AgentIR: A Workload-Adaptive Cascade Retrieval Substrate for Long-Term Conversational Memory
Pith reviewed 2026-06-29 23:39 UTC · model grok-4.3
The pith
A BM25-margin cascade router skips dense retrieval on most conversational queries without losing accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
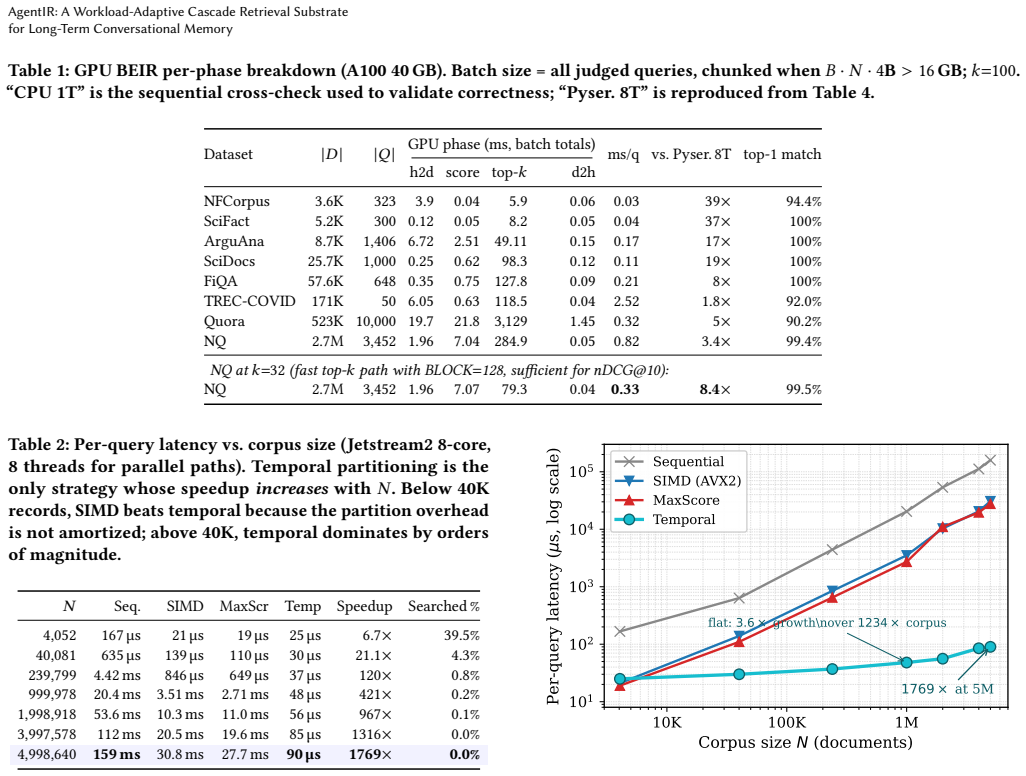
The central claim is that a confidence-triggered cascade router, driven solely by the BM25 top-k margin, can decide per query whether the dense retrieval channel is worth running, and that a time-partitioned index performs O(log 1/epsilon) work independent of corpus size, together yielding large speedups at parity quality on conversational and BEIR benchmarks.
What carries the argument
The confidence-triggered cascade router that uses the BM25 top-k margin as the sole signal to decide whether to invoke the dense channel or apply a particular fusion method.
If this is right
- On LongMemEval the cascade skips 63% of queries at parity accuracy for 2.67x speedup.
- On LoCoMo it reaches 100% skip rate for 132x speedup and higher Hit@5.
- The time-partitioned index sustains sub-100us latency even as the corpus grows 1234x.
