ArtSplat: Feed-Forward Articulated 3D Gaussian Splatting from Sparse Multi-State Uncalibrated Views
Pith reviewed 2026-06-30 14:24 UTC · model grok-4.3
The pith
A single forward pass reconstructs both 3D Gaussian geometry and joint parameters of articulated objects from sparse uncalibrated multi-state views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ArtSplat is a feed-forward network that ingests sparse multi-view images captured at multiple articulation states and directly outputs 3D Gaussian primitives together with the object's joint parameters. It solves the joint geometry-and-articulation inference task by representing articulation via a per-pixel joint map and by applying a Cross-State Attention mechanism that uses learned state tokens to model discrete motion between the input states, all without per-object optimization or strong external priors.
What carries the argument
The per-pixel joint map representation together with the Cross-State Attention mechanism that employs state tokens to capture discrete motion across input states.
If this is right
- Both geometry and joint parameters are recovered jointly inside a single network pass instead of separate optimization stages.
- The same architecture handles both single-joint and multi-joint objects without requiring the number of joints to be known in advance.
- Inference becomes more than 400 times faster than optimization-based baselines while remaining competitive in geometry and joint accuracy.
- Reconstruction no longer depends on dense views, depth maps, or predefined joint types.
Where Pith is reading between the lines
- The feed-forward design could be inserted into video pipelines to track articulated objects across continuous motion sequences.
- If the joint-map representation generalizes, similar per-pixel structure tokens might help other inverse-graphics tasks that must infer hidden parameters from images.
- Real-time robotics applications could acquire movable-object models from a few casual phone photos taken while the object is moved by hand.
- Extending the state-token mechanism to handle more than the tested number of discrete states might reduce errors on highly articulated objects.
Load-bearing premise
That a per-pixel joint map plus cross-state attention suffices to resolve the ambiguities of simultaneous geometry and articulation recovery from sparse uncalibrated multi-state views.
What would settle it
Running the model on a set of objects whose joint types or counts lie outside the PartNet-Mobility single- and multi-joint configurations used in training and checking whether the predicted joint parameters produce geometrically inconsistent splats across states.
Figures


read the original abstract
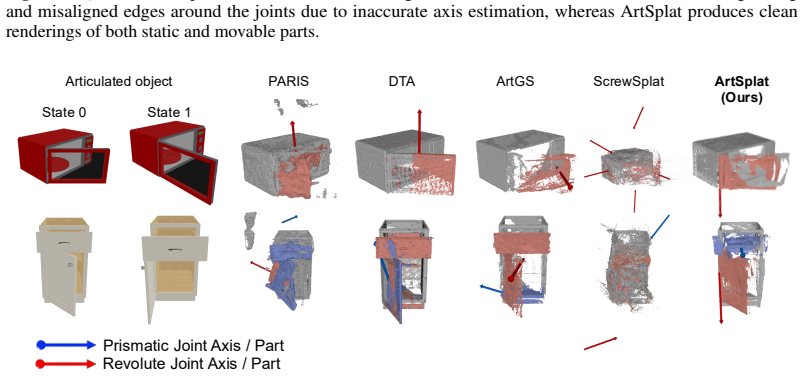
Articulated object reconstruction from sparse-view images is an ill-posed problem that requires simultaneous inference of geometry and underlying articulation structure. Existing methods for articulated object reconstruction based on NeRF and 3D Gaussian Splatting (3DGS) typically rely on dense views or strong priors (e.g., depth maps, joint types, predefined number of joints) and require costly per-object optimization. In this paper, we propose ArtSplat, the first feed-forward framework for articulated 3D Gaussian Splatting. It reconstructs both geometry and joint parameters from sparse multi-view images across multiple articulation states in a single forward pass. To address the challenges of single-pass articulated reconstruction, we introduce a per-pixel joint map representation that enables the integration of joint parameter estimation into the feed-forward pipeline. We further propose a Cross-State Attention (CSA) mechanism with state tokens, which effectively captures discrete motion across input states. Experiments on 68 articulated objects from PartNet-Mobility, including both single- and multi-joint configurations, demonstrate that ArtSplat achieves competitive performance in both geometry and joint estimation, while being over 400 times faster than baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ArtSplat, the first feed-forward framework for articulated 3D Gaussian Splatting. It reconstructs both geometry and joint parameters from sparse multi-view images across multiple articulation states in a single forward pass. The method introduces a per-pixel joint map representation and a Cross-State Attention (CSA) mechanism with state tokens to handle the ill-posed problem of simultaneous geometry and articulation inference. Experiments on 68 articulated objects from PartNet-Mobility (single- and multi-joint) report competitive performance in geometry and joint estimation while being over 400 times faster than baselines.
