High-speed Networking for Giga-Scale AI Factories
Pith reviewed 2026-05-21 01:27 UTC · model grok-4.3
The pith
Spectrum-X multiplane Ethernet with hardware load balancing sustains 98% line rate and low jitter for hundred-thousand-GPU AI training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
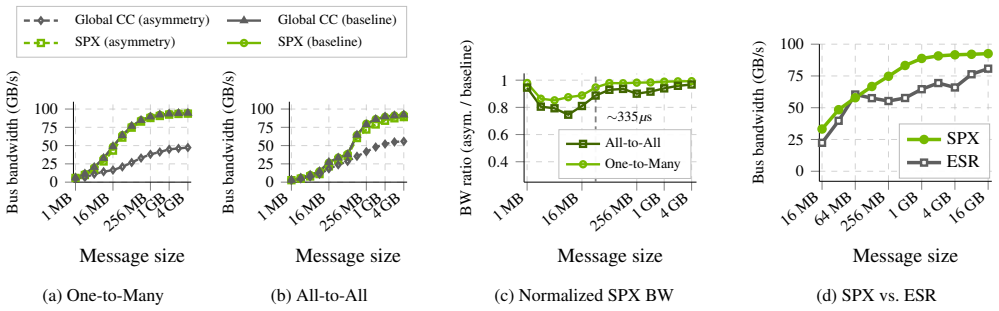
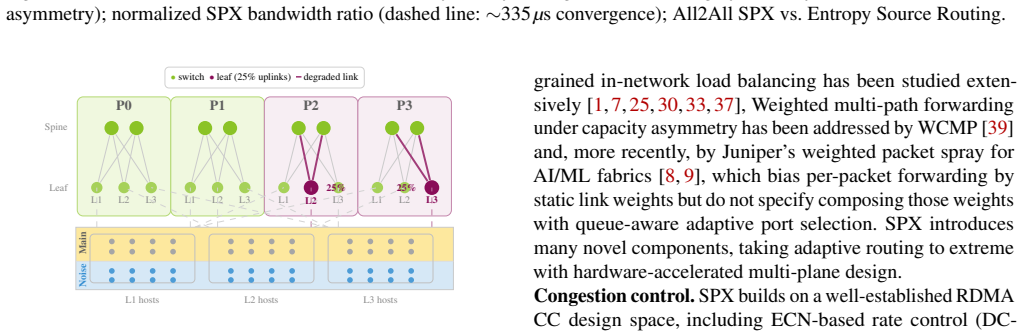
The Spectrum-X multiplane architecture replaces hierarchical depth with topological parallelism and adds hardware-accelerated load balancing in NICs and switches to handle the microsecond-timescale dynamics of AI training traffic. This combination yields 98% of theoretical line rate with low jitter-free latency, strong cross-tenant isolation, capacity-proportional bisection bandwidth, and only a 7% latency increase under 10% fabric link failures during LLM training.
What carries the argument
Multiplane topology paired with hardware-accelerated load balancing inside NICs and switches that reacts at microsecond timescales.
Load-bearing premise
AI training creates network conditions that fluctuate so rapidly at microsecond scales that only hardware load balancing can keep utilization and latency stable.
What would settle it
A controlled run of the same LLM training workload on an equivalent-scale cluster showing that software load balancing or a traditional hierarchical Ethernet fabric achieves within a few percent of the reported utilization and latency numbers.
