Transcoders Trace Visual Grounding and Hallucinations in Vision-Language Models
Pith reviewed 2026-05-25 06:18 UTC · model grok-4.3
The pith
Transcoders decompose VLMs into pathways that link image patches to token generation and predict hallucinations via circuit graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
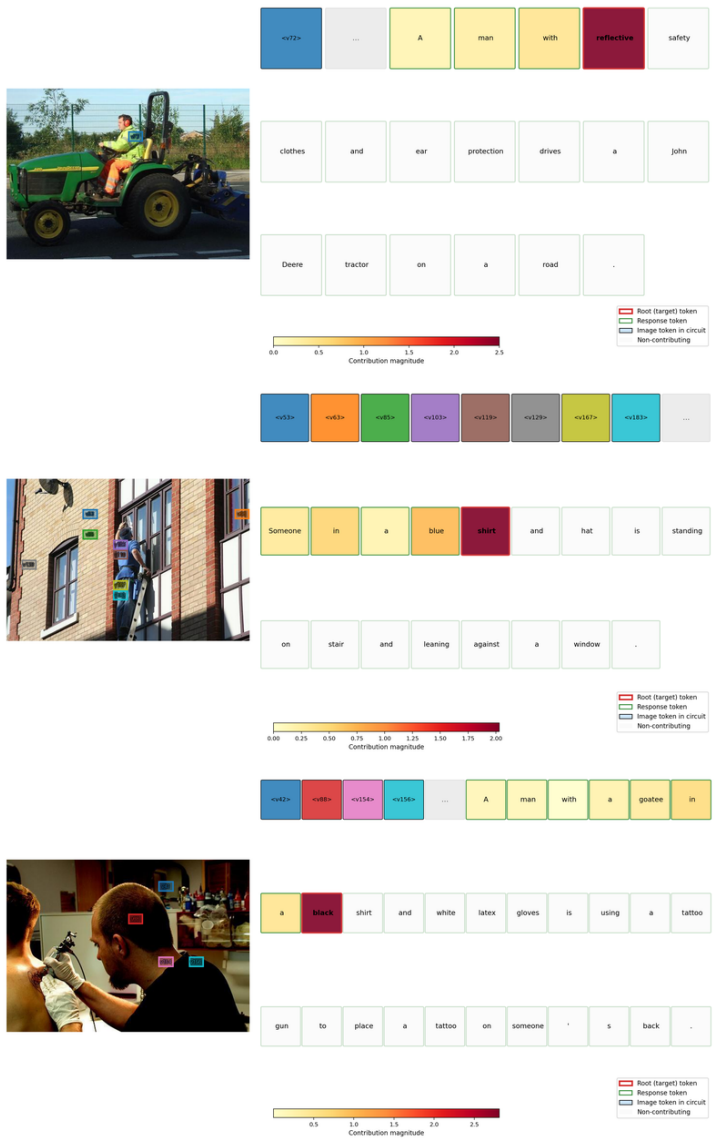
Applied to Gemma 3-4B-IT, transcoders decompose the model into interpretable computational pathways linking image patches to directions in token generation. Transcoder attributions produce stronger and more stable effects on visually grounded tokens under patch ablation than SAE attributions, and align better with semantically relevant image regions. A False Visual Grounding counterfactual analysis confirms that the recovered pathways are specific to vision-language interaction. Structural analysis of hallucinated generations extracts graph-based indicators from circuit traces produced by the transcoders, enabling a logistic classifier over these mechanistic graph features to predict hallucn
What carries the argument
Transcoders as sparse approximations of MLP sublayers that act as a causal proxy for layer-wise functional updates.
If this is right
- Transcoder attributions affect visually grounded tokens more strongly and stably than SAE attributions under patch ablation.
- The recovered pathways align more closely with semantically relevant image regions than those from prior methods.
- Counterfactual analysis with false visual grounding isolates the pathways as specific to vision-language interaction.
- Graph features extracted from transcoder circuit traces support a logistic classifier that predicts hallucinations at AUC 0.68.
