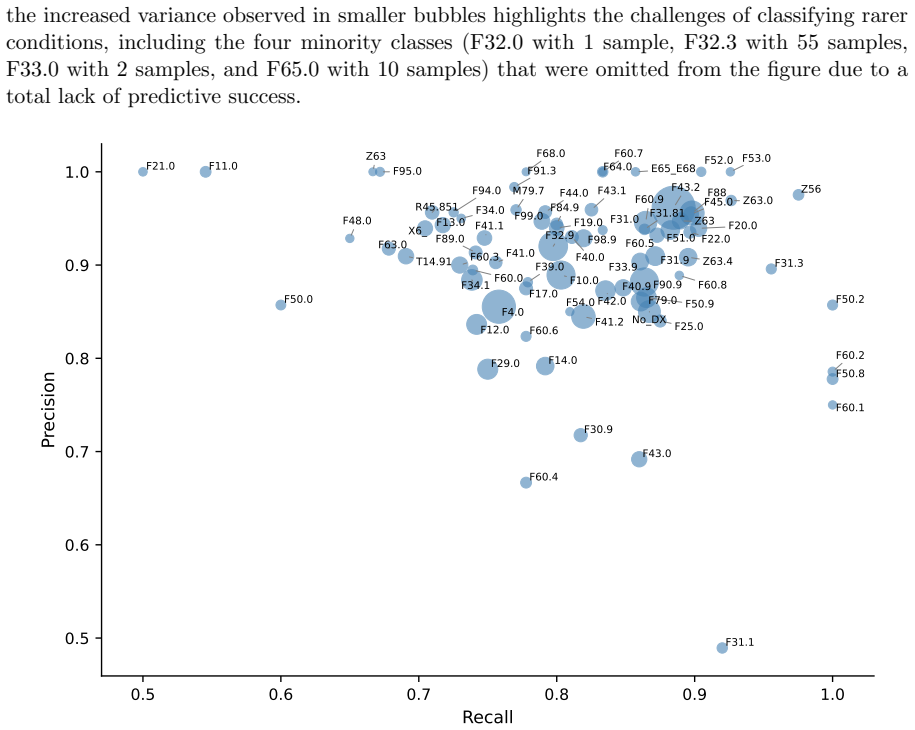
Automated ICD Classification of Psychiatric Diagnoses: From Classical NLP to Large Language Models
Pith reviewed 2026-05-21 04:42 UTC · model grok-4.3
The pith
Fine-tuned e5_large model classifies Spanish psychiatric descriptions to ICD codes at 0.866 F1 micro score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that transformer-based embeddings from large language models consistently outperform traditional NLP approaches in ICD classification of psychiatric text because they capture implicit semantic cues and specialized medical terminology. On the specialized dataset of 145,513 Spanish psychiatric descriptions, end-to-end fine-tuning of the e5_large model produces the strongest result with an F1_micro score of 0.866. This outcome indicates that domain-specific fine-tuning is required to manage long-tail label distributions and the inherent ambiguity of psychiatric discourse.
What carries the argument
End-to-end fine-tuning of the e5_large transformer model, which learns task-specific embeddings directly from the labeled psychiatric descriptions for multi-label ICD code prediction.
If this is right
- Transformer embeddings handle nuanced psychiatric terminology better than bag-of-words or TF-IDF vectors.
- End-to-end fine-tuning is necessary to adapt models to the long-tail distribution of ICD labels in mental health data.
- Automated classification reduces manual coding effort for clinicians dealing with free-text descriptions.
- Similar fine-tuning on other clinical domains could extend the approach beyond psychiatry.
Where Pith is reading between the lines
- Integration into electronic health record systems could offer real-time coding suggestions during note entry.
- Performance on rare diagnoses might improve with additional techniques such as data augmentation or hierarchical label modeling.
- The method could be adapted to support multilingual clinical coding by training on mixed-language datasets.
