PlexRL: Cluster-Level Orchestration of Serviceized LLM Execution for RLVR
Pith reviewed 2026-05-21 02:21 UTC · model grok-4.3
The pith
PlexRL multiplexes LLM services across RLVR jobs at the cluster level to exploit anti-correlated idle gaps and cut GPU costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
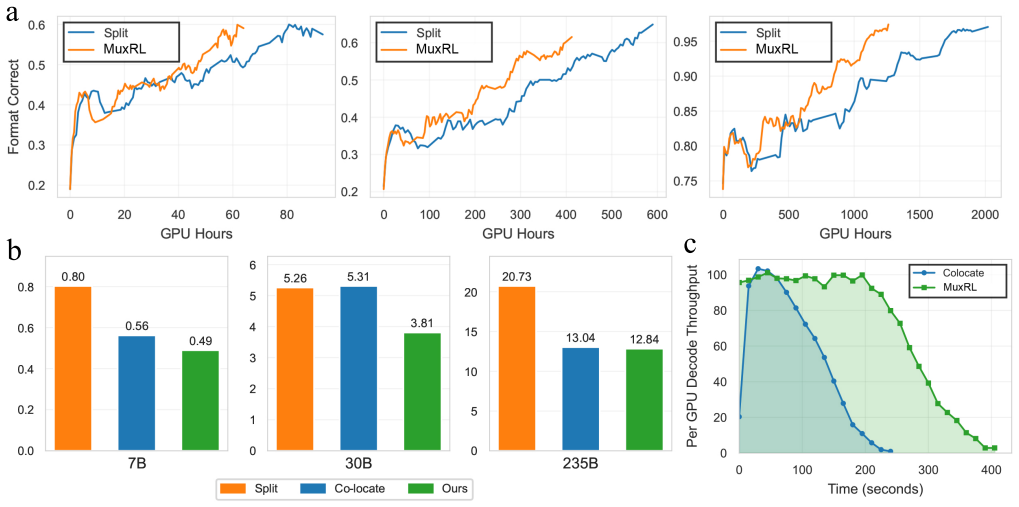
The paper claims that the idle time in RLVR is a structural feature of individual jobs but anti-correlated across jobs, which a cluster-level orchestrator can use by time-slicing unified LLM services. PlexRL manages model placement, state transitions, and function-level scheduling to fill idle periods. This yields up to 37.58 percent lower GPU hour costs for users while keeping algorithmic flexibility and adding little per-job overhead.
What carries the argument
PlexRL, the cluster-level runtime for multiplexing unified LLM services across RLVR jobs under strict affinity constraints by centrally managing model placement, state transitions, and function-level scheduling.
If this is right
- Effective cluster capacity for RLVR jobs increases substantially.
- Users experience up to 37.58 percent reduction in GPU hour costs.
- RLVR algorithms retain full flexibility with no changes needed.
- Per-job overhead stays minimal compared to local optimizations.
- Expensive model migrations are avoided while still utilizing idle times.
Where Pith is reading between the lines
- If anti-correlation holds at larger cluster sizes, gains in capacity could scale with the number of concurrent jobs.
- Operators of shared GPU clusters might adopt similar multiplexing for other workloads with variable execution patterns.
Load-bearing premise
The idle gaps within individual RLVR jobs are largely anti-correlated with those of other jobs, allowing cluster-level exploitation without costly model migrations.
What would settle it
Observing the timing of idle periods when running several RLVR jobs simultaneously on the cluster; high overlap in idle times would mean little benefit from multiplexing.
Figures







read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has recently unlocked strong reasoning capabilities in large language models (LLMs), triggering rapid exploration of new algorithms and data. However, RLVR training is notoriously inefficient: long-tailed rollouts, tool-induced stalls, and asymmetric resource requirements between rollout and training introduce substantial idle time that cannot be eliminated by job-local optimizations such as synchronous pipelining, asynchronous rollout, or colocated execution. We argue that this inefficiency is structural. While idle gaps are unavoidable within individual RLVR jobs, they are largely anti-correlated across jobs and therefore exploitable at the cluster level. Leveraging this observation, we present PlexRL, a cluster-level runtime for multiplexing unified LLM services across RLVR jobs. By centrally managing model placement, state transitions, and function-level scheduling under strict affinity constraints, PlexRL time-slices LLM execution across jobs to fill otherwise idle periods without expensive model migration. Our implementation and evaluations demonstrate that PlexRL significantly improves effective cluster capacity and reduces user GPU hour cost by maximum 37.58% while preserving algorithmic flexibility and introducing minimal per-job overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PlexRL, a cluster-level runtime for multiplexing unified LLM services across multiple RLVR jobs. It posits that idle periods arising from long-tailed rollouts, tool stalls, and asymmetric rollout/training phases are largely anti-correlated across jobs and can therefore be filled via central time-slicing under affinity constraints, without expensive model migration. The central empirical claim is that this approach improves effective cluster capacity and reduces user GPU-hour cost by a maximum of 37.58% while preserving algorithmic flexibility and adding only minimal per-job overhead.
