Survive or Collapse: The Asymmetric Roles of Data Gating and Reward Grounding in Self-Play RL
Pith reviewed 2026-05-22 07:20 UTC · model grok-4.3
The pith
A strict data gate stabilizes self-play RL under every reward variant tested, but no reward variant prevents collapse once the gate is removed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
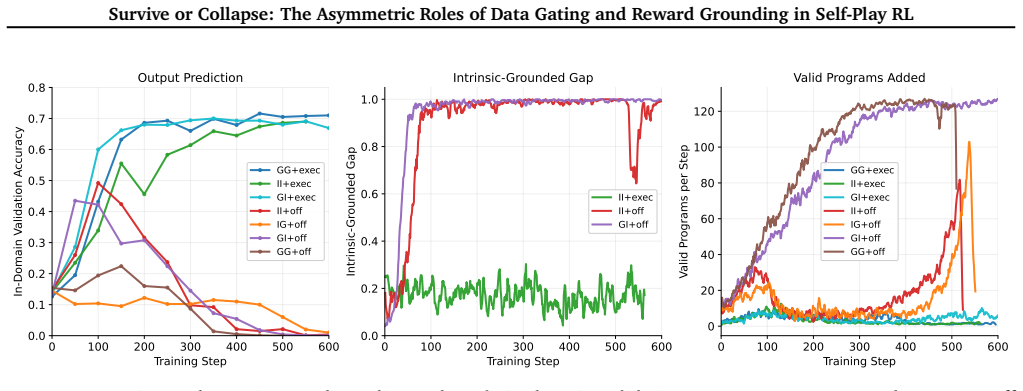
The central claim is that self-play stability is governed by an asymmetry between data gating and reward grounding. A strict gate is sufficient for stability under every reward variant tested, including a self-consistency reward with no access to ground truth, while no reward variant is sufficient once the gate is removed. This holds on both the Python task and the deterministic-DSL twin task. The authors further describe the Grounded Proposer Paradox, in which a proposer with ground-truth access accelerates collapse faster than an ungrounded one when paired with a self-consistency solver by concentrating training on clean tasks that lead to spurious self-consistent attractors. Replacing the
What carries the argument
The data-level gate that decides which proposer-generated tasks enter the training pool, which dominates over the reward signal in determining stability.
If this is right
- A strict gate maintains stability for every reward variant, including self-consistency rewards lacking ground truth.
- Collapse occurs under all reward variants once the gate is removed.
- A grounded proposer accelerates collapse with a self-consistency solver through concentration on clean tasks leading to spurious attractors.
- Training-side metrics decouple at low gate strictness while validation accuracy holds until strictness is raised further.
- Data-level gating is the binding constraint on self-play stability rather than reward calibration.
Where Pith is reading between the lines
- Self-play system designers could prioritize adaptive or learned gating over further reward engineering to sustain longer training runs.
- The two-stage phase transition suggests an intermediate strictness window that might balance stability with continued performance gains.
- The asymmetry may extend to other iterative self-improvement setups where data selection quality controls long-term coherence.
- Applying similar gating tests to nondeterministic or open-ended tasks would check whether the priority of filtering generalizes beyond the controlled deterministic setup.
