Saturating Scaling Laws for Equational Discovery: A Phenomenology of Growth Dynamics in Three Toy Substrates with Two Real-World Replications
Pith reviewed 2026-06-30 20:08 UTC · model grok-4.3
The pith
Growth of new equations in discovery systems follows power laws whose form and parameters depend on the substrate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
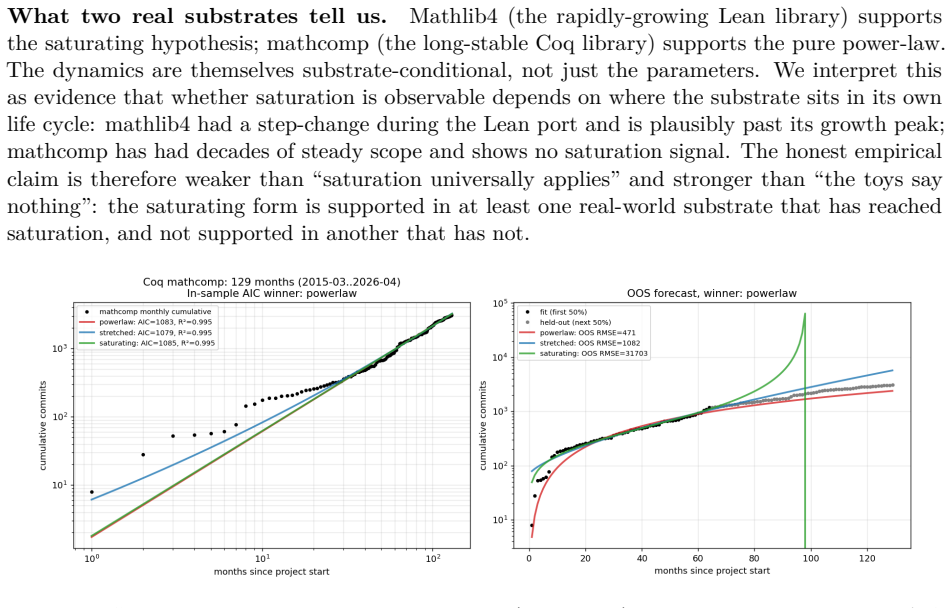
Across 592 trajectories in arithmetic, boolean, and higher-order list substrates, short-range N(t) obeys a power law N(t) proportional to t^b where b is sensitive to the search architecture inside each substrate yet yields negative R^2 when the regression is transferred to another substrate. A heuristic closure model supplies the saturating differential equation dN/dt = K N^k exp(-mu N), of which the pure power law is the short-range limit. Out-of-sample tests on the toy trajectories are won by the pure power law, while Mathlib4 monthly file additions favor the saturating form and Coq mathcomp commits favor the pure form with mu collapsing to zero. The dynamics are therefore substrate-condit
What carries the argument
The saturating power-law differential equation dN/dt = K N^k exp(-mu N), whose parameters (k, mu) are treated as substrate-dependent and whose pure-power-law limit holds only before saturation sets in.
If this is right
- Architecture-specific exponents measured inside one domain cannot be used to forecast growth in another domain.
- Saturation effects become visible only after a substrate has run long enough for the exponential cutoff to matter.
- Forecasts of future equation counts must select the functional family according to the substrate rather than assuming a single universal law.
- In substrates that have entered saturation, additional compute yields diminishing returns on new discoveries.
- Pure power-law growth can persist indefinitely in some substrates when mu remains near zero.
Where Pith is reading between the lines
- Long-running automated provers may need separate scaling models for each mathematical area rather than a single global predictor.
- Resource planning for large formal libraries could shift from uniform compute scaling to substrate-aware monitoring of saturation onset.
- Extending the toy substrates for many more epochs would provide a direct test of whether the saturating regime eventually appears in all three domains.
- The split between Mathlib and mathcomp suggests that library curation style itself may act as an additional substrate variable controlling mu.
Load-bearing premise
The three toy domains and two real libraries are representative enough that the observed non-transfer of exponents and the split between pure and saturating families will appear in other equational discovery settings.
What would settle it
An additional substrate in which an architecture-to-b regression trained on one domain yields R^2 above 0.5 on another, or in which the saturating model loses to the pure power law on out-of-sample forecasting, would falsify the claim of substrate-conditional dynamics.
