Making the Discrete Continuous: Synthetic RAW Augmentations for Fine-Grained Evaluation of Person Detection Performance in Low Light
Pith reviewed 2026-05-22 06:53 UTC · model grok-4.3
The pith
Synthetic RAW augmentations generate low-light images whose detection performance matches real low-light captures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
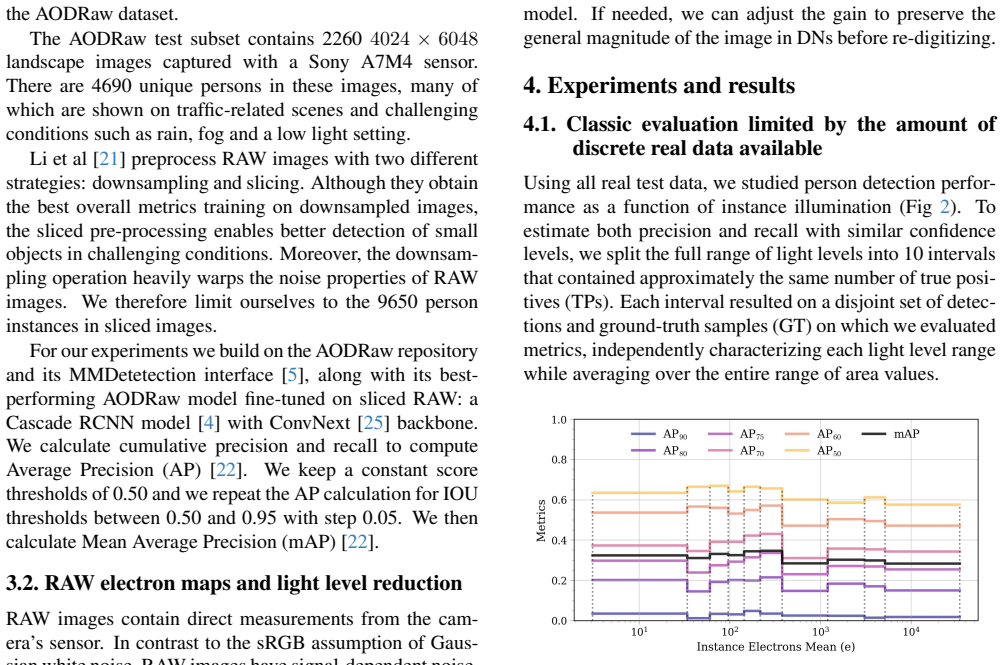
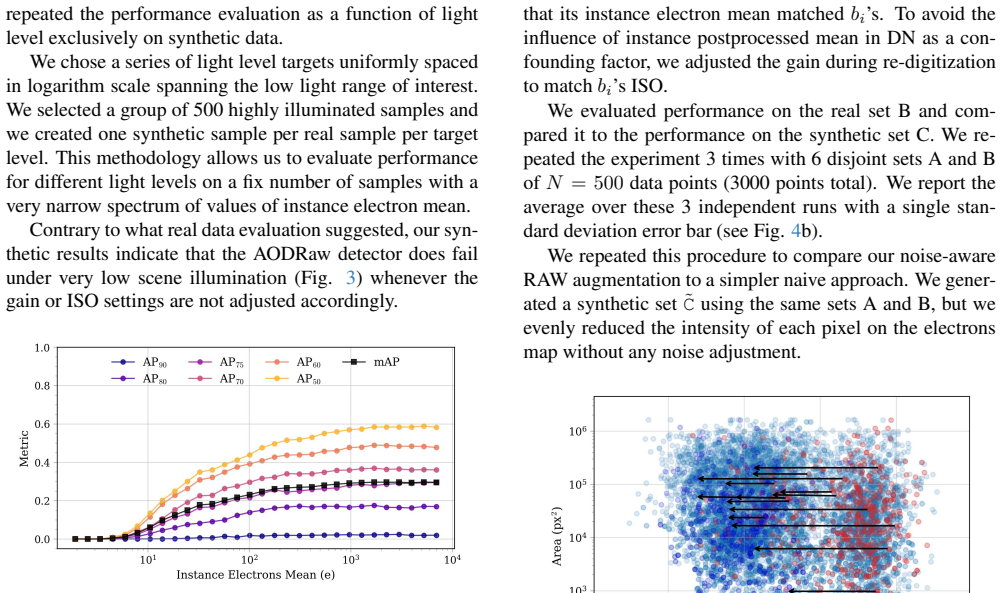
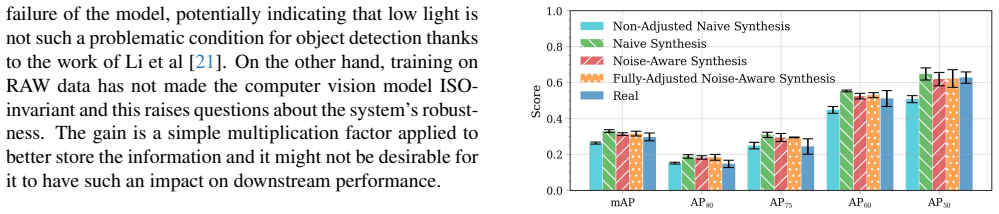
Focusing on pedestrian detection in the dark, the work uses a synthetic RAW image augmentation technique to generate low-light samples that match the noise model of the camera sensor. Performance metrics on real and synthetic low-light data are similar, indicating that the AI model finds it hard to distinguish between them.