Significance. If the results hold, this would represent a meaningful advance by moving articulated 3DGS reconstruction from per-object optimization to feed-forward inference, addressing a key scalability bottleneck in prior NeRF/3DGS-based articulated methods. The per-pixel joint map and CSA approach could enable practical use in settings requiring rapid reconstruction from limited uncalibrated multi-state views.
major comments (2)
- Abstract and method description: the central claim that the per-pixel joint map together with CSA using state tokens resolves the ill-posed simultaneous geometry and articulation inference from sparse uncalibrated multi-state views cannot be evaluated, as no equations, network architecture diagrams, loss formulations, or training details are provided to show how joint parameters are regressed or how CSA integrates discrete motion across states.
- Experiments section: the claims of 'competitive performance' and '>400 times faster' on 68 PartNet-Mobility objects lack supporting quantitative tables, metrics (e.g., PSNR, Chamfer distance, joint angle error), baselines, error bars, or ablation studies, making it impossible to verify whether the reported results actually support the feed-forward advantage or the handling of single- vs. multi-joint cases.
Simulated Author's Rebuttal
We thank the referee for their review. We address the two major comments below. Both comments correctly identify that the provided manuscript text consists only of the abstract and lacks the requested technical details and results; we will revise the manuscript to incorporate them.
read point-by-point responses
-
Referee: [—] Abstract and method description: the central claim that the per-pixel joint map together with CSA using state tokens resolves the ill-posed simultaneous geometry and articulation inference from sparse uncalibrated multi-state views cannot be evaluated, as no equations, network architecture diagrams, loss formulations, or training details are provided to show how joint parameters are regressed or how CSA integrates discrete motion across states.
Authors: The referee is correct that the abstract alone does not contain equations, diagrams, loss terms, or training details. We will expand the Methods section in the revised manuscript to include: (1) the per-pixel joint map formulation and regression head, (2) the CSA mechanism with state tokens and cross-state attention equations, (3) a network architecture diagram, (4) the full loss formulation combining reconstruction, joint, and regularization terms, and (5) training hyperparameters and data preprocessing details. revision: yes
-
Referee: [—] Experiments section: the claims of 'competitive performance' and '>400 times faster' on 68 PartNet-Mobility objects lack supporting quantitative tables, metrics (e.g., PSNR, Chamfer distance, joint angle error), baselines, error bars, or ablation studies, making it impossible to verify whether the reported results actually support the feed-forward advantage or the handling of single- vs. multi-joint cases.
Authors: The referee is correct that the abstract provides no quantitative tables or metrics. We will add a dedicated Experiments section containing: Table 1 reporting PSNR/SSIM/LPIPS and Chamfer distance for geometry reconstruction, Table 2 reporting joint angle and axis errors for single- and multi-joint objects, direct comparisons against optimization-based baselines with runtime measurements confirming the >400x speedup, error bars from repeated runs, and ablation studies isolating the contribution of the joint map and CSA components. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and provided context describe a proposed feed-forward architecture (per-pixel joint map + Cross-State Attention with state tokens) for articulated 3DGS reconstruction, presented as an empirical engineering contribution evaluated on PartNet-Mobility. No equations, derivation chains, fitted-parameter predictions, or self-citation load-bearing steps are visible in the given material. The method is introduced as a new representation and mechanism rather than derived from prior results by construction, so the central claims remain independent of any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. J. Campello, D. Moulavi, and J. Sander. Density-Based Clustering Based on Hierarchical Density Estimates. InProceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), 2013
2013
-
[2]
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, et al. Shapenet: An information-rich 3d model repository.arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
Charatan, S
D. Charatan, S. L. Li, A. Tagliasacchi, and V . Sitzmann. pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[4]
X. Chen, Y . Chen, Y . Xiu, A. Geiger, and A. Chen. Easi3R: Estimating Disentangled Motion from DUSt3R Without Training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[5]
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai. MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[6]
J. Guo, Y . Xin, G. Liu, K. Xu, L. Liu, and R. Hu. ArticulatedGS: Self-supervised Digital Twin Modeling of Articulated Objects using 3D Gaussian Splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[7]
Hartley and A
R. Hartley and A. Zisserman.Multiple View Geometry in Computer Vision. Cambridge university press, 2003
2003
-
[8]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. LoRA: Low-Rank Adaptation of Large Language Models. InProceedings of the International Conference on Learning Representations (ICLR), 2022
2022
-
[9]
Huang, Z
B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao. 2D Gaussian Splatting for Geometrically Accurate Radiance Fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024
2024
-
[10]