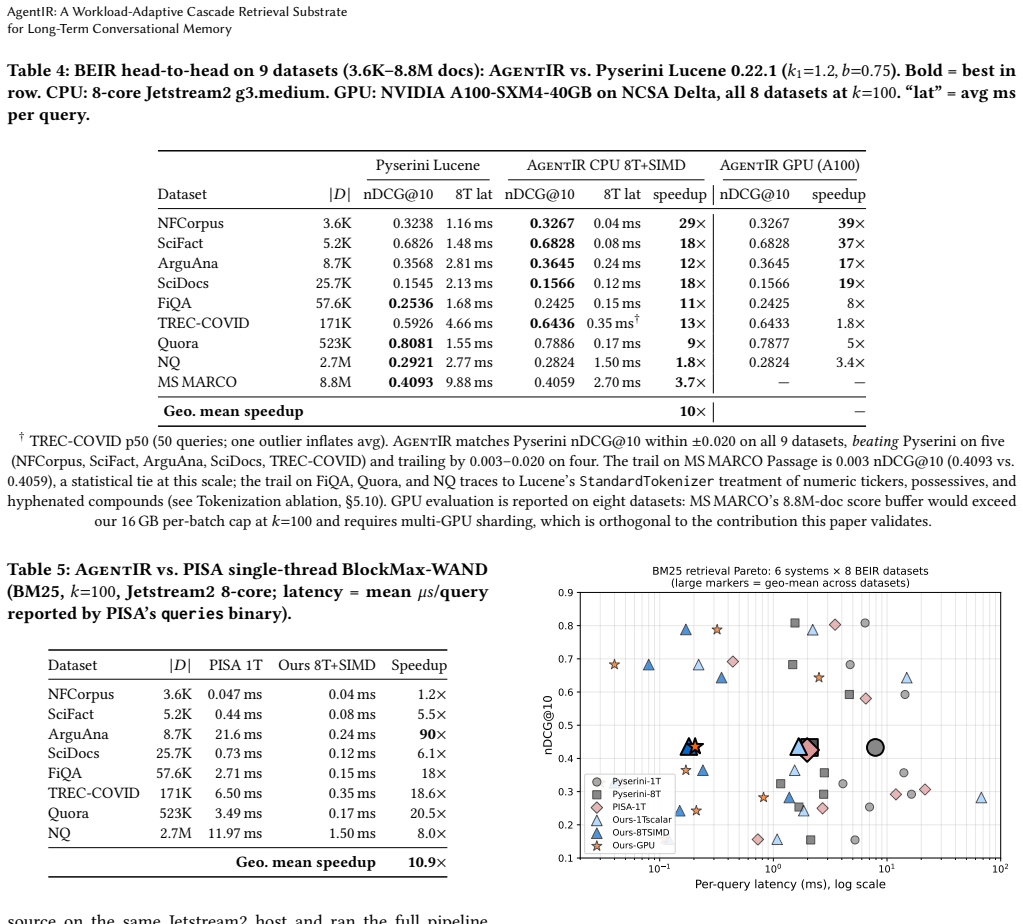
- It achieves 10-11x geo-mean speedup over Pyserini and PISA at parity quality on BEIR datasets.
- Capacity rises from 154 to 1400 concurrent agents on the same hardware.
Where Pith is reading between the lines
- This approach could allow agent systems to maintain much longer conversation histories without proportional increases in retrieval cost.
- The router's workload-adaptive behavior suggests it may generalize to other hybrid retrieval settings where one channel is significantly more expensive.
- Fixing the documented BM25/GPU pitfalls enables reliable comparison between CPU and GPU implementations at high precision.
- If the margin statistic proves robust, it removes the need for learned routers in many cascade setups.
Load-bearing premise
The BM25 top-k margin alone provides enough information to decide whether the dense channel will improve retrieval quality for that query.
What would settle it
Measuring LLM-judged accuracy on a held-out conversational workload where the cascade's skip decisions produce lower accuracy than always running both channels.
