APT-Agent: Automated Penetration Testing using Large Language Models
Pith reviewed 2026-06-30 00:08 UTC · model grok-4.3
The pith
APT-Agent uses a rectification module and command memory to let an LLM complete full penetration testing sequences at 84 percent success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
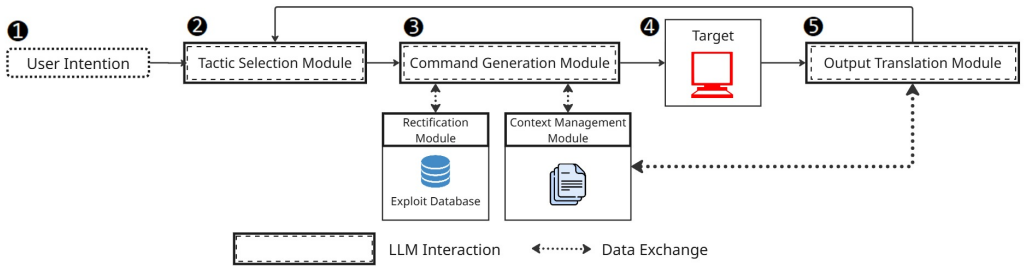
APT-Agent is a fully automated LLM-driven penetration testing framework that systematically orchestrates reconnaissance, exploitation, and exfiltration. It introduces a hybrid rectification module to recover hallucinated commands and a command-specific memory architecture to preserve operational context across multi-step attack sequences, achieving an 84.29 percent end-to-end exploitation success rate on Metasploitable 2 against seven vulnerable services.
What carries the argument
The hybrid rectification module paired with command-specific memory architecture, which corrects invalid LLM outputs and retains attack history for sequential decision making.
If this is right
- Enables more complete automation of reconnaissance through exfiltration phases without constant operator input.
- Produces higher success rates than both script-based and earlier LLM pen-testing tools on the same target services.
- Applies across web, database, and network protocol vulnerabilities in a single framework.
- Lowers the cognitive load on security teams by handling error recovery internally.
Where Pith is reading between the lines
- Similar rectification and memory techniques could transfer to other multi-step security tasks such as vulnerability scanning or incident response.
- Testing the framework on production networks rather than lab images would reveal how well the modules handle real-world noise and defenses.
- The architecture suggests that targeted memory designs may improve LLM reliability in other long-horizon technical domains beyond security.
Load-bearing premise
The rectification module reliably fixes hallucinated commands and the memory system preserves enough context for the LLM to finish multi-step sequences without human fixes.
