JT-SAFE-V2: Safety-by-Design Foundation Model with World-Context Data
Pith reviewed 2026-06-30 13:42 UTC · model grok-4.3
The pith
JT-Safe-V2 demonstrates that safety-by-design training with world-context data can produce a foundation model that leads on both general intelligence and safety benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
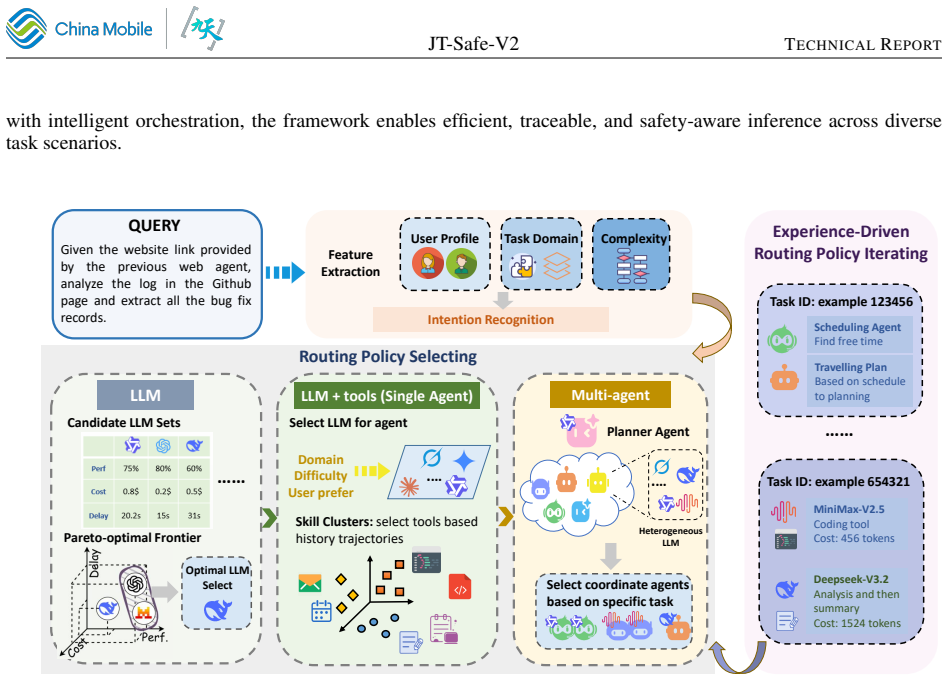
JT-Safe-V2 extends prior work by jointly optimizing general capabilities and safety through contextual world knowledge in pre-training, high-certainty procedures, and post-training safety strengthening for agentic use. Evaluations show it leads benchmarks in both areas. Safe-MoMA then allows efficient, traceable inference by deploying multiple models and agents together, cutting costs over 30 percent versus the largest single model.
What carries the argument
Safe-MoMA, a framework that orchestrates multiple models and agents for traceable and efficient inference on the safety-enhanced JT-Safe-V2 base model.
If this is right
- Enterprises gain access to agentic capabilities with built-in safety at reduced inference cost.
- The public release of the 35B checkpoint enables community research on safety-by-design approaches.
- The mixture approach achieves comparable performance to the largest standalone model at lower expense.
- Joint optimization avoids visible trade-offs on the evaluated general and safety tasks.
Where Pith is reading between the lines
- The same data enrichment strategy could be applied to other foundation models to test whether safety gains generalize.
- Additional benchmarks could reveal if safety holds when general intelligence is stressed in novel ways.
- Cost savings from Safe-MoMA may compound in large-scale deployments beyond the reported figures.
- The approach points toward safety becoming a core training objective rather than an add-on.
Load-bearing premise
The safety strengthening post-training mechanisms and world-context data enrichment do not trade off against general intelligence in ways that would be visible only on benchmarks not reported in the abstract.
What would settle it
Running JT-Safe-V2 against a comparable non-safety model on a wide range of general intelligence tasks not included in the paper's evaluations and finding lower scores would falsify the no-tradeoff claim.
