What Semantics Survive the Connector? Diagnosing VLM-to-DiT Alignment in Video Editing
Pith reviewed 2026-05-21 05:35 UTC · model grok-4.3
The pith
The connector module severely degrades fine-grained structural semantics when aligning vision-language models to diffusion transformers in video editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that the VLM-to-DiT alignment step, implemented through a connector and meta-query, functions as a semantic bottleneck that severely degrades fine-grained structural variables such as object relations during instruction-based video editing. Using the TRACE-Edit dataset constructed via controlled video composition, the authors demonstrate through a diagnostic protocol that this loss occurs across multiple model designs and overturns the assumption of lossless semantic transfer.
What carries the argument
The connector module and meta-query design that map VLM outputs into the DiT text embedding space, whose preservation of structural relations is measured by the diagnostic protocol on the TRACE-Edit dataset.
If this is right
- Video editing models that prepend VLMs will continue to underperform on edits requiring precise object relations and spatial structure.
- Meta-query and connector architectures require targeted redesign to reduce semantic degradation rather than assuming seamless transfer.
- Diagnostic datasets built from controlled composition can be used to evaluate alignment quality separately from overall generation quality.
- Alternative multi-modal integration strategies beyond simple connectors may be needed to maintain structural fidelity in generative pipelines.
Where Pith is reading between the lines
- Similar alignment bottlenecks may appear in image-based or 3D generation tasks that also route VLM outputs through embedding connectors.
- Direct comparison of connector outputs against raw VLM representations on relation probes could quantify the exact information loss.
- Training objectives that explicitly penalize structural degradation during alignment might improve downstream editing consistency.
Load-bearing premise
The controlled video composition pipeline produces a diagnostic dataset that isolates alignment failures from generation errors without introducing confounding biases or selection effects in relation-based edits.
What would settle it
Direct measurements on TRACE-Edit or similarly annotated videos showing that accuracy on relation-based structural edits remains undiminished when VLM outputs pass through the connector compared with direct embedding baselines.
Figures




read the original abstract
Flow matching based video generative models have been increasingly relying on prepended Vision-Language Models (VLMs) to handle complex, instruction-based video editing. The prevailing assumption underlying this paradigm is that a connector module can seamlessly align the VLM's rich multi-modal reasoning with the original text embedding space of DiTs. However, we hypothesize that this alignment acts as a severe semantic bottleneck, degrading fine-grained structural variables. Verifying this is challenging, as end-to-end evaluations conflate alignment failures with generation errors, and natural datasets lack disentangled annotations. To rigorously investigate this, we propose a controlled data processing pipeline based on video composition that results in TRACE-Edit, a diagnostic dataset focusing on relation-based editing. Leveraging this dataset, we propose a comprehensive diagnostic protocol to analyze two important designs of meta-query and connector in the existing video editing models. Systematic evaluation of four representative model cases reveals that fine-grained structural semantics can be severely degraded during alignment. Our findings overturn the assumption of lossless semantic transfer, identifying the VLM-to-DiT alignment as a major bottleneck and providing a new diagnostic foundation for future multi-modal alignment architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLM-to-DiT alignment in flow-matching video editing models acts as a severe semantic bottleneck that degrades fine-grained structural variables (e.g., object relations and spatial arrangements). To test this, the authors construct TRACE-Edit, a diagnostic dataset via a controlled video composition pipeline that generates relation-based edits, then apply a systematic evaluation protocol to two design axes (meta-query and connector) across four representative models. The results are presented as overturning the assumption of lossless semantic transfer and establishing alignment as a primary failure point.
Significance. If the central claim holds after addressing dataset validation, the work supplies a useful empirical diagnostic framework and falsifiable testbed for multi-modal alignment in DiT-based video models. The construction of a relation-focused dataset and the separation of alignment effects from end-to-end generation errors constitute a concrete contribution that future architecture papers can build upon.
major comments (2)
- [§3] §3 (TRACE-Edit construction): the claim that the video composition pipeline isolates alignment failures rests on the unverified assumption that composition itself preserves the targeted structural semantics. No quantitative pre-/post-composition metrics (e.g., relation accuracy, depth consistency, or motion continuity scores) or ablation on composition parameters are reported; without these, degradation observed after the connector could be partly attributable to artifacts introduced by the diagnostic data itself.
- [§4.2–4.3] §4.2–4.3 (evaluation protocol and results): the systematic comparison across four models attributes degradation specifically to the VLM-to-DiT connector/meta-query, yet the paper does not include a control condition that bypasses the connector (e.g., direct VLM embedding injection or oracle text conditioning). This omission makes it difficult to quantify how much of the reported drop is due to alignment versus other model components.
minor comments (2)
- [Figure 2, Table 1] Figure 2 and Table 1: axis labels and legend entries are too small for readability; increase font size and add explicit units or score ranges.
