Terminal-World: Scaling Terminal-Agent Environments via Agent Skills
Pith reviewed 2026-05-21 04:50 UTC · model grok-4.3
The pith
Agent skills serve as the core primitive for automatically synthesizing aligned tasks, environments, and trajectories to scale terminal-agent training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
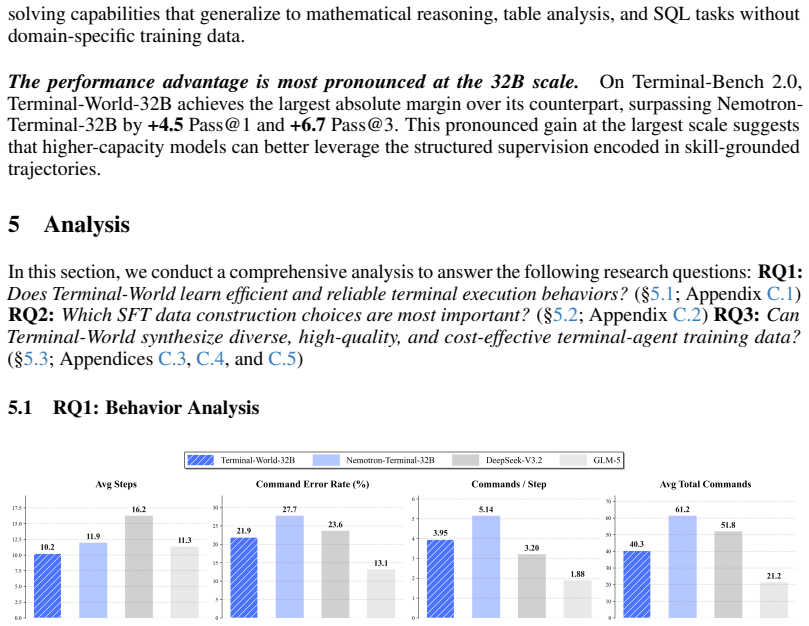
Terminal-World treats agent skills as the fundamental synthesis unit. A skill jointly specifies what must be accomplished, the preconditions and current environment state that determine when it applies, and the precise execution procedure. By composing skills into skill teams for multi-role tasks and skill graphs for cross-domain tasks, the pipeline co-derives complete task instructions, matching environments, and teacher trajectories. This process generated 5,723 training environments. When these data are used to train the Terminal-World series, the resulting models outperform prior terminal-agent baselines across six benchmarks. In particular, Terminal-World-32B, trained with the same base
What carries the argument
Agent skills, which jointly encode accomplishment goals, application preconditions tied to environment state, and execution procedures, acting as composable primitives for generating tasks, environments, and trajectories together.
If this is right
- The synthesized data produces consistent gains over prior terminal-agent baselines on six separate benchmarks.
- A 32B model trained on only 1.2 percent of the data reaches 31.5 Pass@1 and 43.8 Pass@3 on Terminal-Bench 2.0, exceeding Nemotron-Terminal-32B.
- Skill teams and skill graphs allow synthesis of multi-role and cross-domain tasks that exceed the scope of single-seed methods.
- Joint derivation of instructions, environments, and trajectories improves semantic alignment compared with partial bootstrapping approaches.
Where Pith is reading between the lines
- The same skill-composition approach could be tested in other tool-use or embodied-agent settings where data scarcity is the main limit.
- Structured skill graphs might offer a route to more diverse synthetic distributions that improve generalization to unseen command-line patterns.
- If the alignment holds, the method could lower the human effort needed to build large agent training sets across domains.
Load-bearing premise
The tasks, environments, and trajectories created by composing agent skills stay semantically aligned with real-world command-line usage and contain no systematic errors that would hurt downstream model performance.
What would settle it
If a model trained on the Terminal-World data underperforms on a held-out collection of human-written real-world terminal tasks or if manual review finds frequent mismatches between generated environments and their intended tasks, the synthesis method would be shown not to preserve alignment.