Load-bearing premise
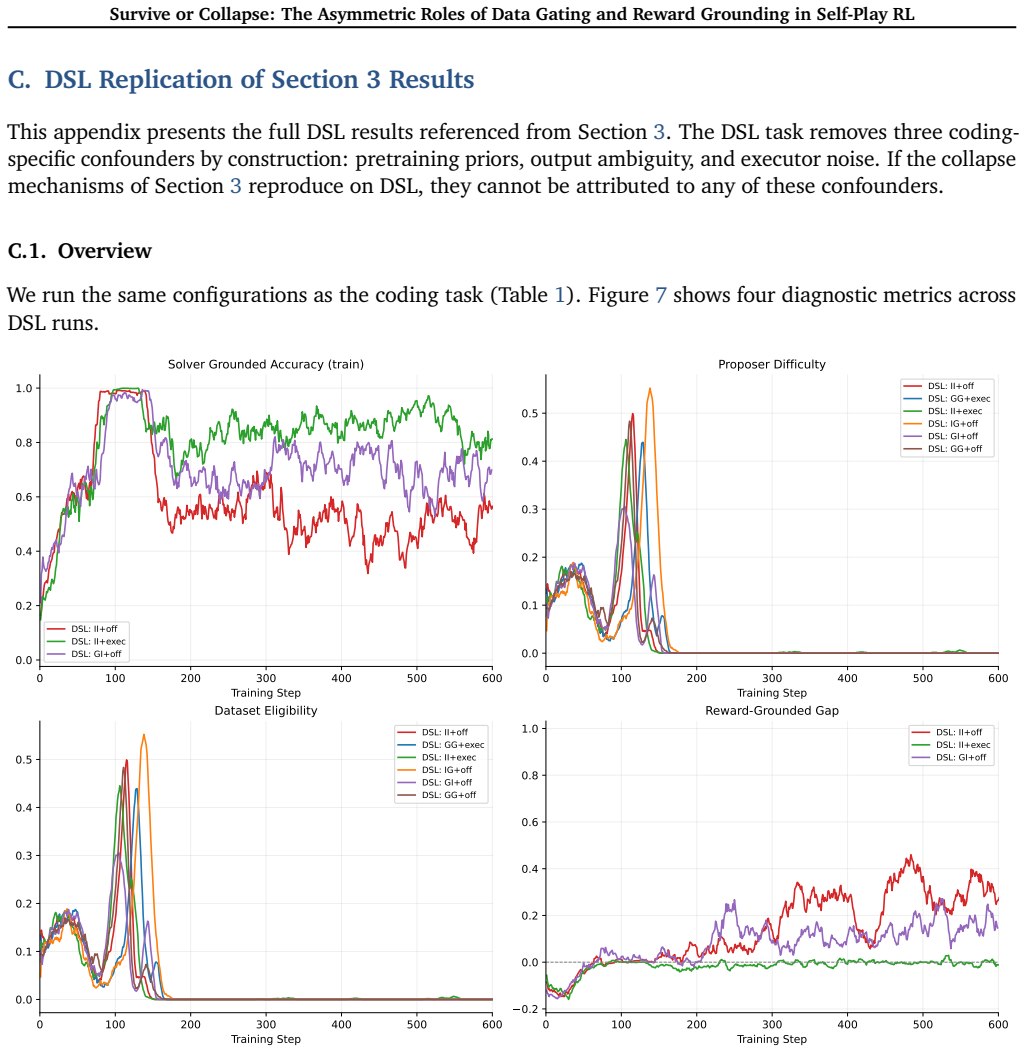
The deterministic-DSL twin task successfully removes pretraining priors, output ambiguity, and executor noise so that observed stability differences can be attributed only to gating versus reward.
What would settle it
Observing collapse despite an active strict gate, or sustained stability without any gate, on the deterministic-DSL task under the tested reward variants would contradict the claimed asymmetry.
Figures






read the original abstract
Self-play reinforcement learning trains language models on their own generated tasks, co-evolving a proposer and solver without human labels. Recent systems report strong reasoning gains, but collapse and instability are widely observed and poorly understood. The dominant response treats this as a reward-design problem. We argue instead that self-play stability is governed by two distinct levers: a data-level gate that decides which proposer-generated tasks enter the training pool, and the reward signal that updates the policy on tasks already admitted. Through controlled experiments on a Python output-prediction task and a deterministic-DSL twin task that strips pretraining priors, output ambiguity, and executor noise, we find the two levers are asymmetric. A strict gate is sufficient for stability under every reward variant we test, including a self-consistency reward with no access to ground truth; while no reward variant is sufficient once the gate is removed. This asymmetry exposes a counter-intuitive coupling we call the Grounded Proposer Paradox: a proposer with ground-truth access accelerates collapse faster than an ungrounded one when paired with a self-consistency solver, by concentrating training on clean tasks that form the fastest path to a spurious self-consistent attractor. Replacing the binary gate with a continuous strictness parameter $\varepsilon$ further reveals a two-stage phase transition: training-side metrics decouple at low $\varepsilon$, while validation accuracy holds until $\varepsilon$ is much higher. Data-level gating, not reward calibration, is the binding constraint on self-play stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instability in self-play RL for language models is governed by an asymmetry between data-level gating (which decides which proposer-generated tasks enter training) and the reward signal. Through controlled experiments on a Python output-prediction task and a deterministic-DSL twin task designed to remove pretraining priors, output ambiguity, and executor noise, a strict gate is shown to ensure stability across all tested reward variants (including self-consistency with no ground truth), while no reward variant prevents collapse once the gate is removed. The work identifies a 'Grounded Proposer Paradox' (grounded proposers accelerate collapse with self-consistency solvers) and a two-stage phase transition under continuous gate strictness ε, concluding that data gating is the binding constraint on stability.