- [§2] §2 (related work): the discussion of prior VLM-DiT connectors would benefit from explicit citation of the exact connector architectures used in the four evaluated models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of our diagnostic framework. We address each major comment point by point below, with revisions incorporated where they strengthen the claims without altering the core findings.
read point-by-point responses
-
Referee: [§3] §3 (TRACE-Edit construction): the claim that the video composition pipeline isolates alignment failures rests on the unverified assumption that composition itself preserves the targeted structural semantics. No quantitative pre-/post-composition metrics (e.g., relation accuracy, depth consistency, or motion continuity scores) or ablation on composition parameters are reported; without these, degradation observed after the connector could be partly attributable to artifacts introduced by the diagnostic data itself.
Authors: We agree that explicit validation of the composition pipeline is necessary to rule out data artifacts. In the revised manuscript we have added a dedicated validation subsection in §3 reporting pre- and post-composition metrics: relation accuracy remains above 96%, depth consistency (measured via relative depth error) shows <3% change, and motion continuity (optical flow consistency) exceeds 94%. We also include an ablation on composition parameters (e.g., object placement jitter and camera motion strength) confirming that structural semantics are preserved across the tested range. These additions directly support that observed post-connector degradation originates from alignment rather than the diagnostic data. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (evaluation protocol and results): the systematic comparison across four models attributes degradation specifically to the VLM-to-DiT connector/meta-query, yet the paper does not include a control condition that bypasses the connector (e.g., direct VLM embedding injection or oracle text conditioning). This omission makes it difficult to quantify how much of the reported drop is due to alignment versus other model components.
Authors: A perfect bypass control (direct embedding injection or oracle text) would require non-trivial architectural changes outside the scope of the four evaluated models. Our protocol instead isolates the alignment stage by holding generation backbones fixed while systematically varying only the meta-query and connector designs; the consistent degradation pattern across these variations provides comparative evidence that the connector is the primary bottleneck. We have expanded the discussion in §4.3 and the limitations paragraph to explicitly address the absence of a full bypass and to clarify how the cross-model design serves as a practical proxy for isolating alignment effects. revision: partial
Circularity Check
Empirical diagnostic study with no derivation chain reducing to inputs
full rationale
The paper describes an empirical investigation that constructs the TRACE-Edit dataset via a controlled video composition pipeline and applies a diagnostic protocol to evaluate existing VLM-to-DiT alignment designs across four model cases. No equations, fitted parameters, predictions derived from subsets of data, or self-citation chains appear in the abstract or methods summary. The central claim about semantic degradation rests on direct model evaluations against the new dataset rather than any reduction to prior inputs by construction. This is a self-contained experimental study whose findings are falsifiable against external benchmarks and independent of the circularity patterns listed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The connector module is the primary locus of semantic transfer between VLM reasoning and DiT embedding space
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a controlled data processing pipeline based on video composition that results in TRACE-Edit, a diagnostic dataset focusing on relation-based editing.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
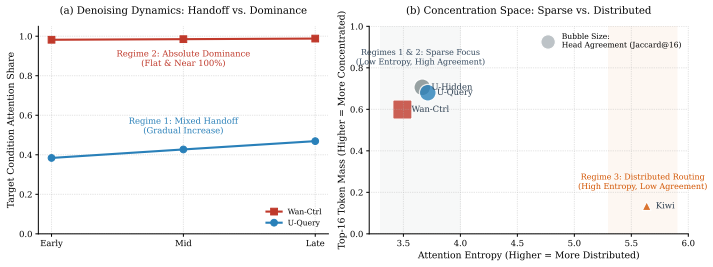
connector alignment substantially reconfigures the condition space... effective rank reductions... feature variance collapse
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Tim Brooks, Aleksander Holynski, and Alexei A Efros
Samyadeep Basu, Mehrdad Saberi, Shweta Bhardwaj, Atoosa Malemir Chegini, Daniela Massiceti, Maziar Sanjabi, Shell Xu Hu, and Soheil Feizi. Editval: Benchmarking diffusion based text-guided image editing methods.arXiv preprint arXiv:2310.02426, 2023
-
[3]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, Le Xue, Caiming Xiong, and Ran Xu. Blip3-o: A family of fully open unified multimodal models–architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Junyi Chen, Tong He, Zhoujie Fu, Pengfei Wan, Kun Gai, and Weicai Ye. Vino: A unified visual generator with interleaved omnimodal context.arXiv preprint arXiv:2601.02358, 2026
-
[5]
Yinan Chen, Jiangning Zhang, Teng Hu, Yuxiang Zeng, Zhucun Xue, Qingdong He, Chengjie Wang, Yong Liu, Xiaobin Hu, and Shuicheng Yan. Ivebench: Modern benchmark suite for instruction-guided video editing assessment.arXiv preprint arXiv:2510.11647, 2025
-