Figures




read the original abstract
Terminal agents extend Large Language Models with the ability to execute tasks directly in command-line environments, but their progress is bottlenecked by the scarcity of high-quality training data. Existing approaches bootstrap from partial sources such as human-defined seeds or GitHub repositories to instantiate one component and then complete the rest, producing tasks confined to narrow seed distributions, environments misaligned with task semantics, and inefficient trajectories from unguided exploration. To address these limitations, we introduce Terminal-World, a fully automated pipeline that uses agent skills as the central synthesis primitive, which jointly encode what to accomplish, when to apply (preconditions and environment state), and how to execute, enabling task instructions, environments, and teacher trajectories to be co-derived. To further broaden the synthesis space, Terminal-World composes skills into skill teams and skill graphs for multi-role and cross-domain task synthesis. Using this pipeline, we construct 5,723 training environments and train Terminal-World-8B/14B/32B, evaluated across 6 benchmarks where the Terminal-World series consistently outperforms terminal-agent baselines. Notably, using the same teacher model and only 1.2% of the training data, Terminal-World-32B surpasses Nemotron-Terminal-32B on Terminal-Bench 2.0 by +4.5 Pass@1 (31.5) and achieves 43.8 Pass@3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Terminal-World, a fully automated pipeline for synthesizing training data for terminal agents using agent skills as the central primitive. Agent skills jointly encode task goals, preconditions, and execution steps, which are then composed into skill teams and skill graphs to generate diverse tasks, environments, and teacher trajectories. Using this method, the authors create 5,723 training environments and train Terminal-World-8B, 14B, and 32B models. These models are evaluated on 6 benchmarks and consistently outperform terminal-agent baselines. Notably, Terminal-World-32B achieves superior performance on Terminal-Bench 2.0 compared to Nemotron-Terminal-32B using only 1.2% of the training data and the same teacher model, with gains of +4.5 in Pass@1 (31.5) and 43.8 in Pass@3.
Significance. If the synthesized data maintains high quality and alignment with real terminal environments, this work offers a significant advancement in scaling terminal-agent training by addressing data scarcity through skill-based composition. The empirical results demonstrate improved data efficiency and performance, which could influence future approaches to training agents in command-line settings. The use of skill teams and graphs for multi-role and cross-domain synthesis is a notable methodological contribution.
major comments (1)
- [Synthesis Pipeline and Results] The headline performance claims, such as the +4.5 Pass@1 improvement on Terminal-Bench 2.0 with 1.2% data, depend on the assumption that the synthesized tasks, environments, and trajectories are free of systematic semantic drift or invalid actions. The manuscript provides no reported metrics for validating the quality of the 5,723 environments, such as human validity ratings, command-frequency comparisons to real logs, or failure-mode analysis. This is a load-bearing issue for interpreting whether the gains reflect better generalization or easier synthetic distributions.
minor comments (2)
- [Abstract] The abstract states evaluation across 6 benchmarks but does not specify which benchmarks are used; explicitly naming them would enhance clarity for readers.
- [Results] The paper mentions consistent outperformance but could benefit from more detailed ablation studies on the contribution of skill teams versus skill graphs to the observed gains.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback. We address the major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Synthesis Pipeline and Results] The headline performance claims, such as the +4.5 Pass@1 improvement on Terminal-Bench 2.0 with 1.2% data, depend on the assumption that the synthesized tasks, environments, and trajectories are free of systematic semantic drift or invalid actions. The manuscript provides no reported metrics for validating the quality of the 5,723 environments, such as human validity ratings, command-frequency comparisons to real logs, or failure-mode analysis. This is a load-bearing issue for interpreting whether the gains reflect better generalization or easier synthetic distributions.