Figures
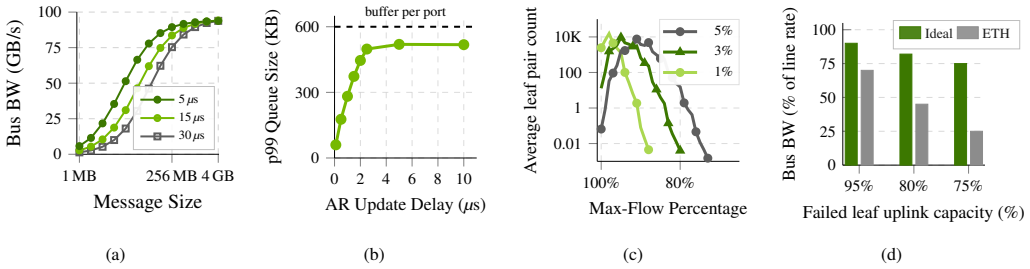
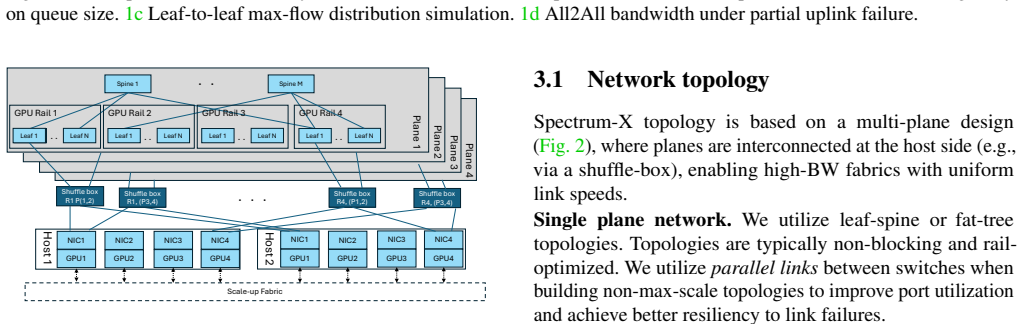




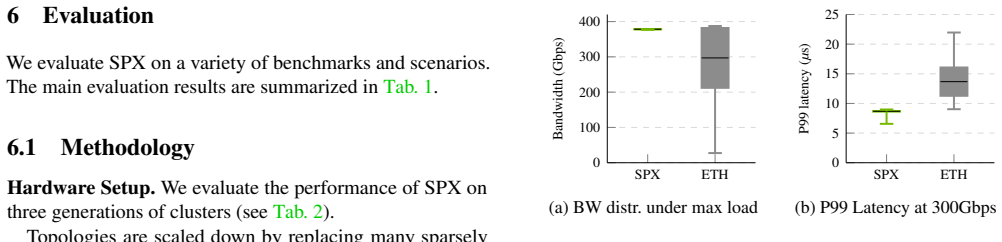


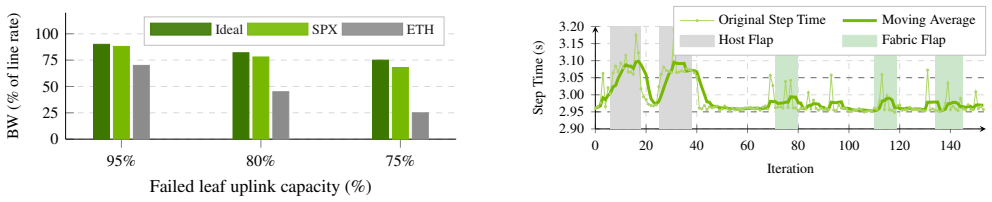


read the original abstract
As distributed model training scales to span hundreds of thousands of GPUs, scale-out networks face unprecedented performance and efficiency demands. NVIDIA Spectrum-X Ethernet has been designed from the ground up to achieve predictable and stable network performance with high utilization and low latency. This paper presents the Spectrum-X multiplane architecture, which replaces hierarchical depth with topological parallelism, and introduces hardware-accelerated load balancing in NICs and switches as the key architectural approach to provide fast reaction to highly dynamic network conditions at the microsecond timescales that AI training workloads demand. We describe the motivation, design principles, evaluation methodology and performance on state-of-the-art benchmarks, as well as the lessons we learned from deploying and debugging Spectrum-X networks in large-scale systems. Our evaluation highlights production-grade AI infrastructure performance across three core dimensions: 98% of the theoretical line rate with low jitter-free latency; strong cross-tenant isolation for concurrent workloads; robust, capacity-proportional bisection bandwidth and 7% latency increase for 10% fabric link failures; and rapid reaction to host and fabric link flaps during LLM training workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes NVIDIA Spectrum-X, a multiplane Ethernet architecture for giga-scale AI training clusters spanning hundreds of thousands of GPUs. It replaces hierarchical topologies with topological parallelism and relies on hardware-accelerated load balancing in NICs and switches to react to microsecond-scale dynamics in AI workloads. Production measurements and benchmarks are reported to demonstrate 98% of theoretical line rate with low jitter-free latency, strong cross-tenant isolation, capacity-proportional bisection bandwidth, and only a 7% latency increase under 10% fabric link failures during LLM training.