What would settle it
Measure end-to-end success rates on the same seven services after disabling the rectification module or the command memory and compare against the reported 84.29 percent baseline.
Figures



read the original abstract
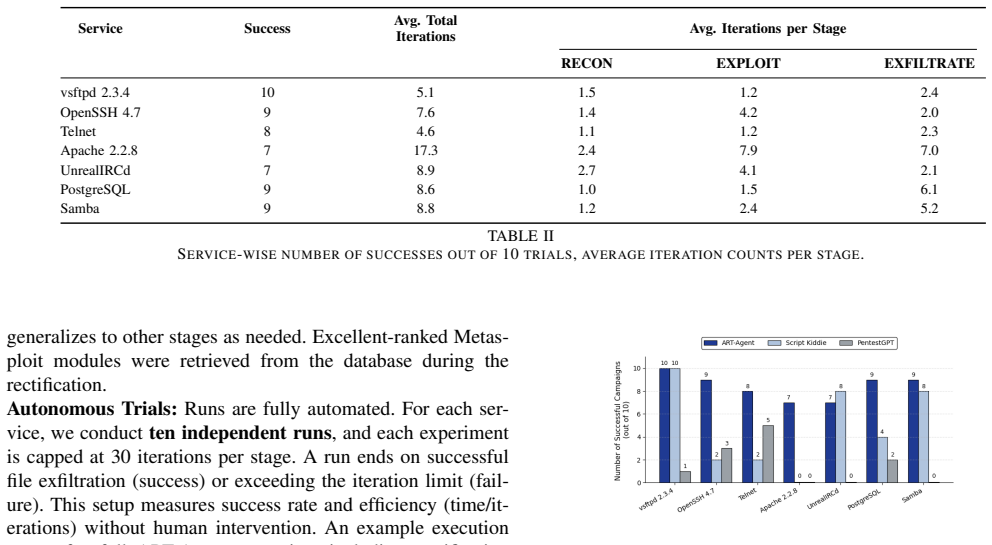
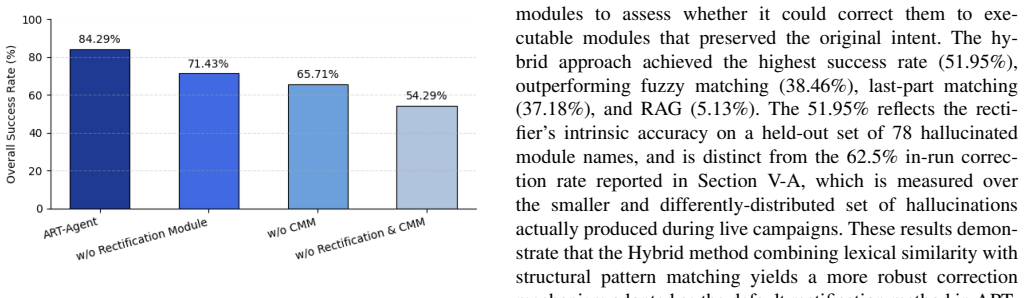
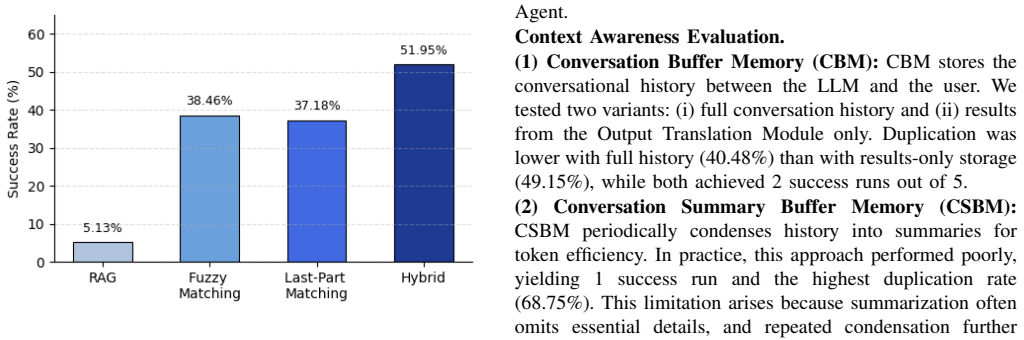
Penetration testing is essential to securing modern web infrastructures, yet traditional manual methods struggle to keep pace with their scale and complexity. Large Language Models (LLMs) offer new opportunities for automating these tasks, but existing approaches face two persistent challenges: hallucination of technical entities and insufficient long-term contextual memory. To address these issues, we present APT-Agent, a fully automated LLM-driven penetration testing framework that systematically orchestrates reconnaissance, exploitation, and exfiltration. APT-Agent introduces a hybrid rectification module to recover hallucinated commands and a command-specific memory architecture to preserve operational context across multi-step attack sequences. We evaluate our APT-Agent on Metasploitable 2 against seven vulnerable services spanning web, database, and network protocols. APT-Agent achieves an 84.29% end-to-end exploitation success rate, compared to 48.57% (Script Kiddie) and 18.57% (PentestGPT) under matched conditions. By reducing cognitive burden and minimizing reliance on human intervention, APT-Agent represents a step toward scalable, reliable, and cognitively efficient automation for penetration testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents APT-Agent, an LLM-based automated penetration testing framework that introduces a hybrid rectification module to recover from hallucinated commands and a command-specific memory architecture to maintain context over multi-step attacks. It evaluates the system on Metasploitable 2 targeting seven vulnerable services and reports an 84.29% end-to-end exploitation success rate, outperforming Script Kiddie (48.57%) and PentestGPT (18.57%) under matched conditions.