Authors: We agree that direct validation metrics for the synthesized environments would strengthen interpretation of the headline results. The current manuscript treats strong performance on real benchmarks (Terminal-Bench 2.0 and five others) as the primary evidence of data quality, since these benchmarks consist of authentic terminal tasks rather than synthetic ones; the fact that Terminal-World-32B outperforms a baseline trained on 80x more data from the same teacher supports that systematic drift or invalid actions did not dominate. Nevertheless, we acknowledge the referee's point that explicit checks are needed to rule out easier synthetic distributions. In the revised manuscript we will add a new subsection on data quality validation that reports: human validity ratings on a stratified sample of 200 environments, command-frequency and action-distribution comparisons against publicly available real terminal logs, and a categorized failure-mode analysis of semantic drift and invalid actions. These additions will be placed in Section 3 and will include quantitative results from analyses we have already conducted. revision: yes
Circularity Check
No circularity: empirical synthesis pipeline validated on external benchmarks
full rationale
The paper introduces an automated synthesis pipeline centered on agent skills for generating terminal environments and trajectories, then trains models and reports direct benchmark results (e.g., Terminal-World-32B achieving +4.5 Pass@1 over Nemotron-Terminal-32B on Terminal-Bench 2.0 using 1.2% data). No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains are present that would reduce claimed outcomes to inputs by construction. Performance is measured against independent external benchmarks rather than derived from the synthesis process itself, making the work self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
agent skills as the central synthesis primitive, which jointly encode what to accomplish, when to apply (preconditions and environment state), and how to execute
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
compose skills into skill teams and skill graphs for multi-role and cross-domain task synthesis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024. 2, 3
work page 2024
-
[2]
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh RN, et al. Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets.Advances in Neural Information Processing Systems, 37:54463–54482, 2024. 2, 3
work page 2024
-
[3]
Toolace: Winning the points of llm function calling
Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong WANG, et al. Toolace: Winning the points of llm function calling. InThe Thirteenth International Conference on Learning Representations. 2, 3
-
[4]
Zhenchao Jin, Mengchen Liu, Dongdong Chen, Lingting Zhu, Yunsheng Li, and Lequan Yu. Toolbridge: An open-source dataset to equip llms with external tool capabilities.arXiv preprint arXiv:2410.10872, 2024. 2, 3
-
[5]
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Hoang, Juan Carlos Niebles, et al. Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay.arXiv preprint arXiv:2504.03601, 2025. 2, 3
-
[6]
Toolmind technical report: A large-scale, reasoning-enhanced tool-use dataset
Chen Yang, Ran Le, Yun Xing, Zhenwei An, Zongchao Chen, Wayne Xin Zhao, Yang Song, and Tao Zhang. Toolmind technical report: A large-scale, reasoning-enhanced tool-use dataset. arXiv preprint arXiv:2511.15718, 2025. 2, 3
-
[7]
Yuwen Li, Wei Zhang, Zelong Huang, Mason Yang, Jiajun Wu, Shawn Guo, Huahao Hu, Lingyi Sun, Jian Yang, Mingjie Tang, et al. Close the loop: Synthesizing infinite tool-use data via multi-agent role-playing.arXiv preprint arXiv:2512.23611, 2025. 2, 3
-
[8]
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Guanting Dong, Junting Lu, Junjie Huang, Wanjun Zhong, Longxiang Liu, Shijue Huang, Zhenyu Li, Yang Zhao, Xiaoshuai Song, Xiaoxi Li, et al. Agent-world: Scaling real-world environment synthesis for evolving general agent intelligence.arXiv preprint arXiv:2604.18292,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Claude code: Best practices for agentic coding
Anthropic. Claude code: Best practices for agentic coding. https://www.anthropic.com/ engineering/claude-code-best-practices, Apr 2025. 2, 3
