CVSearch: Empowering Multimodal LLMs with Cognitive Visual Search for High-Resolution Image Perception
Pith reviewed 2026-05-25 04:45 UTC · model grok-4.3
The pith
CVSearch enables multimodal LLMs to perceive high-resolution images by adaptively switching between expert-assisted search and semantic scanning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
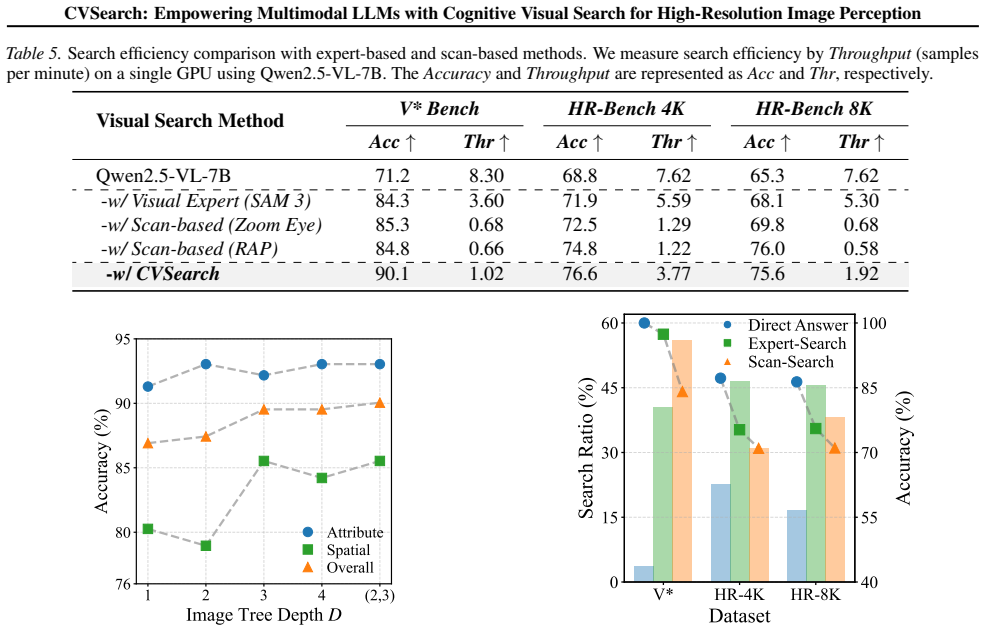
CVSearch is a training-free adaptive framework that dynamically schedules search strategies via an Assess-then-Search workflow: it invokes expert-assisted search when global information is insufficient, and triggers semantic-aware scanning with Semantic Guided Adaptive Patching and Dynamic Bottom-Up Search only upon failure, achieving state-of-the-art accuracy and improved efficiency on HR benchmarks.
What carries the argument
The Assess-then-Search workflow that combines expert-assisted search with semantic-aware scanning triggered on failure, using Semantic Guided Adaptive Patching to avoid object fragmentation and Dynamic Bottom-Up Search driven by a Visual Complexity prior.
Load-bearing premise
The Assess-then-Search workflow correctly identifies when global information is insufficient and that failure of expert-assisted search reliably triggers the semantic scanning without introducing new blind spots or excessive overhead.
What would settle it
A benchmark where expert-assisted search proposals miss critical objects but the subsequent semantic scanning also fails to recover them at higher cost than a full grid scan would have required.
Figures










read the original abstract
High-resolution (HR) image perception presents a key bottleneck for multimodal large language models (MLLMs). While visual search offers a promising solution, existing methods struggle with the trade-off between coverage and efficiency. Visual expert-assisted search is efficient but prone to blind spots when proposals fail, whereas scan-based search guarantees coverage at the cost of computational redundancy and semantic fragmentation. To address this dilemma, we introduce CVSearch, a training-free adaptive framework that dynamically schedules search strategies via an Assess-then-Search workflow. Specifically, CVSearch first invokes expert-assisted search when global information is insufficient, and only triggers a novel semantic-aware scanning mechanism upon failure. Distinct from rigid grid partitioning, this efficient scanning paradigm incorporates Semantic Guided Adaptive Patching to decompose images into semantically consistent regions, effectively mitigating object fragmentation. Furthermore, we devise a Dynamic Bottom-Up Search strategy driven by a Visual Complexity prior to enable efficient and precise iterative exploration of local details. Extensive experiments on HR benchmarks demonstrate that CVSearch achieves state-of-the-art accuracy while substantially improving search efficiency. Code is released at https://github.com/liliupeng28/ICML26-CVSearch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CVSearch, a training-free adaptive framework for high-resolution image perception in multimodal LLMs. It uses an Assess-then-Search workflow that first applies expert-assisted search when global information is insufficient and triggers semantic-aware scanning (with Semantic Guided Adaptive Patching and Dynamic Bottom-Up Search driven by a Visual Complexity prior) only upon failure. The central claim is that this resolves the coverage-efficiency trade-off and achieves state-of-the-art accuracy with substantially improved search efficiency on HR benchmarks; code is released.
