Single-Pass, Depth-Selective Reading for Multi-Aspect Sentiment Analysis
Pith reviewed 2026-05-21 05:28 UTC · model grok-4.3
The pith
DABS performs multi-aspect sentiment analysis in a single Transformer pass by building a shared depth-ordered substrate that each aspect can selectively read from.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DABS is a single-pass inference framework that encodes each sentence once to construct a reusable, depth-ordered substrate. Each aspect then queries this shared representation to selectively read relevant tokens and abstraction levels without re-encoding the sentence. This decouples the shared sentence encoding from lightweight, aspect-conditioned readout.
What carries the argument
The depth-ordered substrate created by a single forward pass through the Transformer, which serves as a queryable resource for aspect-specific selective reading of tokens and abstraction levels.
If this is right
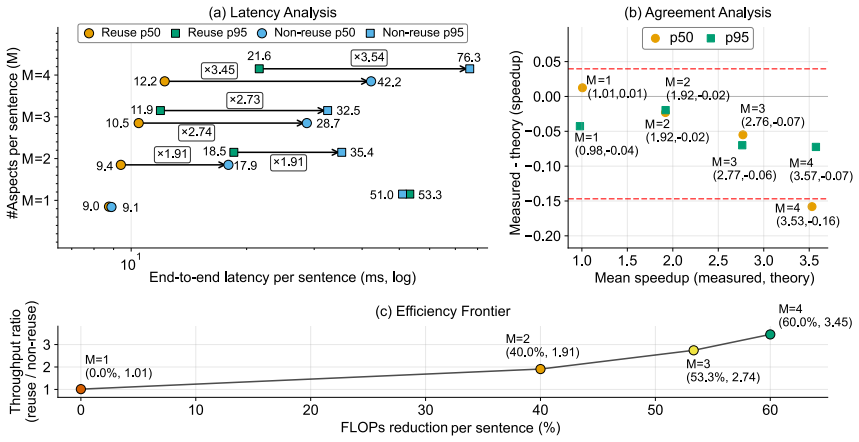
- Competitive performance on four ATSA benchmarks while reducing end-to-end computation by up to 60% in multi-aspect settings.
- Adaptive depth querying proves most beneficial for linguistically complex cases such as negation and contrast.
- The framework maintains expressiveness by allowing each aspect to select its own relevant information from the shared substrate.
- End-to-end computation is decoupled into one shared encoding and multiple lightweight readouts.
Where Pith is reading between the lines
- This selective reading strategy could extend to other multi-query settings in NLP where several labels or questions apply to the same input text.
- By reducing redundant computations, the method may lower energy use in deployed sentiment analysis systems processing many aspects.
- Further exploration could test whether the depth-ordering property holds across different Transformer architectures or pre-training objectives.
Load-bearing premise
A single forward pass through the Transformer produces a reusable, depth-ordered substrate from which aspect-specific selective reading can recover the necessary token and abstraction information without material loss of expressiveness or accuracy.
What would settle it
An experiment showing that aspect-specific selective readout from the single-pass substrate yields substantially lower accuracy than full per-aspect re-encoding on the same benchmarks.
Figures



read the original abstract
Aspect-Term Sentiment Analysis (ATSA) in multi-aspect sentences faces a fundamental tradeoff between efficiency and expressiveness. Existing models either re-encode the sentence for each aspect or rely on static use of deep representations, leading to redundant computation and limited adaptivity. We argue that Transformer depth is a costly, queryable resource, and propose DABS, a single-pass inference framework that encodes each sentence once to construct a reusable, depth-ordered substrate. Each aspect then queries this shared representation to selectively read relevant tokens and abstraction levels, without re-encoding. This decouples shared sentence encoding from lightweight, aspect-conditioned readout. Experiments on four ATSA benchmarks show that DABS achieves competitive performance while reducing end-to-end computation by up to 60% in multi-aspect settings (M >= 2). Further analyses indicate that adaptive depth querying is most beneficial for linguistically complex cases such as negation and contrast. Code is publicly available at https://github.com/panzhzh/acl-dabs
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DABS, a single-pass inference framework for Aspect-Term Sentiment Analysis (ATSA) in multi-aspect sentences. A Transformer encodes the input sentence once to produce a reusable, depth-ordered substrate; each aspect then performs lightweight, aspect-conditioned selective reading over tokens and abstraction levels from this shared representation, avoiding per-aspect re-encoding. On four ATSA benchmarks the method reports competitive accuracy while reducing end-to-end computation by up to 60% when the number of aspects M ≥ 2, with additional gains noted for linguistically complex phenomena such as negation and contrast. Code is released publicly.