work page 2025
-
[10]
OpenAI. Introducing codex. https://openai.com/index/introducing-codex/, May 2025. Overview of the Codex coding agent accessible via ChatGPT and related clients. 2, 3
work page 2025
-
[11]
Agent harness for large language model agents: A survey.Preprints, April
Qianyu Meng, Yanan Wang, Liyi Chen, Qimeng Wang, Chengqiang Lu, Wei Wu, Yan Gao, Yi Wu, and Yao Hu. Agent harness for large language model agents: A survey.Preprints, April
-
[12]
Nghi DQ Bui. Building effective ai coding agents for the terminal: Scaffolding, harness, context engineering, and lessons learned.arXiv preprint arXiv:2603.05344, 2026. 2
-
[13]
Position: Agent Should Invoke External Tools ONLY When Epistemically Necessary
Hongru Wang, Cheng Qian, Manling Li, Jiahao Qiu, Boyang Xue, Mengdi Wang, Heng Ji, and Kam-Fai Wong. Toward a theory of agents as tool-use decision-makers.arXiv preprint arXiv:2506.00886, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Tool learning with large language models: A survey.Frontiers of Computer Science, 19(8):198343, 2025
Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, and Ji-Rong Wen. Tool learning with large language models: A survey.Frontiers of Computer Science, 19(8):198343, 2025. 2, 3
work page 2025
-
[15]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Endless terminals: Scaling rl environments for terminal agents.arXiv preprint arXiv:2601.16443, 2026
Kanishk Gandhi, Shivam Garg, Noah D Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents.arXiv preprint arXiv:2601.16443, 2026. 2, 3, 6
-
[17]
Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, Emad Barsoum, William Yang Wang, and Wenbo Guo. Termigen: High-fidelity environment and robust trajectory synthesis for terminal agents.arXiv preprint arXiv:2602.07274, 2026. 2, 3, 6, 7
-
[18]
On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193,
Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping. On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193,
-
[19]
Large-scale terminal agentic trajectory generation from dockerized environments, 2026
Siwei Wu, Yizhi Li, Yuyang Song, Wei Zhang, Yang Wang, Riza Batista-Navarro, Xian Yang, Mingjie Tang, Bryan Dai, Jian Yang, and Chenghua Lin. Large-scale terminal agentic trajectory generation from dockerized environments, 2026. 2, 3, 6
work page 2026
-
[20]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Skill0: In-context agentic reinforcement learning for skill internalization.arXiv preprint arXiv:2604.02268, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [22]
-
[23]
Agent skills marketplace.https://skillsmp.com/, 2026
SkillsMP. Agent skills marketplace.https://skillsmp.com/, 2026. 2
work page 2026
-
[24]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Webexplorer: Explore and evolve for training long-horizon web agents, 2025
Junteng Liu, Yunji Li, Chi Zhang, Jingyang Li, Aili Chen, Ke Ji, Weiyu Cheng, Zijia Wu, Chengyu Du, Qidi Xu, et al. Webexplorer: Explore and evolve for training long-horizon web agents.arXiv preprint arXiv:2509.06501, 2025. 3
-
[26]
Shrey Pandit, Xuan-Phi Nguyen, Yifei Ming, Austin Xu, Jiayu Wang, Caiming Xiong, and Shafiq Joty. Synthesizing agentic data for web agents with progressive difficulty enhancement mechanisms.arXiv preprint arXiv:2510.13913, 2025. 3
-
[27]
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl
Jiaxuan Gao, Wei Fu, Minyang Xie, Shusheng Xu, Chuyi He, Zhiyu Mei, Banghua Zhu, and Yi Wu. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl. InFirst Workshop on Multi-Turn Interactions in Large Language Models. 3
-
[28]
Scaling generalist data-analytic agents
Shuofei Qiao, Yanqiu Zhao, Zhisong Qiu, Xiaobin Wang, Jintian Zhang, Zhao Bin, Ningyu Zhang, Yong Jiang, Pengjun Xie, Fei Huang, et al. Scaling generalist data-analytic agents. arXiv preprint arXiv:2509.25084, 2025. 3
-
[29]
Taskcraft: Automated generation of agentic tasks.arXiv preprint arXiv:2506.10055, 2025
Dingfeng Shi, Jingyi Cao, Qianben Chen, Weichen Sun, Weizhen Li, Hongxuan Lu, Fangchen Dong, Tianrui Qin, King Zhu, Minghao Liu, et al. Taskcraft: Automated generation of agentic tasks.arXiv preprint arXiv:2506.10055, 2025. 3, 7, 17, 18