Significance. If the reported gains prove robust across workloads and the anti-correlation premise holds, PlexRL would offer a practical engineering solution to a structural inefficiency in RLVR training, increasing cluster utilization in distributed LLM environments. The emphasis on serviceized execution and affinity-preserving scheduling is a constructive contribution to cluster orchestration for AI workloads.
major comments (2)
- Abstract: the headline result of a maximum 37.58% reduction in user GPU-hour cost is presented as demonstrated by evaluations, yet the manuscript supplies no description of the experimental setup, baselines, workload mixes, or how per-job and scheduling overheads were measured and subtracted. This omission leaves the central capacity-improvement claim unsubstantiated.
- Approach / Evaluation sections: the load-bearing premise that idle gaps are largely anti-correlated across jobs is stated without supporting quantitative evidence such as idle-time traces, cross-correlation statistics, or sensitivity analysis to workload variation. Without such data it is impossible to isolate the multiplexing gain from other factors or to assess whether the observed benefit generalizes.
minor comments (1)
- Abstract: the phrase 'serviceized LLM execution' would benefit from a brief parenthetical gloss on what serviceization entails in this context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback identifies key areas where greater detail on experimental methodology and supporting evidence for our core premise would strengthen the paper. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: Abstract: the headline result of a maximum 37.58% reduction in user GPU-hour cost is presented as demonstrated by evaluations, yet the manuscript supplies no description of the experimental setup, baselines, workload mixes, or how per-job and scheduling overheads were measured and subtracted. This omission leaves the central capacity-improvement claim unsubstantiated.
Authors: We agree that the abstract would be improved by briefly contextualizing the reported result. In the revised version we will add a concise clause describing the evaluation: RLVR jobs drawn from standard reasoning benchmarks, comparison against job-local baselines (synchronous pipelining, asynchronous rollout, colocated execution), a mix of short- and long-tailed workloads, and overhead measurement via per-job instrumentation with scheduling costs subtracted from the reported GPU-hour savings. This change substantiates the claim while preserving the abstract's brevity. revision: yes
-
Referee: Approach / Evaluation sections: the load-bearing premise that idle gaps are largely anti-correlated across jobs is stated without supporting quantitative evidence such as idle-time traces, cross-correlation statistics, or sensitivity analysis to workload variation. Without such data it is impossible to isolate the multiplexing gain from other factors or to assess whether the observed benefit generalizes.
Authors: The anti-correlation observation underpins the design, yet the current manuscript presents it primarily through end-to-end results rather than direct measurements. We will add a new subsection in the evaluation that includes representative idle-time traces from multiple concurrent RLVR jobs, pairwise cross-correlation coefficients, and a sensitivity study across workload mixes (varying rollout length distributions and tool-stall frequencies). These additions will allow readers to isolate the multiplexing contribution and evaluate generalizability. revision: yes
Circularity Check
No circularity; claims are empirical engineering results from measurements
full rationale
The paper describes a cluster-level runtime system for multiplexing LLM services across RLVR jobs. Its headline performance claims (up to 37.58% GPU-hour reduction and improved cluster capacity) are presented as outcomes of implementation and evaluations rather than any mathematical derivation, fitted parameter, or first-principles prediction. No equations, self-citations, uniqueness theorems, or ansatzes appear in the supplied text that would reduce a claimed result to its own inputs by construction. The premise that idle gaps are largely anti-correlated across jobs is stated as an empirical observation motivating the design, not as a quantity derived from or fitted to the system's own outputs. This is a self-contained engineering contribution evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
idle gaps are unavoidable within individual RLVR jobs, they are largely anti-correlated across jobs and therefore exploitable at the cluster level... PlexRL time-slices LLM execution across jobs to fill otherwise idle periods without expensive model migration
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Juntong Bai et al. 2020. PipeSwitch: Fast Pipelined Context Switch- ing for Deep Learning Applications. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 499–514
work page 2020
-
[2]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low- Latency Serverless Inference for Large Language Models. In18th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 24). USENIX Association, Santa Clara, CA, 135–153.https: //www.usenix.org/conference/osdi24/pr...
