]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational Conference on Learning Representations, 2023. URL https: //openreview.net/forum?id=9_gsMA8MRKQ
work page 2023
-
[30]
Zero-shot image restoration using denoising diffusion null- space model
Yinhuai Wang, Jiwen Yu, and Jian Zhang. Zero-shot image restoration using denoising diffusion null- space model. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=mRieQgMtNTQ
work page 2023
-
[31]
Decomposed diffusion sampler for accelerating large-scale inverse problems
Hyungjin Chung, Suhyeon Lee, and Jong Chul Ye. Decomposed diffusion sampler for accelerating large-scale inverse problems. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=DsEhqQtfAG
work page 2024
-
[32]
A variational perspective on solving inverse problems with diffusion models
Morteza Mardani, Jiaming Song, Jan Kautz, and Arash Vahdat. A variational perspective on solving inverse problems with diffusion models. InThe Twelfth International Conference on Learning Representations,
-
[33]
URLhttps://openreview.net/forum?id=1YO4EE3SPB
-
[34]
Solving inverse problems with latent diffusion models via hard data consistency
Bowen Song, Soo Min Kwon, Zecheng Zhang, Xinyu Hu, Qing Qu, and Liyue Shen. Solving inverse problems with latent diffusion models via hard data consistency. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=j8hdRqOUhN
work page 2024
-
[35]
Litu Rout, Negin Raoof, Giannis Daras, Constantine Caramanis, Alex Dimakis, and Sanjay Shakkottai. Solving linear inverse problems provably via posterior sampling with latent diffusion models.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[36]
Improving diffusion inverse problem solving with decoupled noise annealing
Bingliang Zhang, Wenda Chu, Julius Berner, Chenlin Meng, Anima Anandkumar, and Yang Song. Improving diffusion inverse problem solving with decoupled noise annealing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20895–20905, 2025. 11
work page 2025
-
[37]
Flowdps: Flow-driven posterior sampling for inverse problems
Jeongsol Kim, Bryan Sangwoo Kim, and Jong Chul Ye. Flowdps: Flow-driven posterior sampling for inverse problems. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12328–12337, 2025
work page 2025
-
[38]
FlowLPS: Langevin-Proximal Sampling for Flow-based Inverse Problem Solvers
Jonghyun Park and Jong Chul Ye. Flowlps: Langevin-proximal sampling for flow-based inverse problem solvers.arXiv preprint arXiv:2512.07150, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pages 402–419. Springer, 2020
work page 2020
- [40]
-
[41]
Veo 3.https://deepmind.google/models/veo/, 2025
Google DeepMind. Veo 3.https://deepmind.google/models/veo/, 2025
work page 2025
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[43]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[44]
David Ruhe, Jonathan Heek, Tim Salimans, and Emiel Hoogeboom. Rolling diffusion models. In International Conference on Machine Learning, pages 42818–42835. PMLR, 2024
work page 2024
-
[45]
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Systems, 37:89834–89868, 2024
work page 2024
-
[46]
Frame context packing and drift prevention in next-frame-prediction video diffusion models
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[47]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong MU, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. In The Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview. net/forum?id=66NzcRQuOq
work page 2025
-
[48]
Methods of conjugate gradients for solving linear systems
Magnus R Hestenes, Eduard Stiefel, et al. Methods of conjugate gradients for solving linear systems. Journal of research of the National Bureau of Standards, 49(6):409–436, 1952
work page 1952
-
[49]
Numerical Mathemat- ics and Scie, 2013
Jörg Liesen and Zdenek Strakos.Krylov subspace methods: principles and analysis. Numerical Mathemat- ics and Scie, 2013
work page 2013
- [50]
-
[51]
Chang-Han Yeh, Chin-Yang Lin, Zhixiang Wang, Chi-Wei Hsiao, Ting-Hsuan Chen, and Yu-Lun Liu. Diffir2vr-zero: Zero-shot video restoration with diffusion-based image restoration models.arXiv preprint arXiv:2407.01519, 2024
-
[52]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
work page 2004
-
[53]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[54]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[55]
FVD: A new metric for video generation, 2019
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. FVD: A new metric for video generation, 2019. URL https://openreview.net/ forum?id=rylgEULtdN
work page 2019
-
[56]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 12
work page 2024
-
[57]
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
work page 2024
-
[58]
Saurabh Saxena, Charles Herrmann, Junhwa Hur, Abhishek Kar, Mohammad Norouzi, Deqing Sun, and David J Fleet. The surprising effectiveness of diffusion models for optical flow and monocular depth estimation.Advances in Neural Information Processing Systems, 36:39443–39469, 2023
work page 2023
-
[59]
Diffbir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diffbir: Toward blind image restoration with generative diffusion prior. InEuropean conference on computer vision, pages 430–448. Springer, 2024
work page 2024
-
[60]
Weimin Bai, Suzhe Xu, Yiwei Ren, Jinhua Hao, Ming Sun, Wenzheng Chen, and He Sun. Instantvir: Real-time video inverse problem solver with distilled diffusion prior.arXiv preprint arXiv:2511.14208, 2025
-
[61]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[62]
On the content bias in fréchet video distance
Songwei Ge, Aniruddha Mahapatra, Gaurav Parmar, Jun-Yan Zhu, and Jia-Bin Huang. On the content bias in fréchet video distance. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7277–7288, 2024
work page 2024
-
[63]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
work page 2016
-
[64]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017
work page 2017
-
[65]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[66]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[67]
Amt: All-pairs multi-field transforms for efficient frame interpolation
Zhen Li, Zuo-Liang Zhu, Ling-Hao Han, Qibin Hou, Chun-Le Guo, and Ming-Ming Cheng. Amt: All-pairs multi-field transforms for efficient frame interpolation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9801–9810, 2023
work page 2023
-
[68]
aesthetic-predictor.https://github.com/LAION-AI/aesthetic-predictor, 2022
LAION-AI. aesthetic-predictor.https://github.com/LAION-AI/aesthetic-predictor, 2022
work page 2022
-
[69]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
work page 2021
-
[70]
Reangle-a-video: 4d video generation as video-to- video translation
Hyeonho Jeong, Suhyeon Lee, and Jong Chul Ye. Reangle-a-video: 4d video generation as video-to- video translation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11164–11175, 2025
work page 2025
-
[71]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024. 13 A Discussion on the Error Bound and Proof Let t0 > t 1 >· · ·> t K = 0 be the reverse sampling schedule of K steps for the n-th chunk, where zn,tgt denotes the target ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.