Toward Native Multimodal Modeling: A Roadmap
Pith reviewed 2026-06-29 22:56 UTC · model grok-4.3
The pith
Native multimodal modeling integrates modalities intrinsically within a unified transformer for superior performance over late-fusion methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Native multimodal modeling with the intrinsic integration of modalities achieves superior multimodal performance compared to late-fusion approaches, enabling understanding and generation to coexist within a unified transformer paradigm.
What carries the argument
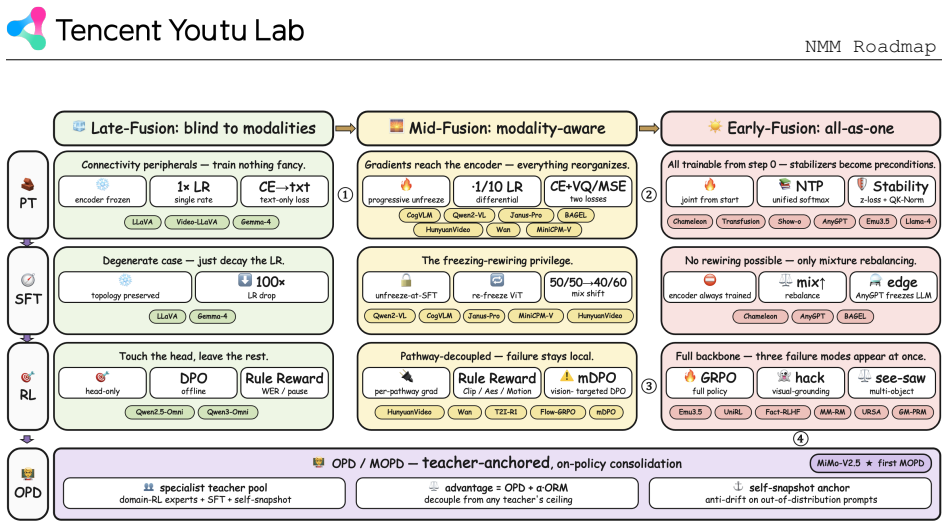
The formal definition of architectural nativity that distinguishes mid-fusion and early-fusion from non-native paradigms, together with the organization of models by input-output duality into the three categories Multi-to-Text, Multi-to-Target, and Multi-to-Multi.
If this is right
- A single transformer architecture can handle both cross-modal comprehension and scenario-oriented generation without separate output heads.
- Industrial-scale native models require coordinated design across data curation, full-stack training, and deployment rather than modular assembly.
- Evaluation must shift from isolated modality tasks to unified tests that measure seamless understanding-generation coexistence.
- Reorganizing prior models under the input-output lens reveals gaps that future native designs can target.
Where Pith is reading between the lines
- The roadmap's emphasis on early integration may reduce reliance on frozen unimodal encoders in large-scale systems.
- If the three categories prove exhaustive, they could serve as a template for standardizing multimodal system taxonomies beyond this paper.
- The transition described could connect to broader world-modeling goals by making generation and perception native to the same parameters.
Load-bearing premise
The proposed distinctions between mid-fusion, early-fusion, and non-native paradigms, along with the three input-output categories, sufficiently define and cover the design space of native architectures.
What would settle it
A controlled experiment in which a well-tuned late-fusion model matches or exceeds native models across a broad suite of multimodal understanding and generation benchmarks would falsify the claimed superiority.
Figures




read the original abstract
Multimodal modeling represents a vital step from modality-agnostic reasoning toward world modeling. While early approaches predominantly rely on late-fusion that assembles encoders and frozen language backbones with output heads, recent efforts have shifted the paradigm toward native multimodal modeling (NMM) with the intrinsic integration of modalities for superior multimodal performance. Despite its potential, the design space of native architectures remains insufficiently defined. In this paper, we present the community with a formalized roadmap for this transition. Specifically, we formally define the architectural nativity, distinguishing mid-fusion and early-fusion from non-native paradigms. We further organize the existing native models through the lens of input-output duality into three categories: (i) Multi-to-Text for cross-modal comprehension with text-only output; (ii) Multi-to-Target for scenario-oriented generation, e.g., image, audio and video generation, and (iii) Multi-to-Multi for unified modeling with symmetric input-output. We deliver a comprehensive and industrial-grade investigation into the transition toward the definitive NMM framework, where understanding and generation seamlessly coexist within a unified transformer paradigm. We systematically unpack the end-to-end pipeline from industrial perspectives from architectural coordination, massive data curation, to full-stack training recipes, inference & deployment, and the comprehensive evaluation for truly native modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide a formalized roadmap for transitioning to native multimodal modeling (NMM), which features intrinsic integration of modalities in unified transformers. It defines architectural nativity by distinguishing mid-fusion and early-fusion from non-native late-fusion paradigms, organizes existing models into three input-output categories (Multi-to-Text, Multi-to-Target, Multi-to-Multi), and unpacks an end-to-end industrial pipeline covering architecture coordination, data curation, training recipes, inference, deployment, and evaluation, with the goal of enabling coexisting understanding and generation.