Figures



read the original abstract
We introduce JT-Safe-V2, a large language model designed to advance the safety and trustworthiness of foundation models, extending our previous JT-Safe model toward a more comprehensive safety-by-design paradigm. JT-Safe-V2 emphasizes the joint optimization of general intelligence and safety-by-design through several key innovations: enriching pre-training data with contextual world knowledge, high-certainty pre-training procedures, and safety strengthening post-training mechanisms for enterprise-oriented agentic capabilities. Building on these safety-enhanced foundation models, we propose Safe-MoMA (Safe Mixture of Models and Agents), a framework that enables traceable and efficient inference through the orchestrated deployment of multiple models and agents. Extensive evaluations demonstrate that JT-Safe-V2 achieves state-of-the-art performance across both general intelligence and safety benchmarks. Moreover, Safe-MoMA reduces inference costs by more than 30\% compared to using the largest standalone model baseline while maintaining comparable performance. To facilitate future research on safety-by-design foundation models, we publicly release the post-trained JT-Safe-V2-35B model checkpoint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JT-Safe-V2, an extension of prior JT-Safe work, as a safety-by-design foundation model that jointly optimizes general intelligence and safety via world-context data enrichment in pre-training, high-certainty pre-training procedures, and safety strengthening post-training for agentic use. It further proposes Safe-MoMA, a mixture-of-models-and-agents framework for traceable, cost-efficient inference. The manuscript claims state-of-the-art results on both general-intelligence and safety benchmarks, reports that Safe-MoMA achieves >30% inference-cost reduction versus the largest standalone baseline while preserving comparable performance, and releases the post-trained JT-Safe-V2-35B checkpoint.
Significance. If the joint-optimization claim and the cost-reduction result are substantiated with complete, reproducible evaluations, the work would contribute a concrete example of safety-by-design scaling and an inference orchestration method that could reduce deployment costs for enterprise agents. The public release of the 35B checkpoint is a positive step for reproducibility.
major comments (3)
- [Evaluation section] Evaluation section (and abstract): the SOTA claim on general-intelligence benchmarks is stated without reported numerical scores, baselines, standard deviations, or the precise benchmark suite; this prevents verification that safety post-training and world-context enrichment produce no capability degradation, directly undermining the central joint-optimization premise.
- [Safe-MoMA framework] Safe-MoMA description and results: the >30% cost-reduction figure is given without an explicit definition of the cost metric (tokens, latency, or FLOPs), the exact model sizes in the mixture, or an ablation isolating the contribution of the safety mechanisms versus the mixture architecture; these omissions make the efficiency claim non-reproducible and load-bearing for the practical contribution.
- [Ablation / Experimental design] No ablation study is presented that isolates the effect of the safety-strengthening post-training on the general-intelligence benchmarks; without such controls it is impossible to confirm that the reported SOTA performance is not achieved only on a narrow, unreported subset of tasks.
minor comments (2)
- [Abstract] The abstract asserts 'state-of-the-art performance' without citing the specific prior models or papers being surpassed; add explicit references and scores.
- [Safe-MoMA] Notation for the mixture orchestration in Safe-MoMA is introduced without a clear diagram or pseudocode; a figure or algorithm box would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to enhance reproducibility and substantiate the central claims.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): the SOTA claim on general-intelligence benchmarks is stated without reported numerical scores, baselines, standard deviations, or the precise benchmark suite; this prevents verification that safety post-training and world-context enrichment produce no capability degradation, directly undermining the central joint-optimization premise.