Figures
read the original abstract
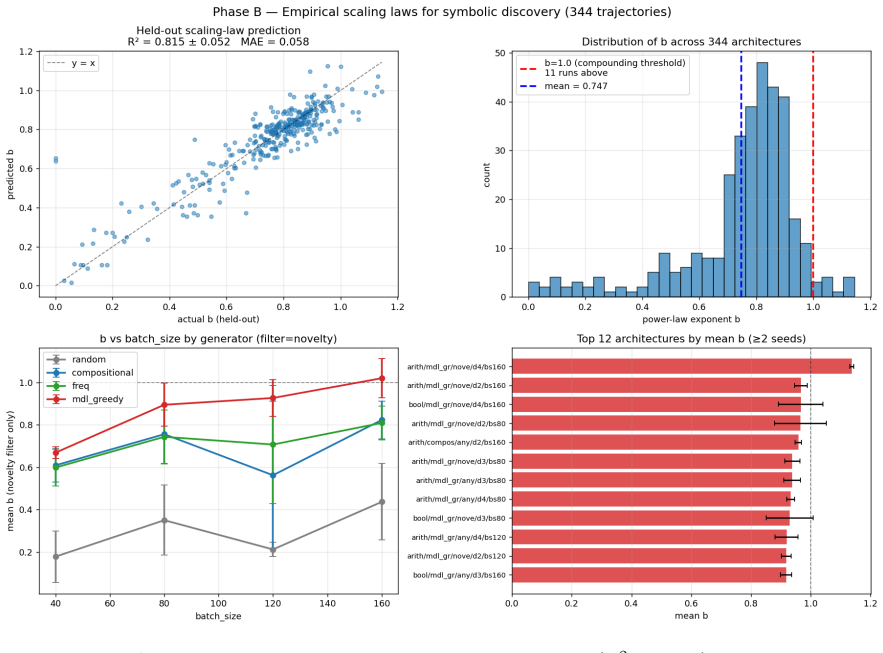
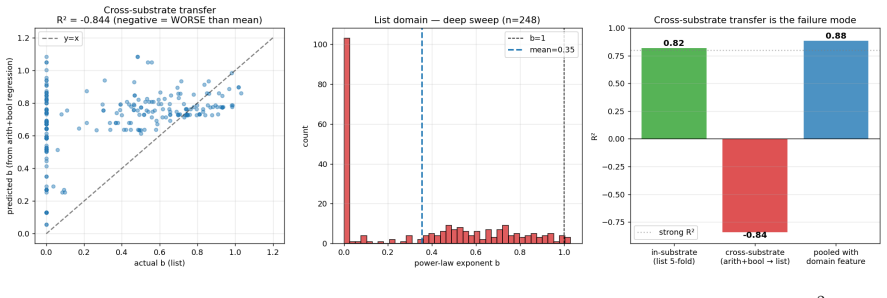
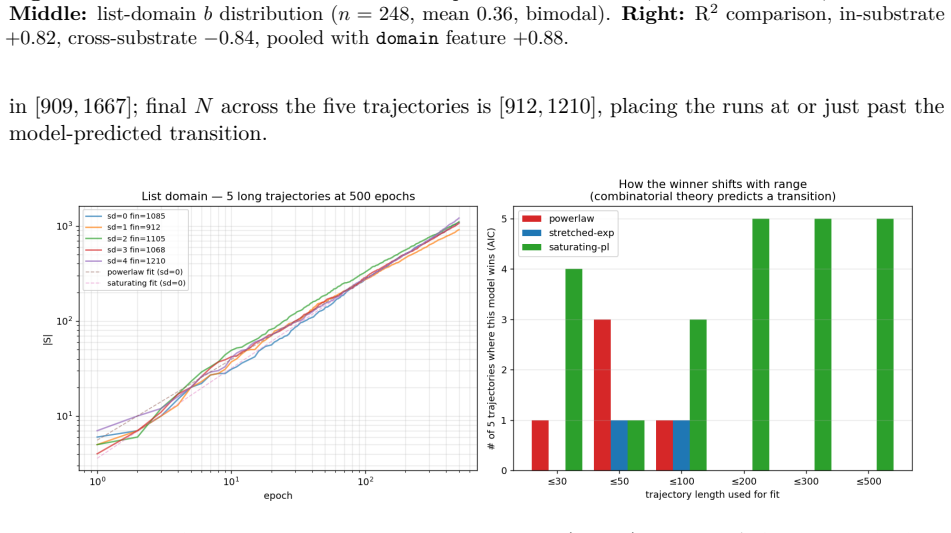
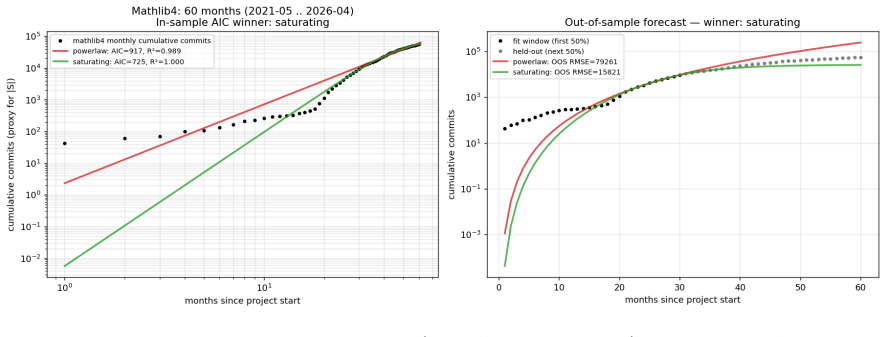
We investigate growth dynamics in deterministic equational discovery substrates. Across three toy domains (arithmetic, boolean, higher-order list; n=592 trajectories), short-range substrate sizes fit a power-law N(t) proportional to t^b. Within each substrate b is architecture-sensitive (cross-validated R^2 approximately 0.82); the regression does not transfer across substrates (arith+bool to list yields R^2 approximately -0.84). A heuristic mean-field closure model predicts a saturating power-law dN/dt = K N^k exp(-mu N) of which the pure power-law is the short-range approximation. Three robustness checks: bootstrap intervals on (k, mu) are tight in 4/5 toy trajectories and degenerate in 1/5; out-of-sample forecasting on toy data (fit first 100 epochs, predict next 400) is won by pure power-law 5/5, indicating the toy trajectories do not reach saturation; on two real-world growth proxies the result splits. New Mathlib/*.lean file additions per month (mathlib4, 60 months, 9701 files) support the saturating form on OOS forecasting by approximately 7x over pure power-law; Coq mathcomp monthly commits (129 months, 3083 commits) favour pure power-law on both tests with mu collapsing to zero. The dynamics are substrate-conditional at two levels: within-substrate architecture-to-b regressions do not transfer, and the preferred functional family for N(t) itself (pure vs. saturating power-law) differs by substrate. We propose "saturating power-law growth with substrate-conditional (k, mu), observable when the substrate has reached its saturation regime" as a working framing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines growth dynamics N(t) in equational discovery across three toy substrates (arithmetic, boolean, higher-order list; 592 trajectories) and two real proxies (Mathlib4 file additions over 60 months; Coq mathcomp commits over 129 months). Short-range toy data fit power-laws N(t) ~ t^b with architecture-sensitive b (cross-validated R² ≈ 0.82) that fail to transfer across substrates. A heuristic mean-field dN/dt = K N^k exp(-mu N) is introduced whose pure-power-law limit is the short-range case; OOS tests