Scaling up Energy-Aware Multi-Agent Reinforcement Learning for Mission-Oriented Drone Networks with Individual Reward
Pith reviewed 2026-06-29 23:57 UTC · model grok-4.3
The pith
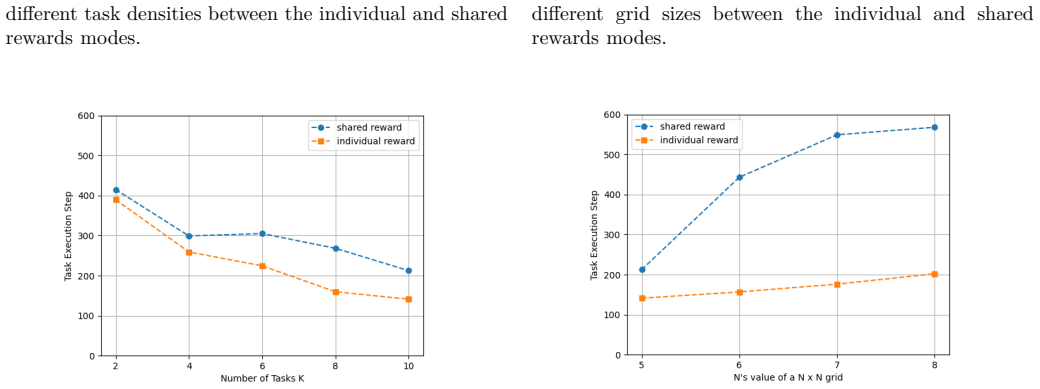
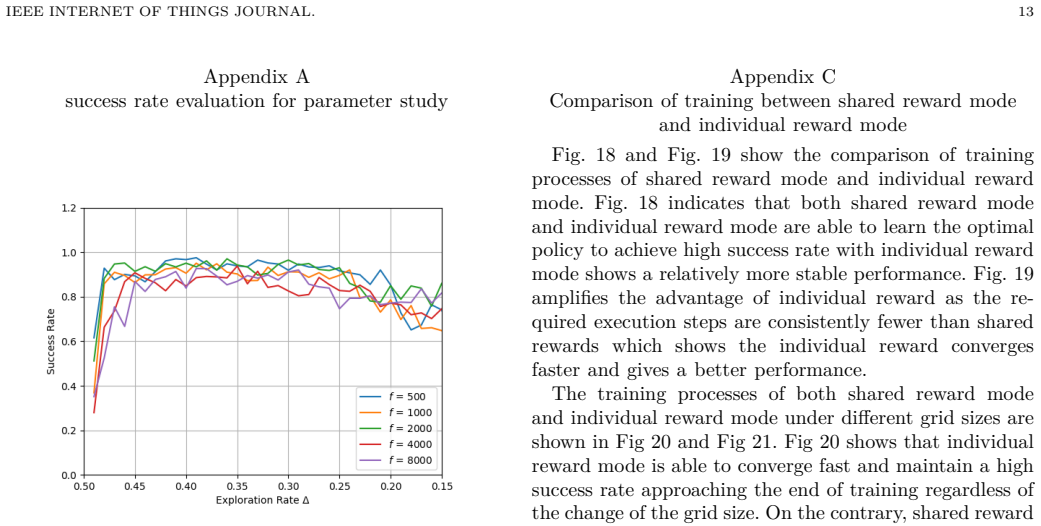
Individual reward functions in energy-aware drone MARL deliver higher success rates and fewer steps when environment size and agent count increase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
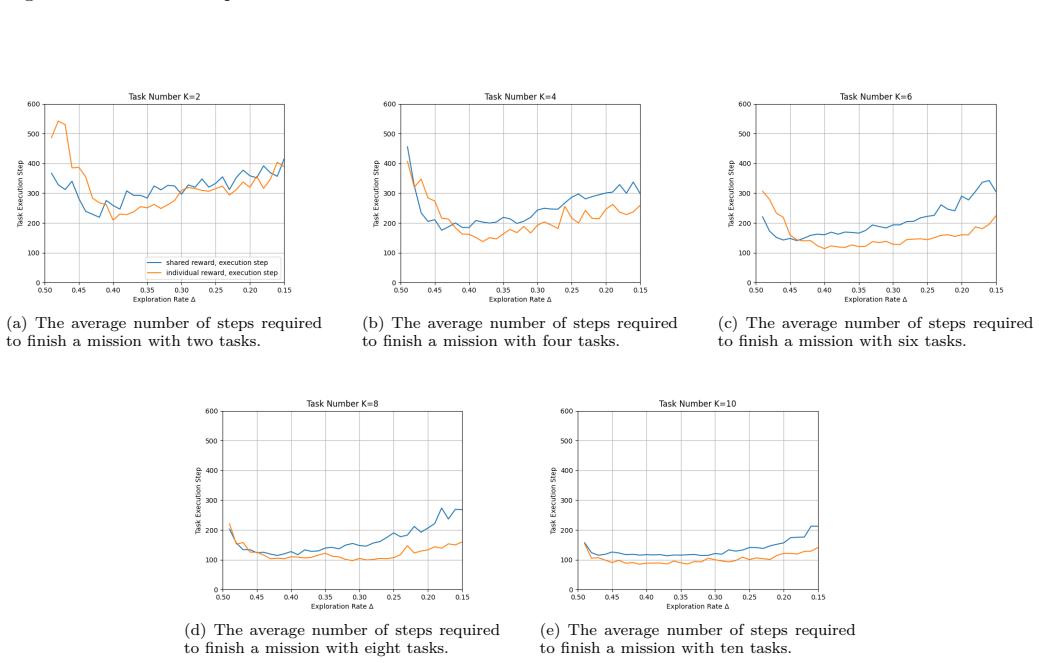
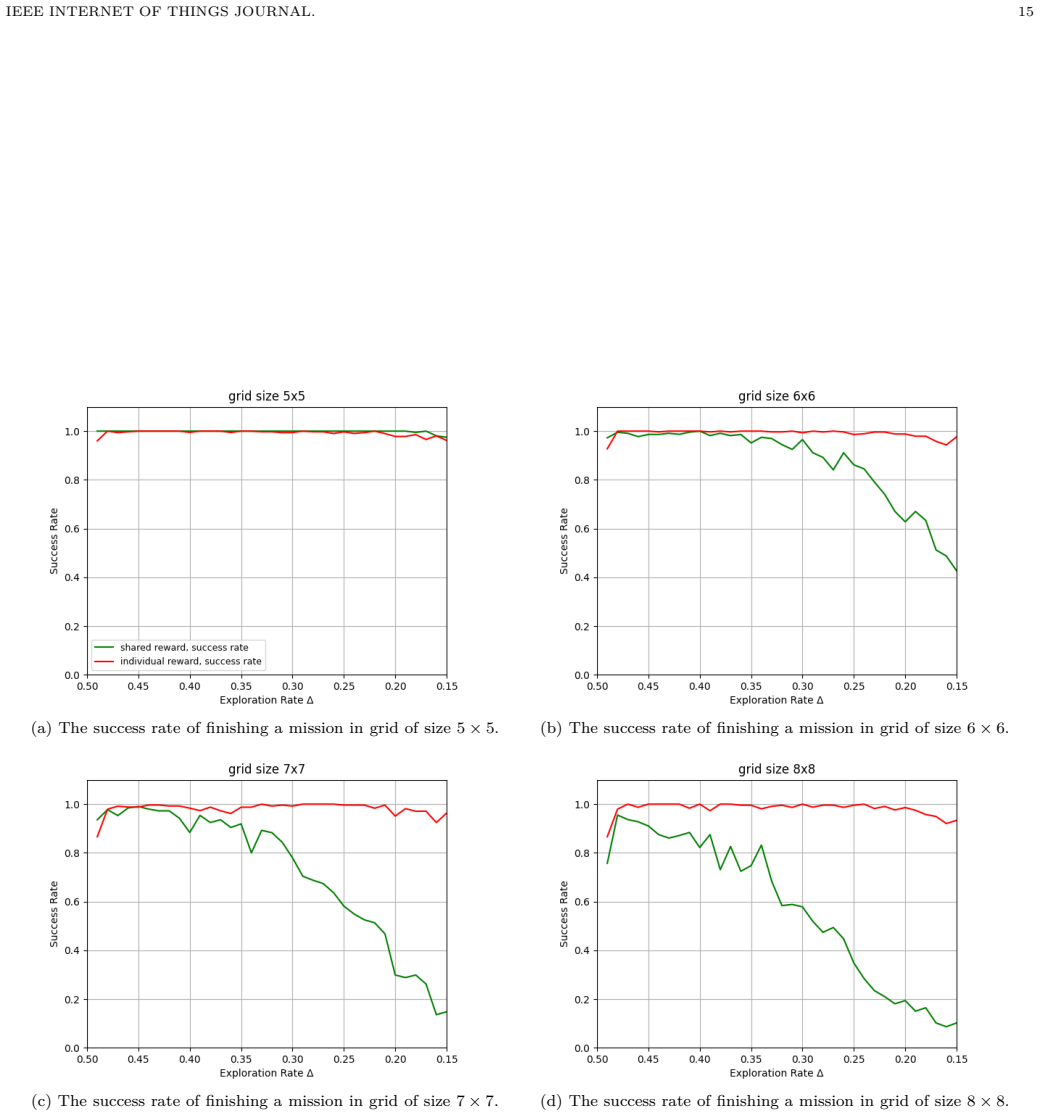