Significance. If the reported measurements hold, the work is significant as a detailed case study of a production-scale networking system tailored to the demands of large-scale distributed AI training. It supplies concrete lessons from deployment and debugging that are directly relevant to operators building next-generation AI factories, and the emphasis on hardware mechanisms for rapid adaptation addresses a practical gap between theoretical network designs and real AI workload behavior.
major comments (1)
- Evaluation section: the headline metrics (98% line rate, 7% latency increase under 10% failures) are presented without accompanying information on benchmark configurations, number of trials, error bars, data filtering criteria, or precise measurement methodology. This absence makes it difficult to assess whether the results robustly support the central claims about utilization, isolation, and failure resilience.
minor comments (2)
- The description of the multiplane topology and load-balancing mechanisms would benefit from a clearer diagram or pseudocode showing the interaction between NIC and switch hardware acceleration.
- A short comparison table against prior Ethernet or InfiniBand solutions at similar scale would help readers situate the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: Evaluation section: the headline metrics (98% line rate, 7% latency increase under 10% failures) are presented without accompanying information on benchmark configurations, number of trials, error bars, data filtering criteria, or precise measurement methodology. This absence makes it difficult to assess whether the results robustly support the central claims about utilization, isolation, and failure resilience.
Authors: We agree that the Evaluation section would benefit from greater methodological transparency. In the revised manuscript we will add a dedicated subsection that specifies the benchmark configurations (including cluster sizes, workload types, and traffic patterns), the number of trials performed, error bars or confidence intervals where statistical variation is present, explicit data filtering criteria, and a precise description of the measurement methodology (including instrumentation points, sampling rates, and how line-rate and latency were computed). These additions will directly support assessment of the utilization, isolation, and failure-resilience claims. revision: yes
Circularity Check
No significant circularity; claims rest on empirical measurements
full rationale
The paper is a systems description of the Spectrum-X multiplane Ethernet architecture and its hardware-accelerated load balancing for large-scale AI training. Performance claims (98% line rate, isolation, bisection bandwidth, failure resilience) are presented as results from production deployments, benchmark runs, and evaluation methodology rather than from any equations, derivations, or first-principles predictions. No load-bearing steps reduce by construction to fitted inputs, self-citations, or ansatzes; the architecture is justified by design principles and measured outcomes that are independently falsifiable through external benchmarks. This is the expected finding for an empirical systems paper without mathematical modeling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and 8-tick orbit structure unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Spectrum-X multiplane architecture, which replaces hierarchical depth with topological parallelism, and introduces hardware-accelerated load balancing in NICs and switches as the key architectural approach to provide fast reaction to highly dynamic network conditions at the microsecond timescales
-
IndisputableMonolith/Cost/FunctionalEquation.leanJcost uniqueness and φ-fixed-point unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SPX sustains 98% of theoretical line rate with p99 latency of just 8–9 µs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Conga: Distributed congestion-aware load balancing for datacenters
Mohammad Alizadeh, Tom Edsall, Sarang Dharma- purikar, Ramanan Vaidyanathan, Kevin Chu, Andy Fin- gerhut, Vinh The Lam, Francis Matus, Rong Pan, Navin- dra Yadav, and George Varghese. Conga: Distributed congestion-aware load balancing for datacenters. In ACM SIGCOMM, 2014
work page 2014
-
[2]
Accelerating AI storage by up to 48% with NVIDIA Spectrum-X networking platform and partners
Taylor Allison. Accelerating AI storage by up to 48% with NVIDIA Spectrum-X networking platform and partners. https://developer.nvidia.com/blog/ accelerating-ai-storage-by-up-to-48-with-n vidia-spectrum-x-networking-platform-and-p artners/, 2025
work page 2025
-
[3]
Wei Bai, Shanim Sainul Abdeen, Ankit Agrawal, Kris- han Kumar Attre, Paramvir Bahl, Ameya Bhagat, Gowri Bhaskara, Tanya Brokhman, Lei Cao, Ahmad Cheema, Rebecca Chow, Jeff Cohen, Mahmoud Elhaddad, Vivek Ette, Igal Figlin, Daniel Firestone, Mathew George, Ilya German, Lakhmeet Ghai, Eric Green, Albert Greenberg, Manish Gupta, Randy Haagens, Matthew Hendel,...