Figures







read the original abstract
Long-term conversational memory is a retrieval workload classical IR was not built for: the index grows during the query stream, query types shift intra-session, and the latency budget per retrieval is sub-10 ms. Lucene-class engines treat the index as static and the query as stateless, leaving the workload's structure unexploited. AgentIR treats fusion as a per-query decision along two axes: which fusion to apply (BM25, Dense, RRF, or agent-aware RRF), and whether the ~52 ms dense channel is worth running at all. The second axis is a confidence-triggered cascade router that decides from the BM25 top-k margin alone and re-tunes across workloads without retraining. On LongMemEval (n=500), where the dense channel does add information, the cascade skips 63% of queries at parity LLM-judged accuracy (2.67x faster under two judges, paired bootstrap p>=0.88); per-qtype thresholds extend this to 5.76x under 5-fold cross-validation. On LoCoMo (n=1,982), where BM25 alone is already the strongest single system, the same trigger auto-tunes to a 100% skip rate (132x faster, +0.089 Hit@5). Capacity on a shared 8-core VM rises from ~154 to ~1,400 concurrent agents (9x). Underneath the cascade, a time-partitioned index does O(log 1/epsilon) work independent of corpus size: 1234x corpus growth costs only 3.6x latency, ending in 1769x over sequential at sub-100 us p50 on 5M records. At parity quality with Lucene on 9 BEIR datasets up to 8.8M docs, the substrate runs 10x geo-mean over Pyserini 8T and 11x over PISA-1T BlockMax-WAND; an A100 reaches 1.8-39x over Pyserini 8T; chunked index build sustains 56.8K docs/sec on MS MARCO. Three subtle BM25/GPU correctness pitfalls that silently regress nDCG@10 by 6-8x are documented and fixed; post-fix CPU and GPU agree within 0.0002 nDCG@10 on all eight datasets that fit a single A100.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AgentIR, a retrieval substrate for long-term conversational memory that treats fusion as a per-query decision via a confidence-triggered cascade router using only the BM25 top-k margin to decide whether to run the dense channel (skipping it when possible) and a time-partitioned index achieving O(log 1/epsilon) work independent of corpus size. It reports empirical results including 63% query skips at LLM-judged accuracy parity (2.67x faster) on LongMemEval, 100% skips (132x faster) on LoCoMo, 10-11x geo-mean speedup over Pyserini/PISA at parity on BEIR, capacity gains to 1400 concurrent agents, and fixes for three BM25/GPU correctness issues that previously regressed nDCG@10 by 6-8x.
Significance. If the central routing claim holds, the work would be significant for IR in dynamic conversational settings by exploiting workload structure (growing index, intra-session shifts) without retraining. The explicit documentation and correction of BM25 implementation pitfalls, plus reproducible speedups on named datasets (LongMemEval, LoCoMo, BEIR), are strengths. The time-partitioned index scaling result is also noteworthy if the independence from corpus size is rigorously shown.
major comments (2)
- [Abstract / cascade router description] Abstract and cascade router section: The claim that the BM25 top-k margin alone is a sufficient statistic for the router (enabling workload-adaptive thresholds without retraining or additional features) is load-bearing for the 63%/100% skip rates at parity, yet the manuscript provides no ablation correlating margin with dense-channel accuracy gain or testing generalization beyond the reported 5-fold CV on these fixed datasets.
- [Abstract / evaluation sections] Results on LongMemEval and LoCoMo: The parity accuracy claims and skip-rate speedups lack error bars, explicit threshold selection procedure details, or sensitivity analysis on the margin threshold; this directly affects assessment of whether the reported 2.67x/132x factors and p>=0.88 are robust.
minor comments (2)
- [Index construction section] The time-partitioned index claim of O(log 1/epsilon) work should include the explicit definition of epsilon and the partitioning scheme to support the 1234x growth to 3.6x latency result.
- [Throughout] Minor notation inconsistency: ensure consistent use of 'margin' vs. 'top-k margin' when describing the router input across sections.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the potential significance of the workload-adaptive routing and scaling results. We address each major comment below and will incorporate revisions to strengthen the empirical support for the central claims.
read point-by-point responses
-
Referee: [Abstract / cascade router description] Abstract and cascade router section: The claim that the BM25 top-k margin alone is a sufficient statistic for the router (enabling workload-adaptive thresholds without retraining or additional features) is load-bearing for the 63%/100% skip rates at parity, yet the manuscript provides no ablation correlating margin with dense-channel accuracy gain or testing generalization beyond the reported 5-fold CV on these fixed datasets.
Authors: We agree that an explicit ablation correlating the BM25 top-k margin with the incremental accuracy gain from the dense channel would provide stronger evidence for the sufficiency claim. In the revised manuscript we will add this analysis on both LongMemEval and LoCoMo, including quantitative correlation measures and visualizations of margin versus dense-channel contribution. The existing 5-fold CV already tests generalization across query types within each dataset, but the new ablation will directly address the referee's concern about the margin as a standalone statistic. revision: yes
-
Referee: [Abstract / evaluation sections] Results on LongMemEval and LoCoMo: The parity accuracy claims and skip-rate speedups lack error bars, explicit threshold selection procedure details, or sensitivity analysis on the margin threshold; this directly affects assessment of whether the reported 2.67x/132x factors and p>=0.88 are robust.