Load-bearing premise
The 145,513 Spanish psychiatric descriptions form a high-quality, accurately labeled dataset that represents real clinical language and the actual distribution of diagnosis codes.
What would settle it
Testing the fine-tuned e5_large model on an independently collected and labeled set of psychiatric descriptions from a different clinical source or region, and finding that the F1_micro score falls substantially below 0.866, would show the performance does not generalize.
Figures


read the original abstract
Mental health has become a global priority, leading to a massive administrative burden in the coding of clinical diagnoses. This study proposes the automation of psychiatric diagnostic analysis by mapping free-text descriptions to the International Classification of Diseases (ICD) using Natural Language Processing (NLP) and Machine Learning (ML) techniques. Utilizing a specialized dataset of 145,513 Spanish psychiatric descriptions, various text representation paradigms were evaluated, ranging from classical frequency-based models (BoW, TF-IDF) to state-of-the-art Large Language Models (LLMs) such as e5\_large, BioLORD, and Llama-3-8B. Results indicate that transformer-based embeddings consistently outperform traditional methods by capturing implicit semantic cues and nuanced medical terminology. The e5\_large model, through end-to-end fine-tuning, achieved the highest performance with a $F1_{micro}$ score of 0.866. This research demonstrates that adapting LLMs to specific clinical nomenclature is essential for overcoming the challenges of ``long-tail'' label distributions and the inherent ambiguity of psychiatric discourse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates classical NLP methods (BoW, TF-IDF) against transformer embeddings and LLMs (e5_large, BioLORD, Llama-3-8B) for mapping 145,513 Spanish psychiatric free-text descriptions to ICD codes. It claims that end-to-end fine-tuning of e5_large achieves the highest F1_micro of 0.866 and that transformer models outperform frequency-based baselines by better capturing semantic and medical nuances in psychiatric language.
Significance. If the experimental claims hold after proper validation, the work would provide evidence that fine-tuned domain-adapted embeddings improve automated ICD coding for psychiatry, a task complicated by long-tail distributions and clinical ambiguity. This could inform practical tools for reducing administrative burden in mental health settings. The systematic comparison across representation paradigms is a positive aspect.
major comments (2)
- [Abstract and Results] Abstract and Results: The headline claim that e5_large reaches F1_micro = 0.866 with clear outperformance is presented without any description of train-test splits, class-imbalance mitigation, statistical significance testing, or error analysis. These omissions make it impossible to assess whether the reported superiority is robust or reproducible.
- [Dataset section] Dataset section: No information is given on label provenance, inter-rater reliability, or quality-control procedures for the 145,513 psychiatric descriptions. Because psychiatric ICD assignment is known to be noisy and subjective, unverified labels directly threaten the validity of every performance number and the central claim that LLMs outperform classical methods on this task.
minor comments (1)
- [Abstract] The abstract refers to 'long-tail' label distributions but provides no quantitative breakdown or per-class metrics in the results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The headline claim that e5_large reaches F1_micro = 0.866 with clear outperformance is presented without any description of train-test splits, class-imbalance mitigation, statistical significance testing, or error analysis. These omissions make it impossible to assess whether the reported superiority is robust or reproducible.
Authors: We agree that these details are necessary for a full evaluation of robustness. In the revised manuscript we will expand the Abstract and Results sections to describe the train-test split (stratified 80/20 split preserving label distribution), class-imbalance handling (weighted loss during fine-tuning), statistical significance testing (McNemar tests on F1 scores across repeated runs), and a short error analysis of common misclassifications among semantically similar psychiatric codes. revision: yes
-
Referee: [Dataset section] Dataset section: No information is given on label provenance, inter-rater reliability, or quality-control procedures for the 145,513 psychiatric descriptions. Because psychiatric ICD assignment is known to be noisy and subjective, unverified labels directly threaten the validity of every performance number and the central claim that LLMs outperform classical methods on this task.