Significance. If the definitions and categorization hold, the roadmap could help standardize terminology and guide development of intrinsically integrated multimodal systems beyond late-fusion baselines. The industrial pipeline discussion adds practical value for scaling such models, though the motivating claim of superior performance remains unsubstantiated within the manuscript itself.
major comments (2)
- [Abstract] Abstract: The assertion that recent efforts have shifted toward NMM 'with the intrinsic integration of modalities for superior multimodal performance' is presented as a premise without new empirical results, meta-analysis, or specific quantitative comparisons to late-fusion baselines; this is load-bearing for motivating the entire roadmap.
- [Section on input-output categories] Section on input-output categories: The claim that the three categories (Multi-to-Text, Multi-to-Target, Multi-to-Multi) via input-output duality sufficiently organize and cover the design space of native architectures lacks explicit mapping criteria, boundary cases, or demonstration of exhaustiveness, which directly affects the roadmap's claimed comprehensiveness.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our roadmap manuscript. Below we address each major comment point by point, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that recent efforts have shifted toward NMM 'with the intrinsic integration of modalities for superior multimodal performance' is presented as a premise without new empirical results, meta-analysis, or specific quantitative comparisons to late-fusion baselines; this is load-bearing for motivating the entire roadmap.
Authors: We acknowledge that the manuscript is a roadmap paper and does not contain new empirical results or meta-analyses comparing NMM to late-fusion approaches. The statement in the abstract reflects an observed trend in the literature we cite rather than a claim supported by new data within this work. To address the concern, we will revise the abstract to describe the shift as an emerging architectural direction without asserting unsubstantiated superiority, and we will add a clarifying sentence in the introduction noting that the roadmap is motivated by design trends rather than proven performance gains. revision: partial
-
Referee: [Section on input-output categories] Section on input-output categories: The claim that the three categories (Multi-to-Text, Multi-to-Target, Multi-to-Multi) via input-output duality sufficiently organize and cover the design space of native architectures lacks explicit mapping criteria, boundary cases, or demonstration of exhaustiveness, which directly affects the roadmap's claimed comprehensiveness.
Authors: We agree that the current presentation would benefit from greater explicitness. In the revised manuscript we will expand the relevant section to define explicit mapping criteria based on input-output modality combinations, include a discussion of boundary cases (e.g., models that straddle categories or hybrid designs), and provide a brief argument for exhaustiveness by illustrating how representative architectures map to the three categories. A summary table will be added to improve clarity and demonstrate coverage. revision: yes
Circularity Check
No circularity: roadmap defines categories and organizes models without derivations or self-referential reductions
full rationale
The paper is a definitional roadmap that introduces architectural nativity distinctions (mid-fusion/early-fusion vs non-native) and input-output categories (Multi-to-Text, Multi-to-Target, Multi-to-Multi) to organize existing work. It asserts superiority of native multimodal modeling based on 'recent efforts' but supplies no equations, fitted parameters, uniqueness theorems, or self-citation chains that reduce any claim to its own inputs by construction. The distinctions function as an organizing framework rather than a derived result; the central premise remains a motivating premise external to any internal reduction. No load-bearing circular steps exist.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
LLM can Read Spectrogram: Encoder-free Speech-Language Modeling
Mel-LLM shows that LLMs can process Mel spectrograms directly for competitive ASR performance without a dedicated speech encoder, with limited degradation versus encoder-based versions when using multimodal initializa...