What carries the argument
Synthetic RAW image augmentation technique to generate low-light samples that match the noise model of the camera sensor.
If this is right
- Object detection performance can be evaluated continuously across different illumination levels using generated samples.
- Synthetic data can improve coverage in low-density regions of real datasets for more reliable benchmarks.
- The approach allows fine-grained analysis of model behavior in safety-critical low-light scenarios without additional real data collection.
- Similar performance metrics validate the use of synthetics for testing in autonomous driving contexts.
Where Pith is reading between the lines
- Similar techniques could be applied to other sensors or environmental conditions to create continuous evaluation spaces.
- Accurate noise modeling might allow synthetic data to replace some real captures in model training pipelines.
- A direct test would involve varying the augmentation parameters and measuring if detection accuracy remains aligned with real data.
Load-bearing premise
The synthetic RAW augmentation accurately reproduces the camera sensor's noise model across varying illumination levels without introducing artifacts that would affect detection differently than real low-light capture.
What would settle it
A controlled experiment comparing detection performance on paired real and synthetic images at the same illumination level and content would show divergence if the claim does not hold.
Figures




read the original abstract
Real-world deployment of AI vision models is both fueled and limited by the data available for training and testing. Real datasets are sparse and uneven: long-tailed or unbalanced distributions hinder generalization, and the low number of samples in low density regions makes it hard to run evaluations. Synthetic data can fill these gaps, providing us with a way to sample the input space more continuously and improve data coverage for benchmarks. Focusing on the autonomous driving safety-critical case of pedestrian detection in the dark, we show how synthetic low-light samples can be used to better characterize the performance of a state-of-the-art object detection model as a function of the scene illumination. We use a synthetic RAW image augmentation technique to generate low-light samples that match the noise model of the camera sensor. Performance metrics on real and synthetic low-light data are similar, indicating that the AI model finds it hard to distinguish between them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a synthetic RAW image augmentation technique that generates low-light samples matching a camera sensor's noise model. Focused on pedestrian detection in dark conditions for autonomous driving, it compares a state-of-the-art detector's performance metrics (e.g., mAP, recall) on real low-light images versus the synthetically augmented ones. The central claim is that similar metrics across real and synthetic data indicate the model finds it hard to distinguish the domains, enabling finer-grained, continuous evaluation of detection performance as a function of scene illumination.
Significance. If the core results hold after addressing the interpretation gap, the work provides a practical method to densely sample illumination levels where real data is sparse, improving benchmark granularity for safety-critical vision tasks. The physics-based noise modeling is a strength when properly validated, as it avoids purely data-driven artifacts and supports reproducible augmentations.
major comments (2)
- [Abstract and §5] Abstract and §5 (Discussion/Conclusion): The inference that similar performance metrics on real vs. synthetic low-light data indicate the detector 'finds it hard to distinguish between them' is not supported by metric parity alone. Comparable mAP or recall can result from independent failure modes (e.g., noise statistics or artifacts degrading bounding-box regression equally) without interchangeable internal representations or decision boundaries. The paper should add direct evidence such as feature-space distances, domain classification accuracy on detector embeddings, or adversarial domain tests to substantiate this load-bearing claim for the evaluation-utility argument.