Significance. If the empirical results hold under rigorous evaluation, the work would demonstrate a meaningful advance in applying LLMs to security automation by addressing hallucination and context retention, with the explicit baseline comparisons on a fixed target environment providing a clear point of reference for the field.
major comments (1)
- [Evaluation] The central empirical claim of 84.29% success rate is presented without any description of the experimental protocol, number of trials, success criteria, variance across runs, or statistical comparison to baselines. This is load-bearing for the headline result and prevents assessment of whether the reported delta is robust or reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the evaluation requires substantially more detail on the experimental protocol to support the central claims.
read point-by-point responses
-
Referee: [Evaluation] The central empirical claim of 84.29% success rate is presented without any description of the experimental protocol, number of trials, success criteria, variance across runs, or statistical comparison to baselines. This is load-bearing for the headline result and prevents assessment of whether the reported delta is robust or reproducible.
Authors: We acknowledge that this comment is correct and that the manuscript as submitted does not contain the requested details. In the revised version we will add a dedicated Experimental Protocol subsection that specifies the number of independent trials, the precise success criteria (end-to-end exploitation resulting in shell access or data exfiltration), observed variance across runs, and statistical comparisons (e.g., appropriate significance tests) to the baselines. This addition will make the 84.29% result reproducible and allow readers to assess its robustness. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical systems contribution: it describes an LLM orchestration framework (hybrid rectification + command-specific memory) and reports measured success rates on Metasploitable 2 against explicit baselines. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim (84.29 % vs. 48.57 % / 18.57 %) is an observable experimental outcome, not a quantity forced by definition or prior self-work. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Technical guide to information security testing and assessment,
National Institute of Standards and Technology, “Technical guide to information security testing and assessment,” U.S. Department of Commerce, Tech. Rep. Special Publication 800-115, Sep. 2008, accessed: September 03, 2025. [Online]. Available: https://csrc.nist.gov/ publications/detail/sp/800-115/final
2008
-
[2]
Nautilus: Automated restful api vulnerability detection,
G. Deng, Z. Zhang, Y . Li, Y . Liu, T. Zhang, Y . Liu, Y . Guo, and D. Wang, “Nautilus: Automated restful api vulnerability detection,” inProceedings of the 32nd USENIX Security Symposium. USENIX Association, 2023
2023
-
[3]
Automated progressive red teaming,
B. Jiang, Y . Jing, T. Shen, T. Wu, Q. Yang, and D. Xiong, “Automated progressive red teaming,”arXiv preprint arXiv:2407.03876, 2024. [Online]. Available: https://arxiv.org/abs/2407.03876
-
[4]
Automated penetration testing: An overview,
F. Abu-Dabaseh and E. Alshammari, “Automated penetration testing: An overview,” inComputer Science & Information Technology (CS & IT), Apr. 2018, pp. 121–129
2018
-
[6]
A Survey of Large Language Models
[Online]. Available: https://arxiv.org/abs/2303.18223
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Digital twin for smart manufacturing, A review,
Y . Liu, T. Han, S. Ma, J. Zhang, Y . Yang, J. Tian, H. He, A. Li, M. He, Z. Liu, Z. Wu, L. Zhao, D. Zhu, X. Li, N. Qiang, D. Shen, T. Liu, and B. Ge, “Summary of chatgpt-related research and perspective towards the future of large language models,”Meta- Radiology, vol. 1, no. 2, p. 100017, Sep. 2023. [Online]. Available: http://dx.doi.org/10.1016/j.metra...
-
[8]
Exploitflow, cyber security exploitation routes for game theory and ai research in robotics,
V . Mayoral-Vilches, G. Deng, Y . Liu, M. Pinzger, and S. Rass, “Exploitflow, cyber security exploitation routes for game theory and ai research in robotics,” 2023. [Online]. Available: https: //arxiv.org/abs/2308.02152
-
[9]
How well does llm generate security tests?
