ERNIE-Image Technical Report
Pith reviewed 2026-06-29 22:52 UTC · model grok-4.3
The pith
An 8B single-stream DiT text-to-image model closes much of the gap to commercial systems by using bottom-up data pipelines and stabilized DPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ERNIE-Image is built on an 8B single-stream DiT architecture. During pre-training a bottom-up data construction pipeline combines fine-grained image categorization, rich caption annotation, aesthetic assessment, and hierarchical sampling to reduce data noise while preserving long-tail concepts. In post-training a top-down pipeline diversifies prompt annotations and applies stabilized DPO to align outputs with human aesthetic preferences. The model is further equipped with ERNIE-Image-Turbo for 8-NFE generation using MT-DMD to limit capability drift, a lightweight Prompt Enhancer, and ERNIE-Image-Aes together with the ERNIE-Image-Aes-1K benchmark. Experiments indicate the resulting model lead
What carries the argument
The bottom-up data construction pipeline (fine-grained categorization, rich captioning, aesthetic assessment, hierarchical sampling) paired with stabilized DPO in post-training.
If this is right
- Open-source text-to-image models can approach commercial performance levels through data curation instead of model scaling.
- Hierarchical sampling preserves long-tail concepts that standard random sampling would discard.
- Stabilized DPO provides a practical route to align generation outputs with human aesthetic judgments after pre-training.
- An 8-NFE turbo variant can retain most quality while cutting inference cost when paired with drift mitigation.
- Dedicated aesthetic models and human-annotated benchmarks enable more reliable comparison than existing proxies.
Where Pith is reading between the lines
- The same bottom-up curation pattern could transfer to video or audio generation to reduce reliance on proprietary data.
- Releasing the aesthetic benchmark may encourage standardized evaluation across future open models.
- Prompt enhancers of this type could become standard tooling for turning short user intents into reliable generation inputs.
- If the gains prove robust, similar staged pipelines might reduce the need for ever-larger base models in other generative domains.
Load-bearing premise
The claimed gains in instruction following, text rendering, and aesthetic quality come from the described data pipelines and DPO rather than from evaluation differences or data overlap with test sets.
What would settle it
An independent test on a fresh prompt set that measures instruction adherence, text rendering accuracy, and aesthetic scores and finds no measurable edge over other open-source 8B models.
Figures


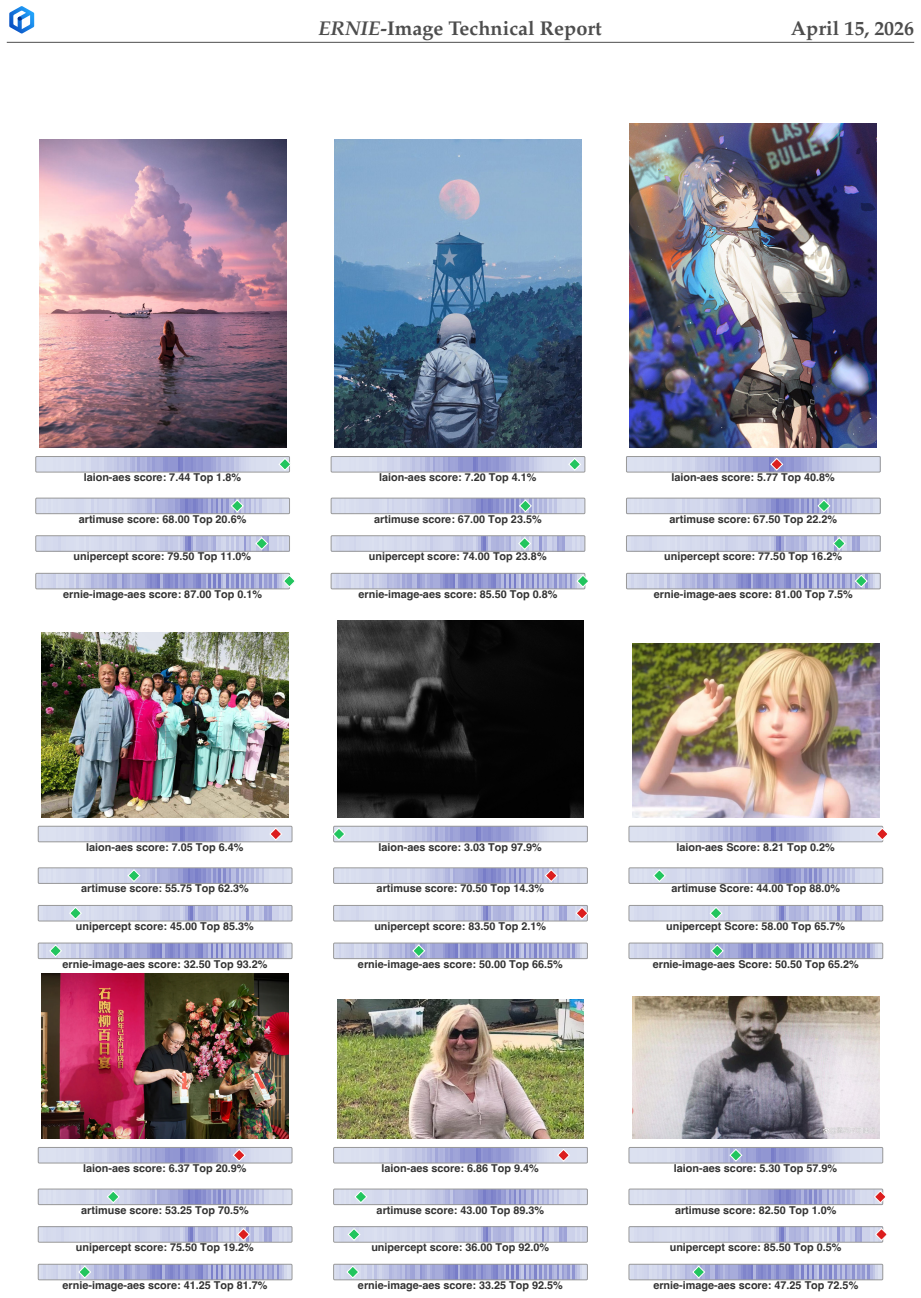






read the original abstract
We introduce ERNIE-Image, an open-source text-to-image generation model built upon an 8B single-stream DiT architecture. ERNIE-Image aims to bridge the gap between current open-source models and leading closed-source systems through more effective mining of large-scale pre-training data and improved supervision quality throughout training. During pre-training, we adopt a bottom-up data construction pipeline that combines fine-grained image categorization, rich caption annotation, aesthetic assessment, and hierarchical sampling. This strategy reduces data noise while preserving long-tail concepts and detailed real-world knowledge, providing a stronger foundation for complex generation tasks. In the post-training stage, we use a top-down data construction pipeline for high-demand scenarios, diversify prompt annotations to