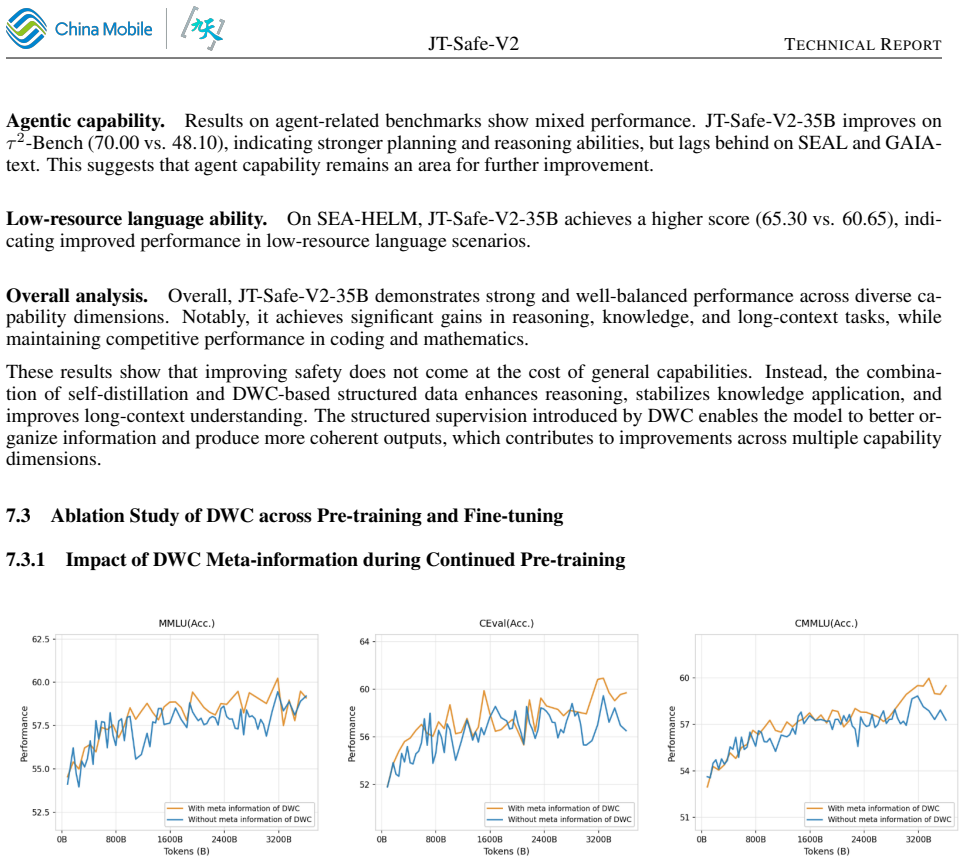
Authors: We agree that the current version does not present the full numerical results, baselines, or standard deviations needed to verify the joint-optimization claim. In the revised manuscript we will add a detailed evaluation table reporting exact scores for JT-Safe-V2-35B and all baselines on the complete general-intelligence benchmark suite (MMLU, GSM8K, HumanEval, BBH, etc.), including standard deviations across runs. This will allow direct confirmation that safety post-training and world-context enrichment incur no capability degradation. revision: yes
-
Referee: [Safe-MoMA framework] Safe-MoMA description and results: the >30% cost-reduction figure is given without an explicit definition of the cost metric (tokens, latency, or FLOPs), the exact model sizes in the mixture, or an ablation isolating the contribution of the safety mechanisms versus the mixture architecture; these omissions make the efficiency claim non-reproducible and load-bearing for the practical contribution.
Authors: We acknowledge that the cost metric, model sizes, and isolating ablation are insufficiently specified. The revision will explicitly define the cost metric as total tokens processed during inference, list the precise model sizes in the Safe-MoMA mixture (35B primary plus auxiliary 7B/13B models), and add an ablation comparing the full framework against a non-safety-aware mixture variant. These additions will render the >30% reduction claim fully reproducible. revision: yes
-
Referee: [Ablation / Experimental design] No ablation study is presented that isolates the effect of the safety-strengthening post-training on the general-intelligence benchmarks; without such controls it is impossible to confirm that the reported SOTA performance is not achieved only on a narrow, unreported subset of tasks.
