The Readout Shortcut: Positional Number Copying Dominates Arithmetic CoT Readout in Small Language Models
Pith reviewed 2026-05-25 06:25 UTC · model grok-4.3
The pith
Small language models achieve most chain-of-thought arithmetic accuracy by copying the final number in the reasoning trace rather than computing it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In three 1-3B instruction-tuned language models, arithmetic chain-of-thought performance is dominated by a positional readout shortcut: the model copies whichever number occupies the trailing position immediately before the answer delimiter, regardless of the logical content of the preceding steps. Gold-answer presence accounts for 54-92 percentage points of accuracy (89-92 percent of the teacher-forcing ceiling), and the final answer matches the last CoT number on 95-96 percent of incorrect items. The copy channel takes precedence over context completion; replacing the trailing number with an incorrect value drives accuracy to near zero despite correct intermediates, yet removing the number
What carries the argument
the trailing-number copy channel that operates in the answer-readout stage and overrides retained-context completion
If this is right
- Replacing the trailing number with a wrong value collapses accuracy to near zero despite correct intermediates.
- Removing the trailing number recovers 5-32 percentage points above the floor, including single-step arithmetic the model can otherwise perform.
- Qwen and Llama copy novel distractors 87-95 percent of the time; Gemma gates selectively.
- The effect replicates on GSM-Symbolic, and head-level ablation identifies architecture-specific head sets.
- On non-arithmetic BBH tasks shuffle retention drops sharply, and at 7-8B content-selective gating emerges.
Where Pith is reading between the lines
- Step-level faithfulness evaluations may be measuring positional transport rather than genuine computation.
- The shortcut could be tested by systematically removing or altering final numbers across a wider range of tasks to measure retained computational ability.
- Larger models may reduce reliance on the shortcut once content-selective gating appears, suggesting a size-dependent transition in readout strategy.
Load-bearing premise
The prefix-completion technique cleanly isolates the readout stage without altering the model's prior internal computation or context retention.
What would settle it
An experiment in which the trailing number is replaced by a distractor while all prior reasoning steps remain correct, followed by measurement of whether accuracy stays high or drops to near zero.
Figures


read the original abstract
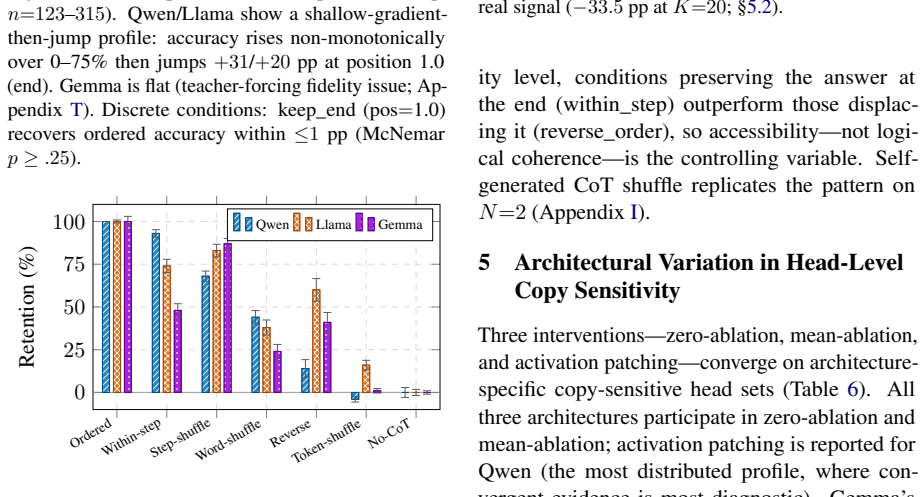
Chain-of-thought (CoT) prompting is necessary for arithmetic in small language models, yet shuffling its steps preserves most performance. What does CoT contribute if not logical sequencing? In three 1-3B instruction-tuned LMs on GSM8K, we isolate the answer-readout stage via prefix completion and identify a positional shortcut: the model copies whichever number occupies the trailing position before the answer delimiter, regardless of intermediate reasoning. Gold-answer presence accounts for 54-92 pp of accuracy (89-92% of each model's teacher-forcing ceiling); even on incorrect items, the final answer matches the last CoT number 95-96% of the time. The copy channel takes precedence over retained-context completion: replacing the trailing number with a wrong value collapses accuracy to near-zero despite correct intermediates, yet removing it recovers 5-32 pp above that floor--even single-step arithmetic the model can otherwise perform is suppressed when a copyable number is present. Qwen and Llama copy novel distractors 87-95% of the time; Gemma gates selectively. Head-level ablation implicates architecture-specific head sets; the effect replicates on GSM-Symbolic. On non-arithmetic BBH tasks, shuffle retention drops sharply; at 7-8B, content-selective gating emerges. Step-level faithfulness evaluations risk conflating positional answer transport with genuine computation--a failure mode for CoT-based oversight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in 1-3B instruction-tuned LMs on GSM8K, CoT primarily enables a positional readout shortcut: the model copies the trailing number before the answer delimiter rather than performing step-by-step reasoning. Using prefix completion to isolate readout, gold-answer presence accounts for 54-92 pp accuracy gains (89-92% of teacher-forcing ceiling); final answers match the last CoT number 95-96% of the time even on errors. Trailing-number replacement collapses accuracy to near zero while removal recovers 5-32 pp; novel distractors are copied 87-95% of the time by Qwen/Llama. Head ablations implicate architecture-specific heads; the effect replicates on GSM-Symbolic. On BBH tasks shuffle retention drops, and at 7-8B content-selective gating appears. The work warns that step-level faithfulness evaluations may conflate positional transport with computation.