- [§3] §3 (Methods): The noise model includes free scaling parameters; the manuscript must specify their selection or fitting procedure (e.g., via sensor measurements or cross-validation on held-out real pairs) and report quantitative fidelity metrics (noise variance, histogram matching) across illumination levels to rule out post-hoc tuning that could artifactually align detection outcomes.
minor comments (2)
- [Results tables] Table 2 or equivalent results table: Include per-illumination bin breakdowns with confidence intervals to clarify the fine-grained evaluation claim.
- [Figures] Figure 3 (example images): Add side-by-side quantitative comparisons (e.g., PSNR or noise power spectra) between real and synthetic patches for visual clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of our claims and methodological transparency. We address each major comment below, proposing targeted revisions where appropriate to strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Discussion/Conclusion): The inference that similar performance metrics on real vs. synthetic low-light data indicate the detector 'finds it hard to distinguish between them' is not supported by metric parity alone. Comparable mAP or recall can result from independent failure modes (e.g., noise statistics or artifacts degrading bounding-box regression equally) without interchangeable internal representations or decision boundaries. The paper should add direct evidence such as feature-space distances, domain classification accuracy on detector embeddings, or adversarial domain tests to substantiate this load-bearing claim for the evaluation-utility argument.
Authors: We agree that metric similarity alone does not rigorously demonstrate that the detector's internal representations or decision boundaries are interchangeable between domains. Our central contribution is the utility of synthetic data for densely sampling illumination levels where real data is sparse, and the observed parity in mAP and recall across real and synthetic samples supports that the augmentations are sufficiently realistic for this evaluation purpose. We will revise the abstract and §5 to remove the phrasing that the model 'finds it hard to distinguish between them' and instead emphasize that performance parity indicates the synthetic data can serve as a proxy for fine-grained analysis. We will also add a short discussion of limitations regarding direct domain-invariance evidence and note that future work could include embedding-based analyses. revision: partial
-
Referee: [§3] §3 (Methods): The noise model includes free scaling parameters; the manuscript must specify their selection or fitting procedure (e.g., via sensor measurements or cross-validation on held-out real pairs) and report quantitative fidelity metrics (noise variance, histogram matching) across illumination levels to rule out post-hoc tuning that could artifactually align detection outcomes.
Authors: We acknowledge that the current description of the noise model parameters is insufficiently detailed. In the revised manuscript, we will explicitly document the procedure for selecting and fitting the free scaling parameters, including whether they were derived from sensor specifications, calibrated on real image pairs, or validated via cross-validation. We will also add quantitative fidelity results, such as comparisons of noise variance and intensity histogram matching between real and synthetic images at multiple illumination levels, to demonstrate that the model was not tuned post-hoc to match detection outcomes. revision: yes
Circularity Check
No significant circularity; evaluation uses independent held-out real data
full rationale
The paper describes generating synthetic low-light RAW images via an augmentation technique that matches the camera sensor noise model drawn from physics. It then reports that detection performance metrics on these synthetics are similar to those on real low-light images, from which it infers the model has difficulty distinguishing domains. This comparison is to held-out real data rather than data used to define or fit the augmentation itself. No equations or steps reduce a claimed prediction or first-principles result to the inputs by construction, and no self-citation chain or ansatz smuggling is evident in the provided derivation. The similarity observation is an empirical outcome, not a tautological re-statement of the generation process.
Axiom & Free-Parameter Ledger
free parameters (1)
- noise model scaling parameters
axioms (1)
- domain assumption The camera sensor noise can be modeled as a combination of signal-dependent and signal-independent components that remain valid under synthetic illumination reduction.