better match real user inputs, and apply a stabilized DPO strategy to align the model with human aesthetic preferences. We further train ERNIE-Image-Turbo for efficient 8-NFE generation and propose MT-DMD to mitigate capability drift during distillation. To make the model easier to use in practical scenarios, we equip it with a lightweight Prompt Enhancer that expands concise user intents into structured visual descriptions. In addition, we develop ERNIE-Image-Aes, an industrial-grade aesthetic model, together with ERNIE-Image-Aes-1K, a human-annotated benchmark for realistic aesthetic evaluation. Extensive qualitative and quantitative experiments show that ERNIE-Image achieves leading performance among open-source models and approaches top-tier commercial models in instruction following, text rendering, and aesthetic quality. We release the trained models and aesthetic resources to facilitate further academic research and technical progress in the AIGC community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ERNIE-Image, an 8B-parameter single-stream DiT text-to-image model. It describes a bottom-up pre-training data pipeline (fine-grained categorization, rich captioning, aesthetic assessment, hierarchical sampling) intended to reduce noise while retaining long-tail concepts, a top-down post-training pipeline with diversified prompts and stabilized DPO for human preference alignment, distillation to ERNIE-Image-Turbo using MT-DMD to limit capability drift, a lightweight Prompt Enhancer, and the auxiliary ERNIE-Image-Aes model plus ERNIE-Image-Aes-1K human-annotated benchmark. The central claim is that extensive qualitative and quantitative experiments demonstrate leading performance among open-source models and near-parity with top commercial systems on instruction following, text rendering, and aesthetic quality.
Significance. If the performance claims are substantiated with proper controls, the work would offer concrete, reproducible details on data-curation and alignment techniques that could help close the open-to-closed-source gap in text-to-image generation; the public release of models and aesthetic resources would constitute a direct community benefit.
major comments (2)
- [Abstract] Abstract: the central claim of 'leading performance among open-source models' and 'approaches top-tier commercial models' in instruction following, text rendering, and aesthetic quality is asserted without any quantitative tables, baselines, metrics, error bars, or dataset statistics, rendering the claim impossible to evaluate from the provided text.
- [Pre-training and post-training sections] Pre-training and post-training sections: the attribution of gains specifically to the bottom-up categorization/captioning/aesthetic/hierarchical-sampling pipeline plus stabilized DPO lacks isolating ablations or matched-data controls that would rule out confounds such as scale differences, data overlap, or benchmark construction variations.
minor comments (1)
- [Abstract] Abstract: 'MT-DMD' is introduced without expansion or citation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The abstract summarizes high-level claims whose supporting quantitative evidence appears in the Experiments section; we address both major comments below and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'leading performance among open-source models' and 'approaches top-tier commercial models' in instruction following, text rendering, and aesthetic quality is asserted without any quantitative tables, baselines, metrics, error bars, or dataset statistics, rendering the claim impossible to evaluate from the provided text.