The central claim is that replacing a shared reward with individual rewards driven by task execution progress and remaining battery in a DQN-based MARL model produces greater robustness to increases in environment size and agent numbers, yielding higher success rates achieved in fewer steps and therefore better energy use than the shared-reward baseline.
What carries the argument
Individual reward functions driven by task execution progress and remaining battery of each drone, which supply each agent with a clear, local signal instead of a single group reward.
If this is right
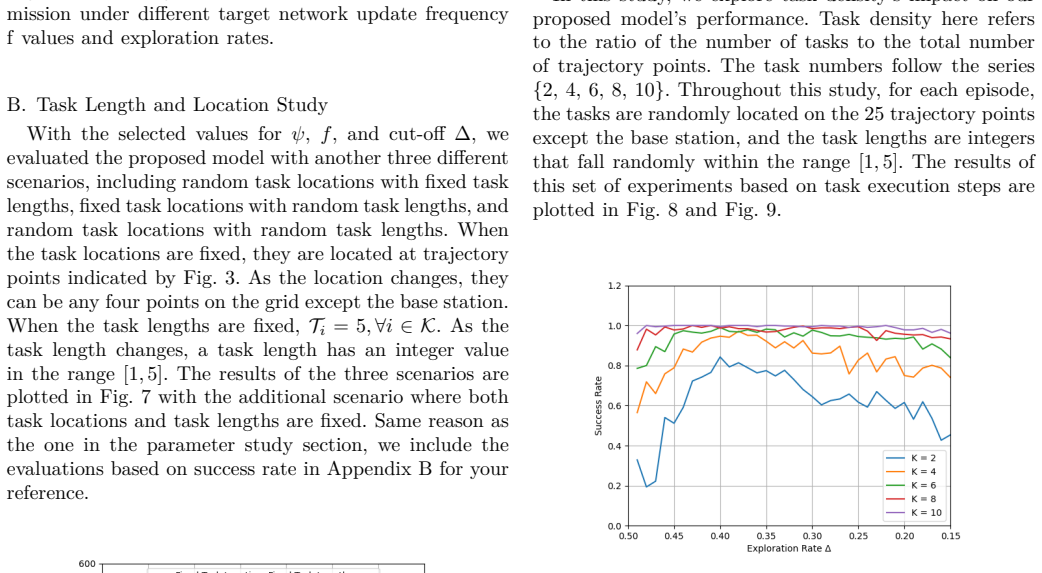
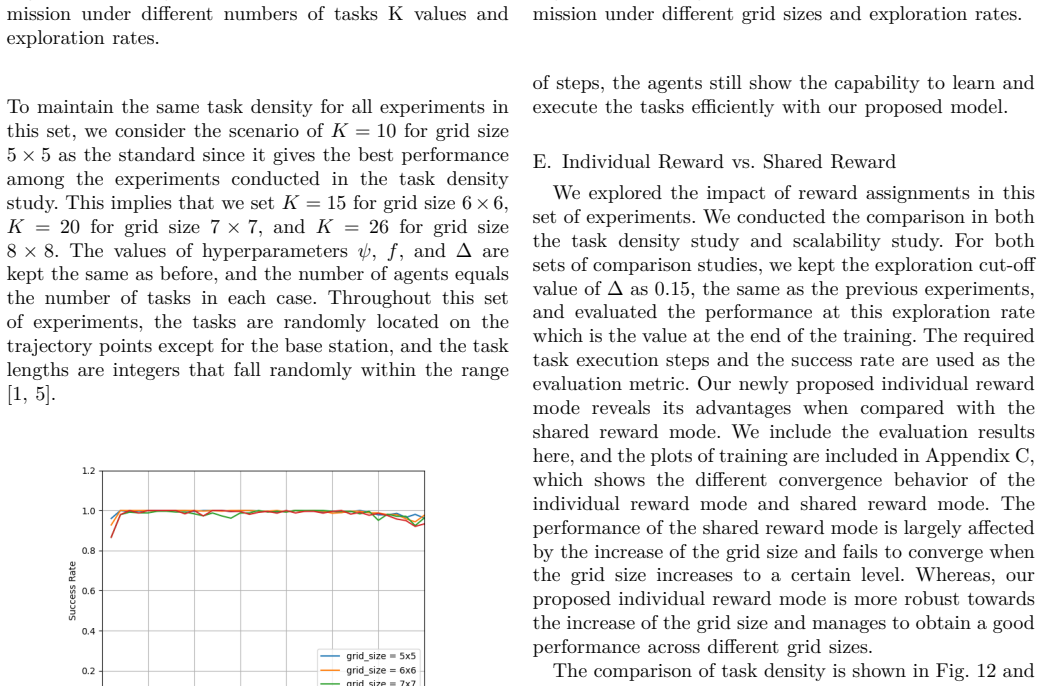
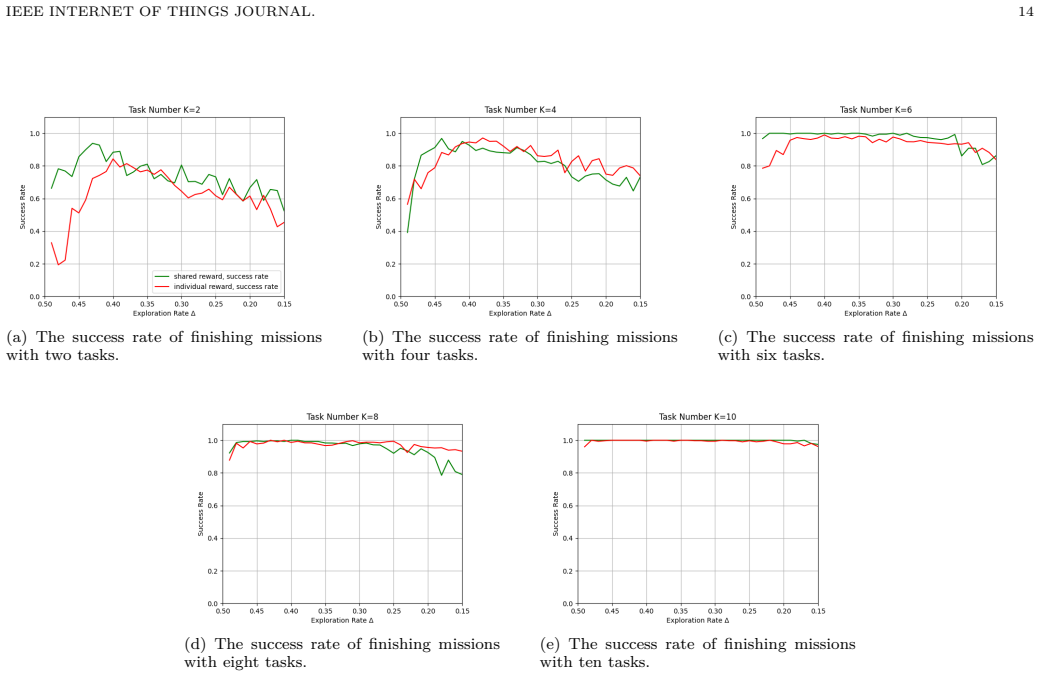
- The individual-reward model achieves at least 80 percent success rate independent of task locations and lengths.
- Success rate improves with higher task density and approaches 100 percent near 40 percent density.
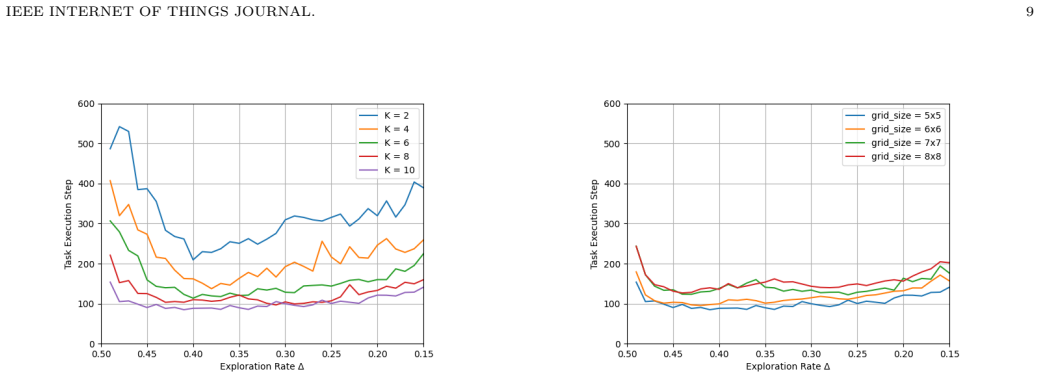
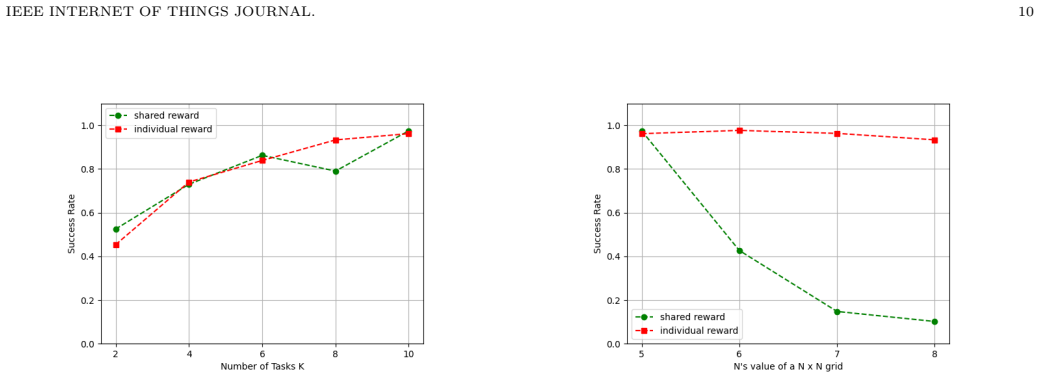
- The model remains effective when environment size or agent count grows, unlike the shared-reward version.