work page 2024
-
[4]
Scott Fujimoto, David Meger, and Doina Precup. 2019. Off-policy deep reinforcement learning without exploration. InInternational conference on machine learning. PMLR, 2052–2062
work page 2019
-
[5]
Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen. 2024. ToRA: A Tool- Integrated Reasoning Agent for Mathematical Problem Solving. InThe Twelfth International Conference on Learning Representations.https: //openreview.net/forum?id=Ep0TtjVoap
work page 2024
-
[6]
Albert Gu and Tri Dao. 2024. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752 [cs.LG]https://arxiv. org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Albert Gu, Karan Goel, and Christopher Ré. 2022. Efficiently Modeling Long Sequences with Structured State Spaces. arXiv:2111.00396 [cs.LG] https://arxiv.org/abs/2111.00396 13
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Juncheng Gu, Yibo Zhao, et al. 2019. Tiresias: A GPU Cluster Man- ager for Distributed Deep Learning. In16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19). 485–500
work page 2019
- [9]
-
[10]
Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. 2025. REIN- FORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization. arXiv:2501.03262 [cs.CL]https://arxiv.org/ abs/2501.03262
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, Weikai Fang, Xianyu, Yu Cao, Haotian Xu, and Yiming Liu. 2025. OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework. arXiv:2405.11143 [cs.AI]https://arxiv.org/abs/2405.11143
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Mahammad Humayoo, Gengzhong Zheng, Xiaoqing Dong, Liming Miao, Shuwei Qiu, Zexun Zhou, Peitao Wang, Zakir Ullah, Naveed Ur Rehman Junejo, and Xueqi Cheng. 2025. Relative importance sam- pling for off-policy actor-critic in deep reinforcement learning.Scien- tific Reports15, 1 (2025), 14349
work page 2025
-
[13]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. arXiv:2503.09516 [cs.CL]https://arxiv.org/abs/2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[15]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. arXiv:2309.06180 [cs.LG]https://arxiv.org/ abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
Kevin Lu and Thinking Machines Lab. 2025. On-Policy Distilla- tion.Thinking Machines Lab: Connectionism(2025). doi:10.64434/ tml.20251026https://thinkingmachines.ai/blog/on-policy-distillation
work page 2025
- [18]
-
[19]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei- Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. 2025. s1: Simple test-time scaling. arXiv:2501.19393 [cs.CL]https://arxiv.org/abs/2501.19393
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Rémi Munos, Tom Stepleton, Anna Harutyunyan, and Marc Bellemare
-
[21]
Safe and efficient off-policy reinforcement learning.Advances in neural information processing systems29 (2016)
work page 2016
-
[22]
Deepak Narayanan et al. 2020. Heterogeneity-Aware Cluster Schedul- ing Policies for Deep Learning Workloads. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 481–498
work page 2020
-
[23]
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He
-
[24]
arXiv:2101.06840 [cs.DC]https://arxiv.org/abs/2101.06840
ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv:2101.06840 [cs.DC]https://arxiv.org/abs/2101.06840
-
[25]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. 2018. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv:1506.02438 [cs.LG]https: //arxiv.org/abs/1506.02438
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL]https://arxiv.org/ abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Gerald Shen, Zhilin Wang, Olivier Delalleau, Jiaqi Zeng, Yi Dong, Daniel Egert, Shengyang Sun, Jimmy Zhang, Sahil Jain, Ali Taghibakhshi, Markel Sanz Ausin, Ashwath Aithal, and Oleksii Kuchaiev. 2024. NeMo-Aligner: Scalable Toolkit for Efficient Model Alignment. arXiv:2405.01481 [cs.CL]https://arxiv.org/abs/2405.01481
-
[31]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2024. Hybrid- Flow: A Flexible and Efficient RLHF Framework.arXiv preprint arXiv: 2409.19256(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybrid- flow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems. 1279–1297
work page 2025
- [33]
-
[34]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chun- ing Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, Hao- tian Zhao, Haoyu Lu, Haoze Li, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
-
[36]
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. 2020. TRL: Transformer Reinforcement Learning. https://github.com/huggingface/trl
work page 2020
-
[37]
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. 2024. Fast Distributed Inference Serving for Large Language Models. arXiv:2305.05920 [cs.LG]https://arxiv.org/abs/2305.05920
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Si- vathanu, Nipun Kwatra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. 2018. Gan- diva: introspective cluster scheduling for deep learning. InProceedings of the 13th USENIX Conference on Operating Systems Design and Imple- mentation(Carlsbad, CA, US...
work page 2018
-
[39]
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. 2025. Logic-RL: 14 Unleashing LLM Reasoning with Rule-Based Reinforcement Learning. arXiv:2502.14768 [cs.CL]https://arxiv.org/abs/2502.14768
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Cheng- peng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Kem- ing Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024. Qwen2.5-Math Technical Report: Toward Mathe- matical Expert Model via Self-Improvement. arXiv:2409.12122 [cs.CL] https://arxiv.org/abs/2409.12122
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Zhewei Yao, Reza Yazdani Aminabadi, Olatunji Ruwase, Samyam Rajb- handari, Xiaoxia Wu, Ammar Ahmad Awan, Jeff Rasley, Minjia Zhang, Conglong Li, Connor Holmes, Zhongzhu Zhou, Michael Wyatt, Molly Smith, Lev Kurilenko, Heyang Qin, Masahiro Tanaka, Shuai Che, Shuai- wen Leon Song, and Yuxiong He. 2023. DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training...
-
[42]
Chen Yu et al. 2020. Salus: Fine-Grained GPU Sharing Primitives for Deep Learning Applications.Proceedings of Machine Learning and Systems2 (2020), 239–250
work page 2020
-
[43]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, Xi- angpeng Wei, Xiangyu Yu, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Ru Zhang, Xin Liu, Mingxuan Wang, Yonghui Wu, and Lin Yan. 2025. VAPO: Efficient and Reli...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
Yuyang Zhong et al. 2025. Optimizing RLHF Training for Large Lan- guage Models with Inter- and Intra-Stage Fusion. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). 15
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.