work page 2023
- [4]
-
[5]
xAI colossus: The Elon project
Doug Eadline. xAI colossus: The Elon project. https: //www.hpcwire.com/2024/09/05/xai-colossu s-the-elon-project/, 2024
work page 2024
-
[6]
Rdma over ethernet for distributed training at meta scale
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, and Hongyi Zeng. Rdma over ethernet for distributed training at meta scale. InACM SIGCOMM, 2024
work page 2024
-
[7]
Brighten Godfrey, Yashar Ganjali, and Amin Firoozshahian
Soudeh Ghorbani, Zibin Yang, P. Brighten Godfrey, Yashar Ganjali, and Amin Firoozshahian. DRILL: Mi- cro load balancing for low-latency data center networks. InACM SIGCOMM, 2017
work page 2017
-
[8]
Networking the AI data center: Ad- vanced load balancing (DLB, GLB, weighted ECMP) for AI/ML fabrics
Juniper Networks. Networking the AI data center: Ad- vanced load balancing (DLB, GLB, weighted ECMP) for AI/ML fabrics. https://www.juniper.net/cont ent/dam/www/assets/white-papers/us/en/netw orking-the-ai-data-center.pdf, 2024
work page 2024
-
[9]
Weighted packet spray for dynamic load balancing (Junos os evolved AI/ML guide)
Juniper Networks. Weighted packet spray for dynamic load balancing (Junos os evolved AI/ML guide). https: //www.juniper.net/documentation/us/en/soft ware/junos/ai-ml-evo/topics/topic-map/wei ghted-packet-spray.html, 2024
work page 2024
-
[10]
Sajy Khashab, Hariharan Sezhiyan, Rani Abboud, Alex Normatov, Stefan Kaestle, Eliav Bar-Ilan, Mohammad Nassar, Omer Shabtai, Wei Bai, Matty Kadosh, Jiarong Xing, Mark Silberstein, T. S. Eugene Ng, and Ang Chen. NSX: Large-scale network simulation on an AI server. InACM NAIC, 2025
work page 2025
-
[11]
Gautam Kumar, Nandita Dukkipati, Keon Jang, Hassan M. G. Wassel, Xian Wu, Behnam Montazeri, Yaogong Wang, Kevin Springborn, Christopher Alfeld, Michael Ryan, David Wetherall, and Amin Vahdat. Swift: Delay is simple and effective for congestion control in the datacenter. InACM SIGCOMM, 2020
work page 2020
-
[12]
Hpcc: High precision congestion control
Yuliang Li, Rui Miao, Hongqiang Harry Liu, Yan Zhuang, Fei Feng, Lingbo Tang, Zheng Cao, Ming Zhang, Frank Kelly, Mohammad Alizadeh, and Minlan Yu. Hpcc: High precision congestion control. InACM SIGCOMM, 2019
work page 2019
-
[13]
Understanding stragglers in large model training using what-if analysis
Jinkun Lin, Ziheng Jiang, Zuquan Song, Sida Zhao, Menghan Yu, Zhanghan Wang, Chenyuan Wang, Zuocheng Shi, Xiang Shi, Wei Jia, Zherui Liu, Shuguang Wang, Haibin Lin, Xin Liu, Aurojit Panda, and Jinyang Li. Understanding stragglers in large model training using what-if analysis. InUSENIX OSDI, 2025
work page 2025
-
[14]
BGP link bandwidth extended community use cases
Stephane Litkowski, SATYA R MOHANTY , Arie Vayner, Akshay Gattani, Ajay Kini, Jeff Tantsura, and Reshma Das. BGP link bandwidth extended community use cases. Internet-Draft draft-ietf-bess-ebgp-dmz-10, 2026
work page 2026
-
[15]
Alibaba stellar: A new generation rdma network for cloud ai
Jie Lu, Jiaqi Gao, Fei Feng, Zhiqiang He, Menglei Zheng, Kun Liu, Jun He, Binbin Liao, Suwei Xu, Ke Sun, Yongjia Mo, Qinghua Peng, Jilie Luo, Qingxu Li, Gang Lu, Zishu Wang, Jianbo Dong, Kunling He, Sheng Cheng, Jiamin Cao, Hairong Jiao, Pengcheng Zhang, Shu Ma, Lingjun Zhu, Chao Shi, Yangming Zhang, Yi- quan Chen, Wei Wang, Shuhong Zhu, Xingru Li, Qiang ...