- Higher success is reached in fewer steps, which directly reduces total energy consumed.
Where Pith is reading between the lines
- The same individual-reward structure could be tried in other resource-constrained multi-agent settings such as autonomous vehicle fleets.
- Explicit per-agent goals may reduce the need for elaborate credit-assignment techniques when the number of agents becomes large.
- Real-world battery discharge curves that include wind or payload effects could be substituted into the reward to test sensitivity.
- The approach might allow mission planners to add or remove drones mid-operation without retraining the entire team policy.
Load-bearing premise
The simulation environment and battery model accurately reflect the dynamics that would occur with real drones, and the shared-reward baseline is reproduced exactly except for the reward structure.
What would settle it
Running the same mission scenarios with physical drones while varying the number of agents and the size of the operating area, then checking whether the individual-reward model still records higher success and fewer total steps than the shared-reward model.
Figures




read the original abstract
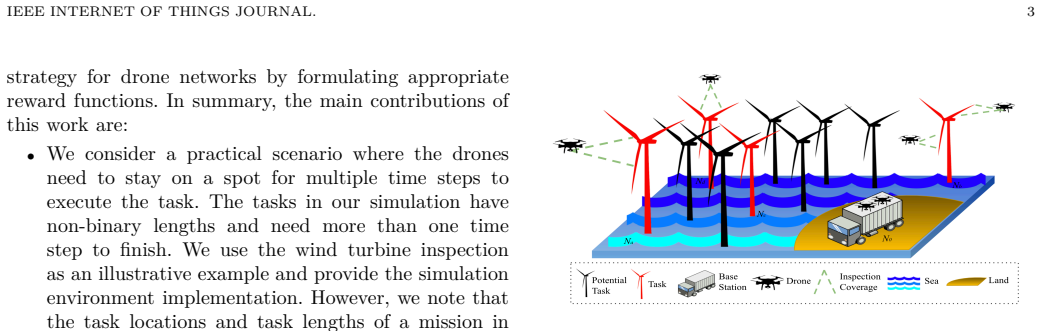
Multi-agent reinforcement learning (MARL) has shown wide applicability in collaborative systems such as autonomous driving and smart cities for its ability of learning through interaction. With the recent development of drone networks, researchers have also applied MARL to address the trajectory planning problems. However, the dynamic environment and the limited battery capacity are still challenging for using MARL to achieve efficient collaborative task execution. In this paper, we propose an energy-aware MARL model as an attempt to tackle these challenges, leveraging Deep Q-Networks (DQN) with \emph{individual reward functions} driven by the task execution progress and the remaining battery of drones. We conduct a set of simulation studies for the proposed mode and compare it with the shared reward MARL~\cite{Li2022MARL} to explore the impact of credit assignment in MARL. The results indicate that our proposed model can achieve at least 80\% success rate regardless of the task locations and lengths. Similar to the shared reward mode, the individual reward mode can achieve a better success rate when the task density is high, and it can hit nearly a 100\% success rate when task density gets close to 40\%. The true advantage of our proposed model with individual reward is revealed when scaling up the environment. The comparison to the shared reward MARL shows that the our proposed model is more robust towards the change of the environment size and agent numbers. It can achieve higher success rate with fewer steps due to the clarity of the goal which improves energy efficiency even better.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an energy-aware multi-agent reinforcement learning model using Deep Q-Networks with individual reward functions (driven by task execution progress and remaining battery) for trajectory planning in mission-oriented drone networks. It reports simulation results claiming at least 80% success rate independent of task locations/lengths, improved performance at high task density (near 100% at ~40% density), and superior robustness to scaling environment size and agent numbers compared to the shared-reward baseline from Li2022MARL, with higher success rates, fewer steps, and better energy efficiency due to clearer goal credit assignment.
Significance. If the baseline comparison is controlled and results reproducible, the work would demonstrate the value of individual rewards for credit assignment in scalable, energy-constrained MARL for drone systems, addressing dynamic environments and battery limits in collaborative task execution.