Authors: We will revise the evaluation sections to include error bars obtained from the 5-fold cross-validation and paired bootstrap resampling. Explicit details on the threshold selection procedure (including how per-query-type thresholds are derived from the CV folds) will be added to the cascade router section. A sensitivity analysis sweeping the margin threshold will also be included to demonstrate the robustness of the reported skip rates, speedups, and accuracy parity (p>=0.88). revision: yes
Circularity Check
No circularity; all central claims are empirical measurements on fixed external datasets
full rationale
The paper reports measured skip rates (63% on LongMemEval, 100% on LoCoMo), speedups (2.67x–132x), and quality parity via LLM judges and nDCG@10 on BEIR, all obtained by running the system on held-out query streams and corpora. The cascade router is tuned via 5-fold CV on the same fixed datasets and the time-partitioned index latency scaling is measured directly; none of these quantities are derived from parameters fitted inside the same equations or reduced by construction to the inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The derivation chain consists of workload-specific empirical evaluation against external baselines (Pyserini, PISA) and is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- BM25-margin confidence threshold
axioms (1)
- domain assumption BM25 top-k margin is a reliable proxy for whether dense retrieval adds information on the target workloads
Reference graph
Works this paper leans on
-
[1]
Sebastian Bruch, Siyu Gai, and Amir Ingber. 2023. An Analysis of Fusion Func- tions for Hybrid Retrieval.ACM Transactions on Information Systems42, 1 (2023), 1–35
2023
-
[2]
Jorge, and Adam Jatowt
Ricardo Campos, Gaël Dias, Alípio M. Jorge, and Adam Jatowt. 2014. Survey of Temporal Information Retrieval and Related Applications.Comput. Surveys47, 2 (2014)
2014
-
[3]
Shane Culpepper
Ruey-Cheng Chen, Luke Gallagher, Roi Blanco, and J. Shane Culpepper. 2017. Efficient cost-aware cascade ranking in multi-stage retrieval. InProceedings of SIGIR. 445–454
2017
-
[4]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
-
[5]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint arXiv:2504.19413(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Cormack, Charles L
Gordon V. Cormack, Charles L. A. Clarke, and Stefan Buettcher. 2009. Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods. In Proceedings of SIGIR. 758–759
2009
-
[7]
Shuai Ding, Jinru He, Hao Yan, and Torsten Suel. 2009. Using Graphics Processors for High Performance IR Query Processing. InProceedings of WWW. 421–430
2009
-
[8]
Shuai Ding and Torsten Suel. 2011. Faster Top- 𝑘 Document Retrieval Using Block-Max Indexes. InProceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. 993–1002
2011
-
[9]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceedings of SIGIR
2021
-
[10]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2021. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3 (2021), 535–547
2021
-
[11]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of EMNLP. 6769–6781
2020
-
[12]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of SIGIR
2020
-
[13]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, Vol. 33
2020
-
[14]
Bruce Croft
Xiaoyan Li and W. Bruce Croft. 2003. Time-Based Language Models. InProceed- ings of CIKM. 469–475
2003
- [15]
-
[16]
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini: A Python Toolkit for Reproducible Infor- mation Retrieval Research with Sparse and Dense Representations. InProceedings of SIGIR
2021
-
[17]
Yang Liu, Jianguo Wang, and Steven Swanson. 2018. Griffin: Uniting CPU and GPU in Information Retrieval Systems for Intra-Query Parallelism. InProceedings of the IEEE International Conference on Data Engineering (ICDE)
2018
-
[18]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of ACL
2024
-
[19]
Malkov and Dmitry A
Yury A. Malkov and Dmitry A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.IEEE Transactions on Pattern Analysis and Machine Intelligence42, 4 (2020), 824–836
2020
-
[20]
Antonio Mallia, Michal Siedlaczek, Joel Mackenzie, and Torsten Suel. 2019. PISA: Performant Indexes and Search for Academia. InProceedings of OSIRRC@SIGIR
2019
-
[21]