Significance. If the asymmetry and isolation claims hold, the result would be significant for self-play RL research by shifting emphasis from reward engineering to data curation as the primary stabilizer. The controlled twin-task design and multi-reward ablations provide a useful empirical lens on collapse mechanisms, and the phase-transition analysis with ε offers a practical lever for practitioners. These elements strengthen the contribution if the attribution of effects to gating versus reward is robustly supported.
major comments (2)
- [Experiments describing the deterministic-DSL twin task] The deterministic-DSL twin task is presented as successfully stripping pretraining priors, output ambiguity, and executor noise so that stability differences can be attributed only to gating versus reward. However, residual distributional overlap with the base model's pretraining corpus on syntactic patterns or implicit output constraints encoded in the DSL grammar could remain; if so, the strict gate may still be filtering on those signals rather than acting as a pure data-level control. This directly affects the central claim that the gate is sufficient under every reward variant while no reward is sufficient without it.
- [Abstract and experimental results] The abstract and experimental description reference controlled experiments and ablations supporting the asymmetry, phase transition, and Grounded Proposer Paradox, but provide no details on sample sizes, number of independent runs, variance across seeds, or statistical tests for the reported stability and accuracy differences. Without these, the reliability of the observed decoupling at low ε versus validation accuracy at higher ε cannot be assessed, weakening support for the load-bearing asymmetry conclusion.
minor comments (2)
- [Section introducing the continuous gate] The continuous strictness parameter ε is introduced to replace the binary gate and reveal the two-stage phase transition, but its precise functional form, how it modulates task admission probabilities, and its interaction with the proposer/solver updates should be specified with an equation or pseudocode for reproducibility.
- The 'Grounded Proposer Paradox' is described qualitatively; a short formal characterization (e.g., relating proposer grounding to the rate of convergence to the self-consistent attractor) would clarify the mechanism.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects of experimental robustness and interpretation that we address below. We have revised the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Experiments describing the deterministic-DSL twin task] The deterministic-DSL twin task is presented as successfully stripping pretraining priors, output ambiguity, and executor noise so that stability differences can be attributed only to gating versus reward. However, residual distributional overlap with the base model's pretraining corpus on syntactic patterns or implicit output constraints encoded in the DSL grammar could remain; if so, the strict gate may still be filtering on those signals rather than acting as a pure data-level control. This directly affects the central claim that the gate is sufficient under every reward variant while no reward is sufficient without it.
Authors: We agree that residual distributional overlap cannot be ruled out with absolute certainty in any finite task design. The deterministic-DSL twin task uses a minimal, purpose-built grammar with no natural-language elements and fully deterministic execution to eliminate output ambiguity and executor noise while minimizing pretraining priors. Nevertheless, we acknowledge that some low-level syntactic regularities shared with general programming languages could persist. In the revised manuscript we have added an explicit limitations subsection discussing this possibility and its implications for causal attribution to the gate. We also include results from a supplementary control using an even more abstract, non-programming symbolic task to further test the robustness of the observed asymmetry. revision: partial
-
Referee: [Abstract and experimental results] The abstract and experimental description reference controlled experiments and ablations supporting the asymmetry, phase transition, and Grounded Proposer Paradox, but provide no details on sample sizes, number of independent runs, variance across seeds, or statistical tests for the reported stability and accuracy differences. Without these, the reliability of the observed decoupling at low ε versus validation accuracy at higher ε cannot be assessed, weakening support for the load-bearing asymmetry conclusion.