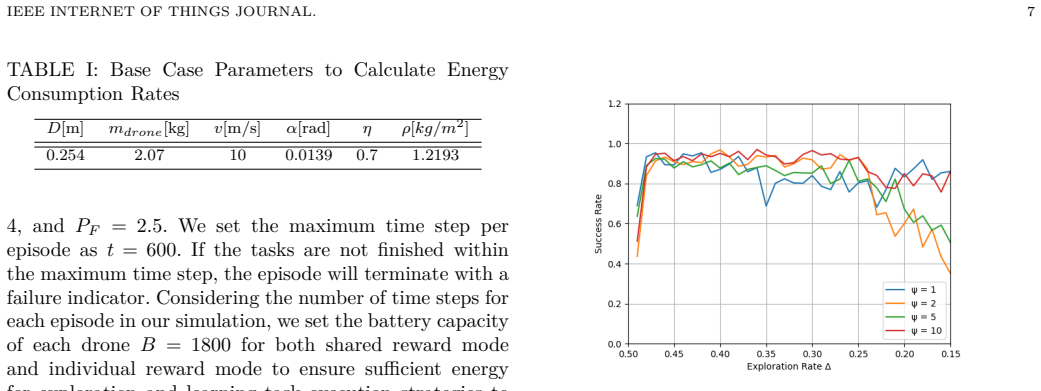
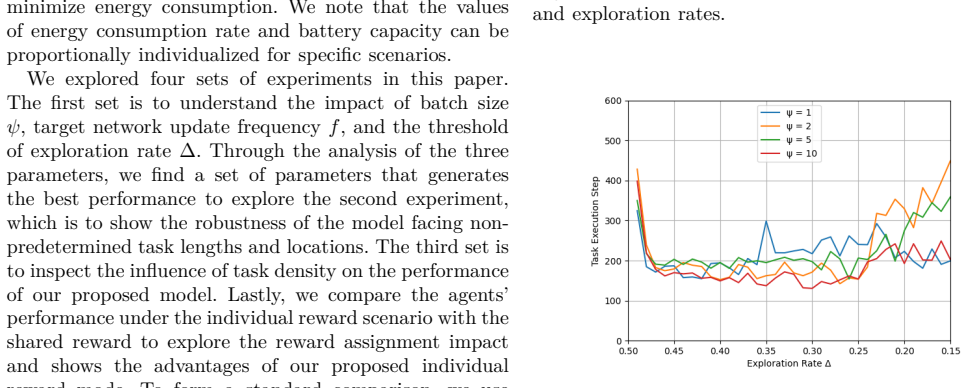
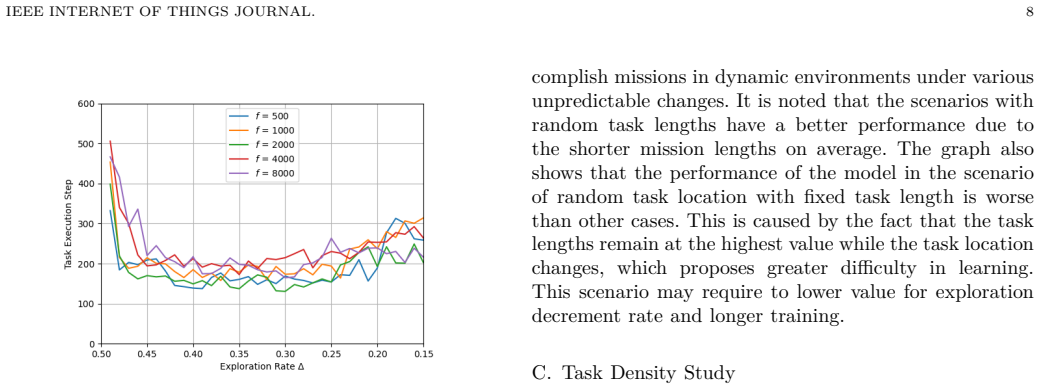
major comments (2)
- [Abstract] Abstract and simulation studies: The central robustness claim (higher success rate with fewer steps when scaling environment size and agent numbers) attributes the advantage to the individual reward. However, no evidence is provided (hyperparameter tables, explicit statement, or code) that the Li2022MARL shared-reward baseline was reimplemented identically in state space, action space, DQN architecture, replay buffer, exploration, battery dynamics, task generation, and termination conditions. Any mismatch confounds the credit-assignment effect.
- [Abstract] Abstract and simulation studies: Success rates and scaling behavior are reported without training curves, run-to-run variance, hyperparameter details, or statistical tests. This makes it impossible to assess whether the reported robustness (e.g., at least 80% success regardless of task locations) is reliable or sensitive to implementation choices.
minor comments (2)
- [Abstract] Abstract: The sentence containing 'the our proposed model' contains a grammatical error that should be corrected for clarity.
- The battery model and full simulation environment parameters are referenced but not described in sufficient detail to allow independent reproduction or assessment of physical fidelity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important issues regarding reproducibility and the strength of the baseline comparison. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and simulation studies: The central robustness claim (higher success rate with fewer steps when scaling environment size and agent numbers) attributes the advantage to the individual reward. However, no evidence is provided (hyperparameter tables, explicit statement, or code) that the Li2022MARL shared-reward baseline was reimplemented identically in state space, action space, DQN architecture, replay buffer, exploration, battery dynamics, task generation, and termination conditions. Any mismatch confounds the credit-assignment effect.
Authors: We agree that the manuscript does not currently provide sufficient documentation to confirm identical reimplementation of the Li2022MARL baseline. In the revised version we will add an explicit subsection (and accompanying table) that lists all implementation choices for both methods side-by-side, covering state/action spaces, DQN architecture, replay buffer size, exploration schedule, battery model, task generation procedure, and termination conditions. This will allow readers to verify that the only controlled difference is the reward structure, thereby isolating the credit-assignment effect. revision: yes
-
Referee: [Abstract] Abstract and simulation studies: Success rates and scaling behavior are reported without training curves, run-to-run variance, hyperparameter details, or statistical tests. This makes it impossible to assess whether the reported robustness (e.g., at least 80% success regardless of task locations) is reliable or sensitive to implementation choices.