Y . Zhang, W. Song, Z. Ji, D. Yao, and N. Meng, “How well does llm generate security tests?”arXiv preprint arXiv:2310.00710, 2023. [Online]. Available: https://arxiv.org/abs/2310.00710
-
[10]
Large language models for blockchain security: A systematic literature review,
Z. He, Z. Li, S. Yang, H. Ye, A. Qiao, X. Zhang, X. Luo, and T. Chen, “Large language models for blockchain security: A systematic literature review,”arXiv preprint arXiv:2403.14280, 2025. [Online]. Available: https://arxiv.org/abs/2403.14280
-
[11]
From promise to peril: Rethinking cybersecu- rity red and blue teaming in the age of llms,
A. Abuadbba, K. Moore, D. Goel, C. Hicks, V . Mavroudis, B. Hasir- cioglu, and P. Jennings, “From promise to peril: Rethinking cybersecu- rity red and blue teaming in the age of llms,”IEEE Security & Privacy, vol. 24, no. 2, pp. 53–63, 2026
2026
-
[12]
R. Fang, R. Bindu, A. Gupta, Q. Zhan, and D. Kang, “Llm agents can autonomously hack websites,”arXiv preprint arXiv:2402.06664, Feb
-
[13]
[Online]. Available: https://doi.org/10.48550/arXiv.2402.06664
-
[14]
LLM Agents can Autonomously Exploit One-day Vulnerabilities
R. Fang, R. Bindu, A. Gupta, and D. Kang, “Llm agents can autonomously exploit one-day vulnerabilities,”arXiv preprint arXiv:2404.08144, Apr. 2024. [Online]. Available: https://doi.org/10. 48550/arXiv.2404.08144
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Pentestgpt: An llm-empowered automatic penetration testing tool,
G. Deng, Y . Liu, V . Mayoral-Vilches, P. Liu, Y . Li, Y . Xu, T. Zhang, Y . Liu, M. Pinzger, and S. Rass, “Pentestgpt: An llm-empowered automatic penetration testing tool,”arXiv preprint arXiv:2308.06782, Aug. 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308. 06782
-
[16]
Autoattacker: A large language model guided system to implement automatic cyber-attacks,
J. Xu, J. W. Stokes, G. McDonald, X. Bai, D. Marshall, S. Wang, A. Swaminathan, and Z. Li, “Autoattacker: A large language model guided system to implement automatic cyber-attacks,”arXiv preprint arXiv:2403.01038, Mar. 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2403.01038
- [17]
-
[18]
Drowzee: Metamorphic testing for fact-conflicting hallucination detection in large language models,
N. Li, Y . Li, Y . Liu, L. Shi, K. Wang, and H. Wang, “Drowzee: Metamorphic testing for fact-conflicting hallucination detection in large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2405. 00648
2024
-
[19]
SelfcheckGPT: Zero-resource black-box hallucination detection for generative large language models,
P. Manakul, A. Liusie, and M. Gales, “SelfcheckGPT: Zero-resource black-box hallucination detection for generative large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023. [Online]. Available: https://openreview.net/forum?id=RwzFNbJ3Ez
2023
-
[20]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems. Curran Associates Inc., 2023. [Online]. Available: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
L. Yang, H. Chen, Z. Li, X. Ding, and X. Wu, “Chatgpt is not enough: Enhancing large language models with knowledge graphs for fact-aware language modeling,”arXiv preprint arXiv:2306.11489, Jun
-
[22]
[Online]. Available: https://doi.org/10.48550/arXiv.2306.11489
-
[23]
Efficient interactive fuzzy keyword search,
S. Ji, G. Li, C. Li, and J. Feng, “Efficient interactive fuzzy keyword search,” inProceedings of the 18th ACM Conference on Information and Knowledge Management (CIKM). New York, NY , USA: Association for Computing Machinery, 2009. [Online]. Available: https://doi.org/10.1145/1526709.1526760
-
[24]
Metasploitable 2,