Reference graph
Works this paper leans on
-
[1]
Junru Lu, Jiarui Qin, Lingfeng Qiao, Yinghui Li, Xinyi Dai, Bo Ke, Jianfeng He, Ruizhi Qiao, Di Yin, Xing Sun, et al. Youtu-llm: Unlocking the native agentic potential for lightweight large language models.arXiv preprint arXiv:2512.24618, 2025
-
[2]
Junnan Dong, Zijin Hong, Yuanchen Bei, Feiran Huang, Xinrun Wang, and Xiao Huang. Clr-bench: Evaluating large language models in college-level reasoning.arXiv preprint arXiv:2410.17558, 2024
-
[3]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Qwen Team. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 33 NMM Roadmap
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Beyond language modeling: An exploration of multimodal pretraining
Shengbang Tong, David Fan, John Nguyen, Ellis Brown, Gaoyue Zhou, Shengyi Qian, Boyang Zheng, Théophane Vallaeys, Junlin Han, Rob Fergus, et al. Beyond language modeling: An exploration of multimodal pretraining. arXiv preprint arXiv:2603.03276, 2026
-
[7]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
The revolution of multimodal large language models: A survey.Findings of the association for computational linguistics: ACL 2024, pages 13590–13618, 2024
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. The revolution of multimodal large language models: A survey.Findings of the association for computational linguistics: ACL 2024, pages 13590–13618, 2024
2024
-
[9]
A survey on multimodal large language models.National Science Review, 11, 2023
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11, 2023
2023
-
[10]
Modality-aware integration with large language models for knowledge-based visual question answering
Junnan Dong, Qinggang Zhang, Huachi Zhou, Daochen Zha, Pai Zheng, and Xiao Huang. Modality-aware integration with large language models for knowledge-based visual question answering. InACL, pages 2417– 2429, 2024
2024
-
[12]
Emu3.5: Native Multimodal Models are World Learners
Yufeng Cui, Honghao Chen, Haoge Deng, Xu Huang, Xinghang Li, Jirong Liu, Yang Liu, Zhuoyan Luo, Jinsheng Wang, Wenxuan Wang, Yueze Wang, Chengyuan Wang, Fan Zhang, Yingli Zhao, Ting Pan, Xianduo Li, Zecheng Hao, Wenxuan Ma, Zhuo Chen, Yulong Ao, Tiejun Huang, Zhongyuan Wang, and Xinlong Wang. Emu3.5: Native multimodal models are world learners.arXiv prepr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava-video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhu- oshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Danial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Arushi Goel, et al. Nemotron 3 nano omni: Efficient and open multimodal intelligence.arXiv preprint arXiv:2604.24954, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Mimo-v2.5: Frontier agency and native multimodality, 2026
Xiaomi MiMo Team. Mimo-v2.5: Frontier agency and native multimodality, 2026. Accessed: 2026-04-29
2026
-
[19]
Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026. URL https://qwen. ai/blog?id=qwen3.6-35b-a3b
2026
-
[20]
Gemma 4: Intelligence-per-parameter for advanced reasoning
Google DeepMind. Gemma 4: Intelligence-per-parameter for advanced reasoning. https://ai.google. dev/gemma/docs/core/model_card_4, 2026
2026
-
[21]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, et al. Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Glm-5v-turbo: Toward a native foundation model for multimodal agents
Wenyi Hong, Xiaotao Gu, Ziyang Pan, Zhen Yang, Yuting Wang, Yue Wang, Yuanchang Yue, Yu Wang, Yanling Wang, Yan Wang, et al. Glm-5v-turbo: Toward a native foundation model for multimodal agents. Technical report, ZhipuAI, 2026. 34 NMM Roadmap
2026
-
[23]
The Llama 4 herd: Architecture, training, evaluation, and deployment notes
Aaron Adcock, Aayushi Srivastava, Abhimanyu Dubey, et al. The Llama 4 herd: Architecture, training, evaluation, and deployment notes. Technical report, Meta AI, 2025. Includes Scout and Maverick series
2025
-
[24]
Qwen Team. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
CogVLM: Visual Expert for Pretrained Language Models
Weihan Wang et al. CogVLM: Visual expert for pretrained language models.arXiv preprint arXiv:2311.03079, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection.arXiv preprint arXiv:2311.10122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Qi Cai, Jingwen Chen, Chengmin Gao, Zijian Gong, Yehao Li, Tao Mei, Yingwei Pan, Yi Peng, Zhaofan Qiu, Ting Yao, Kai Yu, Yiheng Zhang, et al. Hidream-o1-image: A natively unified image generative foundation model with pixel-level unified transformer.arXiv preprint arXiv:2605.11061, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, V...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Inclusion AI. Ming-flash-omni: A sparse, unified architecture for multimodal perception and generation.arXiv preprint arXiv:2510.24821, 2026