Authors: We acknowledge the absence of these elements. The revised manuscript will include: (i) training curves for both reward variants, (ii) mean and standard deviation across at least five independent random seeds, (iii) a complete hyperparameter table, and (iv) statistical significance tests (e.g., paired t-tests or Wilcoxon tests) on the reported success rates and step counts. These additions will allow readers to evaluate the reliability of the scaling results. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivation chain
full rationale
The manuscript presents a simulation-based empirical comparison of an individual-reward DQN variant against a shared-reward baseline from prior work. No mathematical derivation, first-principles result, fitted parameter renamed as prediction, or self-definitional construct is claimed or present. The single self-citation references the baseline method for comparison purposes; the reported robustness findings are direct simulation outputs rather than reductions to inputs by construction. The paper is self-contained as an empirical study against external benchmarks (simulated environments), satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Energy-Aware Multi- Agent Reinforcement Learning for Collaborative Execution in Mission-Oriented Drone Networks,
Y. Li, C. Li, J. Chen, and C. Roinou, “Energy-Aware Multi- Agent Reinforcement Learning for Collaborative Execution in Mission-Oriented Drone Networks,” IEEE International Confer- ence on Computer Communications and Networks, July. 2022
2022
-
[2]
Human-level control through deep rein- forcement learning,
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep rein- forcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[3]
A Deep Policy Inference Q-Network for Multi-Agent Systems
Z.-W. Hong, S.-Y. Su, T.-Y. Shann, Y.-H. Chang, and C.-Y. Lee, “A deep policy inference q-network for multi-agent systems,” arXiv preprint arXiv:1712.07893, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
A review of coopera- tive multi-agent deep reinforcement learning,
A. OroojlooyJadid and D. Hajinezhad, “A review of coopera- tive multi-agent deep reinforcement learning,” arXiv preprint arXiv:1908.03963, 2019
-
[5]
A collaborative multi-agent reinforcement learning anti-jamming algorithm in wireless networks,
F. Yao and L. Jia, “A collaborative multi-agent reinforcement learning anti-jamming algorithm in wireless networks,” IEEE wireless communications letters, vol. 8, no. 4, pp. 1024–1027, 2019
2019
-
[6]
Multiagent cooperation and competition with deep reinforcement learning,
A. Tampuu, T. Matiisen, D. Kodelja, I. Kuzovkin, K. Kor- jus, J. Aru, J. Aru, and R. Vicente, “Multiagent cooperation and competition with deep reinforcement learning,” PloS one, vol. 12, no. 4, p. e0172395, 2017
2017
-
[7]
Multi-agent reinforcement learning: An overview,
L. Buşoniu, R. Babuška, and B. De Schutter, “Multi-agent reinforcement learning: An overview,” Innovations in multi- agent systems and applications-1, pp. 183–221, 2010
2010
-
[8]
Multi-agent actor-critic for mixed cooperative- competitive environments,
R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative- competitive environments,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[9]
Delay-aware multi- agent reinforcement learning for cooperative and competitive environments,
B. Chen, M. Xu, Z. Liu, L. Li, and D. Zhao, “Delay-aware multi- agent reinforcement learning for cooperative and competitive environments,” arXiv preprint arXiv:2005.05441, 2020
-
[10]
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint arXiv:1511.05952, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in International conference on machine learning. PMLR, 2018, pp. 1861–1870
2018
-
[12]
Addressing function approximation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” in International conference on machine learning. PMLR, 2018, pp. 1587–1596
2018
-
[13]
Roer: Regularized optimal experience replay,
C. Li, Z.-W. Hong, P. Agrawal, D. Garg, and J. Pajarinen, “Roer: Regularized optimal experience replay,” arXiv preprint arXiv:2407.03995, 2024
-
[14]
Multi-agent reinforcement learning for adaptive de- mand response in smart cities,
J. Vazquez-Canteli, T. Detjeen, G. Henze, J. Kämpf, and Z. Nagy, “Multi-agent reinforcement learning for adaptive de- mand response in smart cities,” in Journal of Physics: Confer- ence Series, vol. 1343, no. 1. IOP Publishing, 2019, p. 012058
2019
-
[15]
A multi-agent reinforce- ment learning approach to robot soccer,
Y. Duan, B. X. Cui, and X. H. Xu, “A multi-agent reinforce- ment learning approach to robot soccer,” Artificial Intelligence Review, vol. 38, no. 3, pp. 193–211, 2012
2012
-
[16]
Z. Zhang, J. Yang, and H. Zha, “Integrating independent and centralized multi-agent reinforcement learning for traffic signal network optimization,” arXiv preprint arXiv:1909.10651, 2019
-
[17]
Solving dynamic traveling salesman problems with deep reinforcement learning,
Z. Zhang, H. Liu, M. Zhou, and J. Wang, “Solving dynamic traveling salesman problems with deep reinforcement learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 4, pp. 2119–2132, 2023
2023
-
[18]
Secure underwater distributed an- tenna systems: A multi-agent reinforcement learning approach,
C. Wang, Z. Bi, and Y. Wan, “Secure underwater distributed an- tenna systems: A multi-agent reinforcement learning approach,” IEEE/CAA Journal of Automatica Sinica, vol. 10, no. 7, pp. 1622–1624, 2023
2023
-
[19]
Using drones for parcels delivery process,
L. D. P. Pugliese, F. Guerriero, and G. Macrina, “Using drones for parcels delivery process,” Procedia Manufacturing, vol. 42, pp. 488–497, 2020
2020
-
[20]
Cooperative dual-task path planning for persistent surveillance and emergency handling by multiple unmanned ground vehicles,
J. Zhang, Y. Wu, and M. Zhou, “Cooperative dual-task path planning for persistent surveillance and emergency handling by multiple unmanned ground vehicles,” IEEE Transactions on Intelligent Transportation Systems, pp. 1–12, 2024. IEEE INTERNET OF THINGS JOURNAL. 12
2024
-
[21]
Cost-efficient task offloading in mobile edge computing with layered unmanned aerial vehicles,
H. Yuan, M. Wang, J. Bi, S. Shi, J. Yang, J. Zhang, M. Zhou, and R. Buyya, “Cost-efficient task offloading in mobile edge computing with layered unmanned aerial vehicles,” IEEE In- ternet of Things Journal, pp. 1–1, 2024
2024
-
[22]
Energy-efficient scheduling in uav-assisted hierarchi- cal wireless sensor networks,
R. Lai, B. Zhang, G. Gong, H. Yuan, J. Yang, J. Zhang, and M. Zhou, “Energy-efficient scheduling in uav-assisted hierarchi- cal wireless sensor networks,” IEEE Internet of Things Journal, vol. 11, no. 11, pp. 20 194–20 206, 2024
2024
-
[23]