work page 2025
-
[16]
Load balancing for ai training workloads, 2026
Sarah McClure, Evyatar Cohen, Alex Shpiner, Mark Sil- berstein, Sylvia Ratnasamy, Scott Shenker, and Isaac Keslassy. Load balancing for ai training workloads, 2026
work page 2026
-
[17]
Astral: A Datacenter Infrastructure for Large Language Model Training at Scale
Qingkai Meng, Hao Zheng, Zhenhui Zhang, ChonLam Lao, Chengyuan Huang, Baojia Li, Ziyuan Zhu, Hao Lu, Weizhen Dang, Zitong Lin, Weifeng Zhang, Lingfeng Liu, Yuanyuan Gong, Chunzhi He, Xiaoyuan Hu, Yinben Xia, Xiang Li, Zekun He, Yachen Wang, Xianneng Zou, Kun Yang, Gianni Antichi, Guihai Chen, and Chen Tian. Astral: A Datacenter Infrastructure for Large La...
work page 2025
-
[18]
Revisiting network support for rdma
Radhika Mittal, Alexander Shpiner, Aurojit Panda, Eitan Zahavi, Arvind Krishnamurthy, Sylvia Ratnasamy, and Scott Shenker. Revisiting network support for rdma. In ACM SIGCOMM, 2018
work page 2018
-
[19]
Berger, Kevin Hsieh, Srikanth Kandula, Ramesh Govindan, and Behnaz Arzani
Pooria Namyar, Arvin Ghavidel, Daniel Crankshaw, Daniel S. Berger, Kevin Hsieh, Srikanth Kandula, Ramesh Govindan, and Behnaz Arzani. Enhancing net- work failure mitigation with performance-aware ranking. InUSENIX NSDI, 2025
work page 2025
-
[20]
NVIDIA launches accelerated ethernet plat- form for hyperscale generative AI (Spectrum-X)
NVIDIA. NVIDIA launches accelerated ethernet plat- form for hyperscale generative AI (Spectrum-X). http s://nvidianews.nvidia.com/news/nvidia-lau nches-accelerated-ethernet-platform-for-h yperscale-generative-ai, 2023
work page 2023
-
[21]
NCCL developer guide and environment vari- ables
NVIDIA. NCCL developer guide and environment vari- ables. https://docs.nvidia.com/deeplearning /nccl/user-guide/docs/env.html, 2024
work page 2024
-
[22]
NCCL tests: Performance — bus bandwidth metric
NVIDIA. NCCL tests: Performance — bus bandwidth metric. https://github.com/NVIDIA/nccl-tests /blob/master/doc/PERFORMANCE.md, 2024
work page 2024
-
[23]
NVIDIA. NVIDIA introduces Spectrum-XGS ethernet to connect distributed data centers into giga-scale AI super-factories. https://nvidianews.nvidia.com/ news/nvidia-introduces-spectrum-xgs-ether net-to-connect-distributed-data-centers-i nto-giga-scale-ai-super-factories, 2025
work page 2025
-
[24]
NVIDIA Spectrum-X networking platform
NVIDIA. NVIDIA Spectrum-X networking platform. https://www.nvidia.com/en-us/networking/s pectrumx/, 2026
work page 2026
-
[25]
Sglb: Scal- able and robust global load balancing in commodity ai clusters
Chenchen Qi, Wenfei Wu, Yongcan Wang, Keqiang He, Yu-Hsiang Kao, Zongying He, Chen-Yu Yen, Zhuo Jiang, Feng Luo, Surendra Anubolu, Yanjin Gao, Bingfeng Lin, Wenda Ni, Yiming Yang, Donglin Wei, Boyang Zhou, Jian Wang, and Shan Ding. Sglb: Scal- able and robust global load balancing in commodity ai clusters. InACM SIGCOMM, 2025
work page 2025
-
[26]
Alibaba hpn: A data center network for large language model training
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao Wang, Peng Wang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Yao, Ennan Zhai, and Dennis Cai. Alibaba hpn: A data center network for large language model training. InACM SIGCOMM, 2024
work page 2024
-
[27]
Plb: Congestion signals are simple and effec- tive for network load balancing
Mubashir Adnan Qureshi, Yuchung Cheng, Qianwen Yin, Qiaobin Fu, Gautam Kumar, Masoud Moshref, Jun- hua Yan, Van Jacobson, David Wetherall, and Abdul Kabbani. Plb: Congestion signals are simple and effec- tive for network load balancing. InACM SIGCOMM, 2022