Reference graph
Works this paper leans on
-
[1]
Dual-conditioned temporal diffusion modeling for driving scene generation
Xiangyu Bai, Yedi Luo, Le Jiang, and Sarah Ostadabbas. Dual-conditioned temporal diffusion modeling for driving scene generation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8412–8419, 2025. 2
work page 2025
-
[2]
Radu Berdan, Beril Besbinar, Christoph Reinders, Junji Ot- suka, and Daisuke Iso. ReRAW: RGB-to-RAW image recon- struction via stratified sampling for efficient object detection on the edge. InProceedings of the Computer Vision and Pat- tern Recognition Conference (CVPR), pages 11833–11843,
-
[3]
Unprocessing images for learned raw denoising
Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, and Jonathan T Barron. Unprocessing images for learned raw denoising. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 2, 3
work page 2019
-
[4]
Cascade R-CNN: Delv- ing into high quality object detection
Zhaowei Cai and Nuno Vasconcelos. Cascade R-CNN: Delv- ing into high quality object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018. 3
work page 2018
-
[5]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, Tian- heng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Yue Wu, Jifeng Dai, Jingdong Wang, Jianping Shi, Wanli Ouyang, Chen Change Loy, and Dahua Lin. MMDetection: Open mmlab detection toolbox and...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[6]
Instance segmentation in the dark.International Journal of Computer Vision, 131(8):2198–2218, 2023
Linwei Chen, Ying Fu, Kaixuan Wei, Dezhi Zheng, and Fe- lix Heide. Instance segmentation in the dark.International Journal of Computer Vision, 131(8):2198–2218, 2023. 2
work page 2023
-
[7]
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, An- dreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164– 10183, 2024. 2
work page 2024
-
[8]
Conde, Steven McDonagh, Matteo Maggioni, Ales Leonardis, and Eduardo P ´erez-Pellitero
Marcos V . Conde, Steven McDonagh, Matteo Maggioni, Ales Leonardis, and Eduardo P ´erez-Pellitero. Model-based image signal processors via learnable dictionaries.Proceed- ings of the AAAI Conference on Artificial Intelligence, 36(1): 481–489, 2022. 2
work page 2022
-
[9]
David F. Crouse. On implementing 2d rectangular assign- ment algorithms.IEEE Transactions on Aerospace and Elec- tronic Systems, 52(4):1679–1696, 2016. 2
work page 2016
-
[10]
Raw-adapter: Adapting pre- trained visual model to camera raw images
Ziteng Cui and Tatsuya Harada. Raw-adapter: Adapting pre- trained visual model to camera raw images. InComputer Vision – ECCV 2024, pages 37–56, Cham, 2025. Springer Nature Switzerland. 2, 3
work page 2024
-
[11]
Multitask aet with orthogo- nal tangent regularity for dark object detection
Ziteng Cui, Guo-Jun Qi, Lin Gu, Shaodi You, Zenghui Zhang, and Tatsuya Harada. Multitask aet with orthogo- nal tangent regularity for dark object detection. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2533–2542, 2021. 2
work page 2021
-
[12]
Mauricio Delbracio, Damien Kelly, Michael S. Brown, and Peyman Milanfar. Mobile computational photography: A tour.Annual Review of Vision Science, 7(V olume 7, 2021): 571–604, 2021. 2
work page 2021
-
[13]
ImageNet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical im- age database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 2
work page 2009
-
[14]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InProceedings of the 1st Annual Conference on Robot Learning, pages 1–16. PMLR, 2017. 2
work page 2017
-
[15]
Fredo Durand, Samuel W. Hasinoff, and William T. Free- man. Noise-optimal capture for high dynamic range photog- raphy. In2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 553–560, Los Alamitos, CA, USA, 2010. IEEE Computer Society. 3 5
work page 2010
-
[16]
MBLLEN: Low-light image/video enhancement using cnns
Jianhua Wu Feifan Lv, Feng Lu and Chongsoon Lim. MBLLEN: Low-light image/video enhancement using cnns. British Machine Vision Conference, 2018. 2
work page 2018
-
[17]
Alessandro Foi, Mejdi Trimeche, Vladimir Katkovnik, and Karen Egiazarian. Practical poissonian-gaussian noise mod- eling and fitting for single-image raw-data.IEEE Transac- tions on Image Processing, 17(10):1737–1754, 2008. 3
work page 2008
-
[18]
Yang Hong, Kaixuan Wei, Linwei Chen, and Ying Fu. Craft- ing object detection in very low light.Proceedings of the British Machine Vision Conference 2021, 2021. 2
work page 2021
-
[19]
