Online Hand Gesture Recognition Using 3D Convolutional Neural Networks
Pith reviewed 2026-05-25 04:48 UTC · model grok-4.3
The pith
An online system using 3D convolutional neural networks localizes and recognizes hand gestures in real-time video streams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors built an online hand gesture recognition system that can localize gestures within a real-time video stream and identify them. The detector model reaches over 98 percent accuracy and the classifier over 90 percent accuracy when trained and tested on the Jester database. When evaluated on a homemade dataset the best configuration responds in under three seconds and achieves 37.5 percent Levenshtein accuracy.
What carries the argument
3D convolutional neural networks for video feature extraction paired with a sliding window approach to refine predictions across multiple overlapping video segments.
If this is right
- Gesture localization happens continuously in streaming video without noticeable lag.
- Classification accuracy exceeds 90 percent on the training distribution.
- The full system can output recognized gesture sequences with partial matching measured by Levenshtein distance.
- Response times stay below three seconds for complete gestures in the best case.
Where Pith is reading between the lines
- The method could be adapted to other dynamic action recognition tasks in video by swapping the gesture labels.
- Public release of the code makes it possible to measure performance drops when moving from the Jester set to entirely new environments.
- Combining the 3D CNN outputs with additional temporal smoothing might further raise the Levenshtein score on variable data.
Load-bearing premise
The Jester database contains enough variation in gesture execution to prepare the models for real-world use, and the sliding window refinement adds accuracy without creating extra delays or mistakes in live streams.
What would settle it
Running the trained system on a large collection of unscripted videos recorded in varied lighting, backgrounds, and with different users and measuring whether detection and classification accuracies remain above 80 percent while keeping response time under three seconds.
Figures


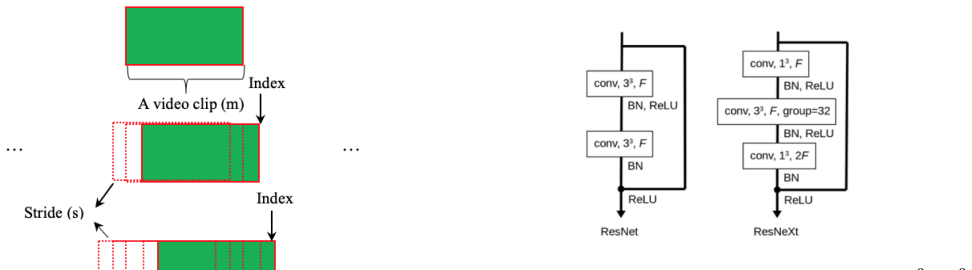


read the original abstract
In human computer interaction, real-time detection and classification of dynamic hand gestures is challenging as: 1) the system must run in a real-time video stream and there is no noticeable lag in response after performing a gesture; 2) there is a large difference in how people perform gestures, making recognition more difficult. In this paper, an online hand gesture recognition system is proposed, which is able to localize gestures in real-time video stream and recognize what these gestures are. To improve the robustness of the system, the sliding window approach is used to refine results from multiple windows. All of the models in my project are trained on Jester database, achieving 98+% accuracy for detector and 90+% accuracy for classifier. For the overall performance of the system, the best group can respond within three seconds and reach 37.5% Levenshtein accuracy on the homemade dataset. The project codes used in this work are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an online hand gesture recognition system using 3D CNNs to localize and classify dynamic gestures in real-time video streams. A detector and classifier are trained on the Jester dataset (reporting 98+% and 90+% accuracy respectively), with a sliding-window approach to refine outputs across multiple windows. The full system is evaluated on a homemade dataset, where the best configuration responds within three seconds and achieves 37.5% Levenshtein accuracy. Code is made publicly available.
Significance. If the integration and generalization claims hold, the work would offer a practical contribution to real-time HCI by combining 3D CNN components with sliding-window refinement for continuous streams. The public code release is a clear strength for reproducibility. However, the reported performance gap between Jester component accuracies and overall homemade results raises questions about whether the approach reliably transfers to live streams, which would limit its significance without further validation.
major comments (2)
- [Abstract] Abstract: The central claim that the system 'localize[s] gestures in real-time video stream and recognize[s] what these gestures are' rests on untested transfer from Jester to live streams. The 37.5% Levenshtein accuracy on the homemade dataset is reported without separate detector/classifier accuracies or an ablation of the sliding-window step on that data, leaving the source of the performance drop (dataset variability vs. online integration errors) undiagnosed and undermining the online-system claim.
- [Abstract] Abstract: No variance, confidence intervals, or statistical tests are provided for the 98+% detector and 90+% classifier accuracies on Jester, nor for the 37.5% Levenshtein result; this makes it impossible to determine whether the component metrics reliably support the overall system performance assertion.
minor comments (1)
- [Abstract] The phrase 'the best group' is used without defining the grouping criterion or how groups were formed in the homemade evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the system 'localize[s] gestures in real-time video stream and recognize[s] what these gestures are' rests on untested transfer from Jester to live streams. The 37.5% Levenshtein accuracy on the homemade dataset is reported without separate detector/classifier accuracies or an ablation of the sliding-window step on that data, leaving the source of the performance drop (dataset variability vs. online integration errors) undiagnosed and undermining the online-system claim.
Authors: The detector and classifier accuracies were measured on Jester to confirm model quality before integration. The homemade dataset evaluates the full online pipeline (localization plus classification) under continuous streaming conditions, with Levenshtein distance quantifying sequence-level correctness. We agree that separate per-component metrics and a sliding-window ablation on the homemade data are absent and would help diagnose the performance gap. In revision we will add these results together with a short discussion attributing the drop mainly to higher inter-subject variability in the homemade recordings while noting that the sliding-window refinement reduces integration errors. revision: yes
-
Referee: [Abstract] Abstract: No variance, confidence intervals, or statistical tests are provided for the 98+% detector and 90+% classifier accuracies on Jester, nor for the 37.5% Levenshtein result; this makes it impossible to determine whether the component metrics reliably support the overall system performance assertion.