work page 2022
-
[28]
Arjun Roy, Hongyi Zeng, Jasmeet Bagga, and Alex C. Snoeren. Passive realtime datacenter fault detection and localization. InUSENIX NSDI, 2017
work page 2017
-
[29]
North–south networks: The key to faster enterprise AI workloads
Shashank Sabhlok. North–south networks: The key to faster enterprise AI workloads. https://developer. nvidia.com/blog/north-south-networks-the-k ey-to-faster-enterprise-ai-workloads/, 2025
work page 2025
-
[30]
Network load balancing with in-network reordering support for rdma
Cha Hwan Song, Xin Zhe Khooi, Raj Joshi, Inho Choi, Jialin Li, and Mun Choon Chan. Network load balancing with in-network reordering support for rdma. InACM SIGCOMM, 2023
work page 2023
-
[31]
Netbouncer: Active device and link failure localization in data center networks
Cheng Tan, Ze Jin, Chuanxiong Guo, Tianrong Zhang, Haitao Wu, Karl Deng, Dongming Bi, and Dong Xiang. Netbouncer: Active device and link failure localization in data center networks. InUSENIX NSDI, 2019
work page 2019
-
[32]
Ultra ethernet specification v1.0
Ultra Ethernet Consortium. Ultra ethernet specification v1.0. https://ultraethernet.org/wp-content/u ploads/sites/20/2025/06/UE-Specification-6 .11.25.pdf, 2025
work page 2025
-
[33]
Let it flow: Resilient asymmet- ric load balancing with flowlet switching
Erico Vanini, Rong Pan, Mohammad Alizadeh, Parvin Taheri, and Tom Edsall. Let it flow: Resilient asymmet- ric load balancing with flowlet switching. InUSENIX NSDI, 2017
work page 2017
-
[34]
Optireduce: Resilient and tail-optimal allreduce for distributed deep learning in the cloud
Ertza Warraich, Omer Shabtai, Khalid Manaa, Shay Var- gaftik, Yonatan Piasetzky, Matty Kadosh, Lalith Suresh, and Muhammad Shahbaz. Optireduce: Resilient and tail-optimal allreduce for distributed deep learning in the cloud. InUSENIX NSDI, 2025
work page 2025
-
[35]
Colossus: The world’s largest AI supercomputer
xAI. Colossus: The world’s largest AI supercomputer. https://x.ai/colossus, 2024. 14
work page 2024
-
[36]
Holmes: Localizing irregulari- ties in LLM training with mega-scale GPU clusters
Zhiyi Yao, Pengbo Hu, Congcong Miao, Xuya Jia, Zun- ing Liang, Yuedong Xu, Chunzhi He, Hao Lu, Mingzhuo Chen, Xiang Li, Zekun He, Yachen Wang, Xianneng Zou, and Junchen Jiang. Holmes: Localizing irregulari- ties in LLM training with mega-scale GPU clusters. In USENIX NSDI, 2025
work page 2025
-
[37]
Distributed adaptive routing for big-data applications running on data center networks
Eitan Zahavi, Isaac Keslassy, and Avinoam Kolodny. Distributed adaptive routing for big-data applications running on data center networks. InACM/IEEE ANCS, 2012
work page 2012
-
[38]
Shizhen Zhao, Rui Wang, Junlan Zhou, Joon Ong, Jef- frey C. Mogul, and Amin Vahdat. Minimal rewiring: Efficient live expansion for Clos data center networks. InUSENIX NSDI, 2019
work page 2019
-
[39]
WCMP: Weighted cost multipathing for improved fair- ness in data centers
Junlan Zhou, Malveeka Tewari, Min Zhu, Abdul Kab- bani, Leon Poutievski, Arjun Singh, and Amin Vahdat. WCMP: Weighted cost multipathing for improved fair- ness in data centers. InEuroSys, 2014
work page 2014
-
[40]
Congestion control for large-scale rdma deploy- ments
Yibo Zhu, Haggai Eran, Daniel Firestone, Chuanxiong Guo, Marina Lipshteyn, Yehonatan Liron, Jitendra Pad- hye, Shachar Raindel, Mohamad Haj Yahia, and Ming Zhang. Congestion control for large-scale rdma deploy- ments. InACM SIGCOMM, 2015. 15
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.