EgoProx: Evaluating MLLMs on Egocentric 3D Proximity Reasoning Across a Cognitive Hierarchy
Pith reviewed 2026-06-30 13:25 UTC · model grok-4.3
The pith
MLLMs contain some spatial knowledge but struggle to leverage it for egocentric 3D proximity reasoning VQA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce EgoProx, a benchmark for egocentric 3D proximity reasoning organized along a cognitive chain covering intention, exploration, exploitation, and chain-of-actions reasoning. Using an agent-based data engine to produce QA pairs, we benchmark MLLMs and find large cross-domain gains from instruction tuning, indicating that current MLLMs contain some spatial knowledge; however, they still struggle to effectively leverage it for spatial reasoning VQA.
What carries the argument
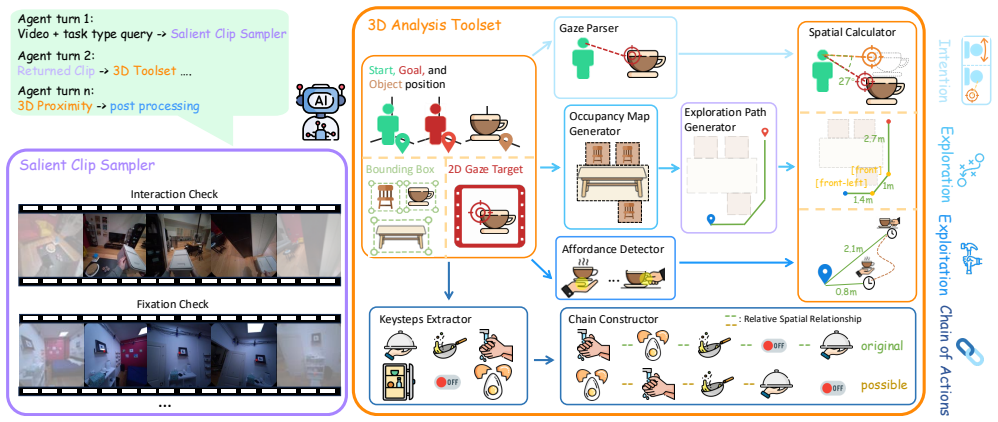
The EgoProx benchmark, which organizes tasks along a cognitive chain covering intention, exploration, exploitation, and chain-of-actions reasoning, generated via an agent-based data engine.
Load-bearing premise
The agent-based data engine produces diverse and consistent QA pairs that accurately test the intended cognitive chain of 3D proximity reasoning without introducing generation artifacts.
What would settle it
Demonstrating that MLLMs achieve near-human performance on the EgoProx tasks without any domain-specific tuning, or that human raters disagree significantly with the generated QA pairs on what the correct answers should be.
Figures







read the original abstract
Humans constantly reason about 3D proximity, the relations between their body and surrounding objects, to guide perception and action in daily life. Whether multimodal large language models (MLLMs) can perform such embodied 3D reasoning remains unclear. To this end, we introduce EgoProx, a benchmark for egocentric 3D proximity reasoning. We organize our tasks along a cognitive chain, covering intention, exploration, exploitation, and chain-of-actions reasoning. We also design an agent based data engine that produces diverse and consistent QA pairs at scale. We benchmark prevailing MLLMs on EgoProx and conduct additional analyses with dataset specific and task specific instruction tuning. We observe large cross-domain gains, indicating that current MLLMs contain some spatial knowledge; however, they still struggle to effectively leverage it for spatial reasoning VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoProx, a benchmark for evaluating MLLMs on egocentric 3D proximity reasoning. Tasks are organized along a cognitive hierarchy (intention, exploration, exploitation, chain-of-actions). An agent-based data engine generates QA pairs at scale. Benchmarking of prevailing MLLMs plus instruction-tuning experiments show large cross-domain gains, interpreted as evidence that models possess some spatial knowledge yet struggle to leverage it for spatial reasoning VQA.