P. J. Huber. Robust Estimation of a Location Parameter.The Annals of Mathematical Statistics, 35(1):73 – 101, 1964
1964
-
[11]
Jiang, Y
L. Jiang, Y . Mao, L. Xu, T. Lu, K. Ren, Y . Jin, X. Xu, M. Yu, J. Pang, F. Zhao, et al. AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
2025
-
[12]
Jiang, C.-C
Z. Jiang, C.-C. Hsu, and Y . Zhu. Ditto: Building Digital Twins of Articulated Objects from Interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[13]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[14]
S. Kim, J. Ha, Y . H. Kim, Y . Lee, and F. C. Park. ScrewSplat: An End-to-End Method for Articulated Object Recognition. InProceedings of the Conference on Robot Learning (CoRL), 2025
2025
-
[15]
Leroy, Y
V . Leroy, Y . Cabon, and J. Revaud. Grounding Image Matching in 3D with MASt3R. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[16]
Z. Li, C. Zhang, Z. Li, H. Howard-Jenkins, Z. Lv, C. Geng, J. Wu, R. Newcombe, J. Engel, and Z. Dong. ART: Articulated Reconstruction Transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[17]
S. Lin, J. Fang, M. Z. Irshad, V . C. Guizilini, R. A. Ambrus, G. Shakhnarovich, and M. R. Walter. SplArt: Articulation Estimation and Part-Level Reconstruction with 3D Gaussian Splatting. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 10
2025
-
[18]
J. Liu, A. Mahdavi-Amiri, and M. Savva. PARIS: Part-level Reconstruction and Motion Analysis for Articulated Objects. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[19]
Y . Liu, B. Jia, R. Lu, J. Ni, S.-C. Zhu, and S. Huang. ArtGS: Building Interactable Replicas of Complex Articulated Objects via Gaussian Splatting. InProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[20]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[21]
K. Mo, S. Zhu, A. X. Chang, L. Yi, S. Tripathi, L. J. Guibas, and H. Su. PartNet: A large-scale benchmark for fine-grained and hierarchical part-level 3D object understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[22]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al. DINOv2: Learning Robust Visual Features without Supervision.arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. FiLM: Visual Reasoning with a General Conditioning Layer. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2018
2018
-
[24]
Ranftl, A
R. Ranftl, A. Bochkovskiy, and V . Koltun. Vision Transformers for Dense Prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[25]
L. I. Rudin, S. Osher, and E. Fatemi. Nonlinear total variation based noise removal algorithms.Physica D: nonlinear phenomena, 60(1-4):259–268, 1992
1992
-
[26]
L. Shen, S. Zhang, H. Li, P. Yang, Z. Huang, Z. Zhang, and H. Zhao. GaussianArt: Unified Modeling of Geometry and Motion for Articulated Objects. InProceedings of the International Conference on 3D Vision (3DV), 2025
2025
-
[27]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
B. Smart, C. Zheng, I. Laina, and V . A. Prisacariu. Splatt3R: Zero-shot Gaussian Splatting from Uncali- brated Image Pairs.arXiv:2408.13912, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Tseng, H.-J
W.-C. Tseng, H.-J. Liao, L. Yen-Chen, and M. Sun. CLA-NeRF: Category-Level Articulated Neural Radiance Field. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2022
2022
-
[29]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. VGGT: Visual Geometry Grounded Transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[30]
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa. Continuous 3D Perception Model with Persistent State. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[31]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. DUSt3R: Geometric 3D Vision Made Easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[32]
Y . Weng, B. Wen, J. Tremblay, V . Blukis, D. Fox, L. Guibas, and S. Birchfield. Neural Implicit Repre- sentation for Building Digital Twins of Unknown Articulated Objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[33]
D. Wu, L. Liu, Z. Linli, A. Huang, L. Song, Q. Yu, Q. Wu, and C. Lu. REArtGS: Reconstructing and Generating Articulated Objects via 3D Gaussian Splatting with Geometric and Motion Constraints. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[34]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su. SAPIEN: A simulated part-based interactive environment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[35]
H. Xu, S. Peng, F. Wang, H. Blum, D. Barath, A. Geiger, and M. Pollefeys. DepthSplat: Connecting Gaussian Splatting and Depth. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[36]
J. Yang, A. Sax, K. J. Liang, M. Henaff, H. Tang, A. Cao, J. Chai, F. Meier, and M. Feiszli. Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 11
2025
-
[37]
B. Ye, S. Liu, H. Xu, X. Li, M. Pollefeys, M.-H. Yang, and S. Peng. No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images. InProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[38]
T. Yu, V . Shah, M. Wahed, Y . Shen, K. A. Nguyen, and I. Lourentzou. Part2GS: Part-aware Modeling of Articulated Objects using 3D Gaussian Splatting.arXiv:2506.17212, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
S. Yuan, R. Shi, X. Wei, X. Zhang, H. Su, and M. Liu. LARM: A Large Articulated Object Reconstruction Model. InProceedings of the SIGGRAPH Asia Conference Papers (SIGGRAPH Asia), 2025
2025
-
[40]
Zhang, C
J. Zhang, C. Herrmann, J. Hur, V . Jampani, T. Darrell, F. Cole, D. Sun, and M.-H. Yang. MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion. InProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[41]
Zhang, J
S. Zhang, J. Wang, Y . Xu, N. Xue, C. Rupprecht, X. Zhou, Y . Shen, and G. Wetzstein. FLARE: Feed- forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 12 Appendix A Training data details A.1 Multi-view rendering For each trainin...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.