-
[30]
Zhihao Xu, Rumei Li, Jiahuan Li, Rongxiang Weng, Jingang Wang, Xunliang Cai, and Xiting Wang. Unlocking implicit experience: Synthesizing tool-use trajectories from text.arXiv preprint arXiv:2601.10355, 2026. 3
-
[31]
Infoagent: Advancing autonomous information-seeking agents.arXiv preprint arXiv:2509.25189, 2025
Gongrui Zhang, Jialiang Zhu, Ruiqi Yang, Kai Qiu, Miaosen Zhang, Zhirong Wu, Qi Dai, Bei Liu, Chong Luo, Zhengyuan Yang, et al. Infoagent: Advancing autonomous information-seeking agents.arXiv preprint arXiv:2509.25189, 2025. 3
-
[32]
Zhengwei Tao, Jialong Wu, Wenbiao Yin, Junkai Zhang, Baixuan Li, Haiyang Shen, Kuan Li, Liwen Zhang, Xinyu Wang, Yong Jiang, et al. Webshaper: Agentically data synthesizing via information-seeking formalization.arXiv preprint arXiv:2507.15061, 2025. 3 11
-
[33]
Shuang Sun, Huatong Song, Yuhao Wang, Ruiyang Ren, Jinhao Jiang, Junjie Zhang, Fei Bai, Jia Deng, Wayne Xin Zhao, Zheng Liu, et al. Simpledeepsearcher: Deep information seeking via web-powered reasoning trajectory synthesis.arXiv preprint arXiv:2505.16834, 2025. 3
-
[34]
SynthAgent: Adapting Web Agents with Synthetic Supervision
Zhaoyang Wang, Yiming Liang, Xuchao Zhang, Qianhui Wu, Siwei Han, Anson Bastos, Rujia Wang, Chetan Bansal, Baolin Peng, Jianfeng Gao, et al. Adapting web agents with synthetic supervision.arXiv preprint arXiv:2511.06101, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Pan, Guilin Qi, Haofen Wang, and Huajun Chen
Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Xin Xu, Tongtong Wu, Kun Wang, Yang Liu, Zhen Bi, Jungang Lou, Yuchen Eleanor Jiang, Hangcheng Zhu, Gang Yu, Haiwen Hong, Longtao Huang, Hui Xue, Chenxi Wang, Yijun Wang, Zifei Shan, Xi Chen, Zhaopeng Tu, Feiyu Xiong, X...
work page 2026
-
[36]
Jiuwenclaw.https://github.com/openJiuwen-ai/jiuwenclaw, 2026
openJiuwen-ai. Jiuwenclaw.https://github.com/openJiuwen-ai/jiuwenclaw, 2026. 4
work page 2026
-
[37]
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu, May
-
[38]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Harbor Framework Team. Harbor: A framework for evaluating and optimizing agents and models in container environments, January 2026. 6
work page 2026
-
[40]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 6, 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026. 6, 7, 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
American invitational mathematics examination (aime) 2024,
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024,
work page 2024
-
[45]
American invitational mathematics examination (aime) 2025,
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025,
work page 2025
-
[46]
Infiagent-dabench: Evaluating agents on data analysis tasks
Xueyu Hu, Ziyu Zhao, Shuang Wei, Ziwei Chai, Qianli Ma, Guoyin Wang, Xuwu Wang, Jing Su, Jingjing Xu, Ming Zhu, et al. Infiagent-dabench: Evaluating agents on data analysis tasks. arXiv preprint arXiv:2401.05507, 2024. 7, 17, 18
-
[47]
Tablebench: A comprehensive and complex benchmark for table question answering
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, et al. Tablebench: A comprehensive and complex benchmark for table question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25497–25506, 2025. 7, 17, 18
work page 2025
-
[48]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.Advances in Neural Information Processing Systems, 36:42330–42357, 2023. 7, 17, 18 12
work page 2023
-
[49]
Swift:a scalable lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024. 7
work page 2024
-
[50]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37:62557–62583, 2024. 18 13 Table of Contents 1 Introduction 2 2 Related Work 3 3 Terminal-...
work page 2024
-
[51]
The file’s description and filepath
-
[52]
The task instruction (what the agent needs to accomplish)
-
[53]
The overall environment context (system requirements, pre-setup)
-
[54]
Previously generated files (maintain consistency with imports, APIs, etc.) You MUST end your response with a ‘‘‘json fenced code block -- this block is required. 28 The JSON object must have exactly two fields: - "filepath": the exact path from the target file - "content": the full file content as a string Prompt for File Generation (local_toolmode)Back t...