Significance. If the benchmark tasks faithfully isolate the intended cognitive chain without generation artifacts, the work would provide a structured evaluation framework for embodied spatial reasoning in MLLMs and highlight a knowledge-application gap. The agent-based engine, if shown to be reliable, would be a scalable contribution for future egocentric benchmarks.
major comments (2)
- [§3.2] §3.2 (Agent-based Data Engine): The central claim that observed model failures reflect inability to leverage spatial knowledge (rather than data artifacts) depends on the engine producing QA pairs that accurately test the cognitive hierarchy. No validation steps—human consistency checks, 3D geometry verification against ground-truth meshes, or controls for LLM-induced biases in the engine—are reported, leaving the interpretation of results load-bearing on an unverified assumption.
- [§4] §4 (Experiments and Analyses): The reported cross-domain gains from instruction tuning are presented as evidence of latent spatial knowledge, but without ablations that isolate whether gains arise from proximity-specific reasoning versus general VQA adaptation, the interpretation that models 'contain some spatial knowledge' remains under-supported by the experimental design.
minor comments (2)
- [Abstract] Abstract: 'agent based' should be hyphenated as 'agent-based' for consistency with later usage.
- [§3.1] Notation: The cognitive chain stages (intention → exploration → exploitation → chain-of-actions) are introduced without an explicit diagram or table summarizing the progression and question templates per stage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments regarding the validation of the agent-based data engine and the interpretation of the instruction-tuning experiments. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Agent-based Data Engine): The central claim that observed model failures reflect inability to leverage spatial knowledge (rather than data artifacts) depends on the engine producing QA pairs that accurately test the cognitive hierarchy. No validation steps—human consistency checks, 3D geometry verification against ground-truth meshes, or controls for LLM-induced biases in the engine—are reported, leaving the interpretation of results load-bearing on an unverified assumption.
Authors: We agree that explicit validation of the data engine is necessary to support the interpretation that model failures stem from limitations in leveraging spatial knowledge rather than generation artifacts. The engine applies deterministic geometric rules derived directly from the 3D meshes to compute proximity relations for the cognitive hierarchy tasks. In the revised manuscript, we will add a validation subsection in §3.2 reporting: human consistency checks on a sampled subset of QA pairs, direct comparison of generated 3D relations against ground-truth mesh annotations, and analysis of any LLM components used in question phrasing to control for bias. These additions will be included in the next version. revision: yes
-
Referee: [§4] §4 (Experiments and Analyses): The reported cross-domain gains from instruction tuning are presented as evidence of latent spatial knowledge, but without ablations that isolate whether gains arise from proximity-specific reasoning versus general VQA adaptation, the interpretation that models 'contain some spatial knowledge' remains under-supported by the experimental design.
Authors: The instruction tuning is performed specifically on EgoProx's proximity reasoning tasks (intention, exploration, exploitation, and chain-of-actions) before measuring gains on cross-domain spatial VQA benchmarks. This design aims to activate latent spatial capabilities through targeted exposure rather than generic adaptation. We acknowledge that dedicated ablations against general VQA tuning would provide stronger isolation of the effect. In the revised version, we will add such an ablation comparing EgoProx-specific tuning to tuning on a general VQA dataset, with results reported in §4 to better support the interpretation. revision: yes
Circularity Check
No circularity: benchmark construction is independent of evaluated claims
full rationale
The paper presents an empirical benchmark (EgoProx) organized along a cognitive hierarchy and generated via an agent-based data engine. No equations, parameter fitting, or derivations appear in the provided text. The central observation—that MLLMs possess some spatial knowledge yet struggle on the benchmark—is an empirical result from model evaluation, not a quantity defined in terms of the benchmark itself or reduced via self-citation. The data engine is a generation tool whose validity is external to the model-performance claim; no step equates a prediction to its own input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human 3D proximity reasoning can be decomposed into a cognitive chain of intention, exploration, exploitation, and chain-of-actions.