show toys favor pure power-law (no saturation reached), while real proxies split (Mathlib supports saturating by ~7×, mathcomp collapses mu to zero). The central claim is that dynamics are substrate-conditional at both the regression-transfer and functional-family levels, with a proposed working framing of 'saturating power-law growth with substrate-conditional (k, mu) observable when saturation is reached.'
Significance. If the substrate-conditional framing is substantiated, the work supplies a concrete phenomenology for scaling in formal discovery systems, distinguishing within-substrate architecture effects from cross-substrate non-transfer. The reported cross-validation, bootstrap intervals, and OOS forecasting (5/5 toy wins for pure power-law) constitute empirical strengths that ground the within-substrate claims.
major comments (2)
- [Abstract] Abstract: the claim that preferred functional family for N(t) (pure vs. saturating) differs systematically by substrate rests on two real-world proxies yielding opposite outcomes (Mathlib4 supports saturating ~7× on OOS; mathcomp favors pure with mu collapsing to zero). With n=2, the data cannot yet distinguish substrate-conditional behavior from case-by-case variation.
- [Abstract] Abstract (heuristic mean-field closure): the saturating form dN/dt = K N^k exp(-mu N) is introduced with free parameters k, mu fitted per substrate; the pure power-law is recovered exactly as the mu=0 limit. Consequently, the assertion that the saturating form is 'preferred when saturation is reached' is partly definitional once the functional family is selected rather than an independent forecast.
minor comments (1)
- A consolidated table listing OOS win rates, bootstrap intervals on (k, mu), and R² values for all five datasets would improve readability of the robustness checks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We respond point-by-point to the major comments, with planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that preferred functional family for N(t) (pure vs. saturating) differs systematically by substrate rests on two real-world proxies yielding opposite outcomes (Mathlib4 supports saturating ~7× on OOS; mathcomp favors pure with mu collapsing to zero). With n=2, the data cannot yet distinguish substrate-conditional behavior from case-by-case variation.