-
[55]
Execute each step listed in setup_steps, in order
-
[56]
Create necessary directories
-
[57]
Install from any dependency manifest in the pre-seeded assets
-
[58]
Start or configure required services, environment variables, and permissions IMPORTANT: - HIGHEST PRIORITY: Never create, download, or overwrite any pre-seeded asset path - Scope is limited to environment configuration only -- no application source code - Do NOT execute the task (e.g. do NOT run ‘node index.js‘ or ‘python main.py‘) 31 - When using sudo wi...
-
[59]
Check that required packages/libraries are importable (e.g. ‘python3 -c "import flask"‘, ‘node -e "require(’express’)"‘)
-
[60]
Check that required CLI tools are available (e.g. ‘which gcc‘, ‘java -version‘)
-
[61]
Check that required directories exist
-
[62]
Check that dependency versions meet requirements if specific versions were requested IMPORTANT: - Do NOT install anything -- only verify - Do NOT execute the task itself or write application code - The script does NOT use ‘set -e‘ -- all commands run even if some fail End your response with a ‘‘‘bash fenced code block containing the verification commands....
-
[63]
The verifier must use pytest
-
[64]
‘test_outputs_py‘ must contain valid Python source code
-
[65]
Tests must be black-box
-
[66]
Prefer verifying via files, command behavior, local HTTP behavior, or deterministic end-to-end examples
-
[67]
Tests must be deterministic and self-contained. 33
-
[68]
Avoid network access unless the task explicitly requires localhost access
-
[69]
Only add packages required by the verifier itself
-
[70]
Put any extra test assets into ‘helper_files‘
-
[71]
Do not generate explanations outside the JSON. # Instruction {instruction} # Evaluation Criteria {evaluation_criteria} # Target Output File {target_output_file} # Initial Text Files (ACTUAL CONTENT -- already present in environment) IMPORTANT: These files already exist when the agent starts. DO NOT test for them. They are provided as context only. {initia...
-
[72]
Low score = just writing files or trivial echo commands
terminal_nativeness Does the task genuinely require terminal CLI operations (compilers, package managers, system commands, build tools, network tools)? High score = real CLI toolchain required. Low score = just writing files or trivial echo commands
-
[73]
Low score = environment is empty, irrelevant, or contradicts the task
env_task_consistency Do the pre-placed environment files and setup precisely match what the instruction requires? High score = environment provides exactly the right scaffolding, 35 no excess or gap. Low score = environment is empty, irrelevant, or contradicts the task
-
[74]
Low score = files are fabricated stubs, have obvious bugs, or are missing critical dependencies
env_quality Are the environment files (Dockerfile, setup.sh, initial files) well-formed and credible? High score = files are realistic, complete, and executable. Low score = files are fabricated stubs, have obvious bugs, or are missing critical dependencies
-
[75]
verifier_robustness Do the pytest assertions in tests/ accurately distinguish task-complete from task-incomplete? High score = assertions are specific, cover all key acceptance criteria from the instruction, low false-positive risk. Low score = only checks file existence, or assertions are unrelated to the instruction requirements. Important: if a dimensi...
-
[76]
We show all six artifacts verbatim
Example E.1illustratesTask Generation(§3.2): from a single (Skill S, Persona U) pair to the synthesized quadruple(I,E,V,G). We show all six artifacts verbatim
-
[77]
Example E.2illustratesEnvironment Building(§3.3): a three-file blueprint is routed through three different sub-agents of the multi-agent GVR architecture, producing the initial files F , setup scriptB env, and pytest verifierT test
-
[78]
Example E.3illustratesTrajectory Collection(§3.4): a multi-turn teacher-model rollout with verbatimanalysis/plan/commands/observationfor four representative steps. E.1 Example 1: Task Generation — ELF Binary Parsing (Astrophysics)Back to ToC /codeStage-Focused Example 1|Stage: Task Generation (§3.2) ❶ InputS— Agent Skill --- name: elf-binary-analysis desc...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.