Significance. If the central premise holds—that a fixed depth-ordered substrate from one forward pass supplies sufficient information for aspect-specific readout without material loss of expressiveness—the work offers a practical route to lowering inference cost in multi-aspect settings. The public code release supports reproducibility and allows direct verification of the claimed speed-ups. The approach is most relevant to efficiency-critical deployments where multiple aspects must be scored from the same sentence.
major comments (2)
- [§3.2] §3.2 (Selective Reading Module): the description states that the readout uses lightweight attention or gating over the fixed substrate, yet provides no mechanism for aspect-specific re-contextualization of tokens. When aspects induce opposing polarities (e.g., “great battery but poor screen”), the same token representations must be re-weighted differently per aspect; it is unclear whether the fixed activations plus lightweight readout can perform this adaptation without the re-encoding performed by the baselines.
- [§4.3] §4.3 (Experimental Results, Table 2): the 60% end-to-end reduction is reported relative to re-encoding baselines, but the table does not list per-baseline FLOPs or wall-clock times, nor does it report statistical significance (e.g., paired t-tests or bootstrap intervals) across the four benchmarks. Without these, it is difficult to judge whether the efficiency gain is robust or sensitive to post-hoc implementation choices.
minor comments (2)
- [Abstract / §1] The abstract and §1 refer to “four ATSA benchmarks” without naming them; the introduction or experimental setup should explicitly list the datasets (e.g., SemEval-2014 Task 4, etc.) for immediate clarity.
- [§3.1] Notation for the depth-ordered substrate (e.g., the tensor H_d in Eq. (3)) is introduced without an accompanying diagram; a small schematic showing how depth indices map to layers would aid readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our work. We address each of the major comments below and outline the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Selective Reading Module): the description states that the readout uses lightweight attention or gating over the fixed substrate, yet provides no mechanism for aspect-specific re-contextualization of tokens. When aspects induce opposing polarities (e.g., “great battery but poor screen”), the same token representations must be re-weighted differently per aspect; it is unclear whether the fixed activations plus lightweight readout can perform this adaptation without the re-encoding performed by the baselines.
Authors: We appreciate the referee pointing out the need for clearer explanation of aspect-specific adaptation. In the DABS framework, the Selective Reading Module conditions the lightweight attention and gating operations directly on aspect-specific embeddings. This allows the model to dynamically re-weight both individual tokens and different abstraction levels from the shared depth-ordered substrate in an aspect-dependent manner. For instance, in sentences with opposing polarities, the aspect query can emphasize positive or negative cues accordingly. Our analyses on complex linguistic phenomena demonstrate the effectiveness of this approach. To address the concern, we will revise §3.2 to include more explicit description of the conditioning mechanism, along with an illustrative example. revision: yes
-
Referee: [§4.3] §4.3 (Experimental Results, Table 2): the 60% end-to-end reduction is reported relative to re-encoding baselines, but the table does not list per-baseline FLOPs or wall-clock times, nor does it report statistical significance (e.g., paired t-tests or bootstrap intervals) across the four benchmarks. Without these, it is difficult to judge whether the efficiency gain is robust or sensitive to post-hoc implementation choices.
Authors: We agree that including detailed efficiency metrics and statistical analysis would enhance the presentation of results. We will update Table 2 to report FLOPs and wall-clock times for each baseline method. Furthermore, we will add statistical significance tests, such as paired t-tests or bootstrap intervals, computed across the four benchmarks to confirm the robustness of the reported speed-ups. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: architectural proposal validated by end-to-end empirical measurements
full rationale
The paper introduces DABS as a new single-pass Transformer framework that encodes the sentence once into a depth-ordered substrate and then performs lightweight aspect-conditioned selective readout. All reported gains (up to 60% computation reduction for M >= 2) are obtained from direct experimental timing and accuracy measurements on four ATSA benchmarks rather than from any fitted parameter that is subsequently renamed as a prediction. No equations, uniqueness theorems, or ansatzes are shown to reduce to their own inputs by construction, and the central premise is not justified solely by self-citation. The derivation chain therefore remains self-contained and independent of the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer depth provides a reusable, ordered set of representations that can be selectively read without re-encoding the sentence.