Authors: We accept that an explicit ablation isolating safety post-training is required. The revised manuscript will include a new ablation subsection comparing the base pre-trained JT-Safe-V2 checkpoint against the safety-strengthened post-trained version on the full set of general-intelligence benchmarks, demonstrating that SOTA performance holds across the broad task distribution rather than a narrow subset. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The manuscript presents JT-Safe-V2 as an empirical engineering contribution: it describes data enrichment, pre-training procedures, post-training mechanisms, and the Safe-MoMA inference framework, then reports benchmark results. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction appear in the provided text. The SOTA and cost-reduction statements rest on external evaluations rather than any deductive step that is definitionally equivalent to its premises. Self-reference to the prior JT-Safe model is present but is not invoked as a uniqueness theorem or load-bearing justification for the new performance numbers. Per the hard rules, absence of quotable reductions that collapse the result to its inputs warrants score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team Google. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
OpenAI. Gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Survey of hallucination in natural language generation.ACM Comput
doi:10.1145/3571730. Junlan Feng, Fanyu Meng, Chong Long, Pengyu Cong, Duqing Wang, Yan Zheng, Yuyao Zhang, Xuanchang Gao, Ye Yuan, Yunfei Ma, Zhijie Ren, Fan Yang, Na Wu, Di Jin, and Chao Deng. Jt-safe: Intrinsically enhancing the safety and trustworthiness of llms,
-
[7]
Towards understanding the safety boundaries of deepseek models: Evaluation and findings
Zonghao Ying, Guangyi Zheng, Yongxin Huang, Deyue Zhang, Wenxin Zhang, Quanchen Zou, Aishan Liu, Xianglong Liu, and Dacheng Tao. Towards understanding the safety boundaries of deepseek models: Evaluation and findings. arXiv preprint arXiv:2503.15092,
-
[8]
Guohai Xu, Jiayi Liu, Ming Yan, Haotian Xu, Jinghui Si, Zhuoran Zhou, Peng Yi, Xing Gao, Jitao Sang, Rong Zhang, et al. Cvalues: Measuring the values of chinese large language models from safety to responsibility.arXiv preprint arXiv:2307.09705,
-
[9]
Flames: Benchmarking value alignment of llms in chinese
Kexin Huang, Xiangyang Liu, Qianyu Guo, Tianxiang Sun, Jiawei Sun, Yaru Wang, Zeyang Zhou, Yixu Wang, Yan Teng, Xipeng Qiu, et al. Flames: Benchmarking value alignment of llms in chinese. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),...
2024
-
[10]
Sweeval: Do llms really swear? a safety benchmark for testing limits for enterprise use
Hitesh Laxmichand Patel, Amit Agarwal, Arion Das, Bhargava Kumar, Srikant Panda, Priyaranjan Pattnayak, Taki Hasan Rafi, Tejaswini Kumar, and Dong-Kyu Chae. Sweeval: Do llms really swear? a safety benchmark for testing limits for enterprise use. InProceedings of the 2025 Conference of the Nations of the Americas Chap- ter of the Association for Computatio...
2025
-
[11]
Air-bench: Benchmarking large audio-language models via generative comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, et al. Air-bench: Benchmarking large audio-language models via generative comprehension. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1979–1998,
1979
-
[12]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Safety assessment of chinese large language models.arXiv preprint arXiv:2304.10436,
Hao Sun, Zhexin Zhang, Jiawen Deng, Jiale Cheng, and Minlie Huang. Safety assessment of chinese large language models.arXiv preprint arXiv:2304.10436,
-
[14]
18 JT-Safe-V2TECHNICALREPORT Mi Zhang, Xudong Pan, and Min Yang. Jade: A linguistics-based safety evaluation platform for large language models.arXiv preprint arXiv:2311.00286, 2023a. Bertie Vidgen, Nino Scherrer, Hannah Rose Kirk, Rebecca Qian, Anand Kannappan, Scott A Hale, and Paul Röttger. Simplesafetytests: a test suite for identifying critical safet...