Authors: The abstract is a concise summary; the full manuscript contains a dedicated Experiments section (Section 4) with quantitative tables reporting metrics (CLIP-T, FID, OCR accuracy, human preference rates), baselines (SDXL, PixArt-α, SD3, commercial APIs), error bars from repeated evaluations, and dataset statistics for the pre-training and post-training corpora. We will revise the abstract to explicitly cross-reference these results and include one or two key headline numbers if space permits. revision: partial
-
Referee: [Pre-training and post-training sections] Pre-training and post-training sections: the attribution of gains specifically to the bottom-up categorization/captioning/aesthetic/hierarchical-sampling pipeline plus stabilized DPO lacks isolating ablations or matched-data controls that would rule out confounds such as scale differences, data overlap, or benchmark construction variations.
Authors: We acknowledge that fully isolating every pipeline component would strengthen causal attribution. The current manuscript reports performance against models trained on public datasets at comparable scale and includes partial controls (e.g., ablation of the aesthetic filter and hierarchical sampling on a 1B-scale proxy). Comprehensive matched-data ablations at 8B scale are computationally prohibitive; we will add an expanded discussion of potential confounds, data-overlap checks, and the available partial ablations in the revision. revision: yes
Circularity Check
No circularity: empirical technical report with no derivations or equations
full rationale
The manuscript is a standard technical report describing an 8B DiT model, bottom-up/top-down data pipelines, stabilized DPO, distillation, and empirical results. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-referential mathematical steps appear. Performance claims rest on experiments rather than any chain that reduces to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. This is the expected non-finding for an engineering report without theoretical content.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Qwen-Image-Flash: Beyond Objective Design
Empirical analysis of data, guidance, and task mixture in few-step distillation of Qwen-Image-2.0 produces the Qwen-Image-Flash model with improved performance in unified generation and editing tasks.
Reference graph
Works this paper leans on
-
[1]
Black Forest Labs
Accessed: 2026-04-28. Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2 , nov
2026
-
[2]
ByteDance
Accessed: 2026-04-28. ByteDance. Seedream 4.5.https://seed.bytedance.com/en/seedream4 5,
2026
-
[3]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025a. Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models- architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025a. Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811, 2025b. Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Eme...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Zigang Geng, Yibing Wang, Yeyao Ma, Chen Li, Yongming Rao, Shuyang Gu, Zhao Zhong, Qinglin Lu, Han Hu, Xiaosong Zhang, et al. X-omni: Reinforcement learning makes discrete autoregressive image generative models great again.arXiv preprint arXiv:2507.22058,
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
URL https://arxiv.org/abs/2106.09685. Dengyang Jiang, Dongyang Liu, Zanyi Wang, Qilong Wu, Liuzhuozheng Li, Hengzhuang Li, Xin Jin, David Liu, Zhen Li, Bo Zhang, Mengmeng Wang, Steven C. H. Hoi, Peng Gao, and Harry Yang. Distribution matching distillation meets reinforcement learning.CoRR, abs/2511.13649,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://doi.org/10.48550/arXiv.2511.13649
doi: 10.48550/ARXIV.2511.13649. URLhttps://doi.org/10.48550/arXiv.2511.13649. Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
-
[11]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[12]
URL https://openreview.net/forum?id=PqvM RDCJT9t. Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sad´e, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, et al. Ministral 3.arXiv preprint arXiv:2601.08584,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Dongyang Liu, Peng Gao, David Liu, Ruoyi Du, Zhen Li, Qilong Wu, Xin Jin, Sihan Cao, Shifeng Zhang, Hongsheng Li, and Steven Hoi. Decoupled DMD: CFG augmentation as the spear, distribution matching as the shield.CoRR, abs/2511.22677,
-
[14]
doi: 10.48550/ARXIV.2511.22677. URL https://doi.org/10.48550/arXiv.2511.22677. Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Conferen...
-
[15]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pp. 4172–4182. IEEE,
2023
-
[16]
Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion
doi: 10.1109/ICCV51070.2023.00387. URLhttps://doi.org/10.1109/ICCV51070.2023.00387. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levin...
-
[17]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer
URL http://papers.nips.cc/pap er files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695,
2023
-
[18]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Kimi K2.5: Visual Agentic Intelligence
URLhttps://arxiv.org/abs/2602.02276. Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8228–8238,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
25 ERNIE-Image T echnical Report April 15, 2026 Wan.https://tongyi.aliyun.com/wan/,
2026
-
[21]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Tianwei Yin, Micha¨el Gharbi, Richard Zhang, Eli Shechtman, Fr´edo Durand, William T. Freeman, and Taesung Park. One-step diffusion with distribution matching distillation.CoRR, abs/2311.18828,
-
[26]
doi: 10.48550/ARXIV.2311.18828. URLhttps://doi.org/10.48550/arXiv.2311.18828. Tianwei Yin, Micha¨el Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fr´edo Durand, and William T. Freeman. Improved distribution matching distillation for fast image synthesis.CoRR, abs/2405.14867,
-
[27]
URLhttps://doi.org/10.48550/arXiv.2405.14867
doi: 10.48550/ARXIV.2405.14867. URLhttps://doi.org/10.48550/arXiv.2405.14867. Z.ai. GLM-Image.https://github.com/zai-org/GLM-Image,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.