invented entities (1)
-
depth-ordered substrate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DABS first constructs a reusable depth substrate via Depth-Ordered Representation Aggregation (DORA) ... gated recurrence over the last K layers ... Aspect-Conditioned Budget-Aware Selection (ACBS)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
single-pass inference framework that encodes each sentence once
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ruan, Zhiwen and Li, Yixia and Zhu, He and Wang, Longyue and Luo, Weihua and Zhang, Kaifu and Chen, Yun and Chen, Guanhua. L ay A lign: Enhancing Multilingual Reasoning in Large Language Models via Layer-Wise Adaptive Fusion and Alignment Strategy. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.81
-
[2]
PASTEL : Polarity-Aware Sentiment Triplet Extraction with LLM -as-a-Judge
Bodke, Aaditya and Kohli, Avinoor Singh and Pardeshi, Hemant Subhash and Bhosale, Prathamesh. PASTEL : Polarity-Aware Sentiment Triplet Extraction with LLM -as-a-Judge. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1309
-
[3]
Simmering and Paavo Huoviala , title =
Paul F. Simmering and Paavo Huoviala , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.18025 , eprinttype =. 2310.18025 , timestamp =
-
[4]
Fukun Ma and Xuming Hu and Aiwei Liu and Yawen Yang and Shuang Li and Philip S. Yu and Lijie Wen , editor =. AMR-based Network for Aspect-based Sentiment Analysis , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.19 , timestamp =
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
TextGT: A Double-View Graph Transformer on Text for Aspect-Based Sentiment Analysis , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , doi =
work page 2024
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
You Only Read Once: Constituency-Oriented Relational Graph Convolutional Network for Multi-Aspect Multi-Sentiment Classification , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , doi =
work page 2024
-
[7]
Song Jin and Qing He and Yuji Wang and Nisuo Du and Wenjing Lei , title =. Eng. Appl. Artif. Intell. , volume =. 2025 , url =. doi:10.1016/J.ENGAPPAI.2025.111654 , timestamp =
-
[8]
Nils Constantin Hellwig and Jakob Fehle and Christian Wolff , title =. Expert Syst. Appl. , volume =. 2025 , url =. doi:10.1016/J.ESWA.2024.125514 , timestamp =
-
[9]
Siyu Zhang and Hongfang Gong and Lina She , title =. Knowl. Based Syst. , volume =. 2023 , url =. doi:10.1016/J.KNOSYS.2023.110662 , timestamp =
-
[10]
Exploring Graph Pre-training for Aspect-based Sentiment Analysis
Bao, Xiaoyi and Wang, Zhongqing and Zhou, Guodong. Exploring Graph Pre-training for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.234
-
[11]
Shen, Chuming and Wei, Wei and Wang, Dong and Wang, Zhong-Hao. Zero-Shot Cross-Domain Aspect-Based Sentiment Analysis via Domain-Contextualized Chain-of-Thought Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.245
-
[12]
I nstruct ABSA : Instruction Learning for Aspect Based Sentiment Analysis
Scaria, Kevin and Gupta, Himanshu and Goyal, Siddharth and Sawant, Saurabh and Mishra, Swaroop and Baral, Chitta. I nstruct ABSA : Instruction Learning for Aspect Based Sentiment Analysis. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers)....
-
[13]
Mukherjee, Rajdeep and Kannen, Nithish and Pandey, Saurabh and Goyal, Pawan. CONTRASTE : Supervised Contrastive Pre-training With Aspect-based Prompts For Aspect Sentiment Triplet Extraction. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.807
-
[14]
M v P : Multi-view Prompting Improves Aspect Sentiment Tuple Prediction
Gou, Zhibin and Guo, Qingyan and Yang, Yujiu. M v P : Multi-view Prompting Improves Aspect Sentiment Tuple Prediction. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.240
-
[15]
Instruction Tuning with Retrieval-based Examples Ranking for Aspect-based Sentiment Analysis
Zheng, Guangmin and Wang, Jin and Yu, Liang-Chih and Zhang, Xuejie. Instruction Tuning with Retrieval-based Examples Ranking for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.284
-
[16]
i ACOS : Advancing Implicit Sentiment Extraction with Informative and Adaptive Negative Examples
Xu, Xiancai and Zhang, Jia-Dong and Xiong, Lei and Liu, Zhishang. i ACOS : Advancing Implicit Sentiment Extraction with Informative and Adaptive Negative Examples. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/202...