Reference graph
Works this paper leans on
-
[1]
Gaze augmentation in egocentric video improves intention prediction
Deepak Akkil, Poika Isokoski, Jani Kangas, Jussi Rantala, and Antti Oulasvirta. Gaze augmentation in egocentric video improves intention prediction. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems (CHI), pages 5181–5191, 2016. 2
2016
-
[2]
Flamingo: A visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Paul Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katie Millican, Malcolm Reynolds, et al. Flamingo: A visual language model for few-shot learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. 2, 3
2022
-
[3]
Scanqa: 3d question answering for spatial scene understanding.2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 19107– 19117, 2021
Daich Azuma, Taiki Miyanishi, Shuhei Kurita, and Mo- toaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding.2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 19107– 19117, 2021. 2, 4
2022
-
[4]
Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023. 2, 3
2023
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Where did i leave my keys? - episodic-memory-based question answering on ego- centric videos
Leonard B ¨armann and Alex Waibel. Where did i leave my keys? - episodic-memory-based question answering on ego- centric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Work- shops, pages 1560–1568, 2022. 4
2022
-
[7]
Navigating cognition: Spatial codes for human thinking.Science, 362(6415):eaat6766, 2018
Jacob LS Bellmund, Peter G ¨ardenfors, Edvard I Moser, and Christian F Doeller. Navigating cognition: Spatial codes for human thinking.Science, 362(6415):eaat6766, 2018. 2
2018
-
[8]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14455–14465,
-
[9]
Ll3da: Visual interactive instruction tuning for omni-3d understand- ing, reasoning, and planning, 2023
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understand- ing, reasoning, and planning, 2023. 3
2023
-
[10]
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Xi Chen, Xiao Wang, Soravit Changpinyo, Anthony J Pier- giovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. Pali: A jointly-scaled multilingual language-image model.arXiv preprint arXiv:2209.06794, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Egoplan- bench: Benchmarking multimodal large language models for human-level planning, 2024
Yi Chen, Yuying Ge, Yixiao Ge, Mingyu Ding, Bohao Li, Rui Wang, Ruifeng Xu, Ying Shan, and Xihui Liu. Egoplan- bench: Benchmarking multimodal large language models for human-level planning, 2024. 3, 4
2024
-
[12]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 2, 3
2024
-
[13]
Ex- panding performance boundaries of open-source multimodal models with model, data, and test-time scaling, 2025
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui Wang, Qingyun Li, Yim- ing Ren, Zixuan Chen, Jiapeng Luo, Jiahao Wang, Tan Jiang, Bo Wang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv, Yi Wang, Wenqi Shao, Pei Chu, Zhongying Tu, Tong He, Zhiyong Wu, Huipeng Deng...
2025
-
[14]
Sijie Cheng, Zhicheng Guo, Jingwen Wu, Kechen Fang, Peng Li, Huaping Liu, and Yang Liu. Egothink: Evalu- ating first-person perspective thinking capability of vision- language models.2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 14291– 14302, 2023. 2, 4
2024
-
[15]
Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023. 2
2023
-
[16]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel, David Griffiths, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, et al. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7395–7408, 2025. 3, 16
2025
-
[17]
Gemini: Multimodal foundation models
Google DeepMind. Gemini: Multimodal foundation models. Technical Report, 2024. 2, 3, 6
2024
-
[18]
Egovqa - an egocentric video question answer- ing benchmark dataset
Chenyou Fan. Egovqa - an egocentric video question answer- ing benchmark dataset. In2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 4359–4366, 2019. 4
2019
-
[19]
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wen- han Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning.arXiv preprint arXiv:2403.11401, 2024. 3
-
[20]
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zachary Chavis, Joya Chen, Feng Cheng, Fu- Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Mar ´ıa Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, M...