Kong Li, Zhe Dai, Xuan Wang, Yongchao Song, and Gwang- gil Jeon. GAN-Based controllable image data augmentation in low-visibility conditions for improved roadside traffic per- ception.IEEE Transactions on Consumer Electronics, 70(3): 6174–6188, 2024. 2
work page 2024
-
[20]
Zhihao Li, Ming Lu, Xu Zhang, Xin Feng, M. Salman Asif, and Zhan Ma. Efficient visual computing with camera raw snapshots.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 46(7):4684–4701, 2024. 2
work page 2024
-
[21]
Towards RAW object detection in di- verse conditions
Zhong-Yu Li, Xin Jin, Bo-Yuan Sun, Chun-Le Guo, and Ming-Ming Cheng. Towards RAW object detection in di- verse conditions. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 8859–8868,
-
[22]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. InComputer Vision – ECCV 2014, pages 740–755, Cham,
work page 2014
-
[23]
Springer International Publishing. 3
-
[24]
Learning raw image denoising with bayer pattern unification and bayer preserving augmen- tation
Jiaming Liu, Chi-Hao Wu, Yuzhi Wang, Qin Xu, Yuqian Zhou, Haibin Huang, Chuan Wang, Shaofan Cai, Yifan Ding, Haoqiang Fan, and Jue Wang. Learning raw image denoising with bayer pattern unification and bayer preserving augmen- tation. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 2070– 2077, 2019. 2
work page 2070
-
[25]
Xinhao Liu, Masayuki Tanaka, and Masatoshi Okutomi. Practical signal-dependent noise parameter estimation from a single noisy image.IEEE Transactions on Image Process- ing, 23(10):4361–4371, 2014. 3
work page 2014
-
[26]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convNet for the 2020s. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 11976– 11986, 2022. 3
work page 2022
-
[27]
Text2Traffic: a text-to-image generation and editing method for traffic scenes
Feng Lv, Haoxuan Feng, Zilu Zhang, Chunlong Xia, and Yanfeng Li. Text2Traffic: a text-to-image generation and editing method for traffic scenes. InInternational Confer- ence on AI-Generated Content (AIGC 2025), page 141830B. International Society for Optics and Photonics, SPIE, 2026. 2
work page 2025
-
[28]
Luis Oala, Marco Aversa, Gabriel Nobis, Kurt Willis, Yoan Neuenschwander, Mich `ele Buck, Christian Matek, Jerome Extermann, Enrico Pomarico, Wojciech Samek, Roderick Murray-Smith, Christoph Clausen, and Bruno Sanguinetti. Data models for dataset drift controls in machine learning with optical images.Transactions on Machine Learning Re- search, 2023. 2
work page 2023
-
[29]
PAS- CALRAW: Raw image database for object detection
Alex Omid-Zohoor, David Ta, and Boris Murmann. PAS- CALRAW: Raw image database for object detection. Stan- ford Digital Repository, 2015. Accessed: 2026-04-14. 2
work page 2015
-
[30]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, St ´efan J. van der Walt, Matthew Brett, Joshua Wil- son, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, ˙Ilhan Polat, Yu Feng, Eric ...
work page 2020
-
[31]
Invertible image signal processing
Yazhou Xing, Zian Qian, and Qifeng Chen. Invertible image signal processing. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 6287–6296, 2021. 2
work page 2021
-
[32]
UniSim: A neural closed-loop sensor simulator
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Mani- vasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Ur- tasun. UniSim: A neural closed-loop sensor simulator. In 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 1389–1399, 2023. 2
work page 2023
-
[33]
Rawgment: Noise-Accounted RAW Aug- mentation Enables Recognition in a Wide Variety of Envi- ronments
Masakazu Yoshimura, Junji Otsuka, Atsushi Irie, and Takeshi Ohashi. Rawgment: Noise-Accounted RAW Aug- mentation Enables Recognition in a Wide Variety of Envi- ronments . In2023 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 14007–14017, Los Alamitos, CA, USA, 2023. IEEE Computer Society. 2
work page 2023
-
[34]
CycleISP: Real image restoration via improved data synthesis
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. CycleISP: Real image restoration via improved data synthesis. In2020 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 2693–2702,
-
[35]
ChatScene: Knowledge-enabled safety-critical scenario generation for autonomous vehicles
Jiawei Zhang, Chejian Xu, and Bo Li. ChatScene: Knowledge-enabled safety-critical scenario generation for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15459–15469, 2024. 2 6 Making the Discrete Continuous: Synthetic RA W Augmentations for Fine-Grained Evaluation of Person Detection ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.