Calibration vs Decision Making: Revisiting the Reliability Paradox in Unlearned Language Models
Pith reviewed 2026-05-21 04:42 UTC · model grok-4.3
The pith
Unlearned language models retain low calibration while increasing reliance on spurious correlations for decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
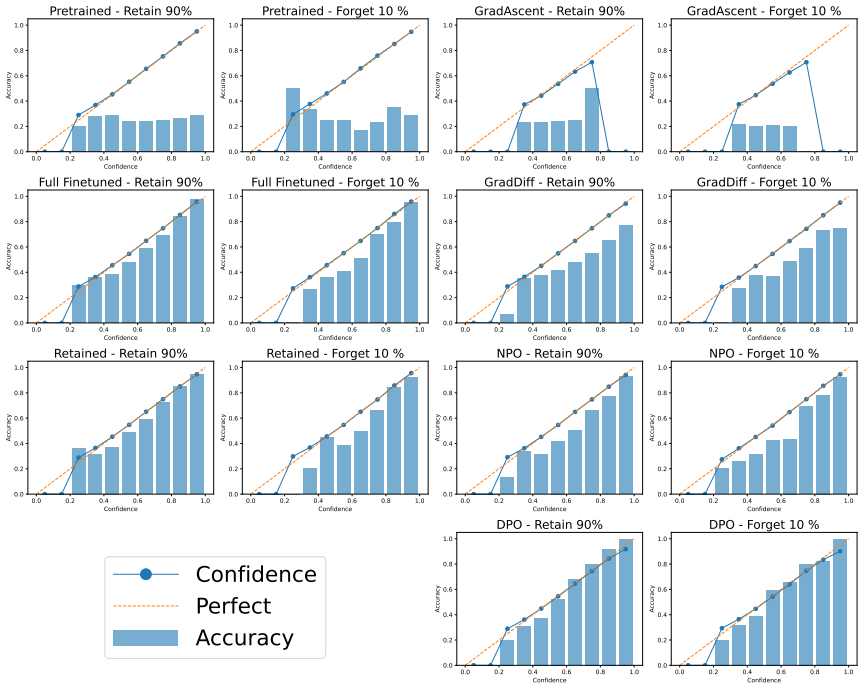
Fine-tuned models achieve low calibration error (ECE around 0.04) compared to pretrained models (ECE over 0.5) on the TOFU benchmark. Models after unlearning retain similarly low calibration on the forget split despite reduced accuracy, while attribution analysis shows increased reliance on correlation-based tokens. These results demonstrate that good calibration can coexist with shortcut-based decision rules after unlearning.
What carries the argument
Attribution-based shortcut detection with Integrated Gradients and Local Mutual Information, used to identify when models depend on spurious correlation tokens instead of true features.
If this is right
- Calibration error alone cannot confirm that unlearning has removed unwanted data influences.
- Models can appear probabilistically reliable while basing answers on shortcut patterns.
- Unlearning evaluations must add checks for decision-rule quality beyond calibration scores.
- Drops in accuracy on forgotten data may reflect a shift toward correlation-driven choices.
Where Pith is reading between the lines
- Unlearning methods may need explicit penalties against spurious token reliance to achieve deeper removal of influences.
- Similar calibration-decision gaps could appear in related techniques such as model editing or continued training.
- Applying the same attribution checks across other unlearning benchmarks would test whether the pattern is general.
Load-bearing premise
The attribution methods correctly flag reliance on spurious correlations rather than genuine predictive features.
What would settle it
A follow-up experiment that shows the high-attribution tokens after unlearning are causally relevant features and not mere correlations would refute the claim of increased shortcut use.