Authors: We agree that label provenance and quality controls are critical given the known subjectivity of psychiatric ICD coding. The revised Dataset section will describe the source (anonymized clinical records from a collaborating mental health center), collection process, and any institutional quality procedures applied. We will also add an explicit limitations paragraph discussing the retrospective nature of the labels and the implications of potential noise for interpreting model comparisons. revision: partial
- Inter-rater reliability statistics for the ICD labels, which were not collected as part of the original clinical workflow and are therefore unavailable for this retrospective dataset.
Circularity Check
No circularity: purely empirical benchmarking on held-out data
full rationale
The paper conducts a standard machine-learning evaluation: a fixed corpus of 145,513 Spanish psychiatric notes is split, classical and transformer models are trained or fine-tuned, and F1_micro is reported on held-out test data. No equations, derivations, or self-citations are used to obtain the headline result; the 0.866 score is a direct empirical measurement, not a quantity that reduces to fitted parameters or prior self-citations by construction. Dataset-label quality is an external validity concern, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 145,513 Spanish psychiatric descriptions are accurately labeled and representative of clinical practice.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Utilizing a specialized dataset of 145,513 Spanish psychiatric descriptions... transformer-based embeddings consistently outperform traditional methods... e5_large model, through end-to-end fine-tuning, achieved the highest performance with a F1_micro score of 0.866.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Informe anual del sistema nacional de salud 2023
Spanish Ministry of Health. Informe anual del sistema nacional de salud 2023. Informe an- ual en PDF, 2024. URLhttps://www.sanidad.gob.es/estadEstudios/estadisticas/ sisInfSanSNS/tablasEstadisticas/InfAnualSNS2023/INFORME_ANUAL_2023.pdf. An- nual report; acceso 17/06/2025
work page 2023
-
[2]
¿cu´ al es el estado de la salud mental en espa˜ na? Publicaci´ on web,
Psic´ ologos Aldama. ¿cu´ al es el estado de la salud mental en espa˜ na? Publicaci´ on web,
-
[3]
URLhttps://psicologosaldama.com/estado-la-salud-mental-en-espana/. Blog; acceso 17/06/2025
work page 2025
- [4]
-
[5]
J. J. McGrath, C. C. W. Lim, O. Plana-Ripoll, Y. Holtz, E. Agerbo, N. C. Momen, P. B. Mortensen, C. B. Pedersen, J. Abdulmalik, S. Aguilar-Gaxiola, A. Al-Hamzawi, J. Alonso, E. J. Bromet, R. Bruffaerts, B. Bunting, J. M. C. de Almeida, G. de Girolamo, Y. A. De Vries, S. Florescu, O. Gureje, J. M. Haro, M. G. Harris, C. Hu, E. G. Karam, N. Kawakami, A. Kie...