Significance. If the central empirical measurements hold, the result is significant for understanding CoT mechanisms in small models and for the reliability of CoT-based oversight techniques. The direct evidence from replacement experiments, high match rates on errors, and replication on GSM-Symbolic are strengths; the head-level ablation and scaling observations to 7-8B add useful granularity. The finding that a copy channel can suppress even single-step arithmetic the model can otherwise perform is a clear, falsifiable observation with implications for interpretability work.
major comments (2)
- [prefix-completion experiments] Prefix-completion experiments (abstract and methods): the central claim that gold-answer presence drives 54-92 pp via positional copying of the trailing number depends on the technique cleanly isolating the readout stage without altering prior internal states. In transformers, conditioning on a prefix containing the full CoT plus (possibly altered) final number can modify attention patterns over earlier tokens, so the observed copying may reflect changed computation rather than native readout on unaltered context. The replacement and match-rate results are consistent with copying but do not rule out this confound.
- [results on accuracy deltas] Abstract and results sections: the reported accuracy deltas (54-92 pp) and match rates (95-96%) are presented without error bars, full dataset splits, or statistical tests. Given the noted possibility of post-hoc item/model selection, it is difficult to assess whether the effect sizes are robust or whether the 89-92% of teacher-forcing ceiling claim generalizes.
minor comments (2)
- [replication paragraph] The abstract states the effect replicates on GSM-Symbolic but does not specify whether the same prefix-completion protocol and replacement controls were applied identically.
- [abstract] Notation for 'teacher-forcing ceiling' is used without an explicit definition or equation in the provided abstract; a short methods paragraph would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of the empirical measurements. We address each major comment below, proposing revisions where the concerns are valid.
read point-by-point responses
-
Referee: [prefix-completion experiments] Prefix-completion experiments (abstract and methods): the central claim that gold-answer presence drives 54-92 pp via positional copying of the trailing number depends on the technique cleanly isolating the readout stage without altering prior internal states. In transformers, conditioning on a prefix containing the full CoT plus (possibly altered) final number can modify attention patterns over earlier tokens, so the observed copying may reflect changed computation rather than native readout on unaltered context. The replacement and match-rate results are consistent with copying but do not rule out this confound.
Authors: We agree that prefix completion could in principle alter attention patterns over earlier tokens. The replacement experiments (which modify only the trailing number while keeping the prefix otherwise fixed) and the 95-96% match rates observed during standard (non-prefix) generation provide convergent evidence that the effect is readout-driven, but these do not fully eliminate the possibility of a confound in the prefix-completion setting itself. We will add an explicit limitations paragraph discussing this architectural consideration and its implications for interpreting the isolation of the readout stage. revision: partial
-
Referee: [results on accuracy deltas] Abstract and results sections: the reported accuracy deltas (54-92 pp) and match rates (95-96%) are presented without error bars, full dataset splits, or statistical tests. Given the noted possibility of post-hoc item/model selection, it is difficult to assess whether the effect sizes are robust or whether the 89-92% of teacher-forcing ceiling claim generalizes.