-
[32]
MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction
Junbo Cui, Bokai Xu, Chongyi Wang, Tianyu Yu, Weiyue Sun, Yingjing Xu, Tianran Wang, Zhihui He, Wenshuo Ma, Tianchi Cai, et al. Minicpm-o 4.5: Towards real-time full-duplex omni-modal interaction.arXiv preprint arXiv:2604.27393, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Kling Team. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Wan 2.2: A high-fidelity video generation foundation model, 2025
Wan Team. Wan 2.2: A high-fidelity video generation foundation model, 2025
2025
-
[37]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, Wei Liu, Yichun Shi, Shiqi Sun, Yu Tian, Zhi Tian, Peng Wang, Rui Wang, Xuanda Wang, Xun Wang, Ye Wang, Guofeng Wu, Jie Wu, Xin Xia, Xuefeng Xiao, Zhonghua Zhai, Xinyu Zhang, Qi Zhang, Yuwei Zhang, Shijia Zhao, Jianchao Yang, and Weilin Hu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Lance: Unified Multimodal Modeling by Multi-Task Synergy
Fengyi Fu, Mengqi Huang, Shaojin Wu, Yunsheng Jiang, Yufei Huo, Hao Li, Yinghang Song, Fei Ding, Jianzhu Guo, Qian He, Zheren Fu, Zhendong Mao, and Yongdong Zhang. Lance: Unified multimodal modeling by multi-task synergy.arXiv preprint arXiv:2605.18678, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
Yangming Shi, Shixiang Zhu, Tao Shen, Zhimiao Yu, Dengsheng Chen, Taicai Chen, Yunfei Yang, Juan Zhou, Chen Cheng, Liang Ma, Xibin Wu, Benxuan Yan, Ge Li, Tuoyu Zhang, Dan Li, Chang Liu, and Zhenbang Sun. Mamoda2.5: Enhancing unified multimodal model with dit-moe.arXiv preprint arXiv:2605.02641, 2026. 35 NMM Roadmap
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Zhiheng Liu, Weiming Ren, Xiaoke Huang, Shoufa Chen, Tianhong Li, Mengzhao Chen, Yatai Ji, Sen He, Jonas Schult, Belinda Zeng, Tao Xiang, Wenhu Chen, Ping Luo, Luke Zettlemoyer, and Yuren Cong. Tuna-2: Pixel embeddings beat vision encoders for multimodal understanding and generation.arXiv preprint arXiv:2604.24763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
Haiwen Diao, Penghao Wu, Hanming Deng, Jiahao Wang, Shihao Bai, Silei Wu, Weichen Fan, Wenjie Ye, Wenwen Tong, Xiangyu Fan, et al. Sensenova-u1: Unifying multimodal understanding and generation with neo-unify architecture.arXiv preprint arXiv:2605.12500, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Inclusion AI. Llada2.0-uni: Unifying multimodal understanding and generation with diffusion large language model.arXiv preprint arXiv:2604.20796, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Longcat-next: Lexicalizing modalities as discrete tokens.arXiv preprint arXiv:2603.27538, 2026
Meituan LongCat Team, Bin Xiao, Chao Wang, Chengjiang Li, Chi Zhang, Chong Peng, Hang Yu, Hao Yang, Haonan Yan, Haoze Sun, et al. Longcat-next: Lexicalizing modalities as discrete tokens.arXiv preprint arXiv:2603.27538, 2026
-
[44]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models. arXiv preprint arXiv:2506.15564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Han Li, Xinyu Peng, Yaoming Wang, Zelin Peng, Xin Chen, Rongxiang Weng, Jingang Wang, Xunliang Cai, Wenrui Dai, and Hongkai Xiong. Onecat: Decoder-only auto-regressive model for unified understanding and generation.arXiv preprint arXiv:2509.03498, 2025
-
[47]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
DeepSeek-AI. Janus-Pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team, Meta AI. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Anygpt: Unified multimodal llm with discrete sequence modeling.arXiv preprint arXiv:2402.12226, 2025
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, Hang Yan, Jie Fu, Tao Gui, Tianxiang Sun, Yu-Gang Jiang, and Xipeng Qiu. Anygpt: Unified multimodal llm with discrete sequence modeling.arXiv preprint arXiv:2402.12226, 2025
-
[52]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
Han Zhu, Lingxuan Ye, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhifeng Han, Weiji Zhuang, Long Lin, and Daniel Povey. Omnivoice: Towards omnilingual zero-shot text-to-speech with diffusion language models.arXiv preprint arXiv:2604.00688, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, et al. Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model.arXiv preprint arXiv:2401.16420, 2024. 36 NMM Roadmap
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling
Keming Wu, Zuhao Yang, Kaichen Zhang, Shizun Wang, Haowei Zhu, Sicong Leng, Zhongyu Yang, Qijie Wang, Sudong Wang, Ziting Wang, Zili Wang, Hui Zhang, Haonan Wang, Hang Zhou, Yifan Pu, Xingxuan Li, Fangneng Zhan, Bo Li, Lidong Bing, Yuxin Song, Ziwei Liu, Wenhu Chen, Jingdong Wang, Xinchao Wang, Xiaojuan Qi, Shijian Lu, and Bin Wang. Visual generation in t...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. Better & faster large language models via multi-token prediction.arXiv preprint arXiv:2404.19737, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot.arXiv preprint arXiv:2412.02612, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational Conference on Machine Learning, 2022
2022
-
[61]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[62]
Zhifei Xie, Ziyang Ma, Zihang Liu, Kaiyu Pang, Hongyu Li, Jialin Zhang, Yue Liao, Deheng Ye, Chunyan Miao, and Shuicheng Yan. Mini-omni-reasoner: Token-level thinking-in-speaking in large speech models.arXiv preprint arXiv:2508.15827, 2025
-
[63]
Minh-Quan Le, Yuanzhi Zhu, Vicky Kalogeiton, and Dimitris Samaras. What about gravity in video generation? post-training newton’s laws with verifiable rewards.arXiv preprint arXiv:2512.00425, 2025
-
[64]
Physrvg: Physics-aware unified reinforcement learning for video generative models
Qiyuan Zhang, Biao Gong, Shuai Tan, Zheng Zhang, Yujun Shen, Xing Zhu, Yuyuan Li, Kelu Yao, Chunhua Shen, and Changqing Zou. Physrvg: Physics-aware unified reinforcement learning for video generative models. arXiv preprint arXiv:2601.11087, 2026
-
[65]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. In International Conference on Learning Representations, volume 2025, pages 28085–28128, 2025
2025
-
[66]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[68]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022
2022
-
[69]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[70]
Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022. 37 NMM Roadmap
2022
-
[71]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[72]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. InProceedings of ACL, 2018
2018
-
[73]
Yfcc100m: The new data in multimedia research.Communications of the ACM, 59(2):64–73, 2016
Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. Yfcc100m: The new data in multimedia research.Communications of the ACM, 59(2):64–73, 2016
2016
-
[74]
Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36:27092–27112, 2023
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36:27092–27112, 2023
2023
-
[75]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
2015
-
[76]
Gqa: A new dataset for real-world visual reasoning and com- positional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and com- positional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
2019
-
[77]
Ok-vqa: A visual question answering benchmark requiring external knowledge
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 3195–3204, 2019
2019
-
[78]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in neural information processing systems, 35:2507–2521, 2022
2022
-
[79]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.ArXiv, abs/2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Instructblip: Towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems, 36:49250–49267, 2023
2023
-
[81]
Multimodal c4: An open, billion-scale corpus of images interleaved with text.Advances in Neural Information Processing Systems, 36:8958–8974, 2023
Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, and Yejin Choi. Multimodal c4: An open, billion-scale corpus of images interleaved with text.Advances in Neural Information Processing Systems, 36:8958–8974, 2023
2023
-
[82]
Obelics: An open web-scale filtered dataset of interleaved image-text documents.Advances in Neural Information Processing Systems, 36:71683–71702, 2023
Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open web-scale filtered dataset of interleaved image-text documents.Advances in Neural Information Processing Systems, 36:71683–71702, 2023
2023
-
[83]
Omnicorpus: A unified multimodal corpus of 10 billion-level images interleaved with text
Qingyun Li, Zhe Chen, Weiyun Wang, Wenhai Wang, Shenglong Ye, Zhenjiang Jin, Guanzhou Chen, Yinan He, Zhangwei Gao, Erfei Cui, et al. Omnicorpus: A unified multimodal corpus of 10 billion-level images interleaved with text. InInternational Conference on Learning Representations, volume 2025, pages 13647–13689, 2025
2025
-
[84]
Gustavo Penha, Alexandru Balan, and Claudia Hauff. Introducing mantis: a novel multi-domain information seeking dialogues dataset.arXiv preprint arXiv:1912.04639, 2019
-
[85]
A corpus for reasoning about natural language grounded in photographs
Alane Suhr, Stephanie Zhou, Ally Zhang, Iris Zhang, Huajun Bai, and Yoav Artzi. A corpus for reasoning about natural language grounded in photographs. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 6418–6428, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.