Figures



read the original abstract
Machine unlearning aims to remove the influence of specific training data from a model while preserving reliable behavior on the remaining data, making reliable prediction and uncertainty estimation essential for evaluation. Calibration is commonly used as a proxy for reliability in language models, but low calibration error does not necessarily imply reliable decision rules, as models may rely on spurious correlations while remaining well calibrated. We investigate this gap in generative language models using the multiple-choice question-answering evaluation protocol on the TOFU benchmark, measuring probabilistic reliability with calibration metrics (ECE, MCE, Brier) and decision-rule reliability via attribution-based shortcut detection with Integrated Gradients and Local Mutual Information. We find that fine-tuned models achieve low calibration error (ECE ~ 0.04) compared to pretrained models (ECE > 0.5), and models after unlearning retain similarly low calibration despite reduced accuracy on the forget split, while attribution analysis shows increased reliance on correlation-based tokens. These results demonstrate that good calibration can coexist with shortcut-based decision rules after unlearning, extending the reliability paradox to the machine unlearning setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether calibration metrics reliably indicate decision-making quality in unlearned language models. Using the TOFU benchmark and a multiple-choice QA protocol, it compares pretrained, fine-tuned, and unlearned models on calibration (ECE, MCE, Brier score) and decision-rule reliability via Integrated Gradients and Local Mutual Information attribution. The central claim is that unlearned models retain low calibration error (ECE ~0.04, similar to fine-tuned models) despite reduced accuracy on the forget split, while showing increased reliance on correlation-based tokens, extending the reliability paradox to the unlearning setting.
Significance. If the attribution results hold, the work usefully demonstrates that calibration can coexist with shortcut-based rules after unlearning, which has direct implications for how unlearning success is evaluated beyond accuracy or calibration alone. The combination of standard calibration metrics with attribution analysis on a public benchmark is a constructive approach, and the empirical comparison across model stages provides a clear baseline for future unlearning studies.
major comments (1)
- [Attribution analysis] Attribution analysis section: The central claim that unlearned models exhibit 'increased reliance on correlation-based tokens' as evidence of shortcut-based decision rules rests on Integrated Gradients and Local Mutual Information correctly distinguishing spurious correlations from valid post-unlearning features. Without ground-truth validation (e.g., synthetic data with known shortcuts or controls on the TOFU forget split), the attributions could instead reflect adaptation to remaining legitimate signals, weakening support for the reliability-paradox extension.
minor comments (3)
- [Results] The abstract and results report ECE ~0.04 and >0.5 but should include exact values, standard deviations across runs, and statistical significance tests for the calibration comparisons.
- [Methods] Clarify how 'correlation-based tokens' are operationalized and distinguished from other predictive features in the Local Mutual Information computation.
- [Discussion] Add a limitations paragraph discussing potential sensitivity of the attribution method to the choice of baseline or integration steps.
Simulated Author's Rebuttal
We are grateful to the referee for their positive assessment of the significance of our work and for the detailed feedback. We have carefully considered the major comment and outline our response and planned revisions below.
read point-by-point responses
-
Referee: [Attribution analysis] Attribution analysis section: The central claim that unlearned models exhibit 'increased reliance on correlation-based tokens' as evidence of shortcut-based decision rules rests on Integrated Gradients and Local Mutual Information correctly distinguishing spurious correlations from valid post-unlearning features. Without ground-truth validation (e.g., synthetic data with known shortcuts or controls on the TOFU forget split), the attributions could instead reflect adaptation to remaining legitimate signals, weakening support for the reliability-paradox extension.