Authors: The reported figures are single-run point estimates. We accept that variance measures and statistical context are needed for proper interpretation. The revised manuscript will include standard deviations obtained from repeated training runs (or cross-validation folds) on Jester and will state the size of the homemade test sequences used for the Levenshtein metric. revision: yes
Circularity Check
No circularity; empirical training and evaluation on distinct datasets
full rationale
The paper describes training 3D CNN detector and classifier models on the Jester database, then applying a sliding-window integration for online recognition and reporting Levenshtein accuracy on a separate homemade dataset. No load-bearing mathematical derivation, parameter fitting presented as prediction, or self-citation chain exists; all reported accuracies are direct empirical results from training/testing splits with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- sliding window parameters
- neural network hyperparameters
axioms (1)
- domain assumption 3D CNNs can effectively capture spatio-temporal features in video for gesture recognition
Reference graph
Works this paper leans on
-
[1]
2016 IEEE International Conference on Electron Devices and Solid-State Circuits (EDSSC) , pages=
Glove-based hand gesture recognition sign language translator using capacitive touch sensor , author=. 2016 IEEE International Conference on Electron Devices and Solid-State Circuits (EDSSC) , pages=. 2016 , organization=
work page 2016
-
[2]
2018 International Conference on Applied and Theoretical Electricity (ICATE) , pages=
Development of a wireless glove based on RFID Sensor , author=. 2018 International Conference on Applied and Theoretical Electricity (ICATE) , pages=. 2018 , organization=
work page 2018
-
[3]
IEEE Transactions on Industrial Informatics , volume=
A wearable gesture recognition device for detecting muscular activities based on air-pressure sensors , author=. IEEE Transactions on Industrial Informatics , volume=. 2015 , publisher=
work page 2015
-
[4]
2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019) , pages=
Real-time hand gesture detection and classification using convolutional neural networks , author=. 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019) , pages=. 2019 , organization=
work page 2019
-
[5]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[6]
Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Hand gesture recognition with 3D convolutional neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
-
[7]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Improving the performance of unimodal dynamic hand-gesture recognition with multimodal training , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops , pages=
Motion fused frames: Data level fusion strategy for hand gesture recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[9]
Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
The jester dataset: A large-scale video dataset of human gestures , author=. Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
-
[10]
Image and Vision Computing , volume=
Dynamic hand gesture recognition: An exemplar-based approach from motion divergence fields , author=. Image and Vision Computing , volume=. 2012 , publisher=
work page 2012
-
[11]
2012 IEEE Conference on Computer Vision and Pattern Recognition , pages=
Evaluation of low-level features and their combinations for complex event detection in open source videos , author=. 2012 IEEE Conference on Computer Vision and Pattern Recognition , pages=. 2012 , organization=
work page 2012
-
[12]
IEEE transactions on intelligent transportation systems , volume=
Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations , author=. IEEE transactions on intelligent transportation systems , volume=. 2014 , publisher=
work page 2014
-
[13]
International journal of computer vision , volume=
A robust and efficient video representation for action recognition , author=. International journal of computer vision , volume=. 2016 , publisher=
work page 2016
-
[14]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
Large-scale video classification with convolutional neural networks , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Advances in neural information processing systems , pages=
Two-stream convolutional networks for action recognition in videos , author=. Advances in neural information processing systems , pages=
-
[16]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Long-term recurrent convolutional networks for visual recognition and description , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[17]
European conference on computer vision , pages=
Temporal segment networks: Towards good practices for deep action recognition , author=. European conference on computer vision , pages=. 2016 , organization=
work page 2016
-
[18]
IEEE transactions on pattern analysis and machine intelligence , volume=
3D convolutional neural networks for human action recognition , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2012 , publisher=
work page 2012
-
[19]
Proceedings of the IEEE international conference on computer vision , pages=
Learning spatiotemporal features with 3d convolutional networks , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[20]
Multi-sensor system for driver's hand-gesture recognition , author=. 2015 11th IEEE international conference and workshops on automatic face and gesture recognition (FG) , volume=. 2015 , organization=
work page 2015
-
[21]
Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
Learning spatio-temporal features with 3D residual networks for action recognition , author=. Proceedings of the IEEE International Conference on Computer Vision Workshops , pages=
-
[22]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
-
[23]
IEEE Transactions on Multimedia , volume=
Egogesture: a new dataset and benchmark for egocentric hand gesture recognition , author=. IEEE Transactions on Multimedia , volume=. 2018 , publisher=
work page 2018
-
[24]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Aggregated residual transformations for deep neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[25]
Computer vision and image understanding , volume=
The visual analysis of human movement: A survey , author=. Computer vision and image understanding , volume=. 1999 , publisher=
work page 1999
-
[26]
Improving neural networks by preventing co-adaptation of feature detectors
Improving neural networks by preventing co-adaptation of feature detectors , author=. arXiv preprint arXiv:1207.0580 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Soviet physics doklady , volume=
Binary codes capable of correcting deletions, insertions, and reversals , author=. Soviet physics doklady , volume=
-
[28]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Temporal relational reasoning in videos , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[29]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
SSNet: scale selection network for online 3D action prediction , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
2019 IEEE International Conference on Image Processing (ICIP) , pages=
Gesture Recognition Using Spatiotemporal Deformable Convolutional Representation , author=. 2019 IEEE International Conference on Image Processing (ICIP) , pages=. 2019 , organization=
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.