-
[6]
Amani F. Hamad, Barret A. Monchka, James M. Bolton, Leslie L. Roos, Mohamed Elgendi, and Lisa M. Lix. Leveraging multigenerational health data to enhance mental disorder risk prediction: a population-based cohort study.BMC Psychiatry, 25(1):862, December 2025. ISSN 1471-244X. doi: 10.1186/s12888-025-07323-z
-
[7]
Zhen Hou, Hao Liu, Jiang Bian, Xing He, and Yan Zhuang. Enhancing medical coding efficiency through domain-specific fine-tuned large language models.npj Health Systems, 2:14, 2025. doi: 10.1038/s44401-025-00018-3
-
[8]
Hugo Silva, V´ ıtor Duque, Mar´ ılia Macedo, and M´ ario Mendes. Aiding ICD-10 encoding of clinical health records using improved text cosine similarity and plm-icd.Algorithms, 17(4): 144, 2024. doi: 10.3390/a17040144. URLhttps://www.mdpi.com/1999-4893/17/4/144
-
[9]
Explainable Prediction of Medical Codes from Clinical Text
James Mullenbach, Sarah Wiegreffe, John Duke, Jimeng Sun, and Jacob Eisenstein. Ex- plainable prediction of medical codes from clinical text.CoRR, abs/1802.05695, 2018. doi: 10.48550/arXiv.1802.05695. URLhttps://arxiv.org/abs/1802.05695
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.05695 2018
-
[10]
Thuy Vu, Dat Q. Nguyen, and Anh Nguyen. A label attention model for ICD coding from clinical text.CoRR, abs/2007.06351, 2020. doi: 10.48550/arXiv.2007.06351. URL https://arxiv.org/abs/2007.06351. 12
-
[11]
Xiaoqian Xie, Yujia Xiong, Philip S. Yu, and Ying Zhu. EHR coding with multi-scale feature attention and structured knowledge graph propagation. InProceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), pages 649–658, 2019. doi: 10.1145/3357384.3357897. URLhttps://doi.org/10.1145/ 3357384.3357897
-
[12]
Hy- percore: Hyperbolic and co-graph representation for automatic icd coding
Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao, Shengping Liu, and Weifeng Chong. Hy- percore: Hyperbolic and co-graph representation for automatic icd coding. InProceed- ings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), pages 3105–3114, Online, 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.a...
-
[13]
Multi-label few-shot ICD coding as autoregressive generation with prompt.CoRR, abs/2211.13813, 2022
Zhiqing Yang, Seungyoung Kwon, Zhiyuan Yao, and Hong Yu. Multi-label few-shot ICD coding as autoregressive generation with prompt.CoRR, abs/2211.13813, 2022. doi: 10. 48550/arXiv.2211.13813. URLhttps://arxiv.org/abs/2211.13813
- [14]
-
[15]
URLhttps://arxiv.org/abs/2110.00685
doi: 10.48550/arXiv.2110.00685. URLhttps://arxiv.org/abs/2110.00685
-
[16]
Lu Liu, Oscar Perez-Concha, Anh Nguyen, Veronika Bennett, and Louisa Jorm. Auto- mated icd coding using extreme multi-label long text transformer-based models.CoRR, abs/2212.05857, 2022. doi: 10.48550/arXiv.2212.05857. URLhttps://arxiv.org/abs/ 2212.05857. Incluye la variante jer´ arquica XR-LAT del modelo XR-Transformer
-
[17]
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020. doi: 10.1093/ bioinformatics/btz682
work page 2020
-
[18]
Emily Alsentzer, John R. Murphy, William Boag, Wei-Hung Weng, Di Jindi, Tristan Naumann, and Matthew McDermott. Publicly available clinical bert embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pages 72–78, Minneapolis, Minnesota, USA, 2019. Association for Computational Linguistics. doi: 10.18653/v1/W19-1909. URLhttps:...
-
[19]
Transfer Learning in Biomedical Natural Language Processing: An Evaluation of
Yifan Peng, Shankai Yan, and Zhiyong Lu. Transfer learning in biomedical natural lan- guage processing: An evaluation of BERT and ELMo on ten benchmarking datasets. InProceedings of the 18th BioNLP Workshop and Shared Task, pages 58–65, Florence, Italy, 2019. Association for Computational Linguistics. doi: 10.18653/v1/W19-5006. URL https://aclanthology.or...