-
[17]
Aspect-to-Scope Oriented Multi-view Contrastive Learning for Aspect-based Sentiment Analysis
Chai, Heyan and Yao, Ziyi and Tang, Siyu and Wang, Ye and Nie, Liqiang and Fang, Binxing and Liao, Qing. Aspect-to-Scope Oriented Multi-view Contrastive Learning for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.727
-
[18]
Pinpointing Diffusion Grid Noise to Enhance Aspect Sentiment Quad Prediction
Zhu, Linan and Chen, Xiangfan and Guo, Xiaolei and Zhang, Chenwei and Zhu, Zhechao and Zhou, Zehai and Kong, Xiangjie. Pinpointing Diffusion Grid Noise to Enhance Aspect Sentiment Quad Prediction. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.222
-
[19]
Investigating the Saliency of Sentiment Expressions in Aspect-Based Sentiment Analysis
Wagner, Joachim and Foster, Jennifer. Investigating the Saliency of Sentiment Expressions in Aspect-Based Sentiment Analysis. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.807
-
[20]
It is Simple Sometimes: A Study On Improving Aspect-Based Sentiment Analysis Performance
Cabello, Laura and Akujuobi, Uchenna. It is Simple Sometimes: A Study On Improving Aspect-Based Sentiment Analysis Performance. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.394
-
[21]
Seo, Yongsik and Song, Sungwon and Heo, Ryang and Kim, Jieyong and Lee, Dongha. Make Compound Sentences Simple to Analyze: Learning to Split Sentences for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.653
-
[22]
Span-level Aspect-based Sentiment Analysis via Table Filling
Zhang, Mao and Zhu, Yongxin and Liu, Zhen and Bao, Zhimin and Wu, Yunfei and Sun, Xing and Xu, Linli. Span-level Aspect-based Sentiment Analysis via Table Filling. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.515
-
[23]
Wang, Zhihao and Zhang, Bo and Yang, Ru and Guo, Chang and Li, Maozhen. DAGCN : Distance-based and Aspect-oriented Graph Convolutional Network for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.120
-
[24]
L ayer S kip: Enabling Early Exit Inference and Self-Speculative Decoding
Elhoushi, Mostafa and Shrivastava, Akshat and Liskovich, Diana and Hosmer, Basil and Wasti, Bram and Lai, Liangzhen and Mahmoud, Anas and Acun, Bilge and Agarwal, Saurabh and Roman, Ahmed and Aly, Ahmed and Chen, Beidi and Wu, Carole-Jean. L ayer S kip: Enabling Early Exit Inference and Self-Speculative Decoding. Proceedings of the 62nd Annual Meeting of ...
-
[25]
Bae, Sangmin and Ko, Jongwoo and Song, Hwanjun and Yun, Se-Young. Fast and Robust Early-Exiting Framework for Autoregressive Language Models with Synchronized Parallel Decoding. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.362
-
[26]
The Impact of Depth on Compositional Generalization in Transformer Language Models
Petty, Jackson and Steenkiste, Sjoerd and Dasgupta, Ishita and Sha, Fei and Garrette, Dan and Linzen, Tal. The Impact of Depth on Compositional Generalization in Transformer Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
-
[27]
Opinion Tree Parsing for Aspect-based Sentiment Analysis
Bao, Xiaoyi and Jiang, Xiaotong and Wang, Zhongqing and Zhang, Yue and Zhou, Guodong. Opinion Tree Parsing for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.505
-
[28]
Boosting Large Language Models with Continual Learning for Aspect-based Sentiment Analysis
Ding, Xuanwen and Zhou, Jie and Dou, Liang and Chen, Qin and Wu, Yuanbin and Chen, Arlene and He, Liang. Boosting Large Language Models with Continual Learning for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.252
-
[29]
Efficient Hybrid Generation Framework for Aspect-Based Sentiment Analysis