Where Pith is reading between the lines
- The same transcoder decomposition could be run on other VLMs to test whether similar grounding pathways appear across architectures.
- Targeted interventions on the identified circuits might reduce hallucination rates without full retraining.
- Real-time extraction of the graph indicators could serve as an online detector for ungrounded outputs during generation.
Load-bearing premise
Transcoders serve as a faithful causal proxy for the functional updates inside the model's MLP sublayers.
What would settle it
An experiment in which ablating patches identified by transcoder attributions fails to produce larger or more stable changes to grounded token probabilities than SAE attributions, or in which the graph-feature classifier achieves AUC no higher than random, would falsify the central claims.
Figures


















read the original abstract
Generative Vision-Language Models (VLMs) perform well on multimodal reasoning, but how visual inputs are transformed to text remains poorly understood. Existing interpretability work on VLMs uses Sparse Autoencoders (SAEs), which decompose static residual representations and miss the functional updates that drive cross-modal interaction. We adopt a function-centric framework based on Transcoders, sparse approximations of MLP sublayers that act as a causal proxy for layer-wise computation. Applied to Gemma 3-4B-IT, the framework decomposes the model into interpretable computational pathways linking image patches to directions in token generation. Transcoder attributions produce stronger and more stable effects on visually grounded tokens under patch ablation than SAE attributions, and align better with semantically relevant image regions. A False Visual Grounding counterfactual analysis confirms that the recovered pathways are specific to vision-language interaction.Finally, we perform a structural analysis of hallucinated generations, by extracting graph-based indicators from circuit traces produced by the transcoders. A logistic classifier over these mechanistic graph features predicts hallucinations at AUC $0.68$. These results show that function-centric circuit decomposition yields interpretable and predictive accounts of multimodal computation in VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a function-centric framework using Transcoders to approximate MLP sublayers in VLMs like Gemma 3-4B-IT provides interpretable computational pathways for visual grounding. Transcoder attributions are shown to have stronger and more stable effects on visually grounded tokens under patch ablation than SAE attributions, align better with semantic regions, and a logistic classifier using graph-based features from the traces predicts hallucinations with AUC 0.68. A counterfactual analysis supports the specificity to vision-language interaction.
Significance. Should the results be confirmed with additional controls, this approach could offer a more causal and predictive understanding of how visual inputs influence text generation in VLMs, improving upon representation-based methods like SAEs for tasks such as hallucination detection.
major comments (2)
- [Abstract] The interpretation of transcoder attributions as direct drivers of cross-modal token generation depends on the unverified faithfulness of transcoders as causal proxies for the original MLP computation on VLM inputs. The manuscript provides no quantitative check of reconstruction error on image-patch activations or ablation results using the original MLP instead of the transcoder, which is central to the claim of superior stability and alignment.
- [Hallucination prediction results] The reported AUC of 0.68 for the logistic classifier over mechanistic graph features is presented without error bars, details on the number of hallucinated vs. non-hallucinated examples, cross-validation procedure, or statistical tests, making it hard to evaluate the robustness of the predictive account.
minor comments (1)
- [Notation] Define 'mechanistic graph features' more explicitly in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and will incorporate the suggested additions to strengthen the manuscript's claims regarding transcoder faithfulness and the robustness of the hallucination prediction results.
read point-by-point responses
-
Referee: [Abstract] The interpretation of transcoder attributions as direct drivers of cross-modal token generation depends on the unverified faithfulness of transcoders as causal proxies for the original MLP computation on VLM inputs. The manuscript provides no quantitative check of reconstruction error on image-patch activations or ablation results using the original MLP instead of the transcoder, which is central to the claim of superior stability and alignment.
Authors: We agree that the current manuscript lacks explicit quantitative faithfulness checks on image-patch activations and direct ablations comparing the transcoder to the original MLP. While the framework draws on established transcoder methodology and the False Visual Grounding counterfactual provides supporting evidence for specificity to vision-language interactions, these additional controls are needed to fully substantiate the causal proxy claim. We will add reconstruction error metrics on image-patch activations and original-MLP ablation comparisons in the revised manuscript. revision: yes
-
Referee: [Hallucination prediction results] The reported AUC of 0.68 for the logistic classifier over mechanistic graph features is presented without error bars, details on the number of hallucinated vs. non-hallucinated examples, cross-validation procedure, or statistical tests, making it hard to evaluate the robustness of the predictive account.