Authors: Thank you for this insightful comment. We acknowledge that without explicit ground-truth labels for spurious versus legitimate features on the TOFU dataset, the attribution results are suggestive rather than definitive. Our claim is supported by the differential analysis: the increase in attribution to correlation-based tokens is observed specifically after unlearning, compared to the fine-tuned model which retains high accuracy. This pattern is consistent with shortcut reliance as the model compensates for removed knowledge. Nevertheless, to strengthen the manuscript, we will add a limitations paragraph discussing the need for synthetic benchmarks in future work and include qualitative inspection of the top-attributed tokens to illustrate their correlation-based nature (e.g., specific names or dates that are not core to the question semantics). We believe this addresses the concern while maintaining the contribution of applying attribution to unlearning evaluation. revision: partial
Circularity Check
Empirical evaluation on public benchmark with no circular derivation
full rationale
The paper is an empirical study that applies established calibration metrics (ECE, MCE, Brier) and attribution techniques (Integrated Gradients, Local Mutual Information) to pretrained, fine-tuned, and unlearned models on the public TOFU benchmark. No derivation chain reduces any result to its inputs by construction, no parameters are fitted and then relabeled as predictions, and no load-bearing claims rest on self-citations or uniqueness theorems. The central observation—that low calibration can coexist with increased attribution to correlation-based tokens—is a direct experimental finding rather than a self-referential or fitted outcome, rendering the analysis self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The TOFU benchmark and multiple-choice QA protocol is a valid way to evaluate unlearning and reliability.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We measure probabilistic reliability with calibration metrics (ECE, MCE, Brier) and decision-rule reliability via attribution-based shortcut detection with Integrated Gradients and Local Mutual Information.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
models after unlearning retain similarly low calibration despite reduced accuracy on the forget split, while attribution analysis shows increased reliance on correlation-based tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =
Sundararajan, Mukund and Taly, Ankur and Yan, Qiqi , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , publisher =
work page 2017
- [10]
-
[13]
TOFU: A Task of Fictitious Unlearning for LLMs , author=. 2024 , eprint=
work page 2024
-
[17]
Izmailov, Pavel and Kirichenko, Polina and Gruver, Nate and Wilson, Andrew Gordon , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
work page 2022
-
[20]
Singhal, Karan and Tu, Tao and Gottweis, Juraj and Sayres, Rory and Wulczyn, Ellery and Amin, Mohamed and Hou, Le and Clark, Kevin and Pfohl, Stephen R. and Cole-Lewis, Heather and Neal, Darlene and Rashid, Qazi Mamunur and Schaekermann, Mike and Wang, Amy and Dash, Dev and Chen, Jonathan H. and Shah, Nigam H. and Lachgar, Sami and Mansfield, Philip Andre...
work page 2025
-
[21]
Maity, Subhankar and Saikia, Manob Jyoti , TITLE =. Bioengineering , VOLUME =. 2025 , NUMBER =
work page 2025
-
[25]
Mukhoti, Jishnu and Kulharia, Viveka and Sanyal, Amartya and Golodetz, Stuart and Torr, Philip H. S. and Dokania, Puneet K. , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
work page 2020
-
[26]
On Calibration of Multilingual Question Answering
Yahan Yang and Soham Dan and Dan Roth and Insup Lee , journal=. On Calibration of Multilingual Question Answering. 2026 , url=
work page 2026
-
[27]
Yezi Liu and Hanning Chen and Wenjun Huang and Yang Ni and Mohsen Imani , booktitle=. 2025 , url=