Lv, Haoran and Liu, Junyi and Wang, Henan and Wang, Yaoming and Luo, Jixiang and Liu, Yaxiao. Efficient Hybrid Generation Framework for Aspect-Based Sentiment Analysis. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.71
-
[30]
Qihuang Zhong and Liang Ding and Juhua Liu and Bo Du and Hua Jin and Dacheng Tao , title =. 2023 , url =. doi:10.1109/TKDE.2023.3250499 , timestamp =
-
[31]
Hongtao Liu and Xin Li and Wanying Lu and Kefei Cheng and Xueyan Liu , title =. Expert Syst. Appl. , volume =. 2024 , url =. doi:10.1016/J.ESWA.2024.123981 , timestamp =
-
[32]
Ao Feng and Jiazhi Cai and Zhengjie Gao and Xiaojie Li , title =. J. Big Data , volume =. 2023 , url =. doi:10.1186/S40537-023-00856-8 , timestamp =
-
[33]
Xuefeng Shi and Min Hu and Fuji Ren and Piao Shi and Satoshi Nakagawa , title =. Appl. Intell. , volume =. 2024 , url =. doi:10.1007/S10489-024-05492-0 , timestamp =
-
[34]
ZhongQuan Jian and Jiajian Li and Qingqiang Wu and Junfeng Yao , title =. Inf. Process. Manag. , volume =. 2024 , url =. doi:10.1016/J.IPM.2023.103539 , timestamp =
-
[35]
Bo He and Ruoyu Zhao and Dali Tang , title =. Knowl. Based Syst. , volume =. 2025 , url =. doi:10.1016/J.KNOSYS.2024.112782 , timestamp =
-
[36]
Aspect-Based Sentiment Analysis with Syntax-Opinion-Sentiment Reasoning Chain
Fan, Rui and Li, Shu and He, Tingting and Liu, Yu. Aspect-Based Sentiment Analysis with Syntax-Opinion-Sentiment Reasoning Chain. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[37]
Sun, Xin and Mi, Yongqing and Li, Hongao , title =. 2025 , issue_date =. doi:10.1145/3721844 , journal =
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Jihong Ouyang and Zhiyao Yang and Silong Liang and Bing Wang and Yimeng Wang and Ximing Li , editor =. Aspect-Based Sentiment Analysis with Explicit Sentiment Augmentations , booktitle =. 2024 , url =. doi:10.1609/AAAI.V38I17.29849 , timestamp =
-
[39]
Yanyan Wang and Qun Chen and Murtadha H. M. Ahmed and Zhaoqiang Chen and Jing Su and Wei Pan and Zhanhuai Li , title =. Trans. Assoc. Comput. Linguistics , volume =. 2023 , url =. doi:10.1162/TACL\_A\_00571 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2023
-
[40]
S em E val-2014 Task 4: Aspect Based Sentiment Analysis
Maria Pontiki and Dimitris Galanis and John Pavlopoulos and Harris Papageorgiou and Ion Androutsopoulos and Suresh Manandhar , editor =. SemEval-2014 Task 4: Aspect Based Sentiment Analysis , booktitle =. 2014 , url =. doi:10.3115/V1/S14-2004 , timestamp =
-
[41]
S em E val-2015 Task 12: Aspect Based Sentiment Analysis
Maria Pontiki and Dimitris Galanis and Haris Papageorgiou and Suresh Manandhar and Ion Androutsopoulos , editor =. SemEval-2015 Task 12: Aspect Based Sentiment Analysis , booktitle =. 2015 , url =. doi:10.18653/V1/S15-2082 , timestamp =
-
[42]
S em E val-2016 Task 5: Aspect Based Sentiment Analysis
Pontiki, Maria and Galanis, Dimitris and Papageorgiou, Haris and Androutsopoulos, Ion and Manandhar, Suresh and AL-Smadi, Mohammad and Al-Ayyoub, Mahmoud and Zhao, Yanyan and Qin, Bing and De Clercq, Orph. S em E val-2016 Task 5: Aspect Based Sentiment Analysis. Proceedings of the 10th International Workshop on Semantic Evaluation ( S em E val-2016). 2016...
-
[43]
Jacob Devlin and Ming. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2019 , url =. doi:10.18653/V1/N19-1423 , timestamp =
-
[44]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. CoRR , volume =. 2019 , url =. 1907.11692 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[45]
The Eleventh International Conference on Learning Representations,
Pengcheng He and Jianfeng Gao and Weizhu Chen , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.