-
[20]
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing.ACM Transactions on Computing for Health- care, 3(1):1–23, 2021. doi: 10.1145/3458754. ModeloPubMedBERT
-
[21]
Pretrained biomedical language models for clinical nlp in spanish
Casimiro Pio Carrino, Joan Llop, Marc P` amies, Asier Guti´ errez-Fandi˜ no, Jordi Armengol- Estap´ e, Joaqu´ ın Silveira-Ocampo, Alfonso Valencia, Aitor Gonzalez-Agirre, and Marta Villegas. Pretrained biomedical language models for clinical nlp in spanish. InProceedings of the 21st Workshop on Biomedical Language Processing, pages 193–199, Dublin, Ireland,
-
[22]
doi: 10.18653/v1/2022.bionlp-1.19
Association for Computational Linguistics. doi: 10.18653/v1/2022.bionlp-1.19. URL https://aclanthology.org/2022.bionlp-1.19/. 13
-
[23]
Josu´ e P. Cuevas, Jos´ e A. Reyes-Ortiz, Alma D. Cuevas-Rasgado, Rom´ an A. Mora- Guti´ errez, and Maricela Bravo. M´ edicobert: A medical language model for spanish natu- ral language processing tasks with a question-answering application using hyperparameter optimization.Applied Sciences, 14(16):7031, 2024. doi: 10.3390/app14167031. Modelo denominadom´...
-
[24]
Plm-icd: Automatic icd coding with pretrained language models
Ching-Wei Huang, Shang-Chi Tsai, and Yun-Nung Chen. Plm-icd: Automatic icd coding with pretrained language models. In Tristan Naumann, Steven Bethard, Kirk Roberts, and Anna Rumshisky, editors,Proceedings of the 4th Clinical Natural Language Process- ing Workshop, pages 10–20, Seattle, WA, USA, 2022. Association for Computational Lin- guistics. doi: 10.18...
-
[25]
Surpassing GPT- 4 medical coding with a two-stage approach
Zheng Yang, Shikhar Singh Batra, Joshua Stremmel, and Eran Halperin. Surpassing GPT- 4 medical coding with a two-stage approach. InProceedings of the Machine Learning for Health Symposium (ML4H 2023), pages 1–19, 2023. doi: 10.48550/arXiv.2311.13735. URL https://arxiv.org/abs/2311.13735. FrameworkLLM-Codex; publicado 22 Nov 2023
-
[26]
Latent semantic analysis.ARIST (Annual Review of Information Science Technology), 38:189–230, 2004
Susan Dumais et al. Latent semantic analysis.ARIST (Annual Review of Information Science Technology), 38:189–230, 2004
work page 2004
-
[27]
Latent dirichlet allocation.Journal of machine Learning research, 3(Jan):993–1022, 2003
David M Blei, Andrew Y Ng, and Michael I Jordan. Latent dirichlet allocation.Journal of machine Learning research, 3(Jan):993–1022, 2003
work page 2003
-
[28]
Distributed representations of sentences and documents
Quoc Le and Tomas Mikolov. Distributed representations of sentences and documents. In International conference on machine learning, pages 1188–1196. PMLR, 2014
work page 2014
-
[29]
Casimiro Pio Carrino, Jordi Armengol-Estap´ e, Asier Guti´ errez-Fandi˜ no, Joan Llop-Palao, Marc P` amies, Aitor Gonzalez-Agirre, and Marta Villegas. Biomedical and clinical lan- guage models for spanish: On the benefits of domain-specific pretraining in a mid-resource scenario, 2021
work page 2021
-
[30]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. URLhttp: //arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Fran¸ cois Remy, Kris Demuynck, and Thomas Demeester. BioLORD-2023: semantic textual representations fusing large language models and clinical knowledge graph insights.Journal of the American Medical Informatics Association, page ocae029, 02 2024. ISSN 1527-974X. doi: 10.1093/jamia/ocae029. URLhttps://doi.org/10.1093/jamia/ocae029
-
[33]
Towards building multilingual language model for medicine, 2024
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards building multilingual language model for medicine, 2024
work page 2024
-
[34]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2623–2631, 2019
work page 2019
-
[35]
Fine- tuning can distort pretrained features and underperform out-of-distribution, 2022
Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine- tuning can distort pretrained features and underperform out-of-distribution, 2022. 14 A List of Mental Health ICD Codes Table 6 provides the complete list of the 85 diagnostic categories used in this study, including both standard ICD codes and internal project identifiers. T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.