Authors: We acknowledge that the current manuscript lacks error bars, explicit dataset-split details, and statistical tests, which limits assessment of robustness. The models were the primary publicly available 1-3B instruction-tuned checkpoints at the time of the study, and all experiments used the full GSM8K test set; however, we did not pre-register item or model selection criteria. We will revise the abstract and results to report bootstrap confidence intervals, state the exact splits and model selection process, and add a brief discussion of generalizability. revision: yes
Circularity Check
No circularity: purely empirical measurements on model behavior
full rationale
The paper reports experimental results from prefix-completion interventions, accuracy deltas, and match rates on GSM8K and other benchmarks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on direct observations (e.g., accuracy drops when trailing number is replaced) rather than any self-referential construction. The prefix-completion technique is an experimental method, not a definitional or fitted step that forces the outcome by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prefix completion isolates the answer-readout stage without changing the model's internal state or prior computation.
Reference graph
Works this paper leans on
-
[1]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebr \'o n, and Sumit Sanghai. 2023. GQA : Training generalized multi-query transformer models from multi-head checkpoints. In Proceedings of EMNLP
work page 2023
- [2]
-
[3]
Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy
Paul C. Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy. 2025. Thought anchors: Which LLM reasoning steps matter? arXiv preprint arXiv:2506.19143
-
[4]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schulman, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, Vlad Mikulik, Samuel R. Bowman, Jan Leike, Jared Kaplan, and Ethan Perez. 2025. Reasoning models don't always say what they think. arXiv preprint arXiv:2505.05410
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yi-Chang Chen, Feng-Ting Liao, Da-shan Shiu, and Hung-yi Lee. 2026. Rethinking dense sequential chains: Reasoning language models can extract answers from sparse, order-shuffling chain-of-thoughts. arXiv preprint arXiv:2605.07307
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [7]
-
[8]
Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. 2023. Faith and fate: Limits of transformers on compositionality. In NeurIPS
work page 2023
- [9]
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aieleen Letman, Akhil Mathur, Alan Schelten, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, and 1 others. 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 645(8081):633--638
work page 2025
-
[12]
Sture Holm. 1979. A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 6(2):65--70
work page 1979
-
[13]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In NeurIPS
work page 2022
-
[14]
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, and 1 others. 2025. Chain of thought monitorability: A new and fragile opportunity for AI safety. arXiv preprint arXiv:2507.11473
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, and 1 others. 2023. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let's verify step by step. arXiv preprint arXiv:2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the ACL, 12:157--173
work page 2024
- [18]
-
[19]
Tom McCoy, Ellie Pavlick, and Tal Linzen. 2019. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. In Proceedings of ACL, pages 3428--3448
work page 2019
- [20]
-
[21]
Quinn McNemar. 1947. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2):153--157
work page 1947
-
[22]
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. 2025. GSM-Symbolic : Understanding the limitations of mathematical reasoning in large language models. In ICLR
work page 2025
-
[23]
Yaniv Nikankin, Anja Reusch, Aaron Mueller, and Yonatan Belinkov. 2025. Arithmetic without algorithms: Language models solve math with a bag of heuristics. In ICLR
work page 2025
-
[24]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, and 1 others. 2022. In-context learning and induction heads. Transformer Circuits Thread
work page 2022
-
[25]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. Are NLP models really able to solve simple math word problems? In Proceedings of NAACL-HLT, pages 2080--2094
work page 2021
-
[26]
Jacob Pfau, William Merrill, and Samuel R. Bowman. 2024. Let's think dot by dot: Hidden computation in transformer language models. In Conference on Language Modeling (COLM)
work page 2024
-
[27]
Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, L \'e onard Hussenot, Thomas Mesnard, Bobak Shahriari, and 1 others. 2024. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Sch \"a rli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In ICML
work page 2023
-
[29]
Brown, Adam Santoro, Aditya Gupta, Adri \`a Garriga-Alonso, and 1 others
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adri \`a Garriga-Alonso, and 1 others. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research
work page 2023
-
[30]
Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. 2023. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis. In Proceedings of EMNLP
work page 2023
-
[31]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2024. RoFormer : Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063
work page 2024
-
[32]
Mirac Suzgun, Nathan Scales, Nathanael Sch \"a rli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, and Jason Wei. 2023. Challenging BIG-Bench tasks and whether chain-of-thought can solve them. In Findings of ACL
work page 2023
-
[33]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. In Advances in Neural Information Processing Systems 36 (NeurIPS)
work page 2023
-
[34]
Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. 2023 a . Towards understanding chain-of-thought prompting: An empirical study of what matters. In Proceedings of ACL
work page 2023
-
[35]
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2023 b . Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In ICLR
work page 2023
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35 (NeurIPS)
work page 2022
-
[37]
Edwin B. Wilson. 1927. Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22(158):209--212
work page 1927
- [38]
-
[39]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Chang Wang, and 1 others. 2024. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Fred Zhang and Neel Nanda. 2024. Towards best practices of activation patching in language models: Metrics and methods. In ICLR
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.