Significance. If the empirical results hold, the work addresses a practical bottleneck for MLLMs on high-resolution inputs by adaptively combining search primitives without training. The training-free design and released code are explicit strengths that support reproducibility and allow direct falsification of the pipeline. This could meaningfully improve vision-language performance on tasks requiring fine local detail.
minor comments (3)
- [Method] The description of how the initial global insufficiency check is implemented (e.g., which MLLM outputs or thresholds are used) should be expanded with pseudocode or a concrete example to make the Assess-then-Search decision reproducible.
- [Experiments] Table or figure reporting the efficiency metrics (e.g., number of patches or tokens processed) should include standard deviations across runs or datasets to substantiate the 'substantially improving search efficiency' claim.
- [Method] The paper should clarify whether the expert-assisted search component relies on any external models or APIs whose failure modes could affect the overall pipeline.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its practical significance for MLLMs on high-resolution inputs, and the recommendation for minor revision. The training-free design and code release are indeed intended to facilitate reproducibility and direct evaluation.
Circularity Check
No significant circularity; procedural framework with external empirical validation
full rationale
The paper describes a training-free procedural framework (Assess-then-Search workflow with expert-assisted search, Semantic Guided Adaptive Patching, and Dynamic Bottom-Up Search) without any equations, derivations, fitted parameters, or self-referential definitions. Central claims rest on experimental results from HR benchmarks, which are independent of the method description. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes or known results are renamed or smuggled. The pipeline is explicitly falsifiable and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y .-T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K. V ., Khedr, H., Huang, A., et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ge, C., Cheng, S., Wang, Z., Yuan, J., Gao, Y ., Song, J., Song, S., Huang, G., and Zheng, B. Convllava: Hierar- chical backbones as visual encoder for large multimodal models.arXiv preprint arXiv:2405.15738,
-
[4]
Huang, M., Liu, Y ., Liang, D., Jin, L., and Bai, X. Mini- monkey: Alleviating the semantic sawtooth effect for lightweight mllms via complementary image pyramid. arXiv preprint arXiv:2408.02034,
-
[5]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., et al. Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024a. Li, F., Zhang, R., Zhang, H., Zhang, Y ., Li, B., Li, W., Ma, Z., and Li, C. Llava-next-interleave: Tackling multi- image, video, and 3d in large multimodal models.arX...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Lu, Z., Li, L., Wang, J., Feng, Y ., Chen, B., Chen, K., and Wang, Y . CoPRS: Learning positional prior from chain- of-thought for reasoning segmentation. InThe Fourteenth International Conference on Learning Representations, 2026a. Lu, Z., Li, L., Wang, J., Kang, H., Feng, Y ., Chen, K., and Wang, Y . Segcompass: Exploring interpretable align- ment with ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Modern hierarchical, agglomerative clustering algorithms
10 CVSearch: Empowering Multimodal LLMs with Cognitive Visual Search for High-Resolution Image Perception M¨ullner, D. Modern hierarchical, agglomerative clustering algorithms.arXiv preprint arXiv:1109.2378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
V$^{2}$-SAM: Marrying SAM2 with Multi-Prompt Experts for Cross-View Object Correspondence
Pan, J., Wang, R., Qian, T., Mahdi, M., Fu, Y ., Xue, X., Huang, X., Van Gool, L., Paudel, D. P., and Fu, Y . V2-sam: Marrying sam2 with multi-prompt experts for cross-view object correspondence.arXiv preprint arXiv:2511.20886,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Shen, H., Zhao, K., Zhao, T., Xu, R., Zhang, Z., Zhu, M., and Yin, J. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based im- age exploration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 6613–6629,
work page 2025
-
[11]
Team, Q. et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3),
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Vardakas, G., Papakostas, I., and Likas, A. Deep clustering using the soft silhouette score: Towards compact and well-separated clusters.arXiv preprint arXiv:2402.00608,
-
[14]
Wang, H., Li, X., Huang, Z., Wang, A., Wang, J., Zhang, T., Zheng, J., Bai, S., Kang, Z., Feng, J., et al. Traceable evidence enhanced visual grounded reasoning: Evalua- tion and methodology.arXiv preprint arXiv:2507.07999, 2025a. Wang, H., Su, A., Ren, W., Lin, F., and Chen, W. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven rei...
-
[15]
ai.arXiv preprint arXiv:2403.04652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Zhang, J., Khayatkhoei, M., Chhikara, P., and Ilievski, F. Mllms know where to look: Training-free perception of small visual details with multimodal llms.arXiv preprint arXiv:2502.17422, 2025a. Zhang, L., Yu, J., Xiong, H., Hu, P., Zhuge, Y ., Lu, H., and He, Y . Finers: Fine-grained reasoning and segmenta- tion of small objects with reinforcement learni...
-
[17]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.