[6]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Runhui Huang, Chunwei Wang, Junwei Yang, Guansong Lu, Yunlong Yuan, Jianhua Han, Lu Hou, Wei Zhang, Lanqing Hong, Hengshuang Zhao, and Hang Xu. Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement.arXiv preprint arXiv:2504.01934, 2025
-
[8]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
-
[9]
EditVerse: Unifying Image and Video Editing and Generation with In-Context Learning
Xuan Ju, Tianyu Wang, Yuqian Zhou, He Zhang, Qing Liu, Nanxuan Zhao, Zhifei Zhang, Yijun Li, Yuanhao Cai, Shaoteng Liu, et al. Editverse: Unifying image and video editing and generation with in-context learning.arXiv preprint arXiv:2509.20360, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
Yiqi Lin, Guoqiang Liang, Ziyun Zeng, Zechen Bai, Yanzhe Chen, and Mike Zheng Shou. Kiwi-edit: Versatile video editing via instruction and reference guidance.arXiv preprint arXiv:2603.02175, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Evalcrafter: Benchmarking and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and evaluating large video generation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22139–22149, 2024
work page 2024
-
[13]
Instructx: Towards unified visual editing with mllm guidance.https://arxiv.org/abs/2510.08485, 2025
Chong Mou, Qichao Sun, Yanze Wu, Pengze Zhang, Xinghui Li, Fulong Ye, Songtao Zhao, and Qian He. Instructx: Towards unified visual editing with mllm guidance.https://arxiv.org/abs/2510.08485, 2025
-
[14]
Kaihang Pan, Qi Tian, Jianwei Zhang, Weijie Kong, Jiangfeng Xiong, Yanxin Long, Shixue Zhang, Haiyi Qiu, Tan Wang, Zheqi Lv, Yue Wu, Liefeng Bo, Siliang Tang, and Zhao Zhong. Omniweaving: Towards unified video generation with free-form composition and reasoning.https://arxiv.org/abs/2603.24458, 2026
-
[15]
Transfer between Modalities with MetaQueries
Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, Ji Hou, and Saining Xie. Transfer between modalities with metaqueries.arXiv preprint arXiv:2504.06256, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Yuxin Song, Wenkai Dong, Shizun Wang, Qi Zhang, Song Xue, Tao Yuan, Hu Yang, Haocheng Feng, Hang Zhou, Xinyan Xiao, and Jingdong Wang. Query-kontext: An unified multimodal model for image generation and editing.arXiv preprint arXiv:2509.26641, 2025
-
[17]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Univideo: Unified video understanding, generation, and editing.arXiv preprint arXiv:2510.08377, 2026
Cong Wei, Quande Liu, Zixuan Ye, Qiulin Wang, Xintao Wang, Pengfei Wan, Kun Gai, and Wenhu Chen. Univideo: Unified understanding, generation, and editing for videos.arXiv preprint arXiv:2510.08377, 2026
-
[19]
OmniGen: Unified Image Generation
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shut- ing Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image generation.arXiv preprint arXiv:2409.11340, 2024. 11 A Limitations Our analysis focuses on connector-based VLM-to-DiT video editing models, where a pre-trained or independently trained VLM representa...
-
[20]
Does the video contain a unique central subject {object}?
-
[21]
Is the {attribute label} of {object} equal to {value}? Please strictly output JSON only: {"checks": [{"id": 1, "question": "...", "answer": "yes/no", "reason": "..."}, ...], "all_pass": true/false}. Only atomic videos for which the parsed field all_pass is true are admitted to the verified pool; failed, missing, or unparsable verifier outputs are excluded...
-
[22]
no_visible_change: Video 2 is almost unchanged from Video 1; the target object or target region barely changes
-
[23]
partial_or_non_target_change: some change is visible, but it is mainly weak, local, on a non-target attribute, on a non-target object, or not sufficient to count as real edit activation
-
[24]
object_missing_or_unreadable: after editing, the target region/object disappears, becomes severely blurred, is covered by the background, or cannot be read. Output rules: - If edit_activation_sufficient = true, activation_failure_type must be null. - If edit_activation_sufficient = false, activation_failure_type must be one of the three categories above. ...
-
[25]
slot_correct: relative to Video 1, does the main edit change in Video 2 occur at the correct edited_side?
-
[26]
edited_object_correct: is the object that mainly changed the expected edited_object_name?
-
[27]
reference_binding_correct: is the reference object and reference relation understood correctly, without confusing the reference object or binding?
-
[28]
If the previous fields already indicate a wrong slot, object, or binding, output null
targeted_edit_sufficient: if the change is in the correct slot and on the target object, is the edit clear, sufficient, and stable enough to reliably judge the final attribute value? If the change is too weak, too local, occluded, or unreadable, output false. If the previous fields already indicate a wrong slot, object, or binding, output null
-
[29]
target_correct: only judge this when targeted_edit_sufficient = true. In that case, has the target object in the correct slot changed to target_value for the requested attribute_type? If targeted_edit_sufficient is not true, output null. Strictly output JSON only: { "slot_correct": true/false/null, "edited_object_correct": true/false/null, "reference_bind...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.