2024
-
[21]
3d-llm: In- jecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494,
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: In- jecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494,
-
[22]
Groundnlq@ ego4d natural language queries challenge 2023.arXiv preprint arXiv:2306.15255,
Zhijian Hou, Lei Ji, Difei Gao, Wanjun Zhong, Kun Yan, Chao Li, Wing-Kwong Chan, Chong-Wah Ngo, Nan Duan, and Mike Zheng Shou. Groundnlq@ ego4d natural language queries challenge 2023.arXiv preprint arXiv:2306.15255,
-
[23]
Chat-scene: Bridging 3d scene and large language models with object identifiers.Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 2024
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers.Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 2024. 3
2024
-
[24]
An embodied generalist agent in 3d world, 2024
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world, 2024. 3
2024
-
[25]
Understanding dynamic scenes in ego centric 4d point clouds.ArXiv, abs/2508.07251, 2025
Junsheng Huang, Shengyu Hao, Bocheng Hu, and Gaoang Wang. Understanding dynamic scenes in ego centric 4d point clouds.ArXiv, abs/2508.07251, 2025. 3, 4
-
[26]
Language is not all you need: Aligning perception with language mod- els.Advances in Neural Information Processing Systems, 36:72096–72109, 2023
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, et al. Language is not all you need: Aligning perception with language mod- els.Advances in Neural Information Processing Systems, 36:72096–72109, 2023. 2
2023
-
[27]
Building a mind palace: Structuring environment- grounded semantic graphs for effective long video analysis with llms, 2025
Zeyi Huang, Yuyang Ji, Xiaofang Wang, Nikhil Mehta, Tong Xiao, Donghyun Lee, Sigmund Vanvalkenburgh, Shengxin Zha, Bolin Lai, Licheng Yu, Ning Zhang, Yong Jae Lee, and Miao Liu. Building a mind palace: Structuring environment- grounded semantic graphs for effective long video analysis with llms, 2025. 4
2025
-
[28]
Egotaskqa: Understanding human tasks in egocentric videos,
Baoxiong Jia, Ting Lei, Song-Chun Zhu, and Siyuan Huang. Egotaskqa: Understanding human tasks in egocentric videos,
-
[29]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InProceedings of the International Conference on Machine Learning (ICML),
-
[30]
Robert Konrad, Nitish Padmanaban, J. Gabriel Buckmaster, Kevin C. Boyle, and Gordon Wetzstein. Gazegpt: Augment- ing human capabilities using gaze-contingent contextual ai for smart eyewear.arXiv preprint arXiv:2401.17217, 2024. 2, 3
-
[31]
Refego: Referring expression grounding in egocentric videos
Shuhei Kurita et al. Refego: Referring expression grounding in egocentric videos. InICCV, 2023. 3
2023
-
[32]
Lego: L earning ego cen- tric action frame generation via visual instruction tuning
Bolin Lai, Xiaoliang Dai, Lawrence Chen, Guan Pang, James M Rehg, and Miao Liu. Lego: L earning ego cen- tric action frame generation via visual instruction tuning. In European Conference on Computer Vision, pages 135–155. Springer, 2024. 2, 3
2024
-
[33]
Idefics: An open multimodal chatbot
Hugo Laurenc ¸on et al. Idefics: An open multimodal chatbot. Hugging Face, 2023. 2
2023
-
[34]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Blip: Bootstrapped language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven CH Hoi. Blip: Bootstrapped language-image pre-training for unified vision-language understanding and generation. InProceed- ings of the International Conference on Machine Learning (ICML), 2022. 2, 3
2022
-
[36]
Blip-2: Bootstrapped language-image pretraining with frozen image encoders and large language models
Junnan Li, Dongxu Li, Caiming Xiong, and Steven CH Hoi. Blip-2: Bootstrapped language-image pretraining with frozen image encoders and large language models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2, 3
2023
-
[37]
Ost-bench: Evaluating the capabilities of mllms in online spatio-temporal scene understanding
Jingli Lin, Chenming Zhu, Runsen Xu, Xiaohan Mao, Xihui Liu, Tai Wang, and Jiangmiao Pang. Ost-bench: Evaluat- ing the capabilities of mllms in online spatio-temporal scene understanding.ArXiv, abs/2507.07984, 2025. 2, 4, 6
-
[38]
Egovlp: Egocentric video-language pre- training
Kevin Lin et al. Egovlp: Egocentric video-language pre- training. InNeurIPS, 2022. 2, 3
2022
-
[39]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 2, 3
2023
-
[40]
Minghuang Ma, Haoqi Fan, and Kris M. Kitani. Going deeper into first-person activity recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1894–1903, 2016. 2
1903
-
[41]
Egocentric intention object prediction based on a human-like manner.Egyptian Informatics Journal, 26:100482, 2024