Rapid7, “Metasploitable 2,” 2025, accessed: September 03, 2025. [On- line]. Available: https://docs.rapid7.com/metasploit/metasploitable-2/
2025
-
[25]
S. Moskal, S. Laney, E. Hemberg, and U.-M. O’Reilly, “Llms killed the script kiddie: How agents supported by large language models change the landscape of network threat testing,”arXiv preprint arXiv:2309.00667, Sep. 2023. [Online]. Available: https: //arxiv.org/abs/2309.00667
-
[26]
Pomdp + information- decay: Incorporating defender’s behaviour in autonomous penetration testing,
J. Schwartz, H. Kurniawati, and E. El-Mahassni, “Pomdp + information- decay: Incorporating defender’s behaviour in autonomous penetration testing,” inProceedings of the 30th International Conference on Automated Planning and Scheduling (ICAPS), 2020, pp. 235–243. [Online]. Available: https://doi.org/10.1609/icaps.v30i1.6666
-
[27]
Gail-pt: An intelligent penetration testing framework with generative adversarial imitation learning,
J. Chen, S. Hu, H. Zheng, C. Xing, and G. Zhang, “Gail-pt: An intelligent penetration testing framework with generative adversarial imitation learning,”Computers & Security, vol. 126, p. 103055, 2023
2023
-
[28]
N. Becker, D. Reti, E. V . N. Ntagiou, M. Wallum, and H. D. Schotten, “Evaluation of reinforcement learning for autonomous penetration testing using a3c, q-learning and dqn,”arXiv preprint arXiv:2407.15656, Jul. 2024. [Online]. Available: https://doi.org/10. 48550/arXiv.2407.15656
-
[29]
Q. Li, M. Zhang, Y . Shen, R. Wang, M. Hu, Y . Li, and H. Hao, “A hierarchical deep reinforcement learning model with expert prior knowledge for intelligent penetration testing,”Computers & Security, vol. 132, p. 103358, 2023. [Online]. Available: https: //doi.org/10.1016/j.cose.2023.103358
-
[30]
Pentestagent: Incorporating llm agents to automated penetration testing,
X. Shen, L. Wang, Z. Li, Y . Chen, W. Zhao, D. Sun, J. Wang, and W. Ruan, “Pentestagent: Incorporating llm agents to automated penetration testing,”arXiv preprint arXiv:2411.05185, 2025. [Online]. Available: https://arxiv.org/abs/2411.05185
-
[31]
Metasploit,
Rapid7, “Metasploit,” https://www.metasploit.com/, 2025, accessed: September 03, 2025
2025
-
[32]
Penetration testing for system security: Methods and practical approaches,
W. Zhang, J. Xing, and X. Li, “Penetration testing for system security: Methods and practical approaches,”arXiv preprint arXiv:2505.19174, May 2025. [Online]. Available: https://arxiv.org/abs/2505.19174
-
[33]
Penetration Testing == POMDP Solving?
C. Sarraute, O. Buffet, and J. Hoffmann, “Penetration testing == pomdp solving?”arXiv preprint arXiv:1306.4714, 2013. [Online]. Available: https://doi.org/10.48550/arXiv.1306.4714
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1306.4714 2013
-
[34]
Gpt-3.5 turbo,
OpenAI, “Gpt-3.5 turbo,” https://platform.openai.com/docs/models/ gpt-3.5-turbo, 2022, accessed: September 03, 2025
2022
-
[35]
——, “Gpt-4o,” https://platform.openai.com/docs/models/gpt-4o, 2024, accessed: September 03, 2025
2024
-
[36]
Mitre att&ck ® — enterprise tactics,
MITRE Corporation, “Mitre att&ck ® — enterprise tactics,” accessed 2025-10-08. [Online]. Available: https://attack.mitre.org/ tactics/enterprise/
2025
-
[37]
PenHeal: A Two-Stage LLM Framework for Automated Pentesting and Optimal Remediation,
J. Huang and Q. Zhu, “PenHeal: A Two-Stage LLM Framework for Automated Pentesting and Optimal Remediation,” inProceedings of the Workshop on Autonomous Cybersecurity. ACM, Nov. 2024. [Online]. Available: https://dl.acm.org/doi/10.1145/3689933.3690831 APPENDIXA COMPARISON WITHPENHEAL PenHeal [34] also evaluates its framework on the Metas- ploitable II envi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.