Authors: We agree that two real-world proxies are insufficient to support a claim of systematic substrate-conditional differences in functional family preference, and that the observed split could reflect case-by-case variation rather than a general pattern. The primary evidence for non-transferability remains the toy substrates (architecture-sensitive b within substrate, non-transfer across substrates). For the functional family, we will revise the abstract, results, and conclusion to present the Mathlib/mathcomp split as an empirical observation from the available proxies, qualified by the small sample size and the explicit need for additional real-world cases before generalizing. This change will be made without altering the reported OOS numbers or toy results. revision: partial
-
Referee: [Abstract] Abstract (heuristic mean-field closure): the saturating form dN/dt = K N^k exp(-mu N) is introduced with free parameters k, mu fitted per substrate; the pure power-law is recovered exactly as the mu=0 limit. Consequently, the assertion that the saturating form is 'preferred when saturation is reached' is partly definitional once the functional family is selected rather than an independent forecast.
Authors: The saturating ODE is indeed constructed so that mu=0 recovers the pure power-law exactly. However, which member of the family is preferred is decided by out-of-sample forecasting performance on held-out data, not by the choice of functional family itself. In the toy trajectories the pure power-law wins all five OOS tests, consistent with saturation not having been reached; in Mathlib the saturating form wins by a factor of approximately 7, indicating that the mu term improves predictive accuracy when saturation effects are present. We will add explicit language in the methods and discussion clarifying that model preference is an empirical result of the OOS protocol rather than a definitional consequence of selecting the saturating family. revision: partial
Circularity Check
No significant circularity; phenomenological model tested against independent data splits.
full rationale
The paper introduces a heuristic mean-field closure as an ansatz whose saturating form is chosen by construction, but then fits its parameters (k, mu) to trajectories and evaluates the pure vs. saturating families via explicit out-of-sample forecasting on held-out epochs and real-world proxies. The substrate-conditional claim rests on which family wins those OOS tests (pure in all toys, split in the two real proxies), not on any reduction of the prediction to the input data by definition. No self-citations, uniqueness theorems, or renamings of known results appear as load-bearing steps. The analysis is self-contained against external benchmarks (the 592 toy trajectories and two real proxies with their OOS splits).
Axiom & Free-Parameter Ledger
free parameters (2)
- b (power-law exponent)
- k, mu (saturating-model parameters)
axioms (2)
- domain assumption Short-range growth obeys N(t) ∝ t^b within each substrate.
- ad hoc to paper The heuristic mean-field closure dN/dt = K N^k exp(-mu N) is an appropriate description once saturation is reached.
Forward citations
Cited by 1 Pith paper
-
WorldKernel: A World Model is the Coupling Kernel of Admissible Possible Worlds
A world model is a positive semidefinite coupling kernel over admissible possible worlds, with the off-diagonal supplying the structural information for counterfactual queries that standard prediction cannot recover.
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D. Scaling laws for neural language models. arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Training Compute-Optimal Large Language Models
Hoffmann, J., Borgeaud, S., Mensch, A., et al. Training compute-optimal large language models. arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
AlphaGo moment for model architecture discovery
Liu, Y., Nan, Y., Xu, W., Hu, X., Ye, L., Qin, Z., Liu, P. AlphaGo moment for model architecture discovery. arXiv:2507.18074, 2025
-
[4]
DreamCoder: bootstrapping inductive program synthesis with wake-sleep library learning
Ellis, K., Wong, C., Nye, M., Sablé-Meyer, M., Morales, L., Hewitt, L., Cary, L., Solar-Lezama, A., Tenenbaum, J. DreamCoder: bootstrapping inductive program synthesis with wake-sleep library learning. In PLDI, 2021
2021
-
[5]
R., Saiki, B., Anderson, A., Schulz, A., Grossman, D., Tatlock, Z
Nandi, C., Willsey, M., Zhu, A., Wang, Y. R., Saiki, B., Anderson, A., Schulz, A., Grossman, D., Tatlock, Z. Rewrite rule inference using equality saturation. In OOPSLA, 2021
2021
-
[6]
Learning programs by learning from failures
Cropper, A., Morel, R. Learning programs by learning from failures. In IJCAI, 2021
2021
-
[7]
The mathlib Community. The Lean mathematical library. arXiv:1910.09336, 2020
- [8]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.