Uav-assisted dynamic avatar task migration for vehicular metaverse services: A multi-agent deep reinforcement learning approach,
J. Kang, J. Chen, M. Xu, Z. Xiong, Y. Jiao, L. Han, D. Niy- ato, Y. Tong, and S. Xie, “Uav-assisted dynamic avatar task migration for vehicular metaverse services: A multi-agent deep reinforcement learning approach,” IEEE/CAA Journal of Au- tomatica Sinica, vol. 11, no. 2, pp. 430–445, 2024
2024
-
[24]
Cooperative internet of UA Vs: Distributed trajectory design by multi-agent deep reinforcement learning,
J. Hu, H. Zhang, L. Song, R. Schober, and H. V. Poor, “Cooperative internet of UA Vs: Distributed trajectory design by multi-agent deep reinforcement learning,” IEEE Transactions on Communications, vol. 68, no. 11, pp. 6807–6821, 2020
2020
-
[25]
Wind turbine surface damage detection by deep learning aided drone inspection analysis,
A. Shihavuddin, X. Chen, V. Fedorov, A. Nymark Christensen, N. Andre Brogaard Riis, K. Branner, A. Bjorholm Dahl, and R. Reinhold Paulsen, “Wind turbine surface damage detection by deep learning aided drone inspection analysis,” Energies, vol. 12, no. 4, p. 676, 2019
2019
-
[26]
Toth and D
P. Toth and D. Vigo, The vehicle routing problem. SIAM, 2002
2002
-
[27]
New intelligent battery management system for drones,
S. R. Hashemi, R. Esmaeeli, H. Aliniagerdroudbari, M. Alhadri, H. Alshammari, A. Mahajan, and S. Farhad, “New intelligent battery management system for drones,” in ASME interna- tional mechanical engineering congress and exposition, vol. 59438. American Society of Mechanical Engineers, 2019, p. V006T06A028
2019
-
[28]
A survey on multi-agent deep rein- forcement learning: from the perspective of challenges and applications,
W. Du and S. Ding, “A survey on multi-agent deep rein- forcement learning: from the perspective of challenges and applications,” Artificial Intelligence Review, vol. 54, no. 5, pp. 3215–3238, 2021
2021
-
[29]
3M-RL: Multi- Resolution, Multi-Agent, Mean-Field Reinforcement Learning for Autonomous UA V Routing,
W. Wang, Y. Liu, R. Srikant, and L. Ying, “3M-RL: Multi- Resolution, Multi-Agent, Mean-Field Reinforcement Learning for Autonomous UA V Routing,” IEEE Transactions on Intelli- gent Transportation Systems, 2021
2021
-
[30]
Autonomous multirobot navigation and cooperative mapping in partially un- known environments,
H. Xie, D. Zhang, X. Hu, M. Zhou, and Z. Cao, “Autonomous multirobot navigation and cooperative mapping in partially un- known environments,” IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–12, 2023
2023
-
[31]
Multi-Agent Reinforcement Learning Based 3D Trajectory Design in Aerial-Terrestrial Wireless Caching Networks,
Y.-J. Chen, K.-M. Liao, M.-L. Ku, F. P. Tso, and G.-Y. Chen, “Multi-Agent Reinforcement Learning Based 3D Trajectory Design in Aerial-Terrestrial Wireless Caching Networks,” IEEE Transactions on Vehicular Technology, vol. 70, no. 8, pp. 8201– 8215, 2021
2021
-
[32]
Multi-agent deep reinforcement learning for trajectory design and power allocation in multi- UA V networks,
N. Zhao, Z. Liu, and Y. Cheng, “Multi-agent deep reinforcement learning for trajectory design and power allocation in multi- UA V networks,” IEEE Access, vol. 8, pp. 139 670–139 679, 2020
2020
-
[33]
Multi-agent deep reinforcement learning-based trajectory plan- ning for multi-UA V assisted mobile edge computing,
L. Wang, K. Wang, C. Pan, W. Xu, N. Aslam, and L. Hanzo, “Multi-agent deep reinforcement learning-based trajectory plan- ning for multi-UA V assisted mobile edge computing,” IEEE Transactions on Cognitive Communications and Networking, vol. 7, no. 1, pp. 73–84, 2020
2020
-
[34]
Efficient uav trajectory-planning using economic reinforcement learning,
A. A. Khalil, A. J. Byrne, M. A. Rahman, and M. H. Manshaei, “Efficient uav trajectory-planning using economic reinforcement learning,” arXiv preprint arXiv:2103.02676, 2021
-
[35]
Deep reinforcement learning based task-oriented communication in multi-agent systems,
G. He, M. Feng, Y. Zhang, G. Liu, Y. Dai, and T. Jiang, “Deep reinforcement learning based task-oriented communication in multi-agent systems,” IEEE Wireless Communications, vol. 30, no. 3, pp. 112–119, 2023
2023
-
[36]
Multi-agent reinforcement learning-based coordinated dynamic task alloca- tion for heterogenous uavs,
D. Liu, L. Dou, R. Zhang, X. Zhang, and Q. Zong, “Multi-agent reinforcement learning-based coordinated dynamic task alloca- tion for heterogenous uavs,” IEEE Transactions on Vehicular Technology, vol. 72, no. 4, pp. 4372–4383, 2023
2023
-
[37]
Shapley Q-value: A local reward approach to solve global reward games,
J. Wang, Y. Zhang, T.-K. Kim, and Y. Gu, “Shapley Q-value: A local reward approach to solve global reward games,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, 2020, pp. 7285–7292
2020
-
[38]
Cm3: Cooperative multi-goal multi-stage multi-agent reinforcement learning,
J. Yang, A. Nakhaei, D. Isele, K. Fujimura, and H. Zha, “Cm3: Cooperative multi-goal multi-stage multi-agent reinforcement learning,” arXiv preprint arXiv:1809.05188, 2018
-
[39]
Multi-agent reinforcement learning for problems with combined individual and team reward,
H. U. Sheikh and L. Bölöni, “Multi-agent reinforcement learning for problems with combined individual and team reward,” in 2020 International Joint Conference on Neural Networks (IJCNN). IEEE, 2020, pp. 1–8
2020
-
[40]
Liir: Learning individual intrinsic reward in multi-agent reinforce- ment learning,
Y. Du, L. Han, M. Fang, J. Liu, T. Dai, and D. Tao, “Liir: Learning individual intrinsic reward in multi-agent reinforce- ment learning,” Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[41]
Energy use and life cycle greenhouse gas emissions of drones for commercial package delivery,
J. K. Stolaroff, C. Samaras, E. R. O’Neill, A. Lubers, A. S. Mitchell, and D. Ceperley, “Energy use and life cycle greenhouse gas emissions of drones for commercial package delivery,” Nature communications, vol. 9, no. 1, p. 409, 2018
2018
-
[42]
Evaluation of artificial neural network inference speed and energy consumption on embedded systems,
A. Arnautović and E. Teskeredžić, “Evaluation of artificial neural network inference speed and energy consumption on embedded systems,” in 2021 20th International Symposium INFOTEH-JAHORINA (INFOTEH). IEEE, 2021, pp. 1–5
2021
-
[43]
Neuropower: Designing energy efficient convolutional neural network architecture for embedded systems,
M. Loni, A. Zoljodi, S. Sinaei, M. Daneshtalab, and M. Sjödin, “Neuropower: Designing energy efficient convolutional neural network architecture for embedded systems,” in Artificial Neu- ral Networks and Machine Learning–ICANN 2019: Theoretical Neural Computation: 28th International Conference on Arti- ficial Neural Networks, Munich, Germany, September 17–...