Authors: We concur that the original submission omitted key statistical details necessary for assessing result reliability. The revised manuscript now reports that all conditions were run with five independent random seeds, includes standard deviations for stability and accuracy metrics, and applies two-sample t-tests to confirm that the reported differences in collapse thresholds and phase-transition points are statistically significant (p < 0.05). These additions are placed in the experimental setup and results sections and referenced in the abstract. revision: yes
Circularity Check
No circularity: empirical claims rest on controlled experiments
full rationale
The paper presents its central findings—the asymmetry between data gating and reward, the Grounded Proposer Paradox, and the two-stage phase transition—as observed outcomes from controlled experiments on a Python output-prediction task and a deterministic-DSL twin task. These experiments are described as stripping pretraining priors, output ambiguity, and executor noise to isolate the levers. No mathematical derivations, equations, or fitted parameters are invoked that reduce by construction to the inputs; the claims do not rely on self-definitional loops, predictions forced by fitted subsets, or load-bearing self-citations. The work is self-contained as an empirical investigation whose validity can be assessed against external benchmarks and replication, with no reduction of results to their own assumptions by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- ε
axioms (1)
- domain assumption The deterministic-DSL twin task removes pretraining priors, output ambiguity, and executor noise.
invented entities (1)
-
Grounded Proposer Paradox
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data , author=. 2025 , eprint=
work page 2025
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
arXiv preprint arXiv:2501.12948 , year =. 2501.12948 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The Fourteenth International Conference on Learning Representations , year =
Search Self-Play: Pushing the Frontier of Agent Capability without Supervision , author =. The Fourteenth International Conference on Learning Representations , year =
-
[4]
Liang, Xiao and Li, Zhong-Zhi and Gong, Yeyun and Wang, Yang and Zhang, Hengyuan and Shen, Yelong and Wu, Ying Nian and Chen, Weizhu , journal =. Beyond. 2025 , eprint =
work page 2025
-
[5]
Yang, Ziyi and Shen, Weizhou and Li, Chenliang and Chen, Ruijun and Wan, Fanqi and Yan, Ming and Quan, Xiaojun and Huang, Fei , booktitle =. 2026 , url =
work page 2026
-
[6]
Simonds, Toby and Lopez, Kevin and Yoshiyama, Akira and Garmier, Dominique , journal =. 2025 , eprint =
work page 2025
-
[7]
Towards Understanding Self-play for
Chae, Justin Yang and Alam, Md Tanvirul and Rastogi, Nidhi , booktitle =. Towards Understanding Self-play for. 2025 , url =
work page 2025
-
[8]
Scaling Self-Play with Self-Guidance
Scaling Self-Play with Self-Guidance , author =. arXiv preprint arXiv:2604.20209 , year =. 2604.20209 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
He, Bingxiang and Zuo, Yuxin and Liu, Zeyuan and Zhao, Shangziqi and Fu, Zixuan and Yang, Junlin and Qian, Cheng and Zhang, Kaiyan and Fan, Yuchen and Cui, Ganqu and Chen, Xiusi and Sun, Youbang and Lv, Xingtai and Zhu, Xuekai and Sheng, Li and Li, Ran and Gao, Huan-ang and Zhang, Yuchen and Zhou, Bowen and Liu, Zhiyuan and Ding, Ning , journal =. How Far...