Zongnan Ma, Jingru Men, Fuchun Zhang, and Zhixiong Nan. Egocentric intention object prediction based on a human-like manner.Egyptian Informatics Journal, 26:100482, 2024. 2
2024
-
[42]
Openeqa: Embodied question answering in the era of foun- dation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, 10 Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foun- dation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16488– 16498, 2024. 4
2024
-
[43]
Advances in Neural Information Processing Systems , year=
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding.ArXiv, abs/2308.09126,
-
[44]
So Yeon Min, Devendra Singh Chaplot, Pradeep Ravikumar, Yonatan Bisk, and Ruslan Salakhutdinov. Film: Follow- ing instructions in language with modular methods.arXiv preprint arXiv:2110.07342, 2021. 2, 3
-
[45]
Egocentric vision-based action recog- nition: A survey.Neurocomputing, 495:28–53, 2022
Adri ´an N ´u˜nez-Marcos, Gorka Azkune, and Ignacio Arganda-Carreras. Egocentric vision-based action recog- nition: A survey.Neurocomputing, 495:28–53, 2022. 2
2022
-
[46]
Exo2egodvc: Dense video captioning of ego- centric procedural activities using web instructional videos
Takehiko Ohkawa, Takuma Yagi, Taichi Nishimura, Ryosuke Furuta, Atsushi Hashimoto, Yoshitaka Ushiku, and Yoichi Sato. Exo2egodvc: Dense video captioning of ego- centric procedural activities using web instructional videos. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 8324–8335. IEEE, 2025. 2, 3
2025
-
[47]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Gpt-5, 2025
OpenAI. Gpt-5, 2025. Accessed: 2025-08-09. 6
2025
-
[49]
Aria digital twin: A new benchmark dataset for egocentric 3d machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Pe- ters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20133–20143, 2023. 4, 13, 16
2023
-
[50]
egovlp: Egocentric video un- derstanding with diverse task perspectives
Simone Alberto Peirone, Francesca Pistilli, Antonio Al- liegro, and Giuseppe Averta. egovlp: Egocentric video un- derstanding with diverse task perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18275–18285, 2024. 2
2024
-
[51]
In the eye of mllm: Benchmarking egocentric video intent under- standing with gaze-guided prompting
Taiying Peng, Jiacheng Hua, Miao Liu, and Feng Lu. In the eye of mllm: Benchmarking egocentric video intent under- standing with gaze-guided prompting. InAdvances in Neural Information Processing Systems, 2025. 3, 4
2025
-
[52]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5285–5297, 2023. 2, 3
2023
-
[53]
arXiv preprint arXiv:2501.01428 (2025)
Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. Gpt4scene: Understand 3d scenes from videos with vision-language models.arXiv preprint arXiv:2501.01428, 2024. 3
-
[54]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InProceedings of the International Conference on Machine Learning (ICML), 2021. 2, 3
2021
-
[55]
An empirical analysis on spa- tial reasoning capabilities of large multimodal models
Fatemeh Shiri, Xiao-Yu Guo, Mona Golestan Far, Xin Yu, Reza Haf, and Yuan-Fang Li. An empirical analysis on spa- tial reasoning capabilities of large multimodal models. In Proceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 21440–21455, Miami, Florida, USA, 2024. Association for Computational Linguistics. 2
2024
-
[56]
Alanavlm: A multimodal embodied ai foundation model for egocentric video understanding
Alessandro Suglia, Claudio Greco, Katie Baker, Jose L Part, Ioannis Papaioannou, Arash Eshghi, Ioannis Konstas, and Oliver Lemon. Alanavlm: A multimodal embodied ai foundation model for egocentric video understanding. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 11101–11122, 2024. 2, 3
2024
-
[57]
Visual intention grounding for egocentric assistants, 2025
Pengzhan Sun, Junbin Xiao, Tze Ho Elden Tse, Yicong Li, Arjun Akula, and Angela Yao. Visual intention grounding for egocentric assistants, 2025. 2, 3
2025
-
[58]
Generative multimodal mod- els are in-context learners
Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiy- ing Yu, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative multimodal mod- els are in-context learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14398–14409, 2024. 2
2024
-
[59]
Augmented reality and robotics: A sur- vey and taxonomy for ar-enhanced human-robot interaction and robotic interfaces
Ryo Suzuki, Adnan Karim, Tian Xia, Hooman Hedayati, and Nicolai Marquardt. Augmented reality and robotics: A sur- vey and taxonomy for ar-enhanced human-robot interaction and robotic interfaces. InCHI Conference on Human Factors in Computing Systems, page 1–33. ACM, 2022. 2
2022
-
[60]