2019
-
[44]
Neuro. zero: a zero-energy neural network accelerator for embedded sensing and inference systems,
S. Lee and S. Nirjon, “Neuro. zero: a zero-energy neural network accelerator for embedded sensing and inference systems,” in Proceedings of the 17th Conference on Embedded Networked Sensor Systems, 2019, pp. 138–152
2019
-
[45]
Energy-efficient acceleration of deep neural networks on realtime-constrained embedded edge devices,
B. Kim, S. Lee, A. R. Trivedi, and W. J. Song, “Energy-efficient acceleration of deep neural networks on realtime-constrained embedded edge devices,” IEEE Access, vol. 8, pp. 216 259– 216 270, 2020
2020
-
[46]
Embedded deep neural network processing: Algorithmic and processor techniques bring deep learning to iot and edge devices,
M. Verhelst and B. Moons, “Embedded deep neural network processing: Algorithmic and processor techniques bring deep learning to iot and edge devices,” IEEE Solid-State Circuits Magazine, vol. 9, no. 4, pp. 55–65, 2017
2017
-
[47]
Reinforcement learning for decentralized trajectory design in cellular UA V networks with sense-and-send protocol,
J. Hu, H. Zhang, and L. Song, “Reinforcement learning for decentralized trajectory design in cellular UA V networks with sense-and-send protocol,” IEEE Internet of Things Journal, vol. 6, no. 4, pp. 6177–6189, 2018
2018
-
[48]
Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient,
S. Li, Y. Wu, X. Cui, H. Dong, F. Fang, and S. Russell, “Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 4213–4220
2019
-
[49]
Monotonic value function factorisation for deep multi-agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foer- ster, and S. Whiteson, “Monotonic value function factorisation for deep multi-agent reinforcement learning,” Journal of Ma- chine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
2020
-
[50]
Qtran: Learning to factorize with transformation for coop- erative multi-agent reinforcement learning,
K. Son, D. Kim, W. J. Kang, D. E. Hostallero, and Y. Yi, “Qtran: Learning to factorize with transformation for coop- erative multi-agent reinforcement learning,” in International conference on machine learning. PMLR, 2019, pp. 5887–5896
2019
-
[51]
Mean field multi-agent reinforcement learning,
Y. Yang, R. Luo, M. Li, M. Zhou, W. Zhang, and J. Wang, “Mean field multi-agent reinforcement learning,” in Interna- tional conference on machine learning. PMLR, 2018, pp. 5571– 5580
2018
-
[52]
Multidepot drone path planning with collision avoidance,
K. Shen, R. Shivgan, J. Medina, Z. Dong, and R. Rojas-Cessa, “Multidepot drone path planning with collision avoidance,” IEEE Internet of Things Journal, vol. 9, no. 17, pp. 16 297– 16 307, 2022
2022
-
[53]
Drone networks: Communications, coordina- tion, and sensing,
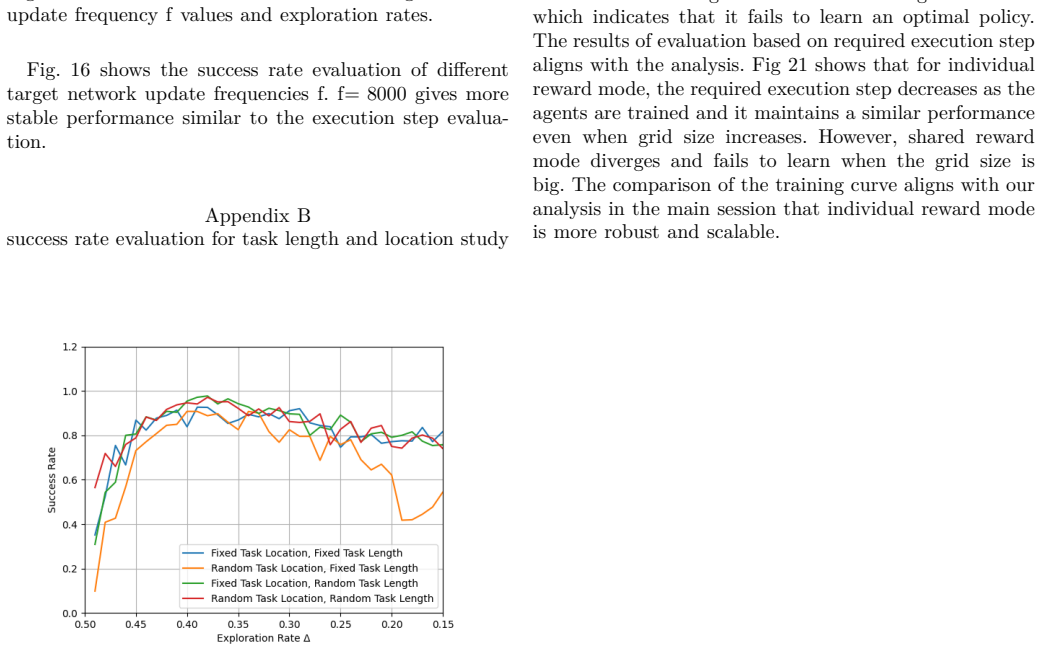
E. Yanmaz, S. Yahyanejad, B. Rinner, H. Hellwagner, and C. Bettstetter, “Drone networks: Communications, coordina- tion, and sensing,” Ad Hoc Networks, vol. 68, pp. 1–15, 2018. IEEE INTERNET OF THINGS JOURNAL. 13 Appendix A success rate evaluation for parameter study Fig. 16: The success rate under different target network update frequency f values and ex...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.