work page 2026
-
[10]
An Imperfect Verifier is Good Enough: Learning with Noisy Rewards
An Imperfect Verifier is Good Enough: Learning with Noisy Rewards , author =. arXiv preprint arXiv:2604.07666 , year =. 2604.07666 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yang, Haotong and Wang, Zitong and Kang, Shijia and Yang, Siqi and Yu, Wenkai and Niu, Xu and Sun, Yike and Hu, Yi and Lin, Zhouchen and Zhang, Muhan , journal =. 2026 , eprint =
work page 2026
-
[12]
Karwowski, Jacek and Hayman, Oliver and Bai, Xingjian and Kiendlhofer, Klaus and Griffin, Charlie and Skalse, Joar , booktitle =. 2024 , url =
work page 2024
-
[13]
Kwa, Thomas and Thomas, Drake and Garriga-Alonso, Adri. Catastrophic. Advances in Neural Information Processing Systems , volume =. 2024 , url =
work page 2024
-
[14]
Ashton, Hal , booktitle =. Causal. 2021 , publisher =. doi:10.5220/0010197300670073 , url =
-
[15]
Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs , author=. 2026 , eprint=
work page 2026
-
[16]
arXiv preprint arXiv:2604.01476 , year =
When Reward Hacking Rebounds: Understanding and Mitigating It with Representation-Level Signals , author =. arXiv preprint arXiv:2604.01476 , year =. 2604.01476 , archivePrefix =
-
[17]
Bai, Bizhe and Wu, Hongming and Ye, Peng and Chen, Tao , booktitle =. 2025 , url =
work page 2025
-
[18]
Overconfident Errors Need Stronger Correction: Asymmetric Confidence Penalties for Reinforcement Learning , author =. arXiv preprint arXiv:2602.21420 , year =. 2602.21420 , archivePrefix =
-
[19]
On Robustness and Chain-of-Thought Consistency of
Zhao, Rosie and Shah, Anshul and Zhu, Xiaoyu and Deng, Xinke and Jiang, Zhongyu and Yang, Yang and Liebelt, Joerg and Mondal, Arnab , journal =. On Robustness and Chain-of-Thought Consistency of. 2026 , eprint =
work page 2026
-
[20]
Rad, Ali and Filom, Khashayar and Keivan, Darioush and Mohajerin Esfahani, Peyman and Kamalinejad, Ehsan , journal =. Rate or Fate?. 2026 , eprint =
work page 2026
-
[21]
Jiang, Xue and Dong, Yihong and Liu, Mengyang and Deng, Hongyi and Wang, Tian and Tao, Yongding and Cao, Rongyu and Li, Binhua and Jin, Zhi and Jiao, Wenpin and Huang, Fei and Li, Yongbin and Li, Ge , journal =. 2025 , eprint =
work page 2025
-
[22]
Privileged Information Distillation for Language Models
Privileged Information Distillation for Language Models , author =. arXiv preprint arXiv:2602.04942 , year =. 2602.04942 , archivePrefix =
work page internal anchor Pith review arXiv
-
[23]
A Survey of Reinforcement Learning for Large Language Models under Data Scarcity: Challenges and Solutions , author =. arXiv preprint arXiv:2604.17312 , year =. 2604.17312 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:2509.15194 , year =
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation , author =. arXiv preprint arXiv:2509.15194 , year =. 2509.15194 , archivePrefix =
-
[25]
Xia, Peng and Zeng, Kaide and Liu, Jiaqi and Qin, Can and Wu, Fang and Zhou, Yiyang and Xiong, Caiming and Yao, Huaxiu , journal =. 2025 , eprint =
work page 2025
-
[26]
Huang, Chengsong and Yu, Wenhao and Wang, Xiaoyang and Zhang, Hongming and Li, Zongxia and Li, Ruosen and Huang, Jiaxin and Mi, Haitao and Yu, Dong , journal =. 2025 , eprint =
work page 2025
-
[27]
Huang, Chengsong and Yu, Wenhao and Wang, Xiaoyang and Zhang, Hongming and Li, Zongxia and Li, Ruosen and Huang, Jiaxin and Mi, Haitao and Yu, Dong , journal =. Guided Self-Evolving. 2025 , eprint =
work page 2025
-
[28]
Self-Play Only Evolves When Self-Synthetic Pipeline Ensures Learnable Information Gain
Self-Play Only Evolves When Self-Synthetic Pipeline Ensures Learnable Information Gain , author =. arXiv preprint arXiv:2603.02218 , year =. 2603.02218 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Can large reasoning models self-train?arXiv preprint arXiv:2505.21444, 2025
Can Large Reasoning Models Self-Train? , author =. arXiv preprint arXiv:2505.21444 , year =. 2505.21444 , archivePrefix =
-
[30]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution , author=. 2024 , journal =
work page 2024
-
[31]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , booktitle =. Is Your Code Generated by Chat. 2023 , url =
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.