GIT: A Generative Image-to-text Transformer for Vision and Language
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. Git: A generative image-to-text transformer for vision and language.arXiv preprint arXiv:2205.14100, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025. 3, 16
2025
-
[62]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024. 2, 3
2024
-
[63]
arXiv preprint arXiv:2312.05269 , year=
Ying Wang, Yanlai Yang, and Mengye Ren. Lifelongmem- ory: Leveraging llms for answering queries in long-form egocentric videos.arXiv preprint arXiv:2312.05269, 2023. 2, 3
-
[64]
Zehan Wang, Haifeng Huang, Yang Zhao, Ziang Zhang, and Zhou Zhao. Chat-3d: Data-efficiently tuning large language model for universal dialogue of 3d scenes.arXiv preprint arXiv:2308.08769, 2023. 3
-
[65]
Deepseek-ocr: Contexts optical compression, 2025
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression, 2025. 2
2025
-
[66]
Chain-of-thought prompting elicits reasoning in large lan- 11 guage models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- 11 guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 6, 7, 13
2022
-
[67]
Assistq: Affordance-centric question-driven task completion for ego- centric assistant
Benita Wong, Joya Chen, You Wu, Stan Weixian Lei, Dongxing Mao, Difei Gao, and Mike Zheng Shou. Assistq: Affordance-centric question-driven task completion for ego- centric assistant. InComputer Vision – ECCV 2022, pages 485–501, Cham, 2022. Springer Nature Switzerland. 4
2022
-
[68]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025. 3, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
St-think: How multimodal large language models reason about 4d worlds from ego-centric videos,
Peiran Wu, Yunze Liu, Chonghan Liu, Miao Liu, and Junx- iao Shen. St-think: How multimodal large language mod- els reason about 4d worlds from ego-centric videos.arXiv preprint arXiv:2503.12542, 2025. 4
-
[70]
Retrieval-augmented egocentric video captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, and Weidi Xie. Retrieval-augmented egocentric video captioning. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13525–13536, 2024. 2, 3
2024
-
[71]
Gupta, Rilyn Han, Fei-Fei Li, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Fei-Fei Li, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10632–10643, 2024. 2, 4, 13, 16
2025
-
[72]
Egolife: Towards egocentric life assistant, 2025
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xi- amengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, Bei Ouyang, Zhengyu Lin, Marco Cominelli, Zhongang Cai, Yuanhan Zhang, Peiyuan Zhang, Fangzhou Hong, Joerg Widmer, Francesco Gringoli, Lei Yang, Bo Li, and Ziwei Liu. Egolife: Towards egocentric life assistant, 2025. 2, 3, 4
2025
-
[73]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, Dahua Lin, Tai Wang, and Jiangmiao Pang. Mmsi-bench: A benchmark for multi-image spatial intelli- gence.ArXiv, abs/2505.23764, 2025. 2, 4, 6, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Mmego: Towards building egocentric multimodal llms for video qa
Hanrong Ye, Haotian Zhang, Erik Daxberger, Lin Chen, Zongyu Lin, Yanghao Li, Bowen Zhang, Haoxuan You, Dan Xu, Zhe Gan, Jiasen Lu, and Yinfei Yang. Mmego: Towards building egocentric multimodal llms for video qa. InIn- ternational Conference on Representation Learning, pages 71705–71723, 2025. 4
2025
-
[76]
mplug- owl2: Revolutionizing multi-modal large language model with modality collaboration
Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, and Fei Huang. mplug- owl2: Revolutionizing multi-modal large language model with modality collaboration. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 13040–13051, 2024. 2
2024
-
[77]
Yuqian Yuan, Ronghao Dang, Long Li, Wentong Li, Dian Jiao, Xin Li, Deli Zhao, Fan Wang, Wenqiao Zhang, Jun Xiao, et al. Eoc-bench: Can mllms identify, recall, and forecast objects in an egocentric world?arXiv preprint arXiv:2506.05287, 2025. 4
-
[78]
How to enable llm with 3d capacity? a survey of spatial reasoning in llm, 2025
Jirong Zha, Yuxuan Fan, Xiao Yang, Chen Gao, and Xinlei Chen. How to enable llm with 3d capacity? a survey of spatial reasoning in llm, 2025. 2
2025
-
[79]
Learning video representations from large language models
Yue Zhao, Ishan Misra, Philipp Kr ¨ahenb¨uhl, and Rohit Gird- har. Learning video representations from large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6586–6597,
-
[80]
Video-3d llm: Learning position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video representation for 3d scene understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8995–9006, 2025. 3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.