work page 2025
-
[28]
Recover-to-Forget: Gradient Reconstruction from Lo
Yezi Liu and Hanning Chen and Wenjun Huang and Yang Ni and Mohsen Imani , booktitle=. Recover-to-Forget: Gradient Reconstruction from Lo. 2025 , url=
work page 2025
-
[29]
U-CAN: Utility-Aware Contrastive Attenuation for Efficient Unlearning in Generative Recommendation , author=. 2026 , eprint=
work page 2026
- [30]
-
[31]
A Study on Large Language Models' Limitations in Multiple-Choice Question Answering , author=. 2024 , eprint=
work page 2024
-
[32]
Towards Making Systems Forget with Machine Unlearning , year=
Cao, Yinzhi and Yang, Junfeng , booktitle=. Towards Making Systems Forget with Machine Unlearning , year=
-
[33]
Who's Harry Potter? Approximate Unlearning in LLMs , author=. 2023 , eprint=
work page 2023
-
[34]
Making AI Forget You: Data Deletion in Machine Learning , url =
Ginart, Antonio and Guan, Melody and Valiant, Gregory and Zou, James Y , booktitle =. Making AI Forget You: Data Deletion in Machine Learning , url =
-
[35]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning , author=. 2024 , eprint=
work page 2024
-
[36]
MUSE: Machine Unlearning Six-Way Evaluation for Language Models , author=. 2024 , eprint=
work page 2024
-
[37]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning , author=. 2024 , eprint=
work page 2024
- [38]
- [39]
-
[40]
Basit Ali, Sachin Pawar, Girish Palshikar, Anindita Sinha Banerjee, and Dhirendra Singh. 2023. https://doi.org/10.18653/v1/2023.argmining-1.6 Legal argument extraction from court judgements using integer linear programming . In Proceedings of the 10th Workshop on Argument Mining, pages 52--63, Singapore. Association for Computational Linguistics
- [41]
-
[42]
Yinzhi Cao and Junfeng Yang. 2015. https://doi.org/10.1109/SP.2015.35 Towards making systems forget with machine unlearning . In 2015 IEEE Symposium on Security and Privacy, pages 463--480
-
[43]
Mengnan Du, Fengxiang He, Na Zou, Dacheng Tao, and Xia Hu. 2023. https://doi.org/10.1145/3596490 Shortcut learning of large language models in natural language understanding . Commun. ACM, 67(1):110–120
-
[44]
Mengnan Du, Varun Manjunatha, Rajiv Jain, Ruchi Deshpande, Franck Dernoncourt, Jiuxiang Gu, Tong Sun, and Xia Hu. 2021. https://doi.org/10.18653/v1/2021.naacl-main.71 Towards interpreting and mitigating shortcut learning behavior of NLU models . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Lingui...
- [45]
-
[46]
Leon Eshuijs, Shihan Wang, and Antske Fokkens. 2025. https://doi.org/10.18653/v1/2025.conll-1.8 Short-circuiting shortcuts: Mechanistic investigation of shortcuts in text classification . In Proceedings of the 29th Conference on Computational Natural Language Learning, pages 105--125, Vienna, Austria. Association for Computational Linguistics
-
[47]
Antonio Ginart, Melody Guan, Gregory Valiant, and James Y Zou. 2019. https://proceedings.neurips.cc/paper_files/paper/2019/file/cb79f8fa58b91d3af6c9c991f63962d3-Paper.pdf Making ai forget you: Data deletion in machine learning . In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc
work page 2019
-
[48]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. 2017. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, page 1321–1330. JMLR.org
work page 2017
-
[50]
Pavel Izmailov, Polina Kirichenko, Nate Gruver, and Andrew Gordon Wilson. 2022. On feature learning in the presence of spurious correlations. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA. Curran Associates Inc
work page 2022
-
[51]
Abhinav Joshi, Shaswati Saha, Divyaksh Shukla, Sriram Vema, Harsh Jhamtani, Manas Gaur, and Ashutosh Modi. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.706 Towards robust evaluation of unlearning in LLM s via data transformations . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 12100--12119, Miami, Florida, USA. A...