-
[15]
do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1671–1685,
2024
-
[16]
Do-not-answer: A dataset for evaluating safeguards in llms.arXiv preprint arXiv:2308.13387,
Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. Do-not-answer: A dataset for evaluating safeguards in llms.arXiv preprint arXiv:2308.13387,
-
[17]
Salad-bench: A hierarchical and comprehensive safety benchmark for large language models
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. Salad-bench: A hierarchical and comprehensive safety benchmark for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3923–3954,
2024
-
[18]
Bbq: A hand-built bias benchmark for question answering
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel Bowman. Bbq: A hand-built bias benchmark for question answering. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2086–2105,
2022
-
[19]
Jailbreak distillation: Renewable safety benchmarking.arXiv preprint arXiv:2505.22037,
Jingyu Zhang, Ahmed Elgohary, Xiawei Wang, ASM Iftekhar, Ahmed Magooda, Benjamin Van Durme, Daniel Khashabi, and Kyle Jackson. Jailbreak distillation: Renewable safety benchmarking.arXiv preprint arXiv:2505.22037,
-
[20]
Zhenhong Zhou, Shilinlu Yan, Chuanpu Liu, Qiankun Li, Kun Wang, and Zhigang Zeng. Cssbench: Evaluating the safety of lightweight llms against chinese-specific adversarial patterns.arXiv preprint arXiv:2601.00588,
-
[21]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Ed- wards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I Wang. Cruxeval: A benchmark for code reasoning, understanding and execution.arXiv preprint arXiv:2401.03065, 2024a. Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Mo...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
19 JT-Safe-V2TECHNICALREPORT Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Language Models are Multilingual Chain-of-Thought Reasoners
Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush V osoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, et al. Language models are multilingual chain-of-thought reasoners.arXiv preprint arXiv:2210.03057,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark
Hongwei Liu, Zilong Zheng, Yuxuan Qiao, Haodong Duan, Zhiwei Fei, Fengzhe Zhou, Wenwei Zhang, Songyang Zhang, Dahua Lin, and Kai Chen. Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark. InFindings of the Association for Computational Linguistics ACL 2024, pages 6884–6915, 2024b. Kiran V odrahall...
2024
-
[27]
URLhttps://arxiv.org/abs/2409.12640. Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?ArXiv,
-
[28]
RULER: What's the Real Context Size of Your Long-Context Language Models?
URLhttps: //arxiv.org/abs/2404.06654. Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-eval: Instituting standardized evaluation for long context language models.ArXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
URLhttps://arxiv. org/abs/2307.11088. Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: reasoning about physical com- monsense in natural language.CoRR, abs/1911.11641,
-
[30]
PIQA: Reasoning about Physical Commonsense in Natural Language
URLhttp://arxiv.org/abs/1911.11641. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?CoRR, abs/1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[31]
HellaSwag: Can a Machine Really Finish Your Sentence?
URLhttp://arxiv.org/abs/1905.07830. Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies.CoRR, abs/2101.02235,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[32]
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies, 2021
URLhttps: //arxiv.org/abs/2101.02235. Qin Zhu, Fei Huang, Runyu Peng, Keming Lu, Bowen Yu, Qinyuan Cheng, Xipeng Qiu, Xuanjing Huang, and Junyang Lin. Autologi: Automated generation of logic puzzles for evaluating reasoning abilities of large language models. arXiv preprint arXiv:2502.16906,
-
[33]
Jiajun Shi, Chaoren Wei, Liqun Yang, Zekun Moore Wang, Chenghao Yang, Ge Zhang, Stephen Huang, Tao Peng, Jian Yang, and Zhoufutu Wen. Cryptox: Compositional reasoning evaluation of large language models.arXiv preprint arXiv:2502.07813,
-
[34]
Liwen Zhang, Wei Cai, Zhaowei Liu, Zhi Yang, Wei Dai, Yujie Liao, Qi Qin, Yifei Li, Xingxian Liu, Zhiqiang Liu, et al. Fineval: A chinese financial domain knowledge evaluation benchmark for large language models.arXiv preprint arXiv:2308.09975, 2023b. Zhouhong Gu, Xiaoxuan Zhu, Haoning Ye, Lin Zhang, Jianchen Wang, Yixin Zhu, Sihang Jiang, Zhuozhi Xiong, ...
-
[35]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
URLhttps://arxiv.org/abs/2506.07982. Thinh Pham, Nguyen Nguyen, Pratibha Zunjare, Weiyuan Chen, Yu-Min Tseng, and Tu Vu. Sealqa: Raising the bar for reasoning in search-augmented language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models
URLhttps://arxiv.org/abs/2506.01062. Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants.arXiv preprint arXiv:2311.12983,
work page internal anchor Pith review Pith/arXiv arXiv
- [37]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.