Authors: We acknowledge that the hallucination prediction results require additional details for proper evaluation. In the revision we will report error bars on the AUC (computed over cross-validation folds or bootstrap samples), the exact counts of hallucinated and non-hallucinated examples, the cross-validation procedure, and results of statistical tests against appropriate baselines. revision: yes
Circularity Check
No significant circularity; results rely on external benchmarks
full rationale
The paper applies transcoders to Gemma 3-4B-IT and evaluates attribution stability via patch ablation, semantic region alignment, and a False Visual Grounding counterfactual, all external to the fitted transcoder parameters. The AUC 0.68 arises from a logistic classifier trained on graph features extracted from circuit traces to predict an independent target (hallucinations). No equation or claim reduces a reported metric to a quantity defined by the authors' own fitted values or self-citation chain; the derivation remains self-contained against these benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Saes are good for steering–if you select the right features
Dana Arad, Aaron Mueller, and Yonatan Belinkov. Saes are good for steering–if you select the right features. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10252–10270,
work page 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review.arXiv preprint arXiv:2404.14082,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Steven Bills, Nick Cammarata, Jeff Wu, et al. Revising and falsifying sparse autoencoder feature explanations.arXiv preprint arXiv:2502.12345,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
URL https://transformer-circuits.pub/ 2023/monosemantic-features/index.html. Accessed: 2026-04-26. Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Mon- itoring and controlling character traits in language models.arXiv preprint arXiv:2507.21509,
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
-
[7]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Controllable llm reasoning via sparse autoencoder-based steering.arXiv preprint arXiv:2601.03595,
Yi Fang, Wenjie Wang, Mingfeng Xue, Boyi Deng, Fengli Xu, Dayiheng Liu, and Fuli Feng. Controllable llm reasoning via sparse autoencoder-based steering.arXiv preprint arXiv:2601.03595,
-
[9]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/2503.19786. Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ActivationReasoning: Logical Reasoning in Latent Activation Spaces
URLhttps://arxiv.org/abs/2510.18184. Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://transformer-circuits.pub/2024/crosscoders/index.html. Ac- cessed: 2026-04-26. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916,
work page 2024
-
[13]
Scott M Lundberg and Su-In Lee
URLhttps://arxiv.org/abs/2502.17514. Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in neural information processing systems, 30,
-
[14]
When Seeing Overrides Knowing: Disentangling Knowledge Conflicts in Vision-Language Models
URL https://arxiv.org/ abs/2507.13868. Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. Sparse autoencoders learn monosemantic features in vision-language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https:// arxiv.org/abs/2504.02821. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
-
[16]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.71. URL https://aclanthology.org/2021.acl-long.71/. Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps.arXiv preprint arXiv:1312.6034,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.acl-long.71 2021
-
[17]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Samuel Soo, Chen Guang, Wesley Teng, Chandrasekaran Balaganesh, Tan Guoxian, and Yan Ming. Interpretable steering of large language models with feature guided activation additions.arXiv preprint arXiv:2501.09929,
-
[19]
Anthropic Interpretability Team
URLhttps://arxiv.org/abs/2502.06755. Anthropic Interpretability Team. Insights on crosscoder model diffing.Anthropic Technical Blog,
-
[20]
Jingcheng Yang, Tianhu Xiong, Shengyi Qian, Klara Nahrstedt, and Mingyuan Wu. Circuit tracing in vision-language models: Understanding the internal mechanisms of multimodal thinking.arXiv preprint arXiv:2602.20330,
-
[21]
Interpreting clip with hierarchical sparse autoencoders.arXiv preprint arXiv:2502.20578,
Vladimir Zaigrajew, Hubert Baniecki, and Przemyslaw Biecek. Interpreting clip with hierarchical sparse autoencoders.arXiv preprint arXiv:2502.20578,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.