Antonio Mallia, Michal Siedlaczek, Torsten Suel, and Mohamed Zahran. 2019. GPU-Accelerated Decoding of Integer Lists. InProceedings of CIKM. 2193–2196
2019
-
[22]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. InProceedings of the Workshop on Cognitive Computation
2016
-
[23]
1993.Usability Engineering
Jakob Nielsen. 1993.Usability Engineering. Morgan Kaufmann. Defines the 100 ms (instant) and 1 s (interactive) latency thresholds for human-perceived responsiveness
1993
-
[24]
Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, and Yong Wang. 2024. CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs. InProceedings of ICDE
2024
-
[25]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. MemGPT: Towards LLMs as Operating Systems. InProceedings of ICLR
2024
-
[26]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of UIST
2023
-
[27]
Pinecone Systems. 2026. Pinecone Serverless Pricing. https://www.pinecone.io/ pricing/. List price for read units as of 2026-Q1; accessed 2026-05
2026
-
[28]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Foundations and Trends in Information Retrieval3, 4 (2009), 333–389
2009
-
[29]
Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford
Stephen E. Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford. 1994. Okapi at TREC-3. InProceedings of the Third Text REtrieval Conference (TREC-3)
1994
-
[30]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. InProceedings of NAACL
2022
-
[31]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems, Vol. 36
2023
-
[32]
Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L
Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L. Griffiths
-
[33]
Cognitive Architectures for Language Agents.Transactions on Machine Learning Research(2024)
2024
-
[34]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InProceedings of NeurIPS Datasets and Bench- marks
2021
-
[35]
Howard Turtle and James Flood. 1995. Query evaluation: strategies and optimiza- tions.Information Processing & Management31, 6 (1995), 831–850. Introduces the MaxScore dynamic pruning strategy used by later WAND / BlockMax-WAND systems. AgentIR: A Workload-Adaptive Cascade Retrieval Substrate for Long-Term Conversational Memory
1995
-
[36]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A Purpose-Built Vector Data Management System. InProceedings of SIGMOD. 2614–2627. Reports millisecond-scale p99 latency on hundred-million-vector corpora
2021
-
[37]
Lidan Wang, Jimmy Lin, and Donald Metzler. 2011. A cascade ranking model for efficient ranked retrieval. InProceedings of SIGIR. 105–114
2011
-
[38]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu
-
[39]
InProceedings of ICLR
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InProceedings of ICLR
-
[40]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2024. C-Pack: Packed Resources For General Chinese Embeddings. InProceedings of SIGIR
2024
-
[41]
Peilin Yang, Hui Fang, and Jimmy Lin. 2017. Anserini: Enabling the Use of Lucene for Information Retrieval Research. InProceedings of SIGIR. 1253–1256
2017
-
[42]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of ICLR
2023
-
[43]
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2024. A Survey on the Memory Mechanism of Large Language Model based Agents.ACM Transactions on Information Systems (2024). Aojie Yuan, Haiyue Zhang, and Shahin Nazarian A Detailed Experimental Results This appendix provides complete numerical results ...
-
[44]
Collect ∼50 labeled deployment questions (Q, A, gold- session-id)
-
[45]
Run all 4 base systems (BM25, Dense, RRF, agent_rrf) on each Q; compute per-qtype LLM-Acc with your judge of choice
-
[46]
Pick the per-qtype best system 𝑠∗ (𝑞𝑡) ; this is your per- type routing table (Table 18-style)
-
[47]
For each qtype, sweep 𝜏𝑐 ∈ [ 0, 1] and pick the max value with within-noise per-qtype LLM-Acc; this gives 𝜏𝑐 [𝑞𝑡]
-
[48]
Train a TF-IDF (or TF-IDF +BGE) classifier over the 50 labels using sklearn.linear_model.LogisticRegression
-
[49]
AAPL”) or percentages (“401(k)
Plug all four into CascadeRouter::Config; you now have a per-tenant tuned cascade. Re-tune quarterly or on drift detection. Aojie Yuan, Haiyue Zhang, and Shahin Nazarian J.12 Reproduction CLI # Build the C++ benchmark (CPU only, 8-core x86) cmake -B build -DENABLE_AVX2=ON -DENABLE_CUDA=OFF cmake --build build -j # Run cascade on LongMemEval (Python orches...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.