-
[52]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, and 38 others. 2024. https://arxiv.org/abs/2403.03218 The wmdp be...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [53]
-
[54]
Yezi Liu, Hanning Chen, Wenjun Huang, Yang Ni, and Mohsen Imani. 2025 a . https://openreview.net/forum?id=Dim7kQ8Kol LUNE : Efficient LLM unlearning via lo RA fine-tuning with negative examples . In Socially Responsible and Trustworthy Foundation Models at NeurIPS 2025
work page 2025
-
[55]
Yezi Liu, Hanning Chen, Wenjun Huang, Yang Ni, and Mohsen Imani. 2025 b . https://openreview.net/forum?id=n7peBaPUmk Recover-to-forget: Gradient reconstruction from lo RA for efficient LLM unlearning . In Socially Responsible and Trustworthy Foundation Models at NeurIPS 2025
work page 2025
-
[56]
TOFU: A Task of Fictitious Unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. 2024. https://arxiv.org/abs/2401.06121 Tofu: A task of fictitious unlearning for llms . Preprint, arXiv:2401.06121
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Subhankar Maity and Manob Jyoti Saikia. 2025. https://doi.org/10.3390/bioengineering12060631 Large language models in healthcare and medical applications: A review . Bioengineering, 12(6)
-
[58]
Jishnu Mukhoti, Viveka Kulharia, Amartya Sanyal, Stuart Golodetz, Philip H. S. Torr, and Puneet K. Dokania. 2020. Calibrating deep neural networks using focal loss. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS '20, Red Hook, NY, USA. Curran Associates Inc
work page 2020
-
[59]
Maja Pavlovic. 2025. https://iclr-blogposts.github.io/2025/blog/calibration/ Understanding model calibration - a gentle introduction and visual exploration of calibration and the expected calibration error (ece) . In ICLR Blogposts 2025. Https://iclr-blogposts.github.io/2025/blog/calibration/
work page 2025
-
[60]
Danish Pruthi, Mansi Gupta, Bhuwan Dhingra, Graham Neubig, and Zachary C. Lipton. 2020. https://doi.org/10.18653/v1/2020.acl-main.432 Learning to deceive with attention-based explanations . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4782--4793, Online. Association for Computational Linguistics
-
[61]
Gabriele Sarti, Nils Feldhus, Ludwig Sickert, Oskar van der Wal, Malvina Nissim, and Arianna Bisazza. 2023. https://doi.org/10.18653/v1/2023.acl-demo.40 Inseq: An interpretability toolkit for sequence generation models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 421-...
-
[62]
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. 2024. https://arxiv.org/abs/2407.06460 Muse: Machine unlearning six-way evaluation for language models . Preprint, arXiv:2407.06460
-
[63]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R. Pfohl, Heather Cole-Lewis, Darlene Neal, Qazi Mamunur Rashid, Mike Schaekermann, Amy Wang, Dev Dash, Jonathan H. Chen, Nigam H. Shah, Sami Lachgar, Philip Andrew Mansfield, and 16 others. 2025. https://doi.org/10.1038/s41591-024-03423-7 Toward...
-
[64]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, page 3319–3328. JMLR.org
work page 2017
-
[65]
Tianlu Wang, Rohit Sridhar, Diyi Yang, and Xuezhi Wang. 2022. https://doi.org/10.18653/v1/2022.findings-naacl.130 Identifying and mitigating spurious correlations for improving robustness in NLP models . In Findings of the Association for Computational Linguistics: NAACL 2022, pages 1719--1729, Seattle, United States. Association for Computational Linguistics
- [66]
-
[67]
Yahan Yang, Soham Dan, Dan Roth, and Insup Lee. 2026. https://openreview.net/forum?id=4klghu2PTj On calibration of multilingual question answering LLM s . Transactions on Machine Learning Research
work page 2026
-
[68]
Yu Yuan, Lili Zhao, Kai Zhang, Guangting Zheng, and Qi Liu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.679 Do LLM s overcome shortcut learning? an evaluation of shortcut challenges in large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 12188--12200, Miami, Florida, USA. Associatio...
-
[69]
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. 2024. https://arxiv.org/abs/2404.05868 Negative preference optimization: From catastrophic collapse to effective unlearning . Preprint, arXiv:2404.05868
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Haoxi Zhong, Chaojun Xiao, Cunchao Tu, Tianyang Zhang, Zhiyuan Liu, and Maosong Sun. 2020. https://doi.org/10.18653/v1/2020.acl-main.466 How does NLP benefit legal system: A summary of legal artificial intelligence